") 選擇合適的工具——輕松玩轉(zhuǎn)AI
選擇合適的工具——輕松玩轉(zhuǎn)AI
啟動人工智能應用從來沒有像現(xiàn)在這樣容易!受益于像Xilinx Zynq UltraScale+ MPSoC 這樣的FPGA,AI現(xiàn)在也可以離線使用或在邊緣部署、使用。瑞蘇盈科核心板模塊結(jié)合Vitis AI開發(fā)工具給用戶提供了便利工具,可用于開發(fā)和部署用于實時推理的機器學習應用,因此將AI集成到應用中變得輕而易舉。圖像檢測或分類、模式或語音識別推動了制造業(yè)、醫(yī)療、汽車和金融服務等產(chǎn)業(yè)的升級。
快速開啟基于AI的FPGA應用
ENCLUSTRA
人工智能正在占據(jù)越來越多的應用和生活場景,例如圖像檢測和分類,翻譯和推薦系統(tǒng)等等。基于機器學習技術(shù)的應用數(shù)量龐大且還在不斷增長。采用瑞蘇盈科結(jié)合FPGA和ARM處理器的核心板模塊,在離線和邊緣使用AI前所未有的容易。
人工智能(AI)歷史悠久,自1955年便被公認為一門學科。人工智能是計算機模仿人類智能、從經(jīng)驗中學習、適應新信息并執(zhí)行類似人類活動的能力。人工智能的應用包括專家系統(tǒng)、自然語言處理(NLP)、語音識別和機器視覺。
AI的復興
ENCLUSTRA
在經(jīng)歷了幾波樂觀和失望之后,人們對人工智能產(chǎn)生了新的興趣,而且越來越感興趣。在過去15年左右的時間里,成千上萬的人工智能初創(chuàng)公司成立了,而且速度在不斷增長。這背后有幾個驅(qū)動因素:可能最重要的一個是現(xiàn)在可以以承擔得起的價格獲得巨大的計算能力。不僅硬件更快,而且現(xiàn)在每個人都可以訪問云中的超級計算機。這使得運行人工智能所需的硬件平臺變得大眾化,使得初創(chuàng)企業(yè)得以大量涌現(xiàn)。
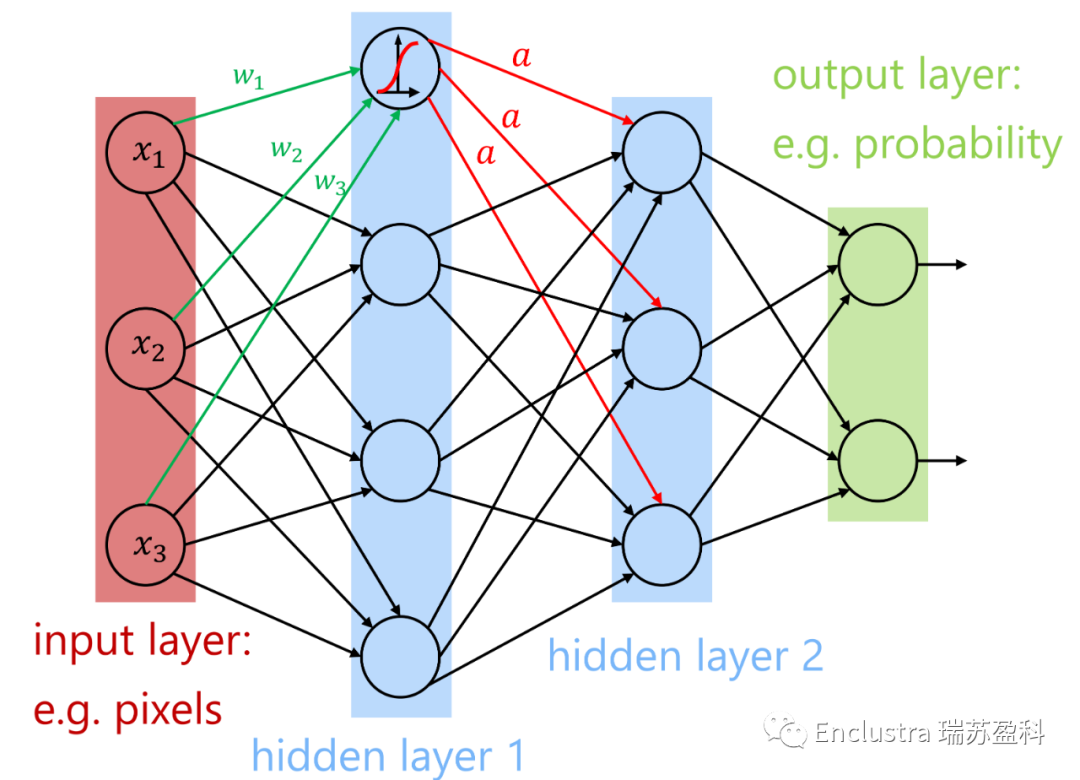
