") 一文捋順千億模型訓(xùn)練技術(shù):流水線并行、張量并行和3D并行
一文捋順千億模型訓(xùn)練技術(shù):流水線并行、張量并行和3D并行
導(dǎo)讀
流水線性并行、張量并行、3D并行三種分布式訓(xùn)練方法的詳細(xì)解讀,從原理到具體方法案例。
流水線性并行和張量并行都是對模型本身進(jìn)行劃分,目的是利用有限的單卡顯存訓(xùn)練更大的模型。簡單來說,流水線并行水平劃分模型,即按照層對模型進(jìn)行劃分;張量并行則是垂直劃分模型。3D并行則是將流行線并行、張量并行和數(shù)據(jù)并行同時應(yīng)用到模型訓(xùn)練中。
一、流水線并行
流水線并行的目標(biāo)是訓(xùn)練更大的模型。本小節(jié)先介紹符合直覺的樸素層并行方法,并分析其局限性。然后,介紹流水線并行算法GPipe和PipeDream。
1. 樸素層并行
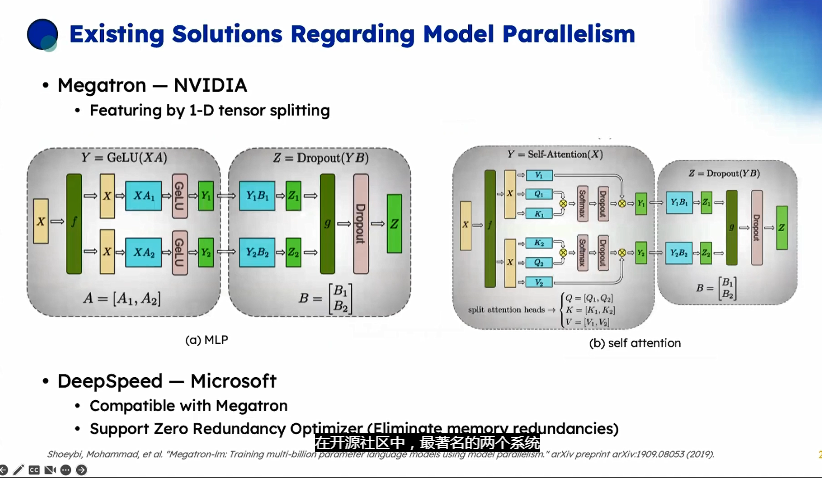
當(dāng)一個模型大到單個GPU無法訓(xùn)練時,最直接的想法是對模型層進(jìn)行劃分,然后將劃分后的部分放置在不同的GPU上。下面以一個4層的序列模型為例,介紹樸素層并行:
將其按層劃分至兩個GPU上:
- GPU1負(fù)責(zé)計算:intermediate (input)) ;
- GPU2負(fù)責(zé)計算:output (intermediate;
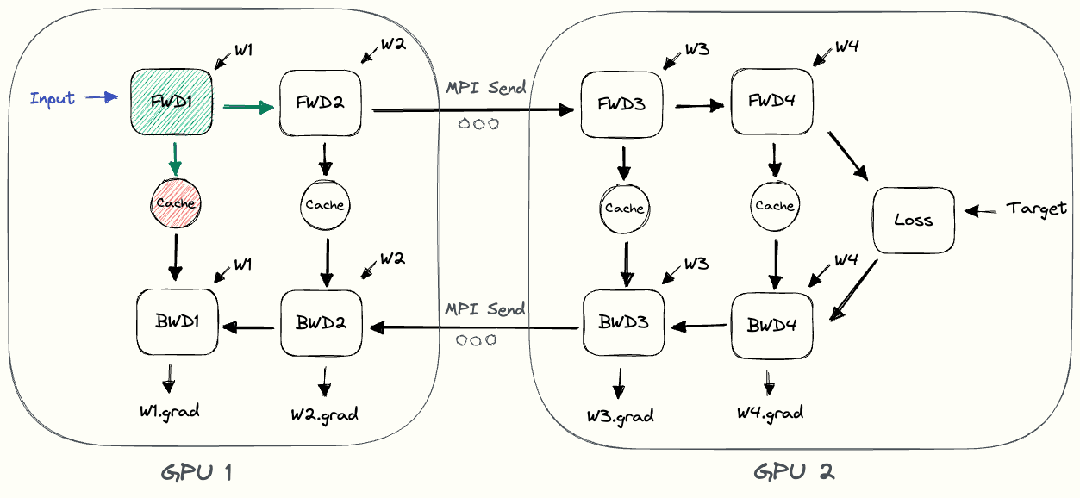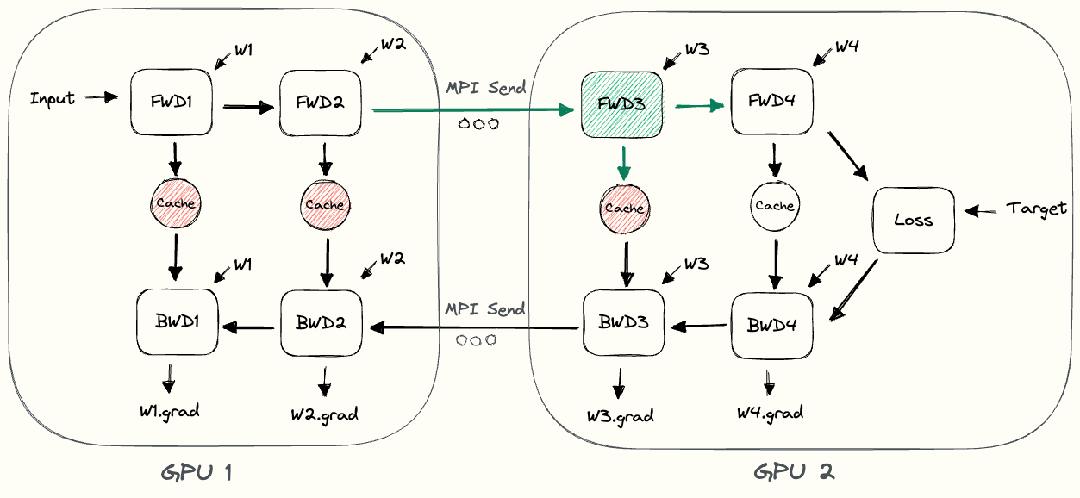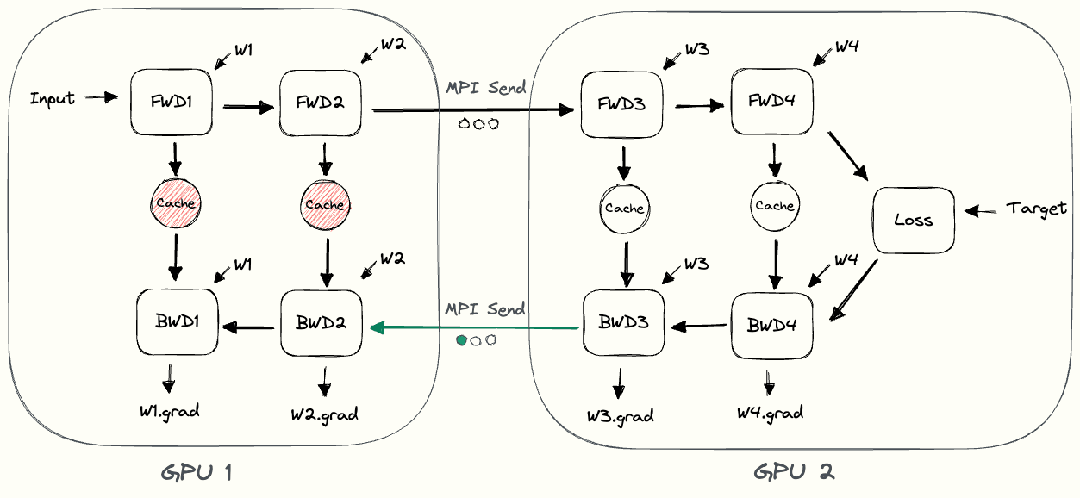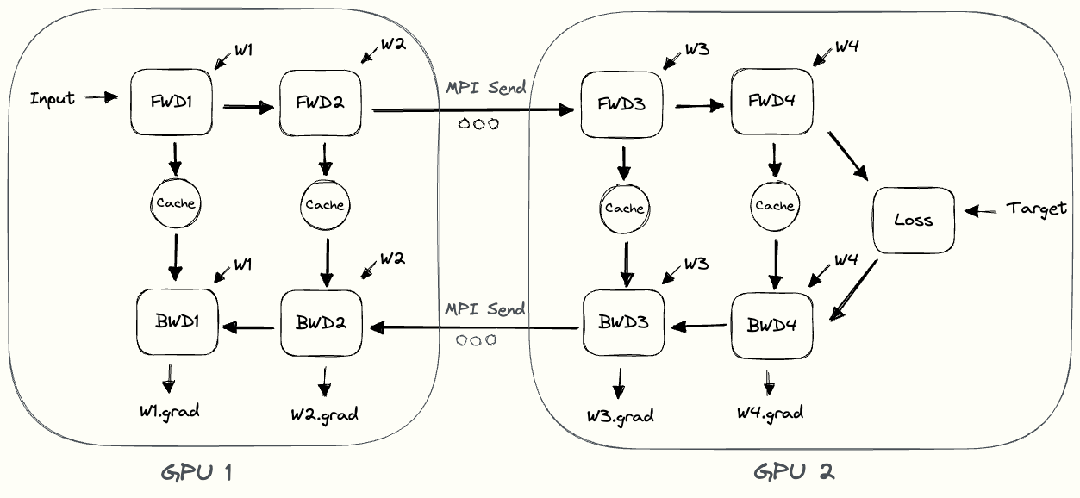
整個樸素層并行前向傳播和后向傳播的過程如上圖所示。GPU1執(zhí)行前向傳播, 并將激活 (activations)緩存下來。然后將層的輸出intermediate發(fā)送給GPU2, GPU2完成前向傳播和loss計算后, 開始反向傳播。當(dāng)GPU2完成反向傳播后, 會將的梯度返還給GPU1。GPU1完成最終的反向傳播。
