 云知聲AGI技術實力在2023年再次獲得國際頂會認可
云知聲AGI技術實力在2023年再次獲得國際頂會認可
近日,國際性語音及語言科學技術領域盛會INTERSPEECH 2023在愛爾蘭都柏林舉行。云知聲聯合上海師范大學發表的4篇論文被大會成功收錄,成果覆蓋語言增強、語音識別、防攻擊聲紋等研究方向。這是繼ACM MM 2023后,云知聲AGI技術實力在2023年再次獲得國際頂會認可。
INTERSPEECH在國際上享有極高盛譽并具有廣泛的學術影響力,是由國際語音通訊協會(ISCA)創辦的旗艦級國際會議,是國際性語音及語言科學技術領域的頂級會議之一,對參會企業和單位有著嚴苛的準入門檻,歷屆INTERSPEECH會議都倍受全球各地語音研究領域人士的廣泛關注。
此次獲得國際頂會認可,既是云知聲與上海師范大學通力合作、持續探索智能語音技術的結果,也離不開云知聲AGI技術架構的有力支撐。
云知聲:通過通用人工智能(AGI)創建互聯直覺的世界
云知聲AI技術體系及U+X戰略
作為中國AGI技術產業化的先驅之一,云知聲于2016年打造Atlas人工智能基礎設施,并構建公司云知大腦(UniBrain)技術中臺,以山海(UniGPT)通用認知大模型為核心,包括多模態感知與生成、知識圖譜、物聯平臺等智能組件,并通過領域增強能力,為云知聲智慧物聯、智慧醫療等業務提供高效的產品化支撐,推動“U(云知大腦)+X(應用場景)”戰略落實,踐行公司“通過通用人工智能(AGI)創建互聯直覺的世界”的使命。
作為云知大腦(UniBrain)的重要組件,智能語音技術包含語音識別、聲紋識別、語音合成等,目前已廣泛應用于家居、車載、客服等領域。以車載場景為例,在云知聲智能語音技術的加持下,可實現多音區識別、連續語音交互、個性化語音播報、所見即可說、模糊指令匹配等強大語音能力,為用戶帶來更智能更自然的交互體驗。隨著云知聲智能語音技術的不斷發展,其在各個場景的落地應用也將進一步提速。此次論文收錄,充分印證了云知聲在智能語音領域的技術創新實力,同時,也將進一步夯實其AGI技術底座,加速千行百業的智慧化升級。
接下來,云知聲將繼續踐行“U+X”戰略,攜手上海師范大學等高校機構,共同加強AI基礎理論和關鍵技術的研發,不斷拓展AGI應用場景,為智慧物聯與智慧醫療兩大領域提供更廣泛、更深入的人工智能解決方案,致力實現以人工智能賦能千行百業的美好愿景。
以下為入選論文概覽:
研究方向:語音增強
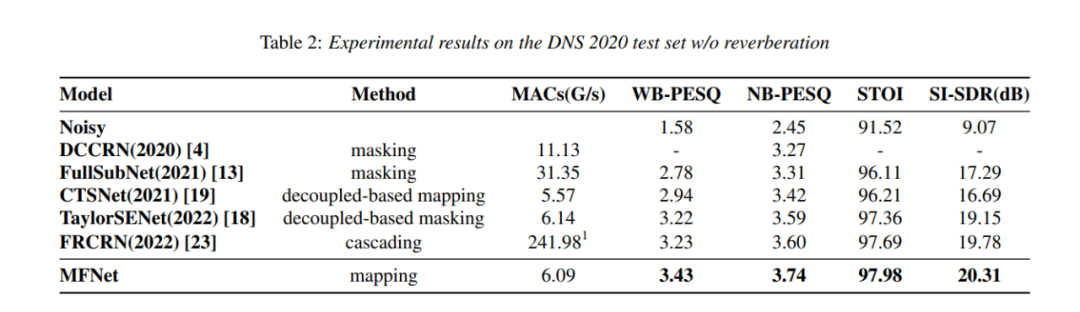
