") Falcon-7B大型語言模型在心理健康對話數(shù)據(jù)集上使用QLoRA進(jìn)行微調(diào)
Falcon-7B大型語言模型在心理健康對話數(shù)據(jù)集上使用QLoRA進(jìn)行微調(diào)
??文本是參考文獻(xiàn)[1]的中文翻譯,主要講解了Falcon-7B大型語言模型在心理健康對話數(shù)據(jù)集上使用QLoRA進(jìn)行微調(diào)的過程。項目GitHub鏈接為https://github.com/iamarunbrahma/finetuned-qlora-falcon7b-medical,如下所示:
??使用領(lǐng)域適應(yīng)技術(shù)對預(yù)訓(xùn)練LLM進(jìn)行微調(diào)可以提高在特定領(lǐng)域任務(wù)上的性能。但是,進(jìn)行完全微調(diào)可能會很昂貴,并且可能會導(dǎo)致CUDA內(nèi)存不足錯誤。當(dāng)進(jìn)行完全微調(diào)時,可能會發(fā)生災(zāi)難性遺忘,因為許多權(quán)重在"知識存儲"的地方發(fā)生了變化。因此,迄今為止,在消費(fèi)者硬件上對擁有數(shù)十億參數(shù)的預(yù)訓(xùn)練LLM進(jìn)行微調(diào)并不容易。
核心原因
??心理健康應(yīng)該是任何個人的首要任務(wù),就像身體健康一樣重要。在我們的社會中,與抑郁和精神障礙有關(guān)的討論已經(jīng)被污名化,以至于人們避免討論與焦慮和抑郁有關(guān)的問題,也避免去看心理醫(yī)生。
??聊天機(jī)器人為尋求支持的個人提供了隨時可用和可訪問的平臺。它們可以隨時隨地訪問,為需要幫助的人提供即時援助。聊天機(jī)器人可以提供富有同情心和非判斷性的回應(yīng),為用戶提供情感支持。雖然它們不能完全取代人際互動,但它們可以在困難時刻提供有用的補(bǔ)充。雖然聊天機(jī)器人很有用,但并沒有多少匿名聊天應(yīng)用程序可以提供關(guān)于各種心理健康狀況、癥狀、應(yīