 頂刊TPAMI 2023!生成式AI與圖像合成綜述發布!
頂刊TPAMI 2023!生成式AI與圖像合成綜述發布!
生成式AI作為當前人工智能領域的前沿技術,已被廣泛的應用于各類視覺合成任務。
隨著DALL-E2,Stable Diffusion和DreamFusion的發布,AI作畫和3D合成實現了令人驚嘆的視覺效果并且在全球范圍內的爆炸式增長。這些生成式AI技術深刻地拓展了人們對于AI圖像生成能力的認識,那么這些生成式AI方法是如何生成以假亂真的視覺效果?又是如何利用深度學習和神經網絡技術來實現畫作、3D生成以及其他創造性任務的呢?我們的綜述論文將會給您提供這些問題的答案。
在第一章節,該綜述描述了多模態圖像合成與編輯任務的意義和整體發展,以及本論文的貢獻與總體結構。
在第二章節,根據引導圖片合成與編輯的數據模態,該綜述論文介紹了比較常用的視覺引導,文字引導,語音引導,還有近期DragGAN提出的控制點引導等,并且介紹了相應模態數據的處理方法。

在第三章節,根據圖像合成與編輯的模型框架,該論文對目前的各種方法進行了分類,包括基于GAN的方法,擴散模型方法,自回歸方法,和神經輻射場(NeRF)方法。
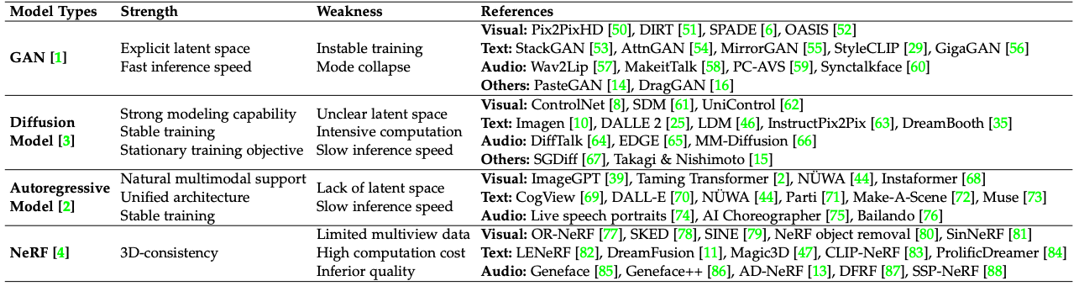
由于基于GAN的方法一般使用條件GAN和 GAN 反演,因此該論文進一步根據 控制條件的融合方式,模型的結構,損失函數設計,多模態對齊,和跨模態監督進行了詳細描述。
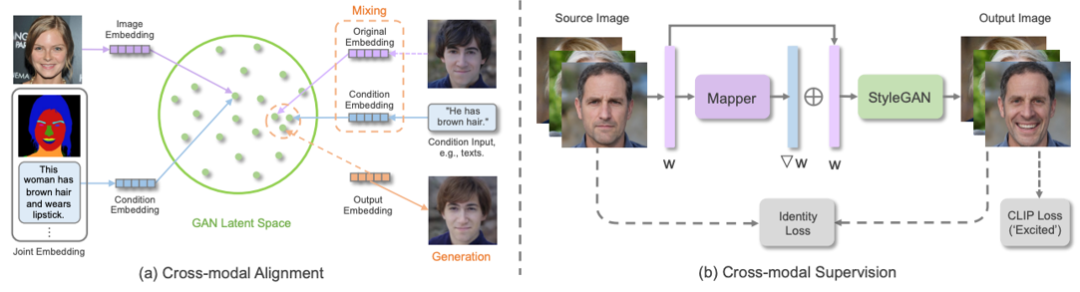
近期,火熱的擴散模型也被廣泛應用于多模態合成與編輯任務。例如效果驚人的DALLE-2和Imagen都是基于擴散模型實現的。相比于GAN,擴散式生成模型擁有一些良好的性質,比如靜態的訓練目標和易擴展性。該論文依據條件擴散模型和預訓練擴散模型對現有方法進行了分類與詳細分析。
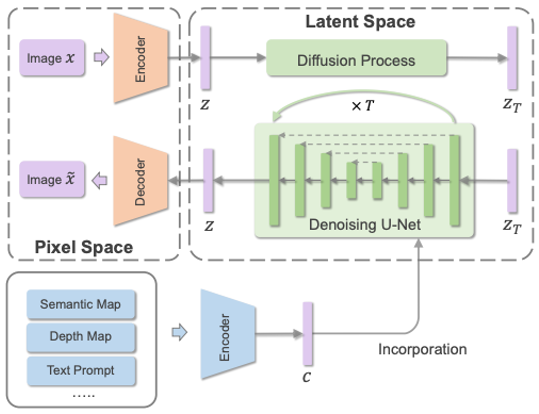
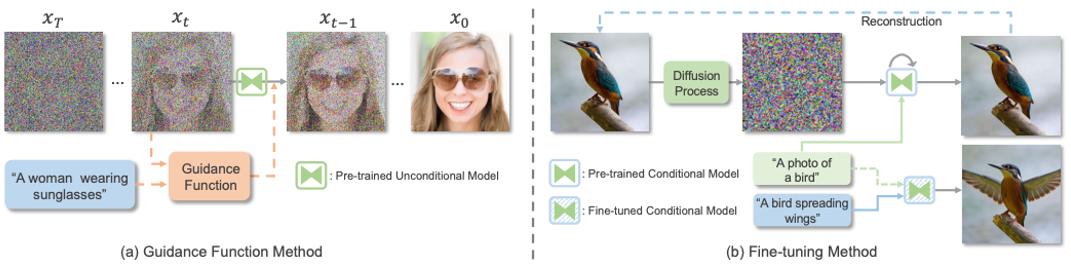
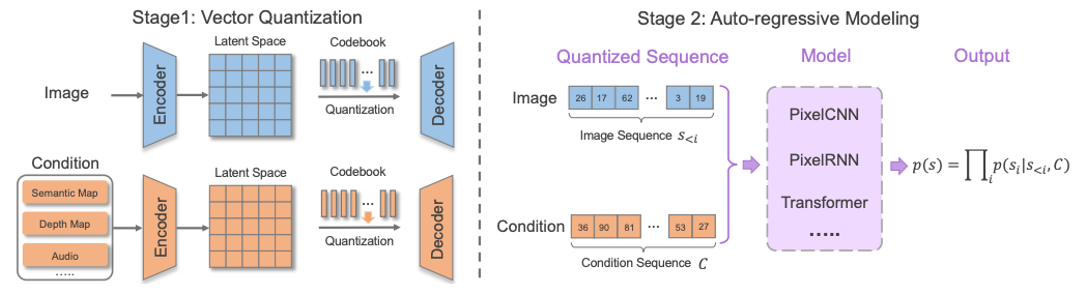
相比于基于GAN和擴散模型的方法,自回歸模型方法能夠更加自然的處理多模態數據,以及利用目前流行的Transformer模型。自回歸方法一般先學習一個向量量化編碼器將圖片離散地表示為token序列,然后自回歸式地建模token的分布。由于文本和語音等數據都能表示為token并作為自回歸建模的條件,因此各種多模態圖片合成與編輯任務都能統一到一個框架當中。
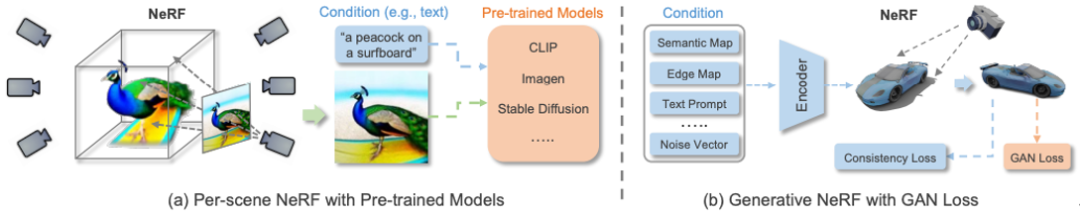
以上方法主要聚焦于2D圖像的多模態合成與編輯。近期隨著神經輻射場(NeRF)的迅速發展,3D感知的多模態合成與編輯也吸引了越來越多的關注。由于需要考慮多視角一致性,3D感知的多模態合成與編輯是更具挑戰性的任務。本文針對單場景優化NeRF,生成式NeRF兩種方法對現有工作進行了分類與總結。
隨后,該綜述對以上四種模型方法的進行了比較和討論。總體而言,相比于GAN,目前最先進的模型更加偏愛自回歸模型和擴散模型。而NeRF在多模態合成與編輯任務的應用為這個領域的研究打開了一扇新的窗戶。