目前主流時頻語音增強系統以復頻譜作為輸入,存在著訓練工具不支持復數,復數建模方式不易訓練,以及基于掩蔽的方法理論上無法完全恢復出干凈語音的問題。為解決以上問題,本文提出了一種無需掩蔽的語音增強系統。該系統利用短時離散余弦變換(STDCT)作為特征,不僅與STFT同樣具備信息完備性,而且是一種實數特征。我們在MetaFomer基礎上,結合MobileNet block的輕量架構以及NAFNet的設計理念構建了全局局部模塊,整個網絡由此模塊堆疊而成。結果表明,相比其他網絡,MFNet的性能達到了SOTA水平,且計算量具有優勢。
研究方向:語音識別
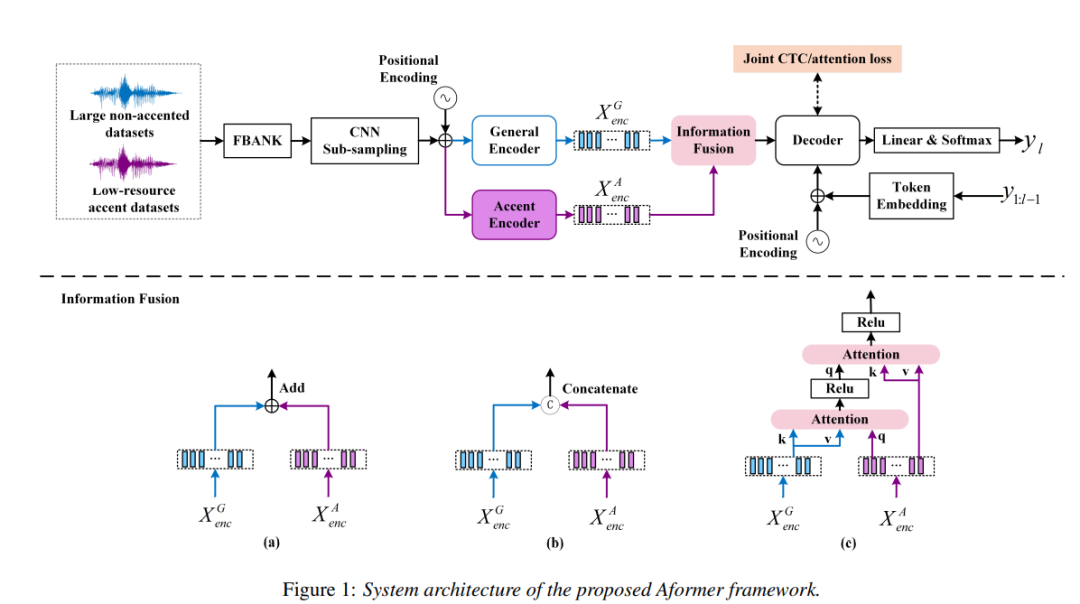
Multi-pass Training and Cross-information Fusion for Low-resource End-to-end Accented Speech Recognition
低資源重口音語音識別是當前ASR技術在實際應用中面臨的重要挑戰之一。在這項研究中,我們提出了一個基于Conformer的架構,稱為Aformer,以利用大量非口音和有限口音訓練數據的聲學信息。在Aformer中設計了一個普通編碼器和一個口音編碼器來提取互補的聲學信息。此外,我們使用多通道的方式訓練Aformer,并研究了三種交叉信息融合方法,以有效地結合來自一般編碼器和口音編碼器的信息。結果表明,在六個域內和域外口音測試集上,我們提出的方法優于Conformer基線,詞/字錯誤率相對減少了10.2%到24.5%。
研究方向:語音識別
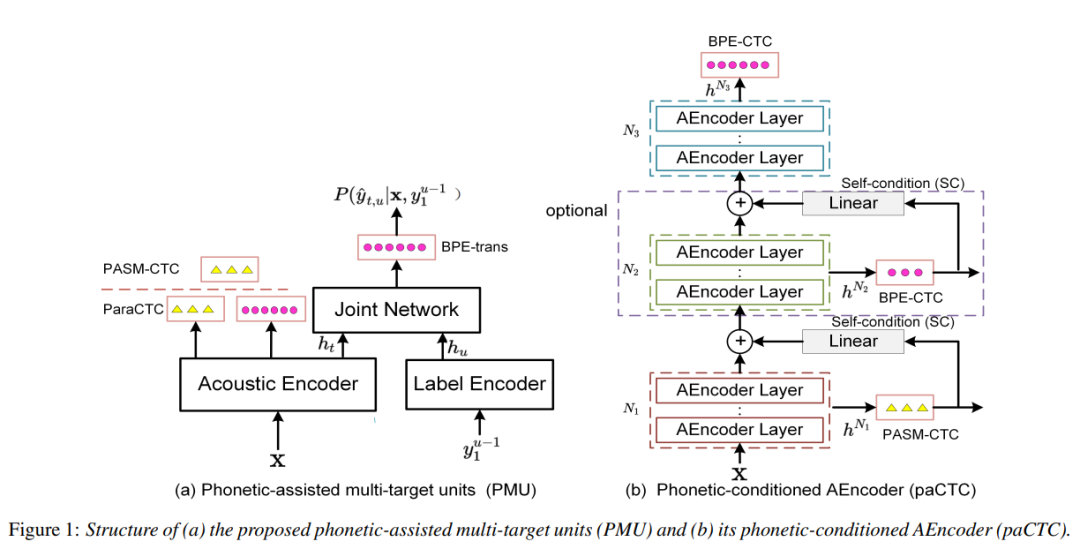
Phonetic-assisted Multi-Target Units Modeling for Improving Conformer-Transducer ASR system
在端到端的自動語音識別(ASR)中,開發有效的目標建模單元是非常重要的,也是大家一直關注的問題。我們提出一種語音輔助的多目標單元(PMU)建模方法,以漸進式表征學習的方式增強Conformer-TransducerASR系統。具體來說,PMU首先使用語音輔助子詞建模(PASM)和字節對編碼(BPE)分別產生語音誘導和文本誘導的目標單元;在此基礎上,我們提出了三種增強聲學編碼器的框架,包括基本PMU、paraCTC和paCTC,它們集成了不同層次的PASM和BPE單元,用于CTC和transducer多任務訓練。在LibriSpeech和口音ASR測試集上的實驗結果表明,與傳統的BPE相比,提出的PMU方法顯著降低了LibriSpeech clean、other和6個重音ASR測試集的WER,分別降低了12.7%、6.0%和7.7%。