圖1:一種具有2個隱含層的前饋人工神經(jīng)網(wǎng)絡的簡化視圖
ENCLUSTRA
人工神經(jīng)網(wǎng)絡(圖1)現(xiàn)在擴展到幾十到幾百個隱藏層節(jié)點(圖2)。即使是有10000個隱藏層的網(wǎng)絡也已經(jīng)實現(xiàn)了。這種進化正在增加神經(jīng)網(wǎng)絡的抽象能力,并使新的應用成為可能。如今,神經(jīng)網(wǎng)絡可以在數(shù)萬個CPU或GPU核上進行訓練,大大加快了開發(fā)廣義學習模型的過程。
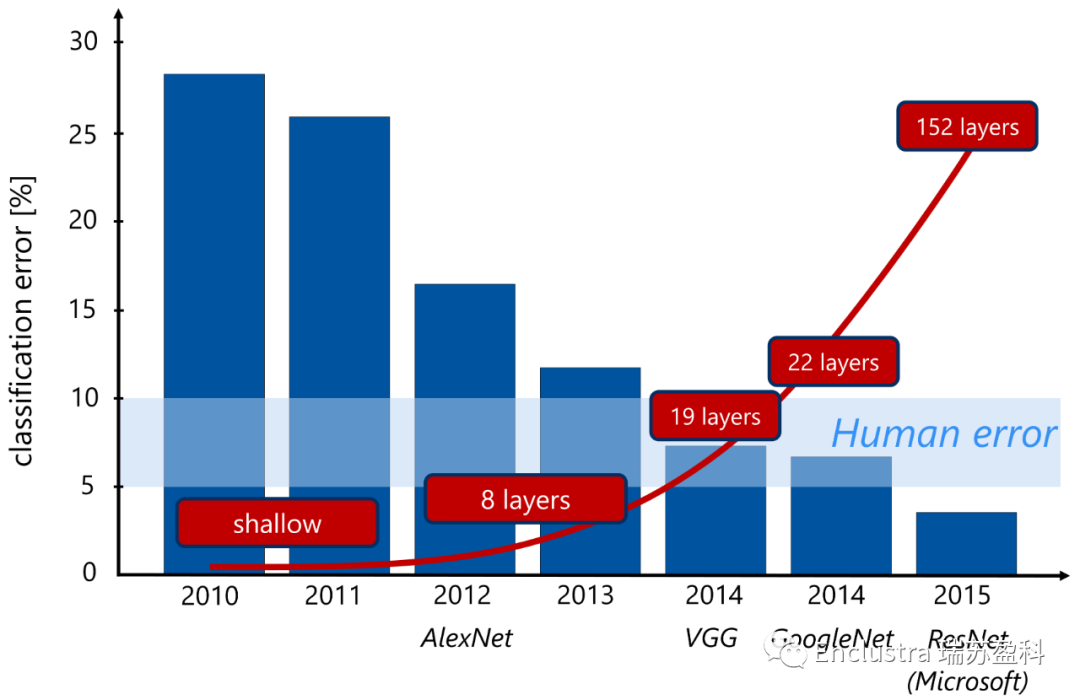
圖2:ImageNet識別挑戰(zhàn)獲勝者展示了在新的神經(jīng)網(wǎng)絡架構(gòu)中不斷增加的隱藏層
ENCLUSTRA
人們對人工智能興趣增加的另一個原因是近年來機器學習方面的突破性進展。這有助于吸引科技投資和初創(chuàng)企業(yè)的興趣,進一步加速人工智能的發(fā)展和完善。
機器如何學習
ENCLUSTRA
人工神經(jīng)網(wǎng)絡是一種受人腦啟發(fā)的計算模型。它由一個簡單的處理單元相互連接的網(wǎng)絡組成,這些網(wǎng)絡可以通過修改它們的連接來學習經(jīng)驗(圖1)。所謂的深度神經(jīng)網(wǎng)絡(DNN -具有許多隱藏層的神經(jīng)網(wǎng)絡)目前為許多大型計算問題提供了最佳解決方案。
目前應用最廣泛的深度學習系統(tǒng)是卷積神經(jīng)網(wǎng)絡(Convolutional Neural Network, CNNs)。這些系統(tǒng)使用前饋的人工神經(jīng)元網(wǎng)絡將輸入特征映射到輸出,他們使用反向饋入系統(tǒng)進行學習(即訓練),并產(chǎn)生一組權(quán)重來校準CNN(反向傳播,圖3)。
