") 大家都在爭相超過A100,無人對標的Grace Hopper性能幾何?
大家都在爭相超過A100,無人對標的Grace Hopper性能幾何?
電子發(fā)燒友網(wǎng)報道(文/周凱揚)作為英偉達在CPU與GPU技術(shù)開發(fā)上的集大成之作,Grace Hopper很大程度上象征著復(fù)雜計算領(lǐng)軍產(chǎn)品。盡管英偉達竭盡所能地去堆這一“超級芯片”的性能,但英偉達還是選擇將Grace Hopper(GH200)描述成了世界上最萬能的計算平臺,這也得益于它同時在AI計算和HPC計算領(lǐng)域展現(xiàn)的可怕性能。
AI計算性能
相信絕大多數(shù)人已經(jīng)從市場瘋搶A100、H100的現(xiàn)狀,對Hopper GPU(H100)的性能有了大致的了解,但Grace Hopper作為一個異構(gòu)計算平臺,在與傳統(tǒng)的x86 CPU與H100對比上,也有著不小的性能差距。
首要區(qū)別自然就是連接Grace CPU和Hopper GPU的NVLink-C2C,這一高帶寬低延遲的互聯(lián)技術(shù)可謂是目前唯一能發(fā)揮H100近乎全部實力的方案。支持最高144TB內(nèi)存的同時,提供900GB/s的帶寬。
英偉達官方也對部分AI計算負載進行了測試,在終端應(yīng)用上對比x86+Hopper與Grace Hopper的一體化方案有何異同。其性能差距可以說是巨大的,就拿最常見的大語言模型推理來說,GH200可以做到x86平臺的4.5倍性能表現(xiàn),而DLRM(深度學(xué)習(xí)推薦模型)訓(xùn)練與圖神經(jīng)網(wǎng)絡(luò)(GNN)訓(xùn)練的性能也可以分別達到3.5倍和1.9倍。
其實這里的差異還是體現(xiàn)在互聯(lián)方案的帶寬上,例如x86+Hopper的方案還是在使用PCIe方案,該方案在batch size較小時性能落后還不算明顯,一旦到了更大的batch size,PCIe的帶寬就成了瓶頸,而不斷以高帶寬輸送數(shù)據(jù)給H100的NVLink-C2C則可以實現(xiàn)比PCIe高出數(shù)倍的性能。
HPC計算性能
Grace Hopper的另一大應(yīng)用領(lǐng)域自然就是HPC了。HPC主要集中在一些科學(xué)、工程的復(fù)雜計算上,比如天氣預(yù)測、生命科學(xué)、流體力學(xué)等。然而與此同時,不少商業(yè)相關(guān)的HPC計算也在進一步推動HPC的發(fā)展,甚至更早用上最新的芯片技術(shù),比如油藏模擬等。
著名油藏模擬軟件ECHELON的開發(fā)商Stone Ridge,在最近獲得了早期訪問權(quán),對英偉達的H100-PCIe、H100-NVL和Grace-Hopper來了場性能測試。早在Volta和Ampere架構(gòu)時,Stone Ridge就對不同架構(gòu)的GPU進行了測試,而如今的H100相較這些舊GPU已經(jīng)在CUDA核心、內(nèi)存容量和內(nèi)存帶寬上有了數(shù)倍的提升。
