 Stable Diffusion的完整指南:核心基礎知識、制作AI數字人視頻和本地部署要求
Stable Diffusion的完整指南:核心基礎知識、制作AI數字人視頻和本地部署要求
★Stable Diffusion;stable;diffusion;SD;stablediffussion;sadtalker;PC集群;PC Farm;PC農場;GPU集群;GAN;VAE;latent;AI繪圖;AI文生圖;文生圖;圖生圖;虛擬數字人;數字人;PNDM;DDIM;U-Net;prompt;CLIP;diffusers;pipeline;NVIDIA RTX GeForce 3070;NVIDIA RTX GeForce 3080;NVIDIA RTX GeForce 4070;NVIDIA RTX GeForce 4060;i9-13900;i7-13700;i5 13400;i3 12100;i7 12700 ;i9 12900
在當今的數字時代,人工智能正在逐步改變人們的生活和工作方式。其中,Stable Diffusion作為一種深度學習技術,受到廣泛關注。它能夠通過對圖像或視頻進行處理,生成逼真的數字人視頻,為許多領域帶來創新。本文將介紹Stable Diffusion的核心基礎知識、如何使用它制作AI數字人視頻、本地部署的要求以及藍海大腦PC集群解決方案的應用。
Stable Diffusion是一種擴散模型(diffusion model)的變體,叫做“潛在擴散模型”(latent diffusion model; LDM)。擴散模型是在2015年推出的,其目的是消除對訓練圖像的連續應用高斯噪聲,可以將其視為一系列去噪自編碼器。Stable Diffusion由3個部分組成:變分自編碼器(VAE)、U-Net和一個文本編碼器。添加和去除高斯噪聲的過程被應用于這個潛在表示,然后將最終的去噪輸出解碼到像素空間中。在前向擴散過程中,高斯噪聲被迭代地應用于壓縮的潛在表征。每個去噪步驟都由一個包含殘差神經網絡(ResNet)中間的U-Net架構完成,通過從前向擴散往反方向去噪而獲得潛在表征。最后,VAE解碼器通過將表征轉換回像素空間來生成輸出圖像。
SadTalker模型是一個使用圖片與音頻文件自動合成人物說話動畫的開源模型。給模型一張圖片以及一段音頻文件,模型會根據音頻文件把傳遞的圖片進行人臉的相應動作,比如張嘴,眨眼,移動頭部等動作。它從音頻中生成 3DMM 的 3D 運動系數(頭部姿勢、表情),并隱式調制一種新穎的 3D 感知面部渲染,用于生成說話的頭部運動視頻。
在進行Stable Diffusion本地部署時,需要滿足一定的硬件和軟件要求。首先,需要具備高性能的GPU集群,以支持大規模的模型訓練和推理。同時,需要安裝相應的軟件環境,包括深度學習框架、Python編程語言和模型庫等。此外,還需要具備相應的網絡帶寬和穩定性,以保證模型的下載和更新。
針對本地部署的硬件和軟件要求,藍海大腦高效、可靠和經濟的PC集群解決方案采用高性能GPU節點和高速網絡互聯,能夠滿足大規模模型訓練和推理的需求。同時,該方案提供多種深度學習框架和模型庫,方便用戶進行模型的訓練和推理。此外,藍海大腦PC集群解決方案還提供全面的安全防護措施,包括數據加密、訪問控制和安全審計等,以確保用戶數據的安全性和隱私性。
Stable Diffusion完整核心基礎知識
2022年AI圖像生成領域迎來重大突破!Stable Diffusion橫空出世,一舉擊敗傳統深度學習,成為開啟人工智能新紀元的強力引擎。它的出現既為工業界帶來革命性創新,也讓投資者看到巨大商機,AI再次變得"性感"起來。下面將以通俗易懂的語言,向大家全方位講解Stable Diffusion的原理、應用和訓練技巧。
一、Stable Diffusion核心基礎內容
1、Stable Diffusion模型原理
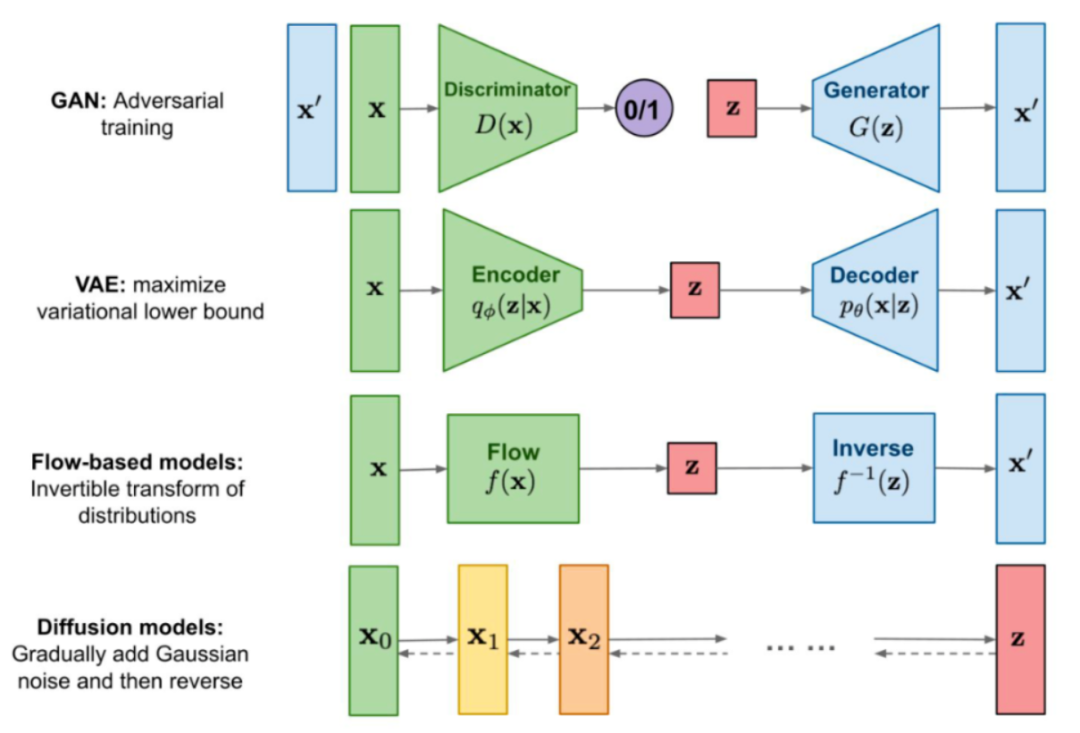
生成式模型可謂是AI界的“制假大師”,能生成看似真實的新數據。其中,GAN和Stable Diffusion可以說是翹楚級的作品。這兩類模型通過不同的技巧,可以捕捉訓練數據的特征分布,然后生成類似風格的新樣本。比如在計算機視覺領域,可以輸出樣子逼真的新圖片;在自然語言處理領域,可以寫出語義連貫的新文字。
GAN通過對抗訓練實現,讓生成器和判別器互相競爭,不斷逼近真實數據分布。而Stable Diffusion無需對抗,直接利用文本提示指導模型生成所需的輸出。可以說,GAN和Stable Diffusion如同變色龍,可根據需求變換不同的創作形態。為人類開拓一個廣闊的想象空間,任何靈感都可以通過生成式模型試驗實現,將抽象概念轉換為具體作品。生成式模型助力人類創造力的釋放和拓展,正在引領一個前所未有的創作新時代。
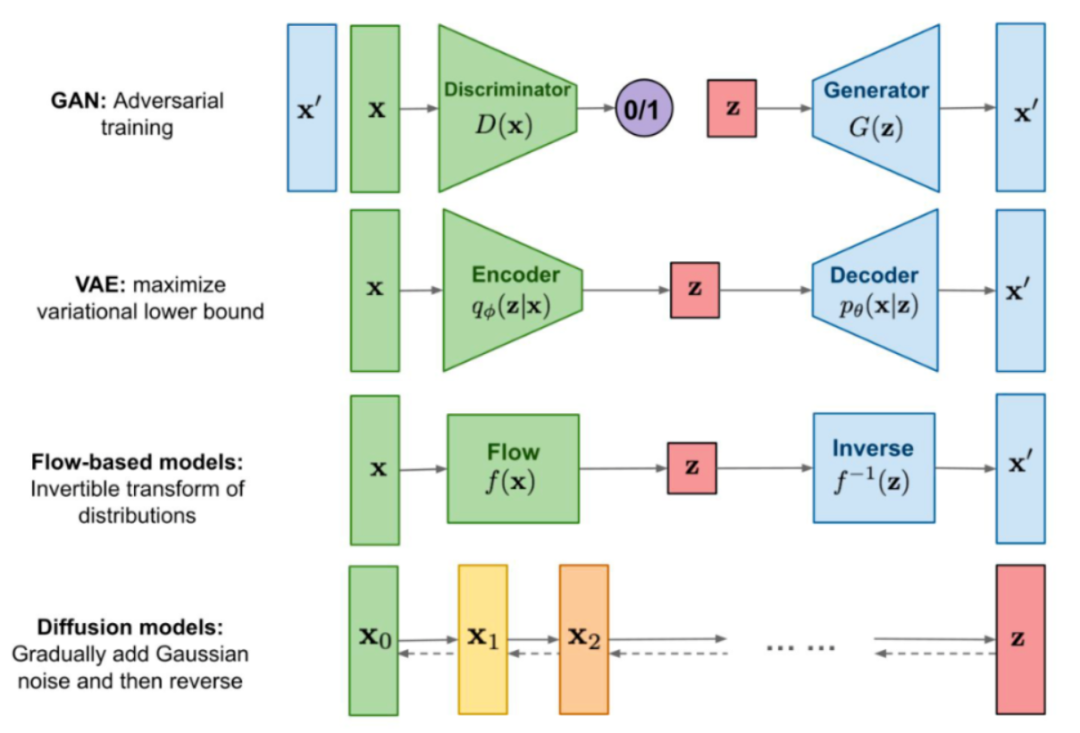
生成式模型的主流架構
下面主要就GAN詳細描述。由于篇幅原因,VAE和Flow-based models這里就不過多介紹。GAN的訓練過程可比喻為一場精妙的舞臺表演。表演由兩大角色聯手完成——生成器與判別器。生成器扮演制作“假貨”的角色,生成盡可能逼真的假數據來欺騙判別器。判別器則扮演辨別真偽的角色,判斷生成器輸出的數據是真是假。
兩者之間展開一場激烈的智慧競賽。生成器不斷提升自己的造假技術,使生成的假數據更加真實。判別器也在競相增強自身的判斷能力,來識別假數據的破綻。雙方都在以極快的速度成長。要取得最佳的生成效果,生成器和判別器必須同步訓練。這也增加了GAN的訓練難度。在訓練初期,生成器制造的假數據非常容易被判別器識破。但隨著訓練輪數的增多,生成器的造假水平越來越高,判別器也必須不斷自我革新來跟上生成器的進步。
這里可以把生成器比喻為高明的畫家,不斷精進繪畫技巧來制作逼真的藝術品。判別器則像鑒賞家,需要提高自己的審美和識別能力,才能判斷畫作的真偽。兩者互相促進,最終畫家可以畫出真假難辨的作品。GAN訓練過程中充滿智慧的對抗與不斷深化的博弈。表面上雙方合作煥然一新,實際都在暗地努力進步。最終,生成器取得決定性優勢,其生成效果達到欺騙判別器的視真程度。

SD文生圖過程