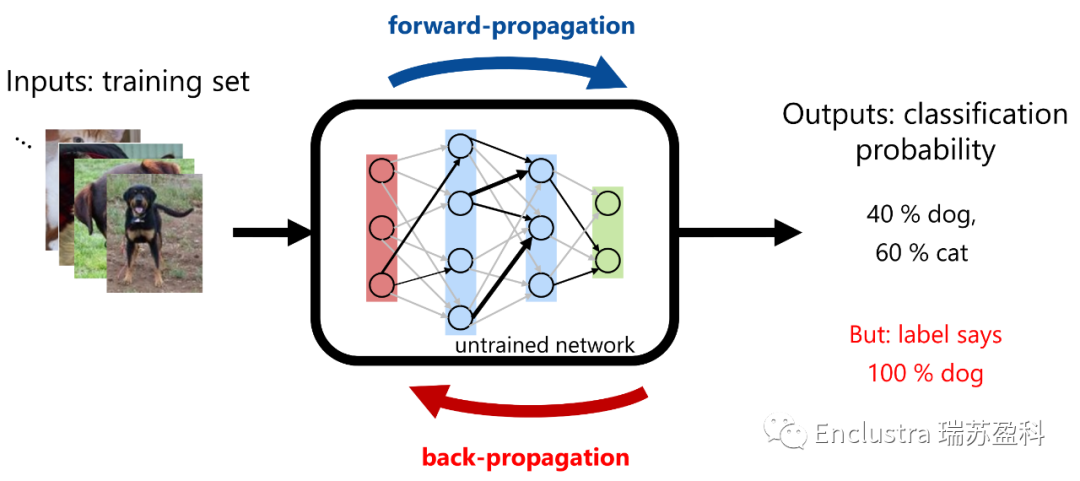
圖片圖3:神經(jīng)網(wǎng)絡需要經(jīng)過訓練來學習如何解決問題或挑戰(zhàn)
ENCLUSTRA
機器學習中計算強度最大的過程是訓練神經(jīng)網(wǎng)絡。對于一個最先進的網(wǎng)絡來說,它可能需要數(shù)天到數(shù)周的時間,需要數(shù)十億的浮點計算和大量的訓練數(shù)據(jù)(GByte到數(shù)百GByte),直到網(wǎng)絡達到所需的精度。幸運的是,這個步驟在大多數(shù)情況下都不需要時間限制,并且可以轉(zhuǎn)移到云上。
當網(wǎng)絡接受訓練時,它可以被輸入一個新的、未標記的數(shù)據(jù)集,并根據(jù)它之前學習的數(shù)據(jù)對數(shù)據(jù)進行分類。這一步稱為推斷,是開發(fā)應用的實際目標。
告訴我你看到了什么
ENCLUSTRA
輸入的分類可以在云中進行,也可以在邊緣(大部分是離線)進行。雖然通過神經(jīng)網(wǎng)絡處理數(shù)據(jù)通常需要專用加速器(FPGA、GPU、DSP或ASIC),但額外的任務最好由CPU處理,CPU可以用傳統(tǒng)的編程語言編程。這就是帶有集成CPU(所謂的片上系統(tǒng)(SoC))的FPGA的優(yōu)勢所在,尤其是在邊緣。SoC將推理加速器(FPGA陣列)和CPU組合在一塊芯片中。CPU運行控制算法和數(shù)據(jù)流管理。同時,與基于GPU或ASIC的解決方案相比,F(xiàn)PGA提供了許多優(yōu)勢,其中包括易于集成多個接口和傳感器,以及適應新神經(jīng)網(wǎng)絡架構(gòu)的靈活性(圖4)。
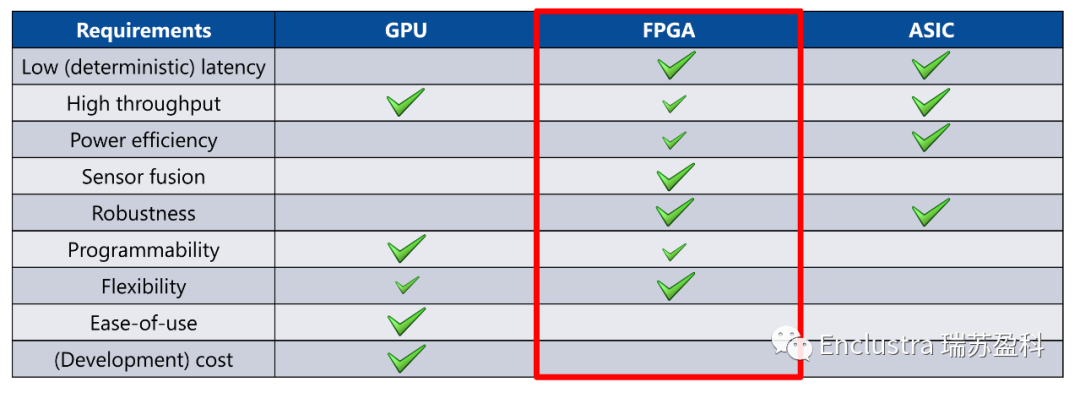
圖4:人工智能推理應用的不同技術(shù)的比較
ENCLUSTRA
