 復旦開源LVOS:面向真實場景的長時視頻目標分割數據集
復旦開源LVOS:面向真實場景的長時視頻目標分割數據集
本文介紹復旦大學提出的面向真實場景的長時視頻目標分割數據集LVOS,論文被ICCV2023收錄

現有的視頻目標分割(VOS)數據集主要關注于短時視頻,平均時長在3-5秒左右,并且視頻中的物體大部分時間都是可見的。然而在實際應用過程中,用戶所需要分割的視頻往往時長更長,并且目標物體常常會消失。現有的VOS數據集和真實場景存在一定的差異,真實場景中的視頻更加困難。
雖然現在的SOTA的視頻目標分割方法在短時的VOS數據集上已經取得了90%的分割準確率,但是這些算法在真實場景中的表現如何卻由于缺少相關的數據集不得而知。

因此,為了探究VOS模型在真實場景下的表現,彌補現有數據集的缺失,我們提出了第一個面向真實場景的長時視頻目標分割數據集Long-term Video Object Segmentation (LVOS)。
背景介紹:
視頻目標分割(VOS)旨在根據視頻中第一幀的物體的掩膜,在視頻之后每一幀中準確地跟蹤并分割目標物體。視頻目標分割有著十分廣泛的應用,比如:視頻編輯、現實增強等。在實際應用場景中,待分割的視頻長度常常大于一分鐘,且視頻中的目標物體會頻繁地消失和重新出現。對于VOS模型來說,在任意長的視頻中準確地重檢測和分割目標物體是一個十分重要的能力。
但是,現有的VOS模型主要是針對于短時視頻設計的,并不能很好的處理長時的物體消失和錯誤累計。并且部分VOS算法依賴于不斷增長的記憶模塊,當視頻長度較長時,存在著低效率甚至顯存不夠的問題。
目前的視頻目標分割數據集主要關注于短時視頻,平均視頻長度為六秒左右,和真實場景存在著較大差異。與現有的數據集相比,LVOS的視頻長度更長,對于VOS算法的要求更高,能夠更高地評估VOS模型在真實場景下的性能。
LVOS數據集介紹:
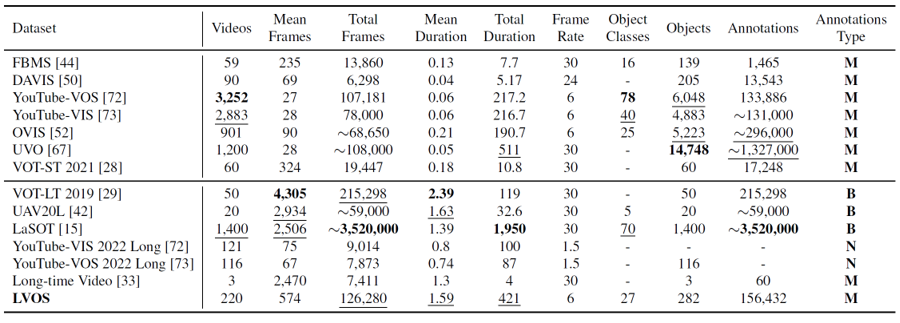
LVOS包含220個視頻,總時長達421分鐘,平均每個視頻時長為1.59分鐘,遠遠大于現有的VOS數據集。LVOS中的視頻更加復雜,且有著在短時視頻中不存在的挑戰,比如長時消失重現和跨時序混淆。這些挑戰更難,且對VOS模型的性能影響更大。LVOS中涉及27個類別的物體,其中包含了7種只有測試集中存在的未見類別,能夠很好地衡量VOS模型的泛化性。
LVOS分為120個訓練視頻,50個驗證視頻和50個測試視頻,其中測試視頻和驗證視頻已經全部開源,而測試視頻目前只開源了視頻圖像和第一幀中目標物體的掩膜,需要將預測結果上傳到測試服務器中進行在線評測。
方法介紹:
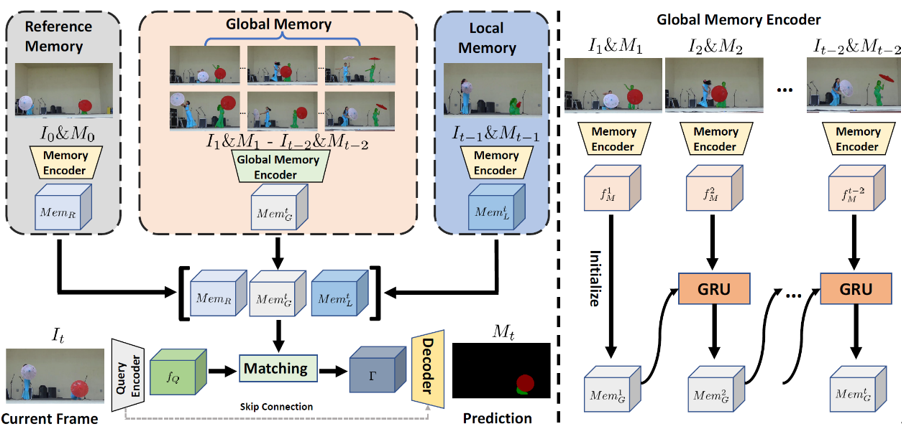
針對于長時視頻,我們提出了一個新穎的VOS算法,Diverse Dynamic Memory (DDMemory)。DDMemory包含三個固定大小的記憶模塊,分別是參考記憶,全局記憶和局部記憶。通過記憶模塊,DDMemory將全局的時序信息壓縮到三個固定大小的記憶特征中,在保持高準確率的同時實現了低GPU顯存占用和高效率。在分割當前幀時,當前幀圖像特征會與三個記憶模塊特征進行匹配,并根據匹配結果輸出掩膜預測。參考記憶存儲第一幀的圖像和掩膜信息,參考記憶負責物體消失或者遮擋之后的找回。局部記憶會隨著視頻不斷更新,存儲前一幀的圖像和掩膜,為當前幀的分割提供位置和形狀的先驗。而全局記憶利用了全局記憶編碼器,通過循環網絡的形式,有效地將全局歷史信息存儲在一個固定大小的特征中,實現對于時序信息的高效壓縮和對冗余噪聲干擾的排除。
實驗:
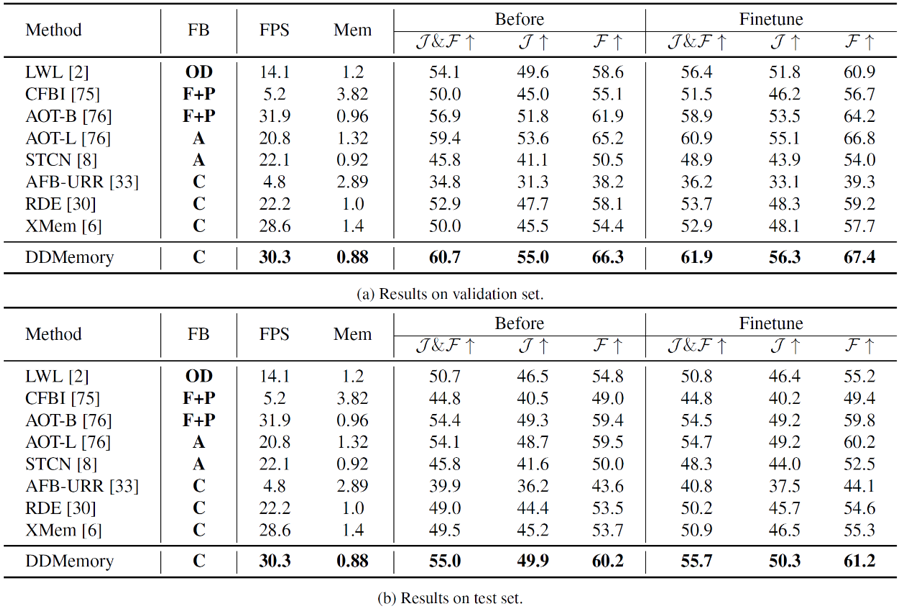
在驗證集和測試集上,我們對現有的VOS模型和DDMemory進行了分別評測。從表中可以看到,現有僅在短時視頻上訓練的VOS模型在長時視頻上表現不如人意,而在長時視頻上進行了微調之后,性能均有一定的提升。我們提出的DDMemory能夠使用最小的GPU顯存,在實現最好性能的同時,實現實時的速度(30.3FPS)。實驗結果表明,現有的VOS模型對于真實場景表現較差,且由于缺少面向真實場景的數據集,在一定程度上限制了現有VOS模型的發展,也證明了LVOS數據集的價值。