Stable Diffusion (SD)模型在圖像生成任務上有著廣泛的應用。其中最典型和基礎的兩大應用分別是文生圖和圖生圖。
文生圖(Text-to-Image)是將文本描述轉換為圖像的過程。可以輸入一段文字到Stable Diffusion模型中,描述想要生成的圖像內容。模型會解析文本語義,經過迭代逐步生成出符合文本描述的圖片。例如,輸入“天堂,巨大的,海灘”等文字,模型會聯想到天堂與海灘的概念,并圖像化出一個美麗寬廣的沙灘場景。文本描述越細致,生成的圖像也會越符合預期。

SD圖生圖過程
圖生圖(Image-to-Image)在文生圖的基礎上,額外輸入一張圖像,根據文本描述對圖片進行修飾和豐富。例如,先輸入“天堂,巨大的,海灘”,生成一張美麗沙灘的圖片。然后繼續輸入“海盜船”,同時輸入先前生成的沙灘圖。模型將解析文本語義,在原圖片中添加一個海盜船,輸出一張融合文本描述的新圖像。可以看出,圖生圖保留原圖片的主體內容,同時根據文本提示進行圖像的二次創作。
感受SD模型強大的生成能力,大家可能會想到生成式領域上一個霸主模型GAN,與GAN模型不同的是,SD模型是屬于擴散模型,是基于latent的擴散模型。那么擴散模型是什么呢?擴散模型是一種圖像生成方法,通過逐步添加細節來生成圖像。將圖像的生成過程分為多個步驟,每個步驟都會對圖像進行一定程度的修改和完善,這樣經過20-50次“擴散”循環后,最終輸出的圖像就會變得更加精致。
下面是一個通過 SD 模型的推理過程, 將隨機高斯噪聲矩陣逐步去燥并生成一張小別墅圖片的直觀示例。

SD模型的Inference過程
那么latent又是什么呢?基于 latent 的擴散模型在低維隱空間中進行“擴散”過程,而不是在實際像素空間中,大大降低了內存占用和計算復雜性。與常規擴散模型不同,latent 擴散模型的主要特點是在訓練和推理過程中都集中在 latent 空間中。
2、Stable Diffusion模型的核心組件
SD模型主要由自動編碼器(VAE),U-Net以及文本編碼器三個核心組件構成。
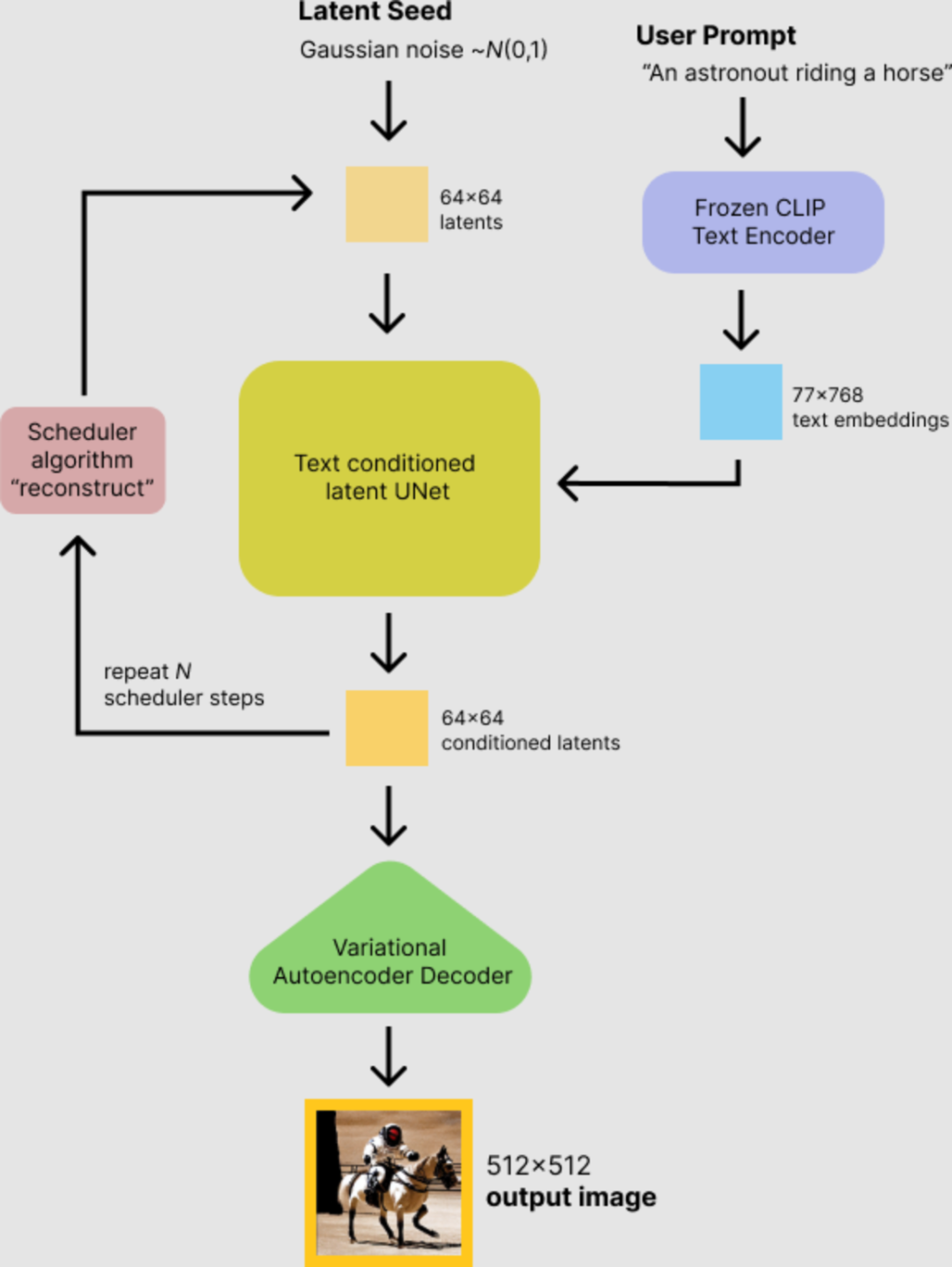
SD模型文生圖流程
1)自動編碼器(VAE)
在圖像生成任務中,VAE的編碼器可以將輸入圖片轉換為低維的特征表示,作為后續模型的輸入。這些低維特征保留原圖像的主要語義信息。而VAE的解碼器則可以將編碼器輸出的低維特征再次恢復為完整的圖像。解碼器實現了從壓縮特征到圖像空間的映射。不同的VAE結構設計,會使其在圖像中的注意力區域不同,從而影響生成圖片的細節與整體顏色風格。
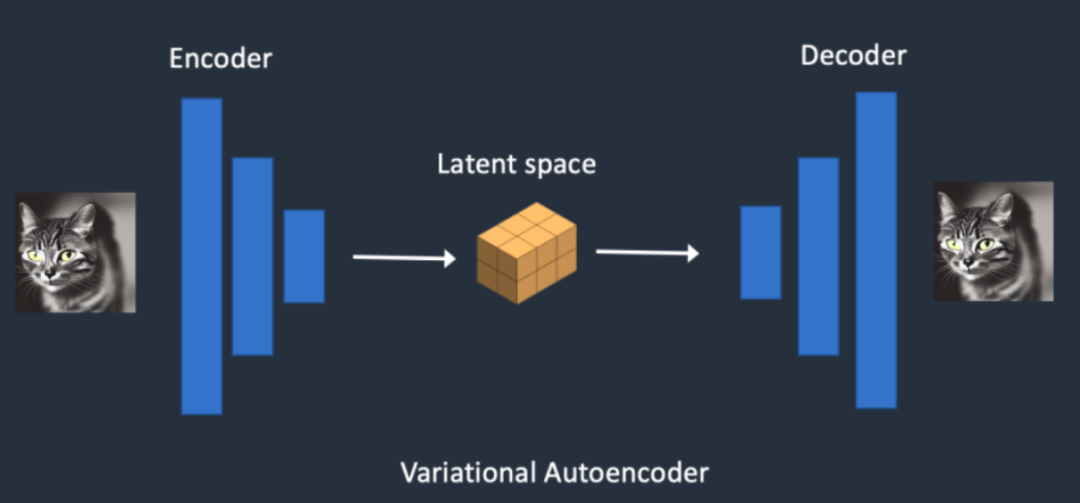
VAE的主要工作
VAE能夠高效壓縮圖像到低維潛空間后仍實現良好重建,其關鍵在于自然圖像具有高度規律性。例如,人臉圖像中眼睛、鼻子、嘴巴遵循特定空間結構;貓身體有固定數量四肢以及特定生物學形態。這種先驗知識使得VAE可以只保留圖像最關鍵信息。即使在壓縮特征損失的情況下,只要生成圖像大小合適,重建后的語義內容和結構依然能夠保持可識別性。
2)U-Net
在擴散模型生成流程中,需要逐步將隨機噪聲轉化為圖像隱特征。實現方式是:
- 模型預測當前噪聲的殘差,即需要調整的量。
- 利用調度算法(如PNDM、DDIM等)結合預測殘差,重新構建并優化噪聲。
- 經過多輪擴散優化,最終得到可生成目標圖像的隱特征。
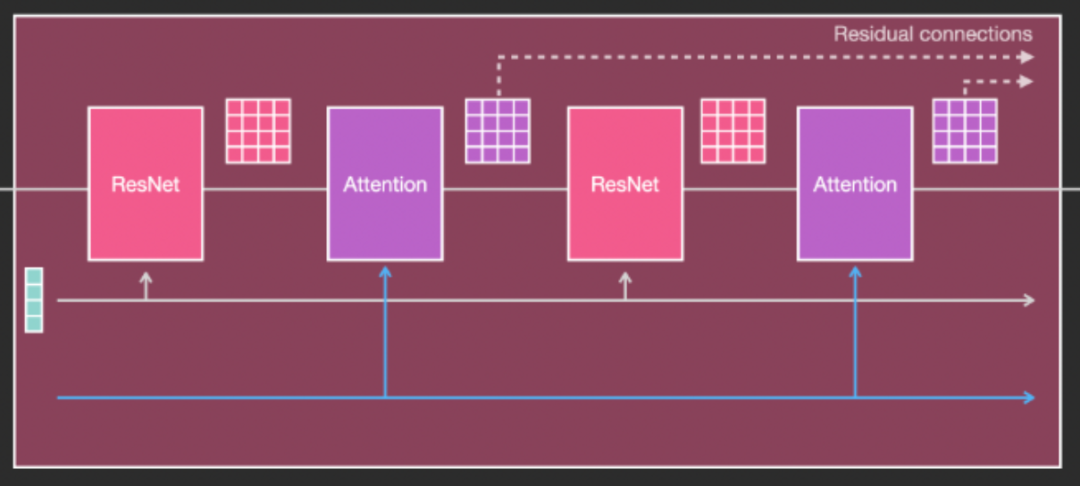
實現擴散模型的網絡結構通常采用U-Net架構。U-Net由多層ResNet模塊串聯構成,并在模塊之間添加交叉注意力機制。交叉注意力可用于接收額外的文本指令,指導圖像生成方向。
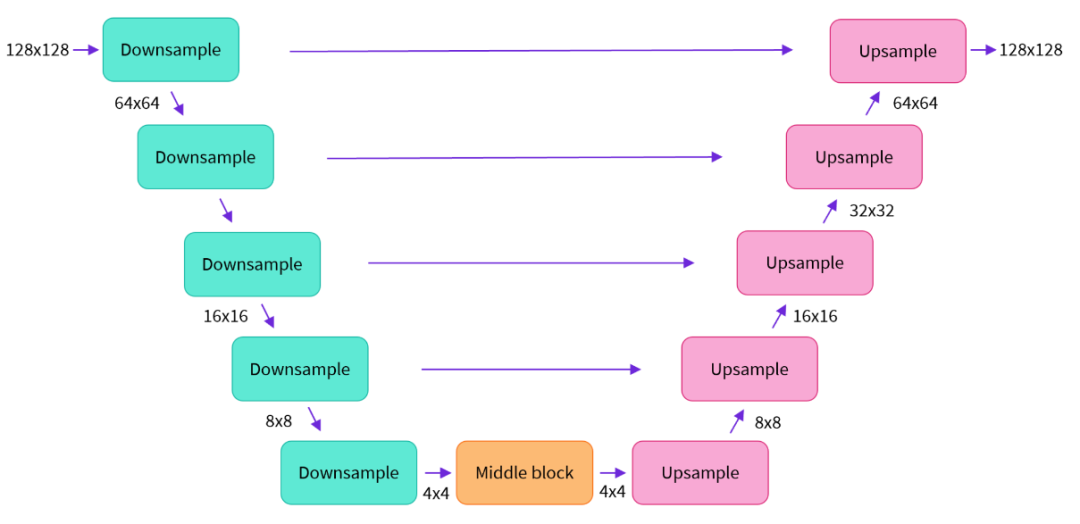
常規U-Net結構
3)文本編碼器
在擴散模型中,需要輸入文本prompt,以指導圖像生成方向。實現方式是:
- 使用文本編碼器(通常是CLIP等預訓練模型),對prompt進行編碼,得到表示其語義信息的詞向量。
- 將文本詞向量通過交叉注意力機制,輸入到擴散模型的U-Net中。
- 文本詞向量作為條件信息,引導U-Net的圖像生成過程,以輸出符合文本意圖的圖片。
默認的文本編碼器是CLIP模型,可以輸出跟圖像語義相關的稠密詞向量。
3、Stable Diffusion推理流程
要運行Stable Diffusion(SD),可以直接使用diffusers庫中的完整pipeline流程。
需要安裝相關依賴,使用以下命令進行安裝:
pip install diffusers transformers scipy ftfy accelerate
導入diffusers庫:
from diffusers import StableDiffusionPipeline
初始化SD模型并加載預訓練權重:
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5"
如果想使用GPU加速,可以使用以下命令將模型加載到GPU上:
pipe.to("cuda")
如果GPU內存少于10GB,可以加載float16精度的SD模型:
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", revision="fp16", torch_dtype=torch.float16)
使用pipeline來運行SD模型。例如,給定一個prompt和一張圖片,可以使用以下代碼生成一張新的圖片:
prompt = "a photograph of an astronaut riding a horse"image = pipe(prompt).images[0]
由于沒有固定seed,每次運行代碼都會得到一個不同的圖片。預訓練文件夾中的模型主要由以下幾個部分組成:text_encoder和tokenizer,scheduler,unet,vae。其中text_encoder,scheduler,unet,vae分別代表SD模型的核心結構。此外,還有一個名為Tokenizer的文件夾表示標記器。標記器將Prompt中的每個詞轉換為一個稱為標記(token)的數字,符號化(Tokenization)是計算機理解單詞的方式。然后通過text_encoder將每個標記轉換為一個768維的向量稱為嵌入(embedding),用于U-Net的condition。