FPGA固有的可重構(gòu)性也使其能夠利用不斷演化的神經(jīng)網(wǎng)絡拓撲、更新的傳感器類型和配置,以及更新的軟件算法。使用SoC可以在需要時保證低而確定的延遲,例如,用于實時對象檢測。同時,SoC也非常節(jié)能。從FPGA中獲得最佳性能的主要挑戰(zhàn)是在不失去精度的情況下將浮點模型有效地映射到定點FPGA實現(xiàn)(圖5),這就是供應商工具的作用所在。
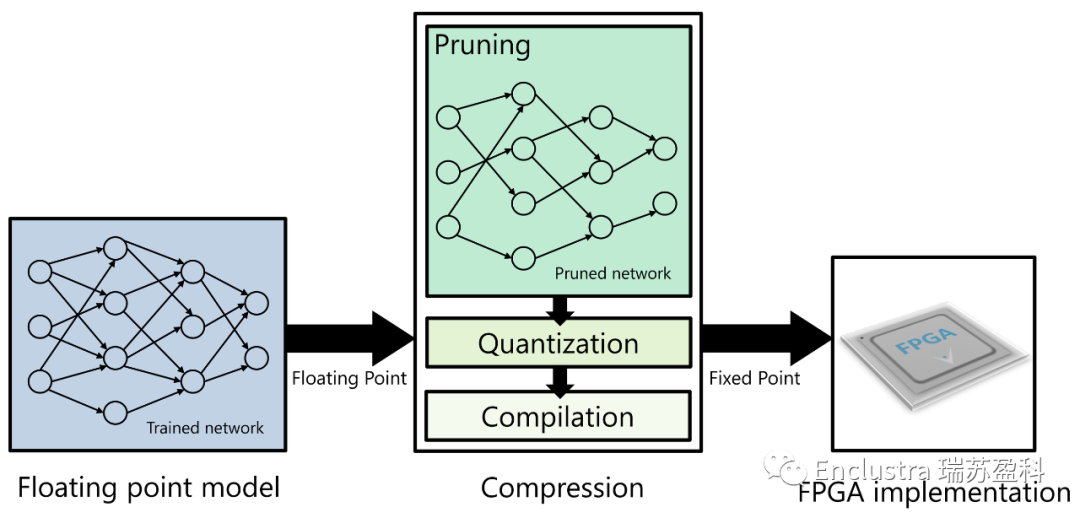
圖5:將浮點模型有效映射到定點FPGA實現(xiàn)的過程稱為壓縮
選擇合適的工具
ENCLUSTRA
現(xiàn)在有很多工具可以幫助我們降低實現(xiàn)第一個AI項目的門檻。例如,VitisAI開發(fā)工具為用戶提供了在FPGA上開發(fā)和部署用于實時推理的機器學習應用程序的工具。它們支持許多常見的機器學習框架,如Caffe和TensorFlow,PyTorch支持也將很快推出。它們使最先進的神經(jīng)網(wǎng)絡能夠有效適應FPGA,用于嵌入式人工智能應用(圖5)。
ENCLUSTRA
結(jié)合標準的核心板模塊(SoM),如瑞蘇盈科的火星XU3(圖6)(基于Xilinx Zynq UltraScale+ MPSoC),插入火星ST3底板,人工智能應用可以比以往更快地實現(xiàn)(圖7)。
 圖7:已被業(yè)界證實的人工智能應用解決方案,基于Xilinx Zynq UltraScale+ MPSoC
圖7:已被業(yè)界證實的人工智能應用解決方案,基于Xilinx Zynq UltraScale+ MPSoC
ENCLUSTRA
為了展示這種組合的性能和快速上市能力,瑞蘇盈科在短短幾天內(nèi)開發(fā)了一個基于人工智能的圖像識別系統(tǒng)。這些圖像是用一個連接到火星ST3底板的標準USB攝像頭拍攝的。如需更高的性能,可使用底板上的MIPI接口。