根據(jù)上面的介紹,可以發(fā)現(xiàn)樸素層并行的缺點(diǎn):
- 低GPU利用率。在任意時刻,有且僅有一個GPU在工作,其他GPU都是空閑的。
- 計算和通信沒有重疊。在發(fā)送前向傳播的中間結(jié)果(FWD)或者反向傳播的中間結(jié)果(BWD)時,GPU也是空閑的。
- 高顯存占用。GPU1需要保存整個minibatch的所有激活,直至最后完成參數(shù)更新。如果batch size很大,這將對顯存帶來巨大的挑戰(zhàn)。
2. GPipe
2.1 GPipe的原理
GPipe通過將minibatch劃分為更小且相等尺寸的microbatch來提高效率。具體來說,讓每個microbatch獨(dú)立的計算前后向傳播,然后將每個mircobatch的梯度相加,就能得到整個batch的梯度。由于每個層僅在一個GPU上,對mircobatch的梯度求和僅需要在本地進(jìn)行即可,不需要通信。
假設(shè)有4個GPU,并將模型按層劃分為4個部分。樸素層并行的過程為
| Timestep | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| GPU3 | FWD | BWD | ||||||
| GPU2 | FWD | BWD | ||||||
| GPU1 | FWD | BWD | ||||||
| GPU0 | FWD | BWD |
可以看到,在某一時刻僅有1個GPU工作。并且每個timesep花費(fèi)的時間也比較長,因?yàn)镚PU需要跑完整個minibatch的前向傳播。
GPipe將minibatch劃分為4個microbatch,然后依次送入GPU0。GPU0前向傳播后,再將結(jié)果送入GPU1,以此類推。整個過程如下表
| Timestep | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPU3 | F1 | F2 | F3 | F4 | B4 | B3 | B2 | B1 | ||||||
| GPU2 | F1 | F2 | F3 | F4 | B4 | B3 | B2 | B1 | ||||||
| GPU1 | F1 | F2 | F3 | F4 | B4 | B3 | B2 | B1 | ||||||