我們也進行了oracle實驗,給定真實的位置和掩膜,模型的性能都會有所提升。在分割當前幀時,給定目標物體的真實位置,性能能夠提升8.3%。而在記憶模塊更新時,使用真實掩膜來代替預測掩膜進行更新,預測性能能夠提升20.8%。但是即使給定目標物體的真實位置和掩膜,模型預測結果仍然和真實結果存在較大差距。實驗表明,錯誤累計以及真實場景視頻中復雜的物體運動對VOS模型仍然是尚未解決的挑戰,且這些挑戰在現有短時視頻數據集中并不明顯,卻在真實場景下對VOS算法性能有著巨大的影響。
總結
針對于真實場景,我們構建了一個新的長時視頻目標分割數據集LVOS,LVOS中的視頻物體運動更加復雜,對于VOS模型的能力有著更高的要求,且比現有的短時數據集更加貼近實際應用。我們對現有的VOS算法進行了測試和比較,發現現有的VOS模型并不能很好地解決長時視頻中的挑戰。基于LVOS,我們也分析了現有方法的缺陷以及一些可能的改進方向。希望LVOS能夠為面向真實場景的視頻理解研究提供一個平臺。
-
算法
+關注
關注
23文章
4601瀏覽量
92673 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
VOS
+關注
關注
0文章
21瀏覽量
8091
原文標題:?ICCV 2023 | 復旦開源LVOS:面向真實場景的長時視頻目標分割數據集
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
鴻蒙開源全場景應用開發資料匯總
復旦微電子學院楊帆:介紹openDACS物理設計&建模驗證SIG,發布開源Verilog Parser
廣泛應用的城市語義分割的數據集整理
如何在信息熵約束下進行視頻的目標分割資料詳細概述


港中大IDEA開源首個大規模全場景人體數據集Human-Art
語義分割數據集:從理論到實踐
PyTorch教程-14.9. 語義分割和數據集

最全自動駕駛數據集分享系列一:目標檢測數據集

SAM-PT:點幾下鼠標,視頻目標就分割出來了!






 工商網監
工商網監
評論