研究方向:防攻擊聲紋
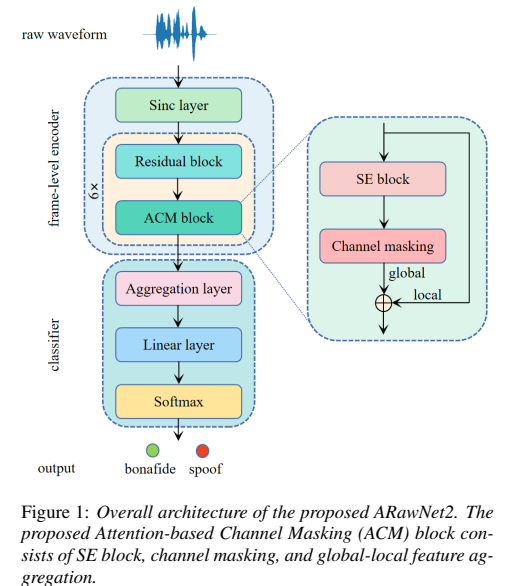
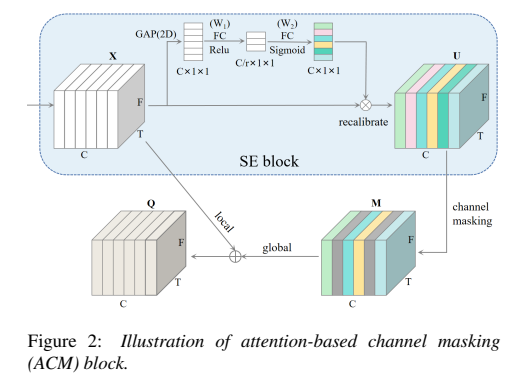
Advanced RawNet2 with Attention-based Channel Masking for Synthetic Speech Detection
自動揚聲器驗證系統通常很容易受到欺騙攻擊,特別是不可見的攻擊。由于語音合成和語音轉換算法的多樣性,如何提高合成語音檢測系統的泛化能力是一個具有挑戰性的問題。為了解決這個問題,我們提出了一種改進的RawNet2,通過引入一個基于注意力的通道掩蔽模塊來改進RawNet2,其中包括三個主要組成部分:SE、通道掩蔽和全局-局部特征聚合。在ASVspoof2019和ASVspoof 2021數據集上評估了該系統的有效性。其中,ARawNet2在ASVspoof 2019 LA任務上達到了4.61%,在ASVspoof 2021 LA和DF任務上的EER分別達到了8.36%和19.03%,比RawNet2基線分別降低了12.00%和14.97%。
審核編輯:彭菁
-
語音識別
+關注
關注
38文章
1721瀏覽量
112542 -
人工智能
+關注
關注
1791文章
46853瀏覽量
237546 -
Agi
+關注
關注
0文章
77瀏覽量
10194 -
云知聲
+關注
關注
0文章
169瀏覽量
8369
原文標題:云知聲4篇論文入選國際頂會INTERSPEECH 2023
文章出處:【微信號:云知聲,微信公眾號:云知聲】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
中國科大攜手云知聲斬獲ACM MM 2024競賽多項榮譽
云知學院榮登2024中國企培業模式創新TOP10榜單
云知聲黃偉:AGI產業升級新范式
云知聲榮獲“年度車載AGI解決方案高成長供應商”
云知聲在邊緣側大模型技術探索和應用
?云知聲榮登“2023年度中國高科技高成長企業系列榜單”

云知聲推進港股IPO!AI解決方案收入排名中國第四,2023年營收破7億





 工商網監
工商網監
評論