該神經(jīng)網(wǎng)絡以低延遲的方式對圖像進行分類、在火星XU3核心板模塊上運行。該系統(tǒng)支持流行的神經(jīng)網(wǎng)絡如ResNet-50和DenseNet,兩者分別用于圖像分類和實時人臉檢測。
單個FPGA模塊不僅可以運行神經(jīng)網(wǎng)絡推理,還可以并行處理許多其他任務,如與主機PC和其他外圍設備通信。而且,同時控制各種高動態(tài)驅(qū)動器是FPGA技術(shù)發(fā)揮其優(yōu)勢的地方。例如,添加瑞蘇盈科通用驅(qū)動控制器IP核來控制無刷直流電機或步進電機將是輕而易舉的事。在邊緣利用AI的力量從未如此容易,所以,即刻開啟您的項目吧!
-
FPGA
+關(guān)注
關(guān)注
1626文章
21667瀏覽量
601843 -
模塊
+關(guān)注
關(guān)注
7文章
2671瀏覽量
47340 -
AI
+關(guān)注
關(guān)注
87文章
30146瀏覽量
268411 -
人工智能
+關(guān)注
關(guān)注
1791文章
46858瀏覽量
237556
發(fā)布評論請先 登錄
相關(guān)推薦
如何選擇合適的電機驅(qū)動芯片

安森美系統(tǒng)設計工具介紹
ECU故障診斷工具 如何選擇合適的ECU
如何選擇合適的UWB模塊
如何選擇合適的AI云平臺

顯存技術(shù)不斷升級,AI計算中如何選擇合適的顯存
如何選擇合適的過載保護器
OOTDiffusion整合包一鍵AI換裝, 免費生成高端服裝模特照! 電商必備省錢工具!
如何選擇合適的邊緣ai分析一體機解決方案

如何根據(jù)需求選擇合適的新加坡VPS操作系統(tǒng)?

泰來三維|如何輕松玩轉(zhuǎn)三維掃描儀中手持快速掃描模式

如何選擇合適的伺服聯(lián)軸器?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論