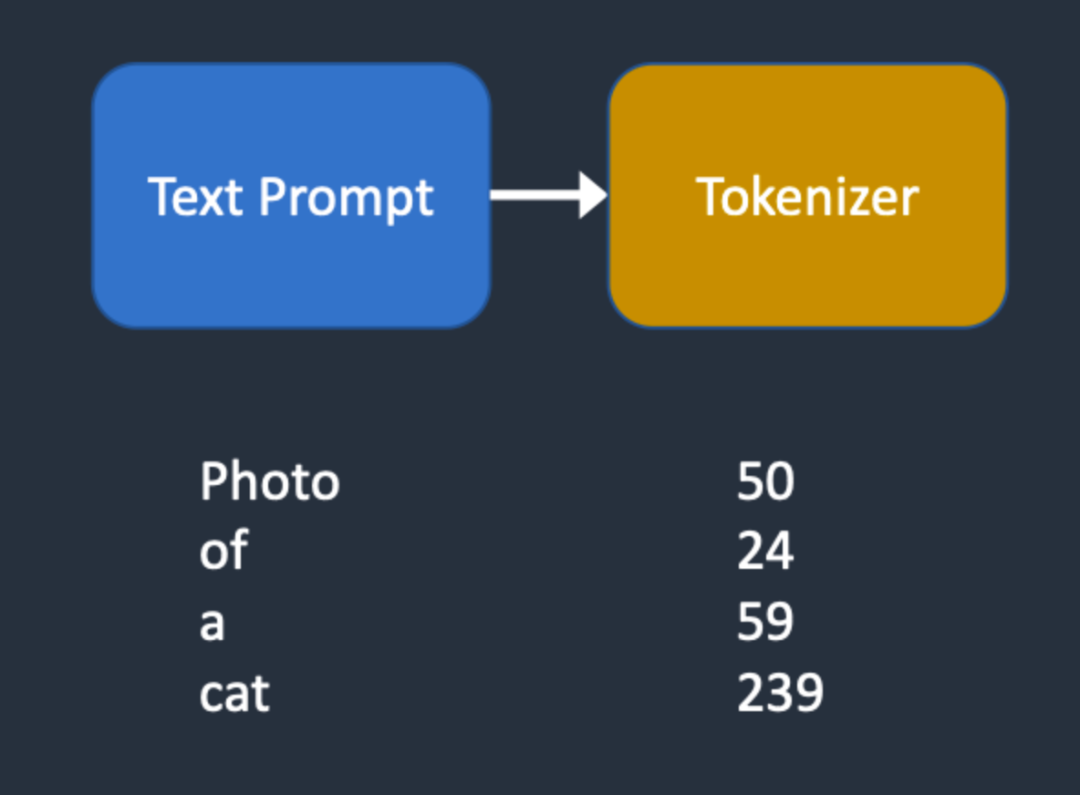
Tokenizer的作用
有時候在運行完pipeline后,可能會遇到生成的圖片全黑情況。這是因為生成的圖片可能觸發了NSFW(不適宜內容)機制,導致生成一些違規的圖片。為解決這個問題,建議使用自定義的seed來重新生成圖片。
可以使用以下代碼來設置seed,并控制生成圖片的輸出:
#import torch
# 設置seedtorch.manual_seed(1024)
# 創建生成器generator = torch.Generator("cuda").manual_seed(1024)
# 使用設置的seed和生成器來生成圖片image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
將pipeline的完整結構梳理好之后,再對一些核心參數進行講解:
1)num_inference_steps表示對圖片進行噪聲優化的迭代次數。一般來說,該值可以選擇在20到50之間,數值越大生成的圖片質量越高,但同時也需要更多的計算時間。
2)guidance_scale代表文本提示對圖像生成過程的影響程度。具體來說,它控制著有條件生成所使用噪聲的比例。通常該值在7到8.5之間取值較好,如果取值過大,生成的圖片質量可能會很高,但多樣性會下降。
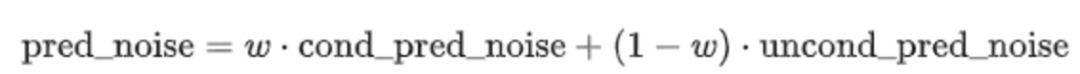
其中代表CFG,當越大時,condition起的作用越大,即生成的圖像更和輸入文本一致,當被設置為時,圖像生成是無條件的,文本提示會被忽略。
3)輸出尺寸
除了將預訓練的SD模型整體加載,還可以選擇加載其不同的組件。通過以下方式實現:
從transformers庫中加載CLIPTextModel和CLIPTokenizer:
from transformers import CLIPTextModel, CLIPTokenizer
從diffusers庫中加載AutoencoderKL、UNet2DConditionModel和PNDMScheduler:
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
還需要加載LMSDiscreteScheduler:
from diffusers import LMSDiscreteScheduler
可以單獨加載VAE模型:
vae = AutoencoderKL.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="vae")
加載CLIP模型和tokenizer:
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-vit-large-patch14")
單獨加載U-Net模型:
unet = UNet2DConditionModel.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="unet")
單獨加載調度算法:
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train=steps)
二、Stable Diffusion經典應用場景
1、文本生成圖片
輸入:prompt
輸入:圖像
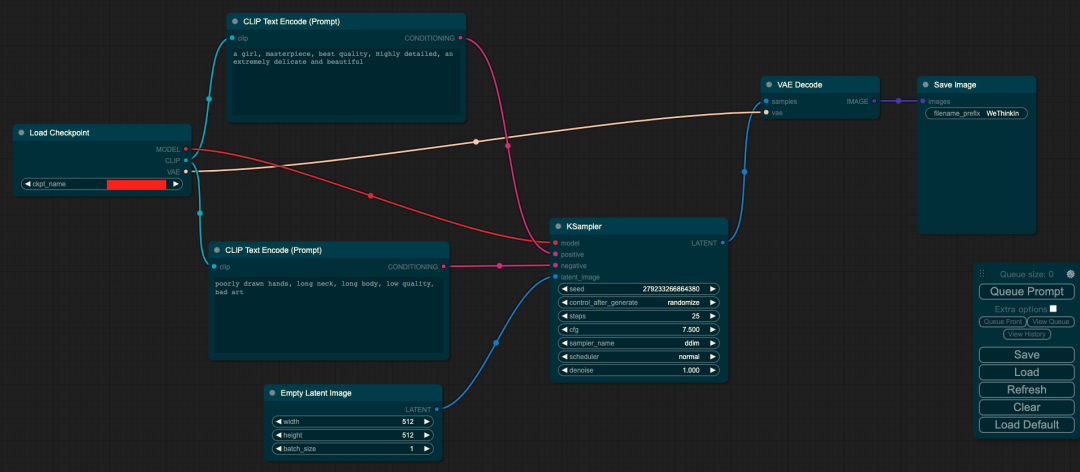
Load Checkpoint模塊負責初始化SD模型的主要結構(包括VAE和U-Net)。CLIP Text Encode代表文本編碼器,接收prompt和negative prompt作為輸入,以控制圖像的生成。Empty Latent Image表示初始化的高斯噪聲。KSampler負責調度算法以及與SD相關的生成參數。最后,VAE Decode利用VAE的解碼器將低維度的隱空間特征轉換為代表圖像的像素空間。
2、圖片生成圖片
輸入:圖像+ prompt
輸出:圖像
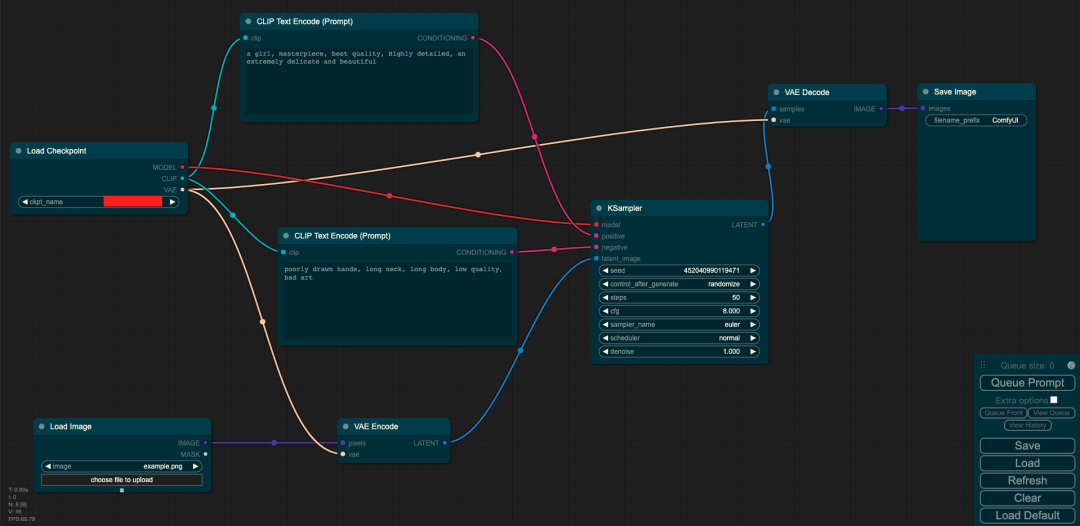
Load Checkpoint模塊負責對SD模型的主要結構(包括VAE和U-Net)進行初始化。CLIP Text Encode代表文本編碼器,接收prompt和negative prompt作為輸入,以控制圖像的生成。Load Image表示輸入的圖像。KSampler負責調度算法以及與SD相關的生成參數。
在圖片生成圖片的預處理階段,首先使用VAE編碼器將輸入圖像轉換為低維度的隱空間特征。然后添加噪聲到隱空間特征中,去噪強度決定加入噪聲的數量。如果去噪強度為0,則不添加任何噪聲;如果去噪強度為1,則會添加最大數量的噪聲,使得潛像成為一個完全隨機的張量。在這種情況下,圖片轉圖像的過程就完全相當于文本轉圖像,因為初始潛像完全是隨機的噪聲。
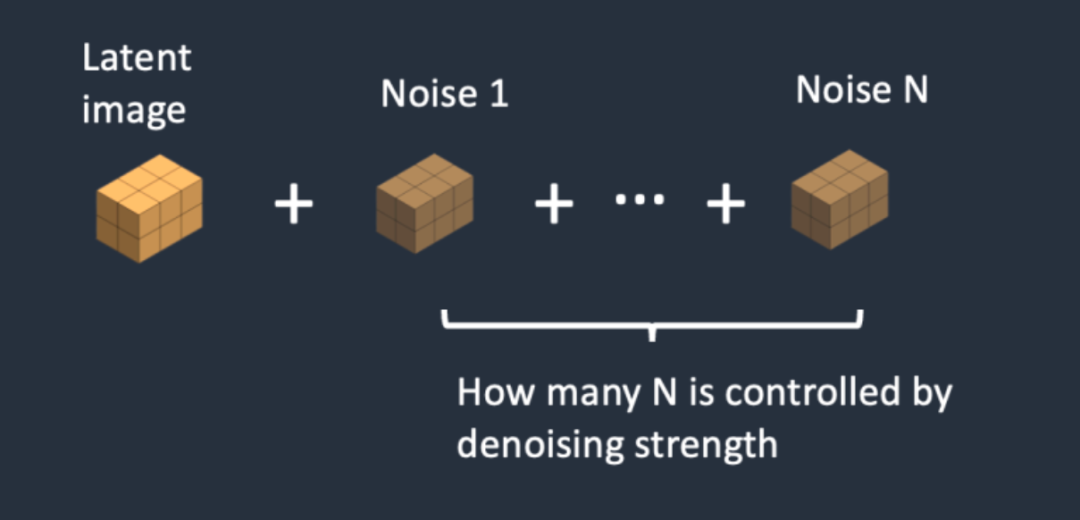
去噪強度(Denoising strength)控制噪音的加入量
3、圖片inpainting
輸入:圖像+ mask + prompt
輸出:圖像
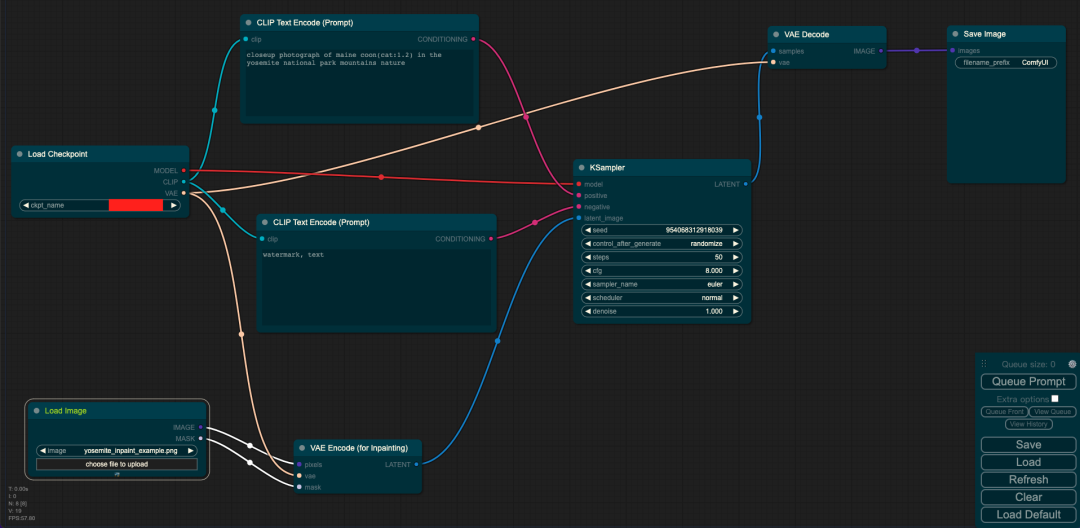
Load Checkpoint模塊負責初始化SD模型的主要結構(包括VAE和U-Net)。CLIP Text Encode代表文本編碼器,接收prompt和negative prompt作為輸入,以控制圖像的生成。Load Image表示輸入的圖像和mask。KSampler負責調度算法以及與SD相關的生成參數。
VAE Encode使用VAE的編碼器將輸入的圖像和mask轉換成為低維度的隱空間特征。然后,VAE Decode利用VAE的解碼器將低維度的隱空間特征轉換為代表圖像的像素空間。
下面是如何進行圖像inpainting的直觀過程:

4、使用controlnet輔助生成圖片
輸入:素描圖+ prompt
輸出:圖像