在第四章節,該綜述匯集了多模態合成與編輯領域流行的數據集以及相應的模態標注,并且針對各模態典型任務(語義圖像合成,文字到圖像合成,語音引導圖像編輯)對當前方法進行了定量的比較。同時也對多種模態同時控制生成的結果進行了可視化。

在第五章節,該綜述對此領域目前的挑戰和未來方向進行了探討和分析,包括大規模的多模態數據集,準確可靠的評估指標,高效的網絡架構,以及3D感知的發展方向。
在第六和第七章節,該綜述分別闡述了此領域潛在的社會影響和總結了文章的內容與貢獻。
-
圖像
+關注
關注
2文章
1083瀏覽量
40418 -
數據集
+關注
關注
4文章
1205瀏覽量
24644 -
生成式AI
+關注
關注
0文章
488瀏覽量
459
原文標題:頂刊TPAMI 2023!生成式AI與圖像合成綜述發布!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
搜狗與新華社聯合發布全球首個站立式AI合成主播
Stability AI開源圖像生成模型Stable Diffusion

虹軟圖像深度恢復技術與生成式AI的創新 生成式AI助力
SIGGRAPH 2023 | 生成式 AI 開啟汽車行業新時代,為設計、工程、生產和銷售帶來改進

解決醫療大模型訓練數據難題,商湯最新研究成果登「Nature」子刊

在線研討會 | 9 月 19 日,利用 GPU 加速生成式 AI 圖像內容生成






 工商網監
工商網監
評論