| GPU0 | F1 | F2 | F3 | F4 | B4 | B3 | B2 | B1 |
F1表示使用當(dāng)前GPU上的層來對microbatch1進(jìn)行前向傳播。在GPipe的調(diào)度中,每個timestep上花費(fèi)的時間要比樸素層并行更短,因?yàn)槊總€GPU僅需要處理microbatch。
2.2 GPipe的Bubbles問題
bubbles指的是流水線中沒有進(jìn)行任何有效工作的點(diǎn)。這是由于操作之間的依賴導(dǎo)致的。例如,在GPU3執(zhí)行完F1之前,GPU4只能等待。整個流水線過程中的bubbles如下圖所示。
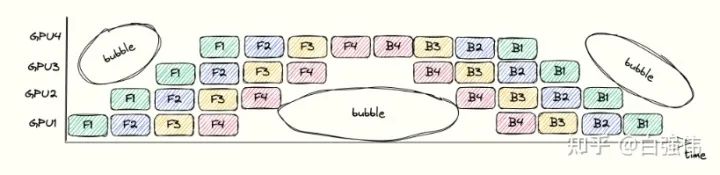
bubbles浪費(fèi)時間的比例依賴于pipeline的深度和mincrobatch的數(shù)量。假設(shè)單個GPU上完成前向傳播或者后向傳播的面積為 1 (也就是上圖中的單個小方塊面積為 1 )。上圖中的總長度為, 寬度為, 總面積為。其中, 彩色小方塊占用的面積表示GPU執(zhí)行的時間, 為其。空白處面積的占比代表了浪費(fèi)時間的比較, 其值為
因此,增大microbatch的數(shù)量m,可以降低bubbles的比例。
2.3 GPipe的顯存需求
增大batch size就會線性增大需要被緩存激活的顯存需求。在GPipe中,GPU需要在前向傳播至反向傳播這段時間內(nèi)緩存激活(activations)。以GPU0為例,microbatch1的激活需要從timestep 0保存至timestep 13。
GPipe為了解決顯存的問題,使用了gradient checkpointing。該技術(shù)不需要緩存所有的激活,而是在反向傳播的過程中重新計算激活。這降低了對顯存的需求,但是增加了計算代價。
假設(shè)所有層都大致相等。每個GPU緩存激活所需要的顯存為
也就是與單個GPU上的層數(shù)以及batch size成正比。相反,使用gradient checkpointing僅需要緩存邊界層(需要跨GPU發(fā)送結(jié)果的層)的輸入。這可以降低每個GPU的顯存峰值需求
(batchsize) 是緩存邊界激活所需要的顯存。當(dāng)對給定的microbatch執(zhí)行反向傳播時, 需要重新計算該microbatch梯度所需要的激活。對于每個GPU上的層需要的顯存空間。
3. PipeDream
GPipe需要等所有的microbatch前向傳播完成后,才會開始反向傳播。PipeDream則是當(dāng)一個microbatch的前向傳播完成后,立即進(jìn)入反向傳播階段。理論上,反向傳播完成后就可以丟棄掉對應(yīng)microbatch緩存的激活。由于PipeDream的反向傳播完成的要比GPipe早,因此也會減少顯存的需求。
下圖是PipeDream的調(diào)度圖,4個GPU和8個microbatchs。藍(lán)色的方塊表示前向傳播,綠色表示反向傳播,數(shù)字則是microbatch的id。
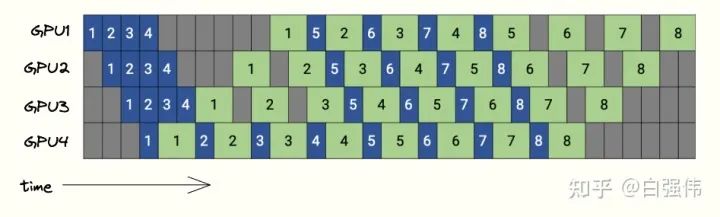
PipeDream在bubbles上與GPipe沒有區(qū)別,但是由于PipeDream釋放顯存的時間更早,因此會降低對顯存的需求。
4. 合并數(shù)據(jù)并行和流水線并行
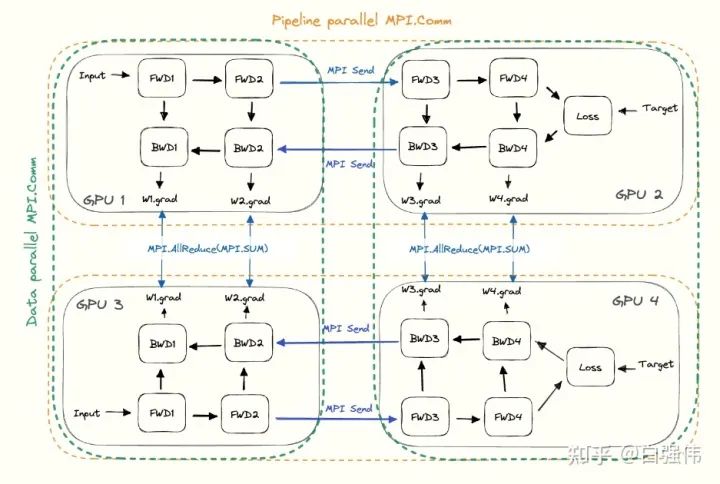
數(shù)據(jù)并行和流水線并行是正交的,可以同時使用。
- 對于流水線并行。每個GPU需要與下個流水線階段(前向傳播)或者上個流水線階段(反向傳播)進(jìn)行通信。
- 對于數(shù)據(jù)并行。每個GPU需要與分配了相同層的GPU進(jìn)行通信。所有層的副本需要AllReduce對梯度進(jìn)行平均。
這將在所有GPU上形成子組,并在子組中使用集合通信。任意給定的GPU都會有兩部分的通信,一個是包含所有相同層的GPU(數(shù)據(jù)并行),另一個與不同層的GPU(流水線并行)。下圖是流水線并行度為2且數(shù)據(jù)并行度為2的示例圖,水平方向是完整的一個模型,垂直方向是相同層的不同副本。
二、張量并行
Transformer中的主要部件是全連接層和注意力機(jī)制,其核心都是矩陣乘法。張量并行的核心就是將矩陣乘法進(jìn)行拆分,從而降低模型對單卡的顯存需求。
1. 1D張量并行
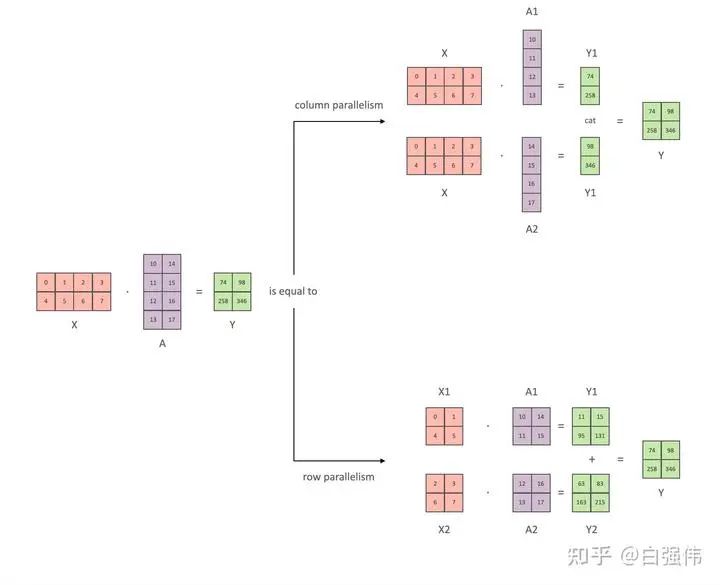
本小節(jié)以全鏈接層為例, 介紹張量并行。其中, 和是輸入和輸出向量,是權(quán)重矩陣,是非線性激活函數(shù)。總量來說張量并行可以分為列并行和行并行(以權(quán)重矩陣的分割方式命名), 上圖展示了兩種并行。
(1) 矩陣乘法角度
這里以矩陣乘法的方式輔助理解1D張量并行。
- 列并行
將矩陣行列劃分為n份(不一定必須相等大小)可以表示為,那么矩陣乘 法表示為
顯然,僅需要對權(quán)重進(jìn)行劃分。
- 行并行
對權(quán)重進(jìn)行劃分,那么必須對輸入矩陣也進(jìn)行劃分。假設(shè)要將A水平劃分為n份,則輸入矩陣X必須垂直劃分為n份,那么矩陣乘法表示為
(2) 激活函數(shù)與通信
顯然,只觀察上面的數(shù)據(jù)公式,無論是行并行還是列并行 ,都只需要在各個部分計算完后進(jìn)行一次通常。只不過列并行將通信的結(jié)果進(jìn)行拼接,而行并行則是對通信結(jié)果相加。
現(xiàn)在,我們將非線性激活GeLU加上,并模擬兩層的全鏈接層。設(shè)X是輸入,A和B則是兩個全鏈接層的權(quán)重。
- 列并行
通過上面的公式可以看到。當(dāng)我們將A和B提前劃分好后,就可以獨(dú)立進(jìn)行計算,在計算出后再進(jìn)行通信。也就是說,這個例子中雖然有兩個全鏈接層,但是僅需要在得到最終結(jié)果前進(jìn)行通信即可。
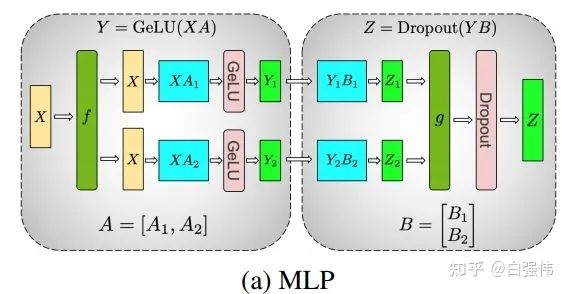
所以,多個全鏈接層堆疊時,僅需要在最終輸出時進(jìn)行一次通信即可(如上圖所示)。
- 行并行
由于是非線性的,所以
因此,行并行每一個全鏈接層都需要進(jìn)行通信來聚合最終的結(jié)果。
(3) 多頭注意力并行
多頭注意力并行不是1D張量并行,但是由于其是Megatron-LM中與1D張量并行同時提出的,所以這里也進(jìn)行簡單的介紹。
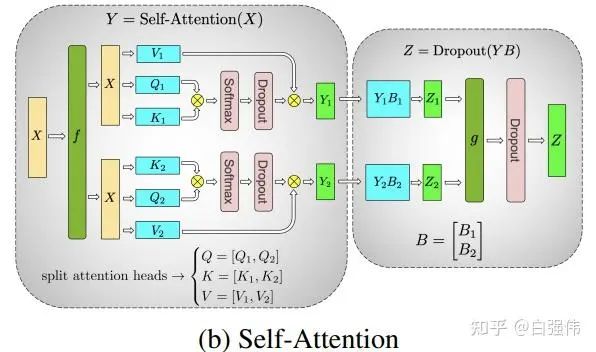
由于多頭注意力的各個頭之間本質(zhì)上就是獨(dú)立的,因此各個頭完全可以并行運(yùn)算。
