") 消息隊列中如何保證消息的順序性?
消息隊列中如何保證消息的順序性?
我舉個例子,我們以前做過一個 mysqlbinlog同步的系統(tǒng),壓力還是非常大的,日同步數(shù)據(jù)要達到上億,就是說數(shù)據(jù)從一個 mysql 庫原封不動地同步到另一個 mysql 庫里面去(mysql -> mysql)。常見的一點在于說比如大數(shù)據(jù) team,就需要同步一個 mysql 庫過來,對公司的業(yè)務(wù)系統(tǒng)的數(shù)據(jù)做各種復雜的操作。
你在 mysql 里增刪改一條數(shù)據(jù),對應(yīng)出來了增刪改 3 條binlog日志,接著這三條binlog發(fā)送到 MQ 里面,再消費出來依次執(zhí)行,起碼得保證人家是按照順序來的吧?不然本來是:增加、修改、刪除;你楞是換了順序給執(zhí)行成刪除、修改、增加,不全錯了么。
本來這個數(shù)據(jù)同步過來,應(yīng)該最后這個數(shù)據(jù)被刪除了;結(jié)果你搞錯了這個順序,最后這個數(shù)據(jù)保留下來了,數(shù)據(jù)同步就出錯了。
先看看順序會錯亂的倆場景:
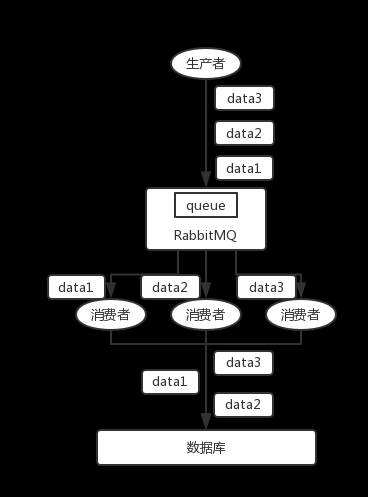
RabbitMQ:一個 queue,多個 consumer。比如,生產(chǎn)者向 RabbitMQ 里發(fā)送了三條數(shù)據(jù),順序依次是 data1/data2/data3,壓入的是 RabbitMQ 的一個內(nèi)存隊列。有三個消費者分別從 MQ 中消費這三條數(shù)據(jù)中的一條,結(jié)果消費者2先執(zhí)行完操作,把 data2 存入數(shù)據(jù)庫,然后是 data1/data3。這不明顯亂了。
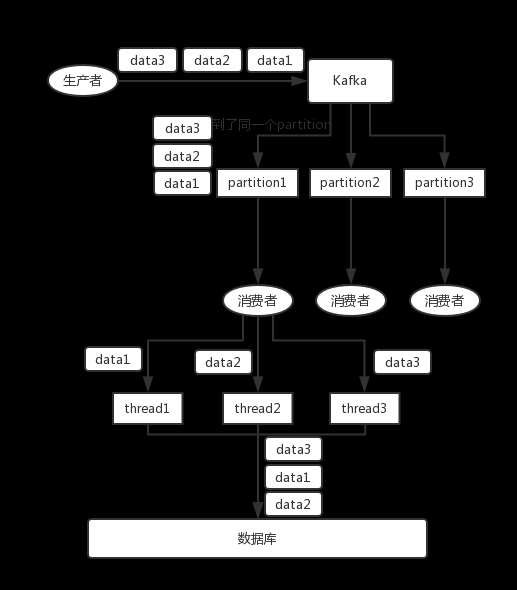
Kafka:比如說我們建了一個 topic,有三個 partition。生產(chǎn)者在寫的時候,其實可以指定一個 key,比如說我們指定了某個訂單 id 作為 key,那么這個訂單相關(guān)的數(shù)據(jù),一定會被分發(fā)到同一個 partition 中去,而且這個 partition 中的數(shù)據(jù)一定是有順序的。
消費者從 partition 中取出來數(shù)據(jù)的時候,也一定是有順序的。到這里,順序還是 ok 的,沒有錯亂。接著,我們在消費者里可能會搞多個線程來并發(fā)處理消息。因為如果消費者是單線程消費處理,而處理比較耗時的話,比如處理一條消息耗時幾十 ms,那么 1 秒鐘只能處理幾十條消息,這吞吐量太低了。而多個線程并發(fā)跑的話,順序可能就亂掉了。
