") 什么是模擬人工智能,模擬人工智能的優(yōu)勢
什么是模擬人工智能,模擬人工智能的優(yōu)勢
作者:Jean-Jaques (JJ) DeLisle
機(jī)器學(xué)習(xí) (ML) 和人工智能 (AI) 技術(shù)(通常稱為 AI)是現(xiàn)代投資最多的領(lǐng)域之一。預(yù)計(jì)在短短幾年內(nèi),人工智能技術(shù)和功能將被集成到大量的邊緣設(shè)備和自治系統(tǒng)中,以及基于云的和生成式人工智能服務(wù)的增長格局中。
然而,人工智能無處不在并非沒有成長的痛苦。在許多方面,大型語言模型 (LLM)、自然語言處理、語音識別、強(qiáng)化學(xué)習(xí)和其他系統(tǒng)背后的深度神經(jīng)網(wǎng)絡(luò) (DNN) 技術(shù)使用大量存儲、內(nèi)存和處理作為創(chuàng)建有效 AI 技術(shù)的捷徑。
這里的前提是,與依賴數(shù)學(xué)效率和優(yōu)化的早期ML / AI模型開發(fā)相比,可以使用更大的訓(xùn)練集和計(jì)算資源來創(chuàng)建更準(zhǔn)確和有用的模型。OpenAI發(fā)布的一項(xiàng)分析顯示,AI開發(fā)中使用的計(jì)算資源每3.4個(gè)月翻一番,而摩爾定律在計(jì)算能力方面的進(jìn)步每2年僅翻一番。因此,在某個(gè)點(diǎn)上,計(jì)算能力的改進(jìn)將被當(dāng)前AI訓(xùn)練和推理范式的需求所超越。
為了保持競爭力并在邊緣實(shí)現(xiàn) AI 技術(shù),這種方法需要妥協(xié)以滿足邊緣系統(tǒng)的尺寸、重量、成本和能源使用要求。其中一些折衷包括降低數(shù)字AI模型中使用的數(shù)據(jù)的分辨率。此外,降低分辨率對AI能源和復(fù)雜性的節(jié)省存在實(shí)際限制。GPU 已成為執(zhí)行 AI 訓(xùn)練和推理任務(wù)所需的大型矩陣操作的流行選擇,因?yàn)?GPU 在執(zhí)行大型矩陣計(jì)算方面比 CPU 更強(qiáng)大、更節(jié)能。
然而,對于基于馮諾依曼架構(gòu)的數(shù)字計(jì)算方法,這些系統(tǒng)的處理速度不可避免地存在實(shí)際限制。這是一種稱為馮諾依曼瓶頸的現(xiàn)象,其中處理速度受到從內(nèi)存到處理單元的數(shù)據(jù)傳輸速率的限制。
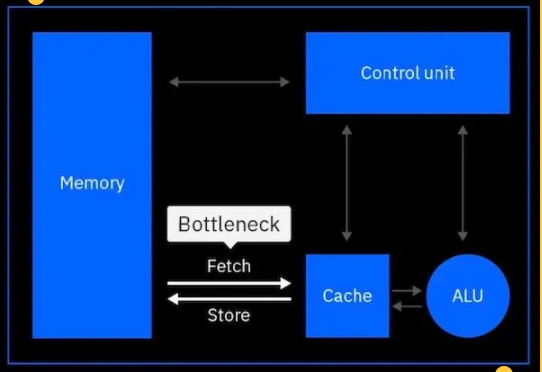
圖1以下是傳統(tǒng)的馮·諾依曼架構(gòu)如何受到大量數(shù)據(jù)移動(dòng)的瓶頸。來源:IBM
輸入模擬
上述事實(shí)是IBM和其他AI技術(shù)公司(如Mythic AI)押注模擬AI用于邊緣AI訓(xùn)練和推理的未來的基礎(chǔ)。一些行業(yè)消息人士聲稱,模擬人工智能技術(shù)可能比數(shù)字人工智能技術(shù)快幾十到幾百倍,效率更高,這將允許在能源受限的邊緣設(shè)備中大幅提高人工智能處理能力。
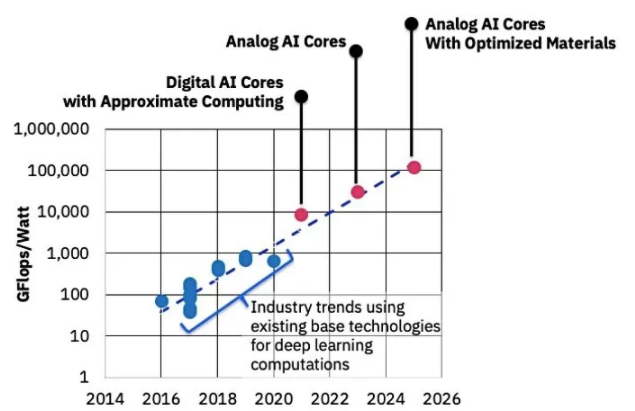
圖2該圖表比較了 2014 年至 2026 年當(dāng)前和近期的數(shù)字 AI 和模擬 AI 硬件技術(shù)及其每瓦性能。來源:IBM
數(shù)字處理技術(shù)依賴于打包為離散值的數(shù)據(jù),每個(gè)位存儲在指定的晶體管或存儲單元中,而模擬處理技術(shù)可以利用存儲在單個(gè)晶體管或存儲單元中的連續(xù)信息。僅此功能就允許模擬處理技術(shù)在更小的空間內(nèi)存儲更多數(shù)據(jù),但通過隨機(jī)錯(cuò)誤注入犧牲了存儲數(shù)據(jù)的可變性。
模擬存儲的可變性可能導(dǎo)致前向傳播(推理)失配誤差,以及反向傳播(訓(xùn)練計(jì)算誤差)。兩者都不是可取的,但可以使用數(shù)字電路和模擬電路來解釋這種誤差,以確保最小的誤差,以及其他人工智能訓(xùn)練技術(shù)來減輕反向傳播誤差。
對于人工神經(jīng)網(wǎng)絡(luò)(ANN),現(xiàn)在可以管理這種可變性。從歷史上看,模擬存儲的可變性是數(shù)字計(jì)算技術(shù)最初在半個(gè)多世紀(jì)前取代模擬計(jì)算技術(shù)的原因,因?yàn)榇蠖鄶?shù)計(jì)算系統(tǒng)都需要更高的精度。
模擬人工智能的優(yōu)點(diǎn)
ANN模擬計(jì)算的其他優(yōu)點(diǎn)包括乘法累加運(yùn)算,這是ANN計(jì)算中最常用的運(yùn)算,可以使用電動(dòng)力學(xué)的物理特性來完成,例如用于乘法的歐姆定律和用于求和的基爾霍夫定律。這允許模擬計(jì)算機(jī)將輸入作為數(shù)組處理并并行執(zhí)行全矩陣操作。這可能比使用 CPU 甚至 GPU 的矩陣計(jì)算更快、更高效。
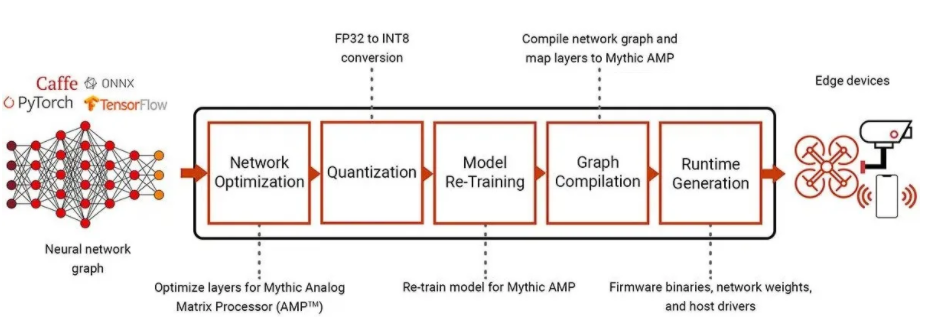
圖3圍繞Pytorch,Caffe和TensorFlow等標(biāo)準(zhǔn)框架構(gòu)建的AI工作流程使用模擬矩陣處理器進(jìn)行部署。
模擬計(jì)算技術(shù)的另一個(gè)優(yōu)點(diǎn)是,這些解決方案可以利用不同的存儲單元技術(shù),例如相變材料(PCM)和數(shù)字閃存,作為可變電阻而不是開關(guān)運(yùn)行。這些模擬存儲方法允許在同一位置進(jìn)行計(jì)算和存儲,而無需持續(xù)使用電源來維護(hù)數(shù)據(jù)存儲。
這些因素意味著模擬計(jì)算/存儲中不存在馮諾依曼瓶頸,模擬數(shù)據(jù)存儲本質(zhì)上是被動(dòng)的,隨著時(shí)間的推移,與主動(dòng)數(shù)字?jǐn)?shù)據(jù)存儲相比,使用的能量要少得多。例如,PCM的工作原理是材料的電導(dǎo)率是PCM存儲單元內(nèi)無定形與結(jié)晶狀態(tài)之比的函數(shù)。
對于IBM的PCM技術(shù),較低的電流編程狀態(tài)導(dǎo)致更低的電阻和更多的晶體結(jié)構(gòu),其中較高的編程電流導(dǎo)致更多的非晶材料在更高的電阻下。這就是為什么PCM數(shù)據(jù)存儲相對非易失性的原因,以及ANN突觸權(quán)重如何存儲為單個(gè)PCM單元的電導(dǎo)上限和電導(dǎo)下限之間的連續(xù)統(tǒng)一體,而不是幾個(gè)晶體管或其他數(shù)字存儲單元上的多個(gè)位。
因此,毫不奇怪,對于能源/處理受限系統(tǒng)上的邊緣計(jì)算推理和 AI 培訓(xùn),模擬 AI 技術(shù)正在成為一種解決方案,無需訪問廣泛的云 AI 基礎(chǔ)設(shè)施和互聯(lián)網(wǎng)連接即可帶來 DNN 的優(yōu)勢。這將導(dǎo)致響應(yīng)更快、更高效、更有能力的邊緣人工智能更適合自主應(yīng)用,如機(jī)器人、完全自動(dòng)駕駛、安全,甚至認(rèn)知無線電/通信。
編輯:黃飛
-
數(shù)據(jù)傳輸
+關(guān)注
關(guān)注
9文章
1853瀏覽量
64499 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4765瀏覽量
100568 -
人工智能
+關(guān)注
關(guān)注
1791文章
46896瀏覽量
237672 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8382瀏覽量
132444
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論