注意:張量并行(TP)需要非常快的網(wǎng)絡(luò),因此不建議跨多個節(jié)點(diǎn)進(jìn)行張量并行。實(shí)際中,若一個節(jié)點(diǎn)有4個GPU,最高的張量并行度為4。
2. 2D、2.5D張量并行
在1D張量并行后,又逐步提出了2D、2.5D和3D張量并行。這里對2D和2.5D張量并行進(jìn)行簡單介紹:
(1) 2D張量并行
1D張量并行并沒有對激活(activations,也就是模型中間層的輸出結(jié)果)進(jìn)行劃分,導(dǎo)致消耗大量的顯存。
這里仍然以矩陣乘法為例, 給定有個處理器。這里假設(shè), 則將X和A都劃分為的塊。
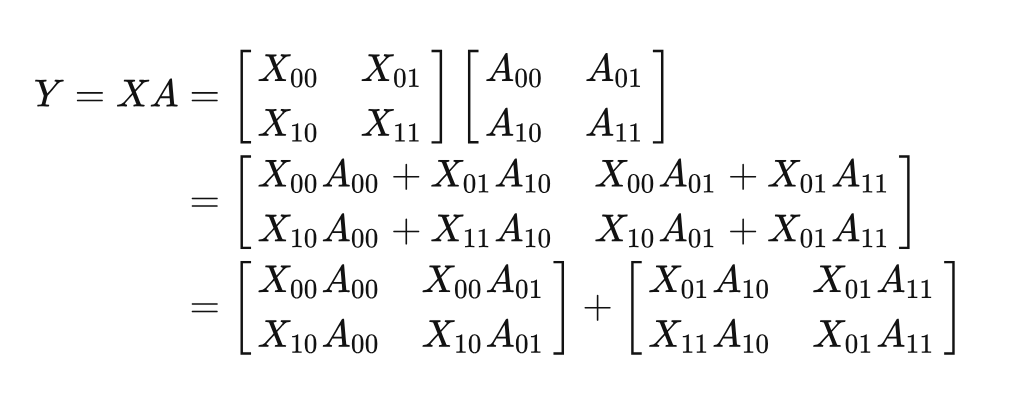
基于上面的矩陣乘法的變化,可以發(fā)現(xiàn)Y=XA可以分解為兩個矩陣相加。具體來說,兩個矩陣的結(jié)果仍然需要串行的計算。但是,單個矩陣中的4個子矩陣可以使用的處理器來并行計算。
當(dāng), 也就是第一步。對
進(jìn)行廣播, 所有的處理器均擁有這 4 個子矩陣。然后分別執(zhí)行。經(jīng)過這一步后就得到了第一個矩陣的結(jié)果。
當(dāng)。對
進(jìn)行廣播,各個處理器在分別計算。最終得到第二個矩陣的結(jié)果。
將兩個矩陣的結(jié)果相加。
(2) 2.5D張量并行
仍然是矩陣乘法, 并假設(shè)有個處理器, 將 X劃分為行和列。不妨設(shè), 將和分別劃分為
那么有
其中, concat 表示兩個矩陣的垂直拼接操作。
基于上面的推導(dǎo), 可以發(fā)現(xiàn)被拼接的兩個矩陣天然可以并行計算。即和可以并行計算。看到這里, 應(yīng)該就可以發(fā)現(xiàn)這兩個矩陣乘法就是上面的2D張量并行適用的形式。所以, 我們總計有個處理器, 每個處理器使用2D張量并行來處理對應(yīng)的矩陣乘法。最后, 將兩個2D張量并行的結(jié)果進(jìn)行拼接即可。
三、3D并行
總的來說,3D并行是由數(shù)據(jù)并行(DP)、張量并行(TP)和流水線并行(PP)組成。前面已經(jīng)分別介紹了TP和PP,ZeRO-DP是一種顯存高效的數(shù)據(jù)并行策略,原理見文章:
白強(qiáng)偉:【深度學(xué)習(xí)】【分布式訓(xùn)練】DeepSpeed:AllReduce與ZeRO-DP142
https://zhuanlan.zhihu.com/p/610587671
下面介紹如何將三種并行技術(shù)結(jié)合在一起,形成3D并行技術(shù)。
1. 一個3D并行的例子
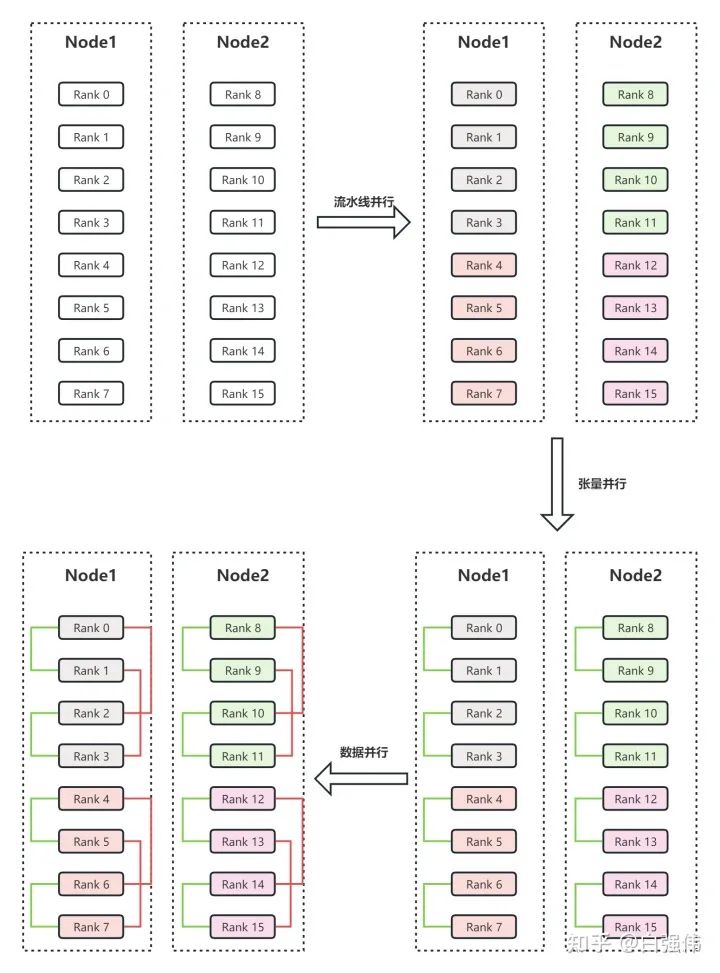
假設(shè)有兩個節(jié)點(diǎn)Node1和Node2,每個節(jié)點(diǎn)有8個GPU,共計16個GPU。16個GPU的編號分別為Rank0、Rank1、...、Rank15。此外,假設(shè)用戶設(shè)置流水線并行度為4,張量并行度為2。
流水線并行。流水線并行會將整個模型劃分為4份,這里稱為sub_model_1至sub_model_4。每連續(xù)的4張GPU負(fù)責(zé)一個sub_model。即上圖右上角中,相同顏色的GPU負(fù)責(zé)相同的sub_model。
張量并行。張量并行會針對流水線并行中的sub_model來進(jìn)行張量的拆分。即Rank0和Rank1負(fù)責(zé)一份sub_model_1,Rank2和Rank3負(fù)責(zé)另一份sub_model_1;Rank4和Rank5負(fù)責(zé)sub_model_2,Rank6和Rank7負(fù)責(zé)另一份sub_model_2;以此類推。上圖右下角中,綠色線條表示單個張量并行組,每個張量并行組都共同負(fù)責(zé)某個具體的sub_model。
數(shù)據(jù)并行。數(shù)據(jù)并行的目的是要保證并行中的相同模型參數(shù)讀取相同的數(shù)據(jù)。經(jīng)過流水線并行和張量并行后,Rank0和Rank2負(fù)責(zé)相同的模型參數(shù),所以Rank0和Rank2是同一個數(shù)據(jù)并行組。上圖左上角中的紅色線條表示數(shù)據(jù)并行組。
2. 3D并行分析
為什么3D并行需要按上面的方式劃分GPU呢?首先,模型并行是三種策略中通信開銷最大的,所以優(yōu)先將模型并行組放置在一個節(jié)點(diǎn)中,以利用較大的節(jié)點(diǎn)內(nèi)帶寬。其次,流水線并行通信量最低,因此在不同節(jié)點(diǎn)之間調(diào)度流水線,這將不受通信帶寬的限制。最后,若張量并行沒有跨節(jié)點(diǎn),則數(shù)據(jù)并行也不需要跨節(jié)點(diǎn);否則數(shù)據(jù)并行組也需要跨節(jié)點(diǎn)。
流水線并行和張量并行減少了單個顯卡的顯存消耗,提高了顯存效率。但是,模型劃分的太多會增加通信開銷,從而降低計算效率。ZeRO-DP不僅能夠通過將優(yōu)化器狀態(tài)進(jìn)行劃分來改善顯存效率,而且還不會顯著的增加通信開銷。
-
3D
+關(guān)注
關(guān)注
9文章
2864瀏覽量
107340 -
gpu
+關(guān)注
關(guān)注
28文章
4703瀏覽量
128725 -
流水線
+關(guān)注
關(guān)注
0文章
120瀏覽量
25629 -
模型
+關(guān)注
關(guān)注
1文章
3178瀏覽量
48730
原文標(biāo)題:一文捋順千億模型訓(xùn)練技術(shù):流水線并行、張量并行和3D并行
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于Transformer做大模型預(yù)訓(xùn)練基本的并行范式
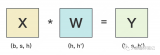
LabVIEW代碼加速之多核并行技術(shù)
基于流水線負(fù)載平衡模型的并行爬蟲研究
基于流水線技術(shù)的并行高效FIR濾波器設(shè)計
基于流水線的并行FIR濾波器設(shè)計
CPU流水線的定義
嵌入式_流水線

GTC 2023:深度學(xué)習(xí)之張星并行和流水線并行
以Gpipe作為流水線并行的范例進(jìn)行介紹
Google GPipe為代表的流水線并行范式
大模型分布式訓(xùn)練并行技術(shù)(一)-概述
基于PyTorch的模型并行分布式訓(xùn)練Megatron解析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論