這些還只是表面上的變化,英偉達還引入了諸多架構(gòu)改進,提高了ML和HPC應(yīng)用程序的性能。而Grace Hopper相較傳統(tǒng)的x86+GPU方案就更具優(yōu)勢了,首先Grace本身就是一個強大的CPU,每個內(nèi)核都有四個128位適量單元,超高的內(nèi)存帶寬以及超大的L2+L3緩存。其次,NVLink的存在大大減少了CPU和GPU之間的通信時間。
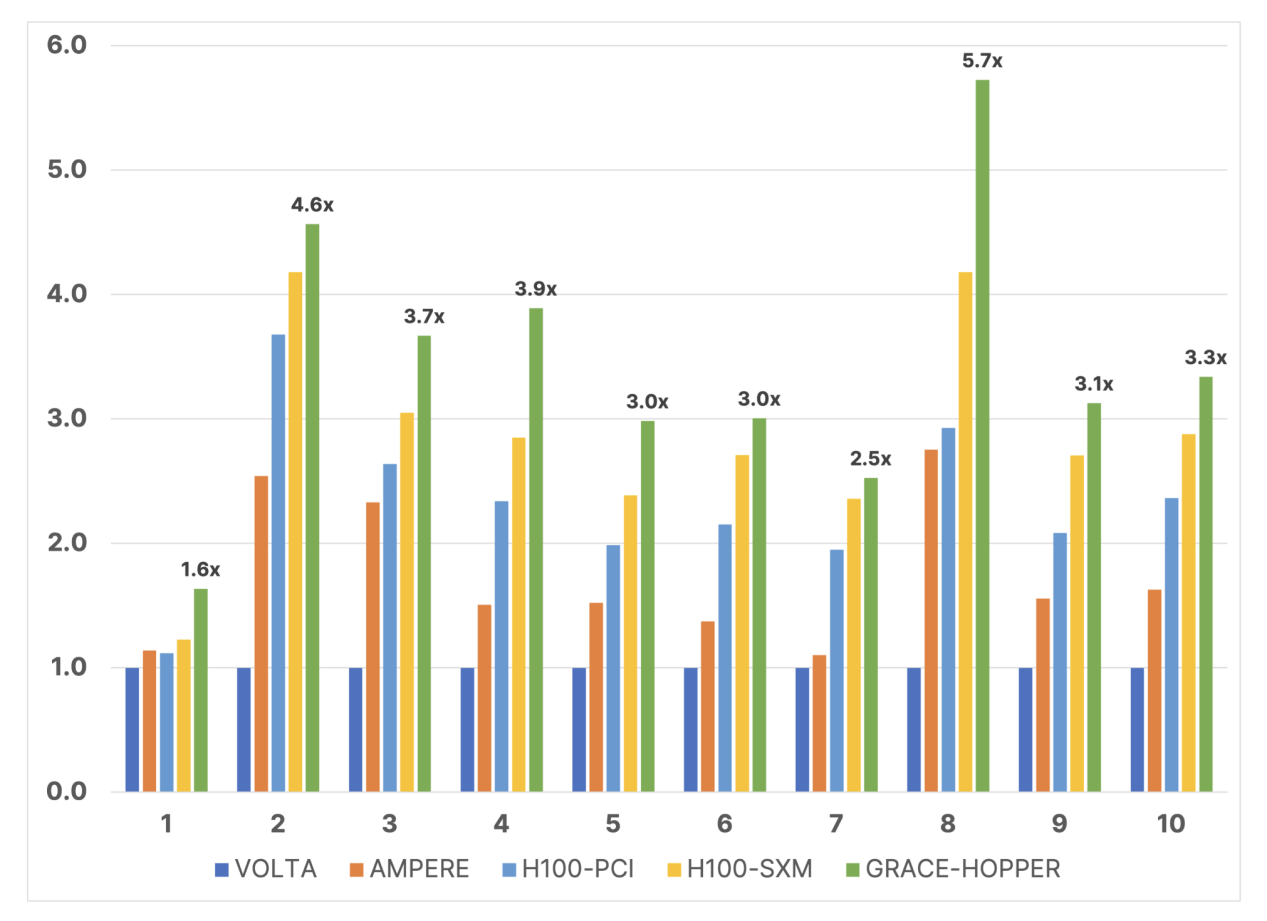
不同架構(gòu)不同版本的英偉達GPU在ECHELON模型上的性能對比 / Stone Ridge
Stone Ridge選擇了不同細胞規(guī)模的模型,從83000個細胞到670萬個細胞,其中Grace Hopper都展現(xiàn)出了不俗的性能,最高可達Volta架構(gòu)的V100的5.7倍。值得一提的是,由于CPU采用了新的Arm架構(gòu),所以ECHELON必須重新編譯才能在系統(tǒng)上運行,不過對于ECHELON來說,重新編譯并不要花太多力氣,他們在不修改代碼的情況就成功重編譯在GH200上正常運行。如果對代碼進行進一步優(yōu)化的話,還有機會獲得更高的性能表現(xiàn)。如此高的性能提升,意味著油藏勘探模擬的時間可以被大幅縮短,從而加快油藏評估的速度。
結(jié)語
可以說無論是A100還是H100,都只是英偉達在AI與HPC戰(zhàn)線擴大戰(zhàn)果的第一步棋,明年Q2交付到各大系統(tǒng)中的GH200才是最大的殺手锏,也很可能會成為更搶手的數(shù)據(jù)中心與超算中心硬件產(chǎn)品。這也恰好證明了英偉達給它的定位,世界上最萬能的計算平臺。
發(fā)布評論請先 登錄
相關(guān)推薦
軟銀升級人工智能計算平臺,安裝4000顆英偉達Hopper GPU
NVIDIA AI Enterprise榮獲金獎

亞馬遜AWS暫緩訂購英偉達Grace Hopper,等待新品Grace Blackwel
亞馬遜未中斷英偉達訂單,等待Grace Blackwell更強性能
英偉達靜候新品來臨,亞馬遜暫緩購買Grace Hopper
NVIDIA Grace Hopper點亮AI超級計算新時代
NVIDIA通過CUDA-Q平臺為全球各地的量子計算中心提供加速
美國首個Grace Hopper架構(gòu)超算Venado落地:達10 exaFLOPS
英偉達H200和A100的區(qū)別
Arm架構(gòu)與Neoverse技術(shù)在基礎(chǔ)設(shè)施領(lǐng)域的應(yīng)用與發(fā)展
NVIDIA特供中國的芯片,AI性能大降10%售價依然高
英偉達Grace-Hopper提供一個緊密集成的CPU + GPU解決方案
英偉達和華為/海思主流GPU型號性能參考

AWS成為第一個提供NVIDIA GH200 Grace Hopper超級芯片的提供商





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論