解決方案
RabbitMQ
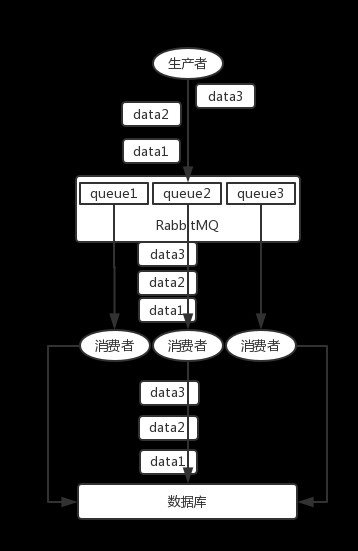
拆分多個 queue,每個 queue 一個 consumer,就是多一些 queue 而已,確實是麻煩點;或者就一個 queue 但是對應(yīng)一個 consumer,然后這個 consumer 內(nèi)部用內(nèi)存隊列做排隊,然后分發(fā)給底層不同的 worker 來處理。
Kafka
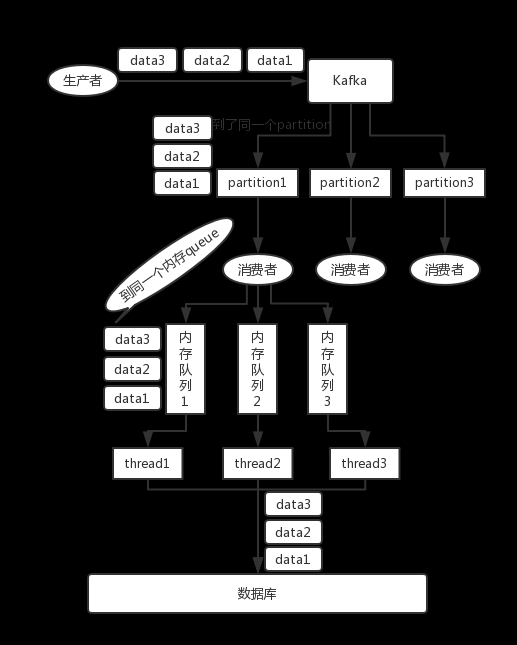
一個 topic,一個 partition,一個 consumer,內(nèi)部單線程消費,單線程吞吐量太低,一般不會用這個。
寫 N 個內(nèi)存 queue,具有相同 key 的數(shù)據(jù)都到同一個內(nèi)存 queue;然后對于 N 個線程,每個線程分別消費一個內(nèi)存 queue 即可,這樣就能保證順序性。
鏈接:https://www.jianshu.com/p/8a5630e2c317
審核編輯:劉清
-
MySQL
+關(guān)注
關(guān)注
1文章
802瀏覽量
26444 -
MYSQL數(shù)據(jù)庫
+關(guān)注
關(guān)注
0文章
95瀏覽量
9382 -
消息隊列
+關(guān)注
關(guān)注
0文章
33瀏覽量
2969 -
mysql觸發(fā)器
+關(guān)注
關(guān)注
0文章
6瀏覽量
1107
原文標題:面試官:消息隊列中如何保證消息的順序性?
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
FIFO隊列原理簡述
嵌入式開發(fā)中消息隊列的實現(xiàn)
局部變量與隊列的使用
利用隊列控制多設(shè)備的控制結(jié)構(gòu)
數(shù)據(jù)結(jié)構(gòu)之隊列順序及其構(gòu)造
LabVIEW什么是隊列
iFix組態(tài)軟件中基于隊列的命令處理機制研究
FIFO隊列原理簡述 擁塞避免原理
單片機實現(xiàn)FIFO循環(huán)隊列的代碼和資料免費下載
SystemVerilog中的隊列
什么是消息隊列?消息隊列中間件重要嗎?
RTOS消息隊列的應(yīng)用
FreeRTOS消息隊列介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論