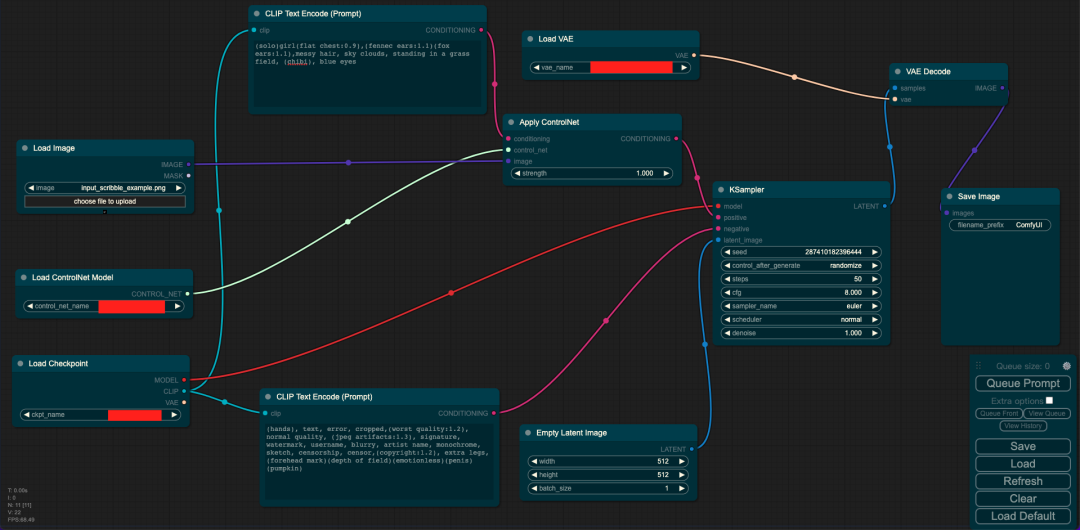
Load Checkpoint模塊負責對SD模型的主要結構(包括VAE和U-Net)進行初始化。CLIP Text Encode代表文本編碼器,接收prompt和negative prompt作為輸入,以控制圖像的生成。Load Image表示輸入的ControlNet需要的預處理圖。Empty Latent Image表示初始化的高斯噪聲。Load ControlNet Model負責對ControlNet進行初始化。KSampler負責調度算法以及與SD相關的生成參數。最后,VAE Decode利用VAE的解碼器將低維度的隱空間特征轉換為代表圖像的像素空間。
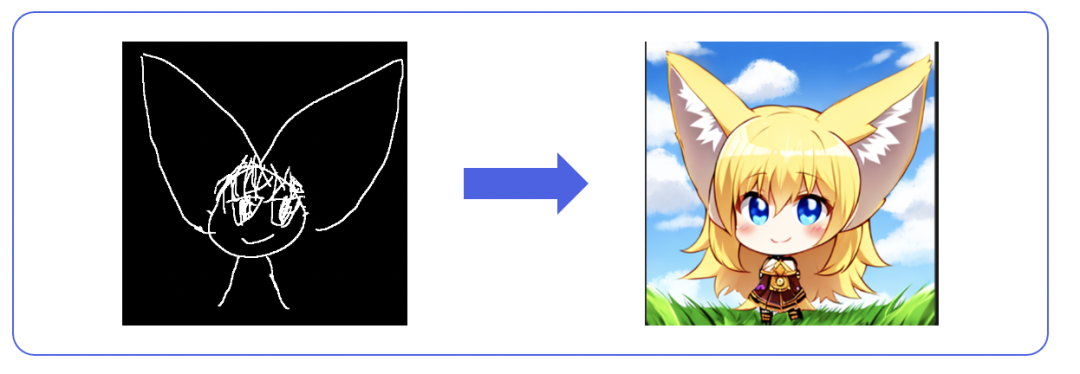
使用ControlNet輔助生成圖片
5、超分辨率重建
輸入:prompt/(圖像+ prompt)
輸入:圖像
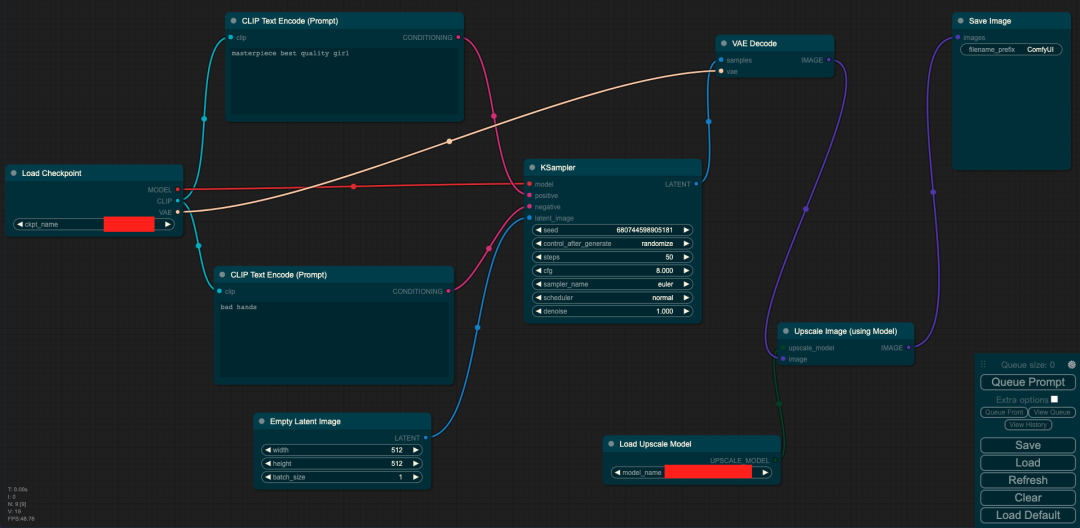
Load Checkpoint模塊負責對SD模型的主要結構(包括VAE和U-Net)進行初始化。CLIP Text Encode代表文本編碼器,接收prompt和negative prompt作為輸入,以控制圖像的生成。Empty Latent Image表示初始化的高斯噪聲。Load Upscale Model負責對超分辨率重建模型進行初始化。KSampler負責調度算法以及與SD相關的生成參數。VAE Decode利用VAE的解碼器將低維度的隱空間特征轉換為代表圖像的像素空間。最后,Upscale Image將生成的圖像進行超分辨率重建,提高其分辨率。
三、Stable Diffusion訓練過程
Stable Diffusion的訓練過程可以被視為在最高維度上添加噪聲和去除噪聲的過程,并在對噪聲的“對抗與攻防”中學習生成圖像的能力。具體地說,在訓練過程中首先對干凈的樣本添加噪聲進行處理,采用多次逐步增加噪聲的方式,直到干凈的樣本變成純噪聲。

SD訓練時的加噪過程
接下來,讓SD模型學習去噪過程,并最終抽象出一個高維函數,這個函數能夠在純噪聲中“優化”噪聲,從而得到一個干凈的樣本。具體來說,將去噪過程具象化為使用U-Net來預測噪聲,并結合調度算法逐步去噪的過程。
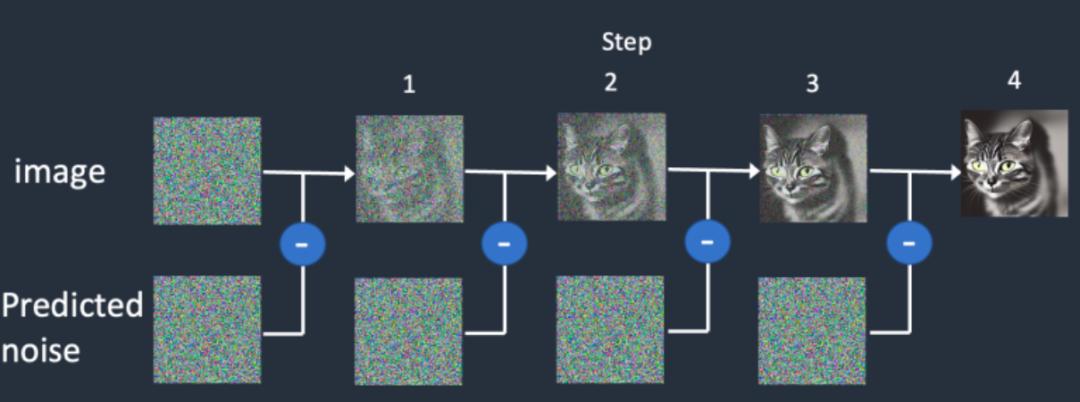
SD訓練時的去噪過程
在添加噪聲的時候,Stable Diffusion采用的是逐步增加的策略,每一步只增加一小部分噪聲,實現“小步快跑”的穩定加噪過程。這類似于移動互聯網產品設計中的迭代與快速推出原則。
另一方面,每次增加的噪聲量級也可以不同,例如可以設定5個不同量級的噪聲,每次隨機選擇一種量級增加到樣本圖片中。這進一步增加了噪聲的多樣性。在去噪過程中,同樣采用逐步減少噪聲的策略,每一步預測并去除一部分噪聲,實現穩定的去噪。
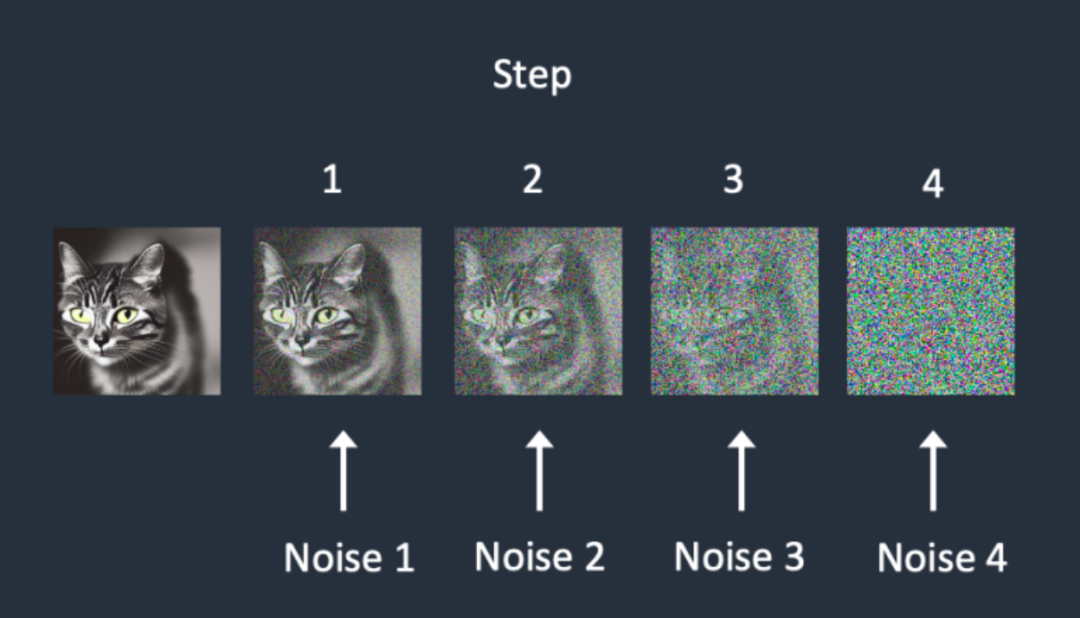
多量級噪聲
為了使網絡能夠知道當前處于k步的哪個階段,需要使用位置編碼。通過將步數作為輸入傳遞給網絡,位置編碼能夠讓網絡知道當前所處的階段。這種操作與Transformer中的操作類似。
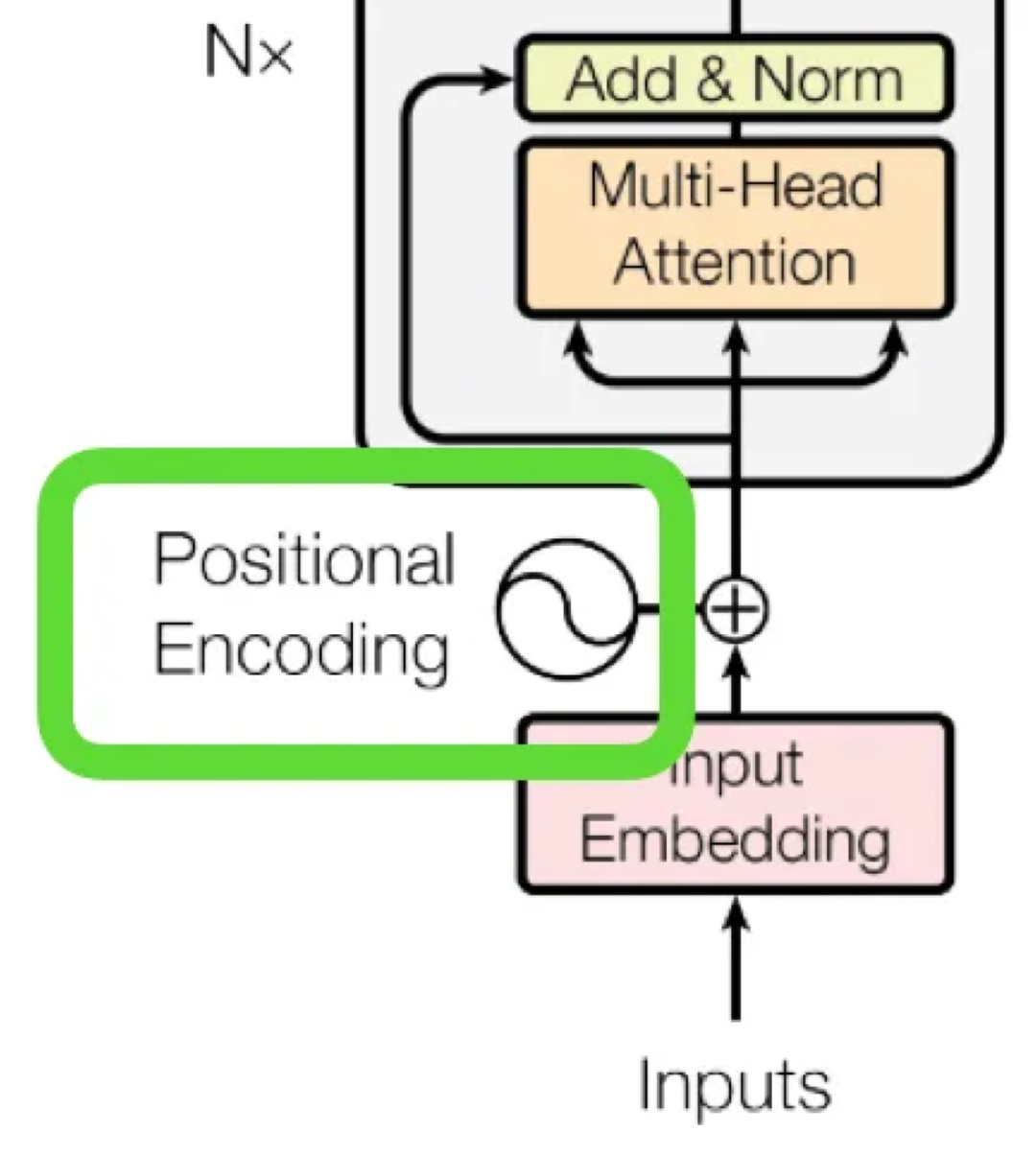
使用Positional embeddings對訓練迭代的步數進行編碼
四、Stable Diffusion性能優化
1、使用TF32精度
導入PyTorch并啟用TF32支持,實現性能和精度的平衡。TF32精度具有以下作用和優勢:
1)加速訓練速度:使用TF32精度可以在保持相對較高的模型精度的同時,加快模型訓練的速度。
2)減少內存需求:TF32精度相對于傳統的浮點數計算(如FP32)需要更少的內存存儲。這對于訓練大規模的深度學習模型尤為重要,可以減少內存的占用。
3)可接受的模型精度損失:使用TF32精度會導致一定程度的模型精度損失,因為低精度計算可能無法精確表示一些小的數值變化。然而,對于大多數深度學習應用,TF32精度仍然可以提供足夠的模型精度。
2、使用FP16半精度
導入PyTorch庫,并從diffusers庫中導入DiffusionPipeline。使用"runwayml/stable-diffusion-v1-5"預訓練模型創建一個DiffusionPipeline對象pipe,同時設置torch_dtype為torch.float16,以使用FP16半精度進行訓練。
使用FP16半精度訓練的優勢在于可以減少一半的內存占用,進一步將批次大小翻倍,同時將訓練時間減半。一些GPU,如V100和2080Ti等,針對16位計算進行優化,可以實現3-8倍的自動加速。
3、對注意力模塊進行切片
當所使用的模型中的注意力模塊包含多個注意力頭時,可以采用切片注意力操作,以便每個注意力頭依次計算注意力矩陣。這種做法可以顯著降低內存占用,但隨之而來的是推理時間大約增加10%。
首先,導入PyTorch庫,并從diffusers庫中導入DiffusionPipeline。然后,使用"runwayml/stable-diffusion-v1-5"預訓練模型創建一個DiffusionPipeline對象pipe,同時設置torch_dtype為torch.float16,以使用FP16半精度進行訓練。接下來,將pipe轉移到CUDA設備上,以便在GPU上運行。
為啟用切片注意力操作,需要調用pipe對象的enable_attention_slicing()方法。通過采用切片注意力操作,可以減少內存占用,但需要付出一些推理時間的代價,大約增加10%。
4、對VAE進行切片
與注意力模塊切片類似,也可以對VAE進行切片,讓VAE每次只處理Batch(32)中的一張圖片,從而大幅減少內存占用。
首先,導入PyTorch庫,并從diffusers庫中導入StableDiffusionPipeline。然后,使用"runwayml/stable-diffusion-v1-5"預訓練模型創建一個StableDiffusionPipeline對象pipe,同時設置torch_dtype為torch.float16,以使用FP16半精度進行訓練。接下來,將pipe轉移到CUDA設備上,以便在GPU上運行。為啟用VAE切片操作,調用pipe對象的enable_vae_slicing()方法。然后,使用prompt作為輸入,將一批32張圖片通過pipe進行生成,并將生成的圖片存儲在images變量中。
5、大圖像切塊
當需要生成4K或更高分辨率的圖像,但內存資源有限時,可以采用圖像切塊的技術。通過對圖像進行切塊,讓VAE的編碼器和解碼器逐一處理每個切塊后的圖像,最后將拼接在一起生成最終的大圖像。
首先,導入PyTorch庫,并從diffusers庫中導入StableDiffusionPipeline。然后,使用"runwayml/stable-diffusion-v1-5"預訓練模型創建一個StableDiffusionPipeline對象pipe,同時設置torch_dtype為torch.float16,以使用FP16半精度進行訓練。接下來,將pipe轉移到CUDA設備上,以便在GPU上運行。為啟用圖像切塊操作,調用pipe對象的enable_vae_tiling()方法。然后,使用prompt作為輸入,并指定圖像的寬度為3840像素,高度為2224像素,以及生成步驟的數量為20。通過調用pipe對象的生成方法,可以得到生成的圖像。最后,從生成的圖像中獲取第一張圖像并將其存儲在image變量中。
6、CPU <-> GPU切換
可將整個SD模型或SD模型的部分模塊的權重加載到CPU中,并在推理時再將所需的權重加載到GPU。以下是如何使用PyTorch和Stable Diffusion Pipeline實現的代碼:
import torch
from diffusers import StableDiffusionPipeline
# 將整個SD模型加載到CPU
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
# 開啟子模塊的CPU offload功能,即可以在CPU上執行某些子模塊的計算
pipe.enable_sequential_cpu_offload()
# 開啟整個SD模型的CPU offload功能,即可以在CPU上執行整個SD模型的計算
pipe.enable_model_cpu_offload()
這段代碼將整個SD模型或SD模型的部分模塊的權重加載到CPU中,并在推理時再將所需的權重加載到GPU,以實現更好的性能和靈活性。
7、變換Memory Format
在計算機視覺領域,有兩種常見的內存格式,分別是channels first(NCHW)和channels last(NHWC)。將channels first轉換為channels last可能會提高推理速度,但需要依賴于特定的AI框架和硬件。
在channels last內存格式中,張量的維度順序為(batch_size,height,width,channels)。其中,batch_size表示批處理大小,height和width表示圖像或特征圖的高度和寬度,channels表示通道數。
相比之下,channels first是另一種內存布局,其中通道維度被放置在張量的第二個維度上。在channels first內存格式中,張量的維度順序為(batch_size,channels,height,width)。
選擇channels last或channels first內存格式通常取決于硬件和軟件平臺以及所使用的深度學習框架。不同的平臺和框架可能對內存格式有不同的偏好和支持程度。
在一些情況下,channels last內存格式具有以下優勢:
1)內存訪問效率:在一些硬件架構中,如CPU和GPU,channels last內存格式能夠更好地利用內存的連續性,從而提高數據訪問的效率。
2)硬件加速器支持:一些硬件加速器(如NVIDIA的Tensor Cores)對于channels last內存格式具有特定的優化支持,可以提高計算性能。
3)跨平臺兼容性:某些深度學習框架和工具更傾向于支持channels last內存格式,使得在不同的平臺和框架之間遷移模型更加容易。
需要注意的是,選擇內存格式需要根據具體的硬件、軟件和深度學習框架來進行評估。某些特定的操作、模型結構或框架要求可能會對內存格式有特定的要求或限制。因此,建議在特定環境和需求下進行測試和選擇,以獲得最佳的性能和兼容性。
8、使用xFormers
使用xFormers插件能夠優化注意力模塊的計算,提升約20%的運算速度。
導入PyTorch庫
創建一個名為"pipe"的StableDiffusionPipeline對象,使用預訓練模型"runwayml/stable-diffusion-v1-5",數據類型為torch.float16,并將模型遷移到"cuda"設備上。
通過調用.enable_xformers_memory_efficient_attention()方法,使用xFormers插件來優化注意力模塊的計算,從而 提升約20%的運算速度。
如何使用StableDiffusion制作AI數字人視頻
下面介紹如何安裝SadTalker插件。
首先,需要確保已經成功安裝Stable Diffusion WebUI。然后,從Github上獲取SadTalker的開源代碼,其地址為:
https://github.com/OpenTalker/SadTalker.git。
一、SadTalker安裝方法
1、安裝方法一
適合訪問Github或外網較流暢的用戶,因為需要自動下載大量文件。在SD WebUI的擴展插件頁面中進行安裝,如下圖所示:
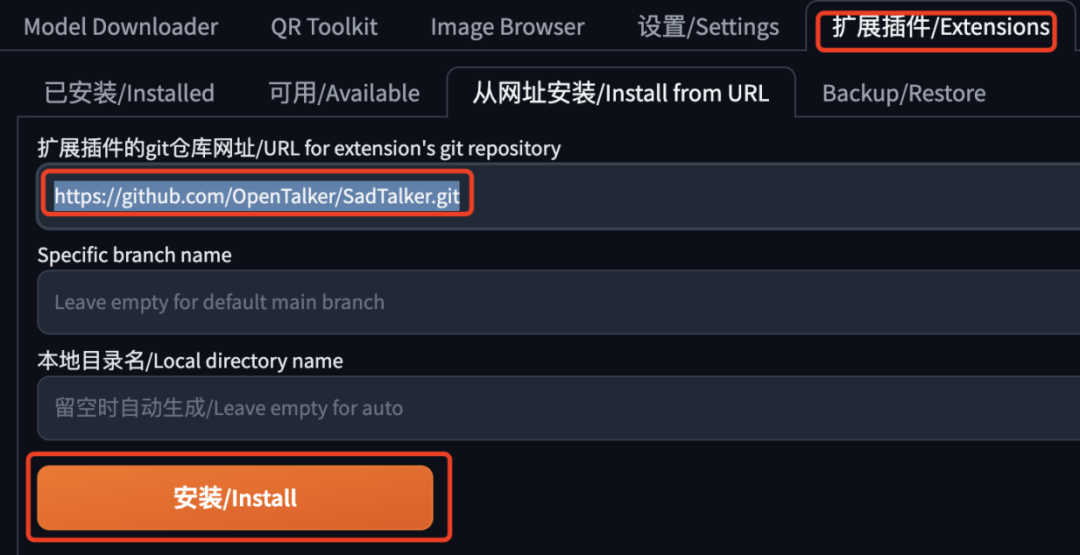
這個插件需要下載許多文件,有些文件體積較大,需耐心等待。如果不確定是否出現了問題,可以查看控制臺輸出的內容,查找是否有錯誤。安裝完成后,不要忘記重啟Stable Diffusion,需要完全重啟,而不僅僅是重啟WebUI。
2、安裝方法二
對于訪問外網不太方便的用戶,可以提前下載所需文件,例如使用迅雷等下載工具。只要將下載的文件上傳到指定的目錄即可。
1)主程序
需要放到以下位置:stable-diffusion-webui/extensions/SadTalker
https://github.com/OpenTalker/SadTalker/archive/refs/heads/main.zip
2)視頻模型
可以從以下鏈接下載:stable-diffusion-webui/extensions/SadTalker/checkpoints
https://github.com/OpenTalker/SadTalker/releases/download/v0.0.2-rc/mapping_00109-model.pth.tar
https://github.com/OpenTalker/SadTalker/releases/download/v0.0.2-rc/mapping_00229-model.pth.tar
https://github.com/OpenTalker/SadTalker/releases/download/v0.0.2-rc/SadTalker_V0.0.2_256.safetensors
https://github.com/OpenTalker/SadTalker/releases/download/v0.0.2-rc/SadTalker_V0.0.2_512.safetensors
3)修臉模型
需要放到以下位置:stable-diffusion-webui/extensions/SadTalker/gfpgan/weights 和 stable-diffusion-webui/models/GFPGAN
您可以從以下鏈接下載:
https://github.com/xinntao/facexlib/releases/download/v0.1.0/alignment_WFLW_4HG.pth
https://github.com/xinntao/facexlib/releases/download/v0.1.0/detection_Resnet50_Final.pth
https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.4.pth
https://github.com/xinntao/facexlib/releases/download/v0.2.2/parsing_parsenet.pth
為了方便使用這種方式部署,我們已經將相關文件打包好,大家無需單獨下載。只需聯系我們,即可獲得下載地址。
4)安裝
首先,將文件下載到本地或云環境中。以AutoDL為例,將文件保存到/root目錄中。
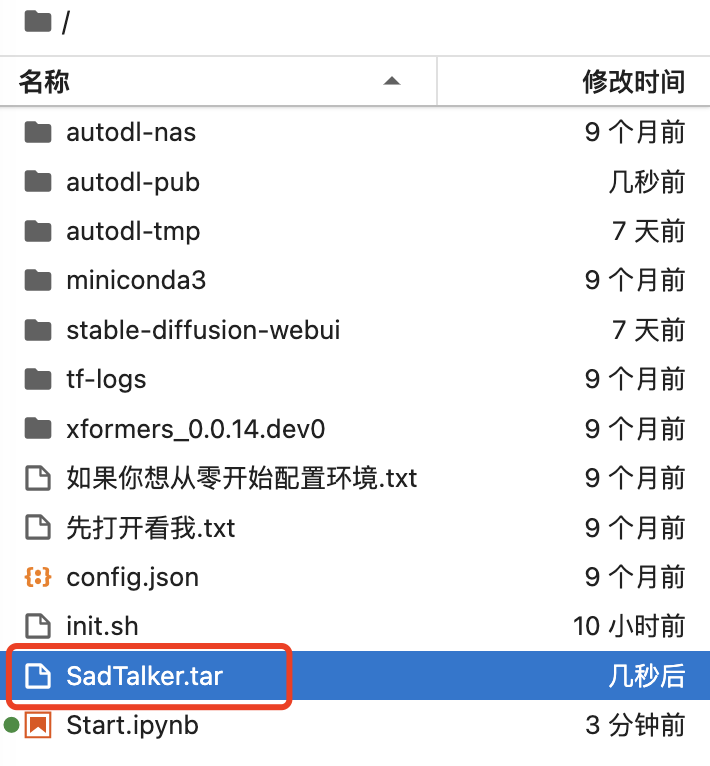
然后解壓文件到 stable diffusion webui的擴展目錄,并拷貝幾個文件到SD模型目錄:
tar -xvf /root/SadTalker.tar -C /root/stable-diffusion-webui/extensions cp -r /root/stable-diffusion-webui/extensions/SadTalker/gfpgan/weights/* /root/stable-diffusion-webui/models/GFPGAN/
看到下邊的結果,就基本上差不多了。
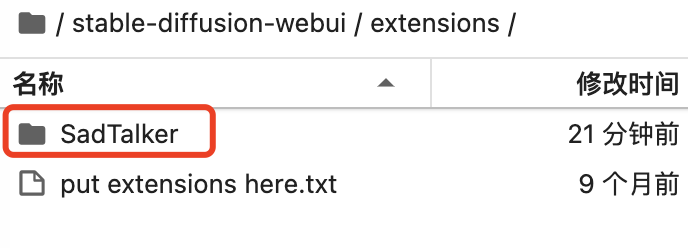
SD models 目錄下有這幾個文件:
部署完畢,不要忘了重啟。
二、使用方法
在SD WebUI的Tab菜單中找到SadTalker,按照下邊的順序進行設置。
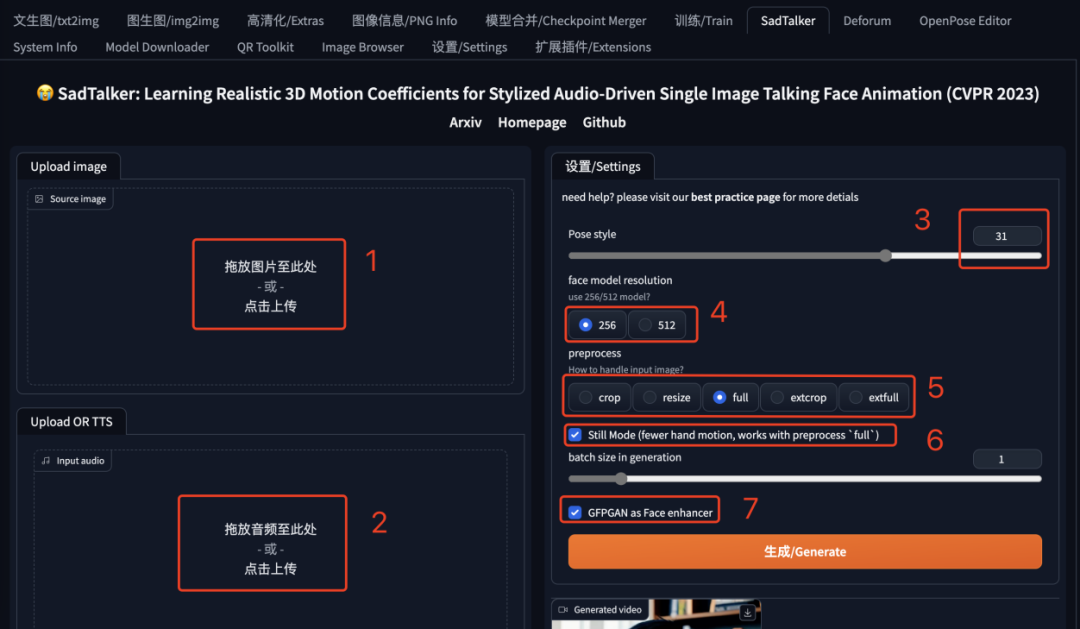
1、上傳人物照片。
2、上傳語音文件。
3、選擇視頻人物的姿勢。實際上,這指的是在人物說話時頭部的動作。可以通過嘗試不同的數字來選擇合適的動作。
4、分辨率。512的視頻分辨率比256的大。
5、圖片處理方法:corp是從圖片截取頭部做視頻,resize適合大頭照或者證件照,full就是全身照做視頻。
6、Still Model:這個選項可以讓頭部動作不要過大,以避免頭部與身體偏離的情況。然而,這樣可能會導致頭部動作不太明顯。
7、GFPGAN:這個選項可以修整臉部,有助于改善說話時嘴部和眼部可能出現的變形現象,從而使臉部看起來更加自然。
最后,點擊“生成”。根據硬件的運行速度以及設置,生成過程可能需要幾分鐘的時間。請耐心等待。
三、常見問題
1、啟動的時候報錯:SadTalker will not support download...

這個提示意味模型無法成功下載。可以執行以下命令來觸發下載(請注意將cd后的路徑替換為SadTalker安裝路徑):
cd stable-diffusion-webui/extensions/SadTalker
chmod 755 scripts/download_models.sh
scripts/download_models.sh
2、合成視頻時報錯:No module named 'xxx'
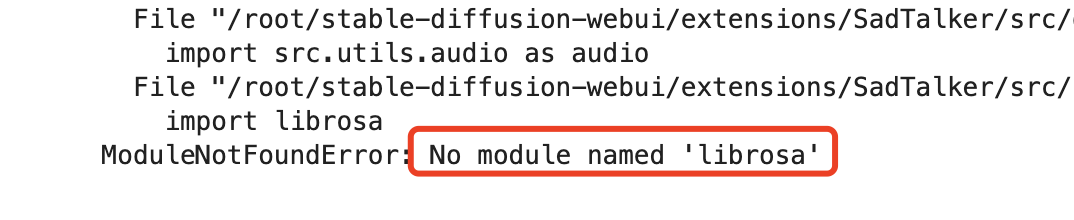
可以使用pip install命令來安裝xxx。但請注意,如果使用Python虛擬環境,需要先激活。例如,這里需要先執行source xxx命令。然后,可以運行以下命令來安裝
librosa:
source /root/stable-diffusion-webui/venv/bin/activate
pip install librosa
這些命令將激活虛擬環境并安裝librosa庫。
3、合成視頻時報錯:在合成視頻時,可能會遇到一個錯誤:No such file or directory: '/tmp/gradio/xxx'。這意味著系統無法找到該文件或目錄。為了解決這個問題,可以創建一個目錄。使用以下命令可以輕松地創建該目錄:mkdir -p /tmp/gradio
4、如果遇到提示找不到ffmpeg的情況,嘗試先下載并安裝ffmpeg。通過以下鏈接下載安裝程序:http://ffmpeg.org/download.html
Stable Diffusion本地部署要求
隨著Stable Diffusion在AI藝術生成領域的不斷發展和普及,越來越多的用戶希望能夠在自己的本地機器上部署SD模型,以獲得更好的性能表現和使用體驗。然而,部署一個大規模的生成模型如SD需要強大的計算資源和硬件配置。那么,究竟需要怎樣的計算機配置才能流暢地運行SD模型呢?
一、GPU
GPU最好使用NVIDIA的RTX系列,如RTX 3070,RTX 4070和RTX4060。老一代的RTX 2000系列也可考慮,但性能較新卡略低,且顯存略小。不推薦使用專業級顯卡如NVIDIA A6000,其擁有大量視頻內存,非常適合預算充足的情況。不要使用筆記本等移動GPU,因為其顯存和功耗都有限,難以進行高效的模型訓練。如果條件允許,可以使用多張GPU進行多卡訓練,以提高訓練速度。
二、CPU
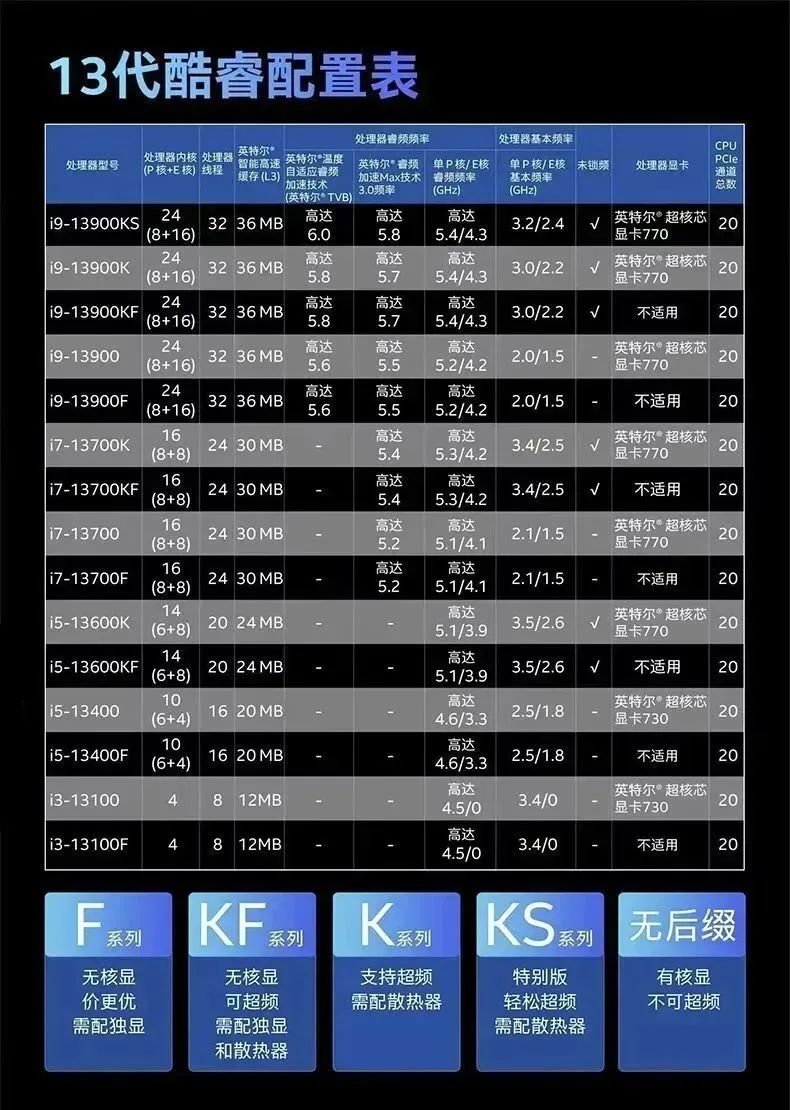
除了GPU之外,具有高核心數的CPU也是必不可少的。Stable Diffusion的訓練和推理過程需要進行大量的矩陣計算,對CPU的并行計算能力有很高的要求。一般來說,至少需要8核心或更多的CPU,如i9-13900;i7-13700;i5 13400;i3 12100;i7 12700 ;i9 12900 等。
三、RAM內存
大量的RAM內存同樣不可或缺。本地部署SD時,系統內存最好在32GB以上。這可以顯著加速數據交換與傳輸速度。與GPU類似,更多的GPU卡也會需要更多的系統內存配合。
四、存儲方面
系統盤無特殊要求,需要1TB甚至更大的磁盤空間來存儲大規模的模型文件、數據集和生成結果。使用RAID 0可以獲得更高的讀取速度。
五、網絡方面
網絡對于Stable Diffusion的部署和使用都非常關鍵,需要準備以下幾方面:
1、帶寬需求
初始部署需要下載模型文件,通常數十GB甚至上百GB,需要具備穩定的大帶寬來支持。訓練過程中也需要大量的數據流量,務必確認網絡帶寬足夠,例如千兆寬帶。如果使用云訓練平臺,還需要考慮上傳訓練結果的流量。
2、網絡速度
部署時的下載速度直接影響部署進度,需要盡可能高的網絡速度。訓練時網絡速度影響同步效率。內網訓練可以做到更低延遲。公網環境下,光纖寬帶的低延遲有利于分布式訓練。
3、網絡穩定性
訓練過程需要持續不間斷的連接,斷網會造成失敗。部署和使用期間應盡量避免網絡抖動現象的發生。
4、代理和緩存
可以使用本地代理做緩存,加速模型和數據的下載。代理同時還可以提供一定的數據安全性和隱私保護。
5、數據安全
如果涉及敏感數據,要注意加密傳輸和訪問控制。遵守相關的數據隱私規范,謹慎上傳或共享數據。
六、軟件方面
操作系統需要Windows 10/11或者較新版本的Linux發行版,如Ubuntu 20.04+。Python版本需要在3.7以上,主要的深度學習框架如PyTorch、TensorFlow也需要相應安裝,并確認版本與硬件兼容。可能還需要安裝許多Python庫來支持不同的數據加載和圖像處理功能。使用Docker等虛擬化技術可以簡化軟件環境配置。
藍海大腦集成SD的PC集群解決方案
AIGC和ChatGPT4技術的爆燃和狂飆,讓文字生成、音頻生成、圖像生成、視頻生成、策略生成、GAMEAI、虛擬人等生成領域得到了極大的提升。不僅可以提高創作質量,還能降低成本,增加效率。同時,對GPU和算力的需求也越來越高,因此GPU服務器廠商開始涌向該賽道,為這一領域提供更好的支持。在許多領域,如科學計算、金融分析、天氣預報、深度學習、高性能計算、大模型構建等領域,需要大量的計算資源來支持。為了滿足這些需求,藍海大腦PC集群解決方案應運而生。
PC集群是一種由多臺計算機組成的系統,這些計算機通過網絡連接在一起,共同完成計算任務。PC集群解決方案是指在PC集群上運行的軟件和硬件系統,用于管理和優化計算資源,提高計算效率和可靠性。
藍海大腦PC集群解決方案提供高密度部署的服務器和PC節點,采用4U機架式設計,每個機架可插拔4個PC節點。融合了PC的高主頻和高性價比以及服務器的穩定性的設計,實現了遠程集中化部署和管理運維。同時,采用模塊化可插拔設計,使維護和升級變得更加容易。
同時,集成Stable Diffusion AI模型,可以輕松地安裝和使用,無需進行任何額外的配置或設置。與傳統的人工創作方式相比,Stable Diffusion Al模型可以更快地生成高品質的創作內容。通過集成這個模型,可以使創作者利用人工智能技術來優化創作流程。另外,藍海大腦PC集群解決方案還具有開箱即用的特點,不僅易于安裝和使用,而且能夠快速適應各種創作工作流程。這意味著用戶可以在短時間內開始創作,并且在整個創作過程中得到更好的體驗。

一、主要技術指標
1、支持遠程開關機和硬重啟PC節點
2、集成的供電和管理背板,每個節點750W峰值供電功率
3、機箱管理單元支持節點遠程上下電
4、每個PC節點支持熱插拔,單個節點故障不影響其他節點工作
5、獨立的管理網口和串口
6、每個節點配置2個可插拔8038高功率服務器風扇,提供智能溫控
二、客戶收益
Stable Diffusion技術對游戲產業帶來了極大的影響和改變。它提升了游戲圖像的質量和真實感、增強了游戲體驗和沉浸感、優化了游戲制作流程、擴展了游戲應用領域,并推動了游戲產業的發展和創新。這些都表明,Stable Diffusion技術在游戲產業中的應用前景十分廣闊,有助于進一步推動游戲行業的發展,提高用戶體驗和娛樂價值。
1、提升游戲圖像質量和真實感
Stable Diffusion可以在保證渲染速度的前提下,提高游戲圖像的細節和真實感。傳統的光線追蹤方法需要檢查和模擬每條光線,這樣會消耗大量計算資源,并放緩渲染速度。而Stable Diffusion則利用深度學習技術對光線的擴散過程進行建模,使得處理數百萬條光線所需的計算時間更短,同時還能夠生成更為精準的光線路徑。這意味著,Stable Diffusion可以讓計算機產生更加逼真的景觀、人物、物品等元素,在視覺效果上得到質的飛躍。
2、增強游戲體驗和沉浸感
游戲是一個交互式體驗,它的目標是盡可能地讓玩家沉浸到虛構的世界中。Stable Diffusion可以使游戲環境變得更加真實,并增添一些更具有交互性和觀賞性的場景。例如,利用Stable Diffusion技術,游戲可以在水面上添加波紋、落葉,或者使搖曳的草叢更逼真。這些改善能夠讓玩家更好地感受游戲中所處的環境,增強沉浸感。
3、優化游戲制作流程
Stable Diffusion的應用可以提高游戲開發的效率和質量,減少手動制作和修改的工作量。渲染過程的快速執行還可以加速開發周期,甚至使一些在過去被看做是計算機圖形學難題的事情變得可能。例如,在模擬復雜的自然現象或在大范圍內生成游戲元素時,使用Stable Diffusion可有效降低游戲開發的成本和時間,讓開發者有更多的精力關注其他方面的設計和創意。
4、擴展游戲的應用領域
Stable Diffusion的應用使得游戲在更多的領域得到應用。例如,在心理治療、教育、文化傳播等領域中,人工智能游戲可以根據用戶的情緒和行為變化來調整游戲內容和策略,為用戶提供更符合需求和娛樂性的游戲體驗。此外,利用Stable Diffusion技術,游戲可以生成不同類型的場景,包括虛擬現實和增強現實等體驗,開發出更豐富更多變的游戲內容。
5、推動游戲產業的發展和創新
Stable Diffusion作為先進的計算機圖形學技術之一,進一步推動了游戲產業的發展和創新。利用人工智能技術渲染的游戲將會產生更高品質、更廣泛的游戲類別,從而吸引更多領域的玩家參與,并且會推動相關行業的發展,如文化傳媒行業、數字娛樂業等。同時,穩定性更好、性能更高的Stable Diffusion技術還具有在未來制造更復雜的虛擬世界的潛力,例如更多樣化、更逼真、更具交互性的虛擬現實環境和游戲。
三、PC集群解決方案的優勢
1、高性能
PC集群解決方案可將多臺計算機的計算能力整合起來,形成一個高性能的計算系統。可支持在短時間內完成大量的計算任務,提高計算效率。
2、可擴展性
可以根據需要進行擴展,增加計算節點,提高計算能力。這種擴展可以是硬件的,也可以是軟件的,非常靈活。
3、可靠性
PC集群可以通過冗余設計和備份策略來提高系統的可靠性。當某個節點出現故障時,其他節點可以接管其任務,保證計算任務的順利進行。
4、低成本
相比于傳統的超級計算機,PC集群的成本更低。這是因為PC集群采用的是普通的PC硬件,而不是專門的高性能計算硬件。
四、PC集群解決方案的應用領域有哪些?
PC集群是指將多臺個人電腦連接在一起,通過網絡協同工作,實現高性能計算的一種方式。它的應用領域非常廣泛,以下是一些常見的應用領域:
1、科學計算
PC集群可以用于各種科學計算,如天文學、生物學、物理學、化學等領域的計算模擬和數據分析。
2、工程計算
PC集群可以用于工程領域的計算,如飛機設計、汽車設計、建筑結構分析等。
3、金融計算
PC集群可以用于金融領域的計算,如股票交易、風險評估、投資組合優化等。
4、大數據處理
PC集群可以用于大數據處理,如數據挖掘、機器學習、人工智能等領域的數據處理和分析。
5、圖像處理
PC集群可以用于圖像處理,如視頻編碼、圖像識別、虛擬現實等領域的圖像處理和渲染。
五、常用配置推薦
1、處理器,CPU:
i9-13900 24C/32T/2.00GHz/32MB/65W/Up to DDR5 5600 MT/s / Up to DDR4 3200 MT/s
i7-13700 16C/24T/2.10GHz/30MB/65W/Up to DDR5 5600 MT/s / Up to DDR4 3200 MT/s
i5 13400 10C/16T/1.80GHz/20MB/65W/Up to DDR5 4800 MT/s /Up to DDR4 3200 MT/s
i3 13100 4C/8T/3.40GHz/12MB/60W/Up to DDR5 4800 MT/s /Up to DDR4 3200 MT/s
G6900 2C/2T/3.40GHz/4MB/46W/Up to DDR5 4800 MT/s /Up to DDR4 3200 MT/s
G7400 2C/4T/3.70GHz/6MB/46W/Up to DDR5 4800 MT/s /Up to DDR4 3200 MT/s
i3 12100 4C/8T/3.30GHz/12MB/60W/Up to DDR5 4800 MT/s /Up to DDR4 3200 MT/s
i5 12400 6C/12T/2.50GHz/18MB/65W/Up to DDR5 4800 MT/s /Up to DDR4 3200 MT/s
i7 12700 12C/20T/2.10GHz/25MB/65W/Up to DDR5 4800 MT/s /Up to DDR4 3200 MT/s
i9 12900 16C/24T/2.40GHz/30MB/65W/Up to DDR5 4800 MT/s /Up to DDR4 3200 MT/s
2、顯卡GPU:
NVIDIA RTX GeForce 3070 8GB
NVIDIA RTX GeForce 3080 10GB
NVIDIA RTX GeForce 4070 12GB
NVIDIA RTX GeForce 4060Ti 8GB or 16GB
3、內存:
32GB×2
4、系統盤:
M.2 500GB
5、數據盤:
500GB 7200K
審核編輯 黃宇
-
AI
+關注
關注
87文章
30197瀏覽量
268447 -
人工智能
+關注
關注
1791文章
46879瀏覽量
237616 -
深度學習
+關注
關注
73文章
5493瀏覽量
120985
發布評論請先 登錄
相關推薦
Stability AI開源圖像生成模型Stable Diffusion
大腦視覺信號被Stable Diffusion復現圖像!
一文讀懂Stable Diffusion教程,搭載高性能PC集群,實現生成式AI應用

使用OpenVINO?在算力魔方上加速stable diffusion模型
優化 Stable Diffusion 在 GKE 上的啟動體驗
iPhone兩秒出圖,目前已知的最快移動端Stable Diffusion模型來了

美格智能高算力AI模組成功運行Stable Diffusion大模型
樹莓派能跑Stable Diffusion了?
Stable Diffusion的完整指南:核心基礎知識、制作AI數字人視頻和本地部署要求





 工商網監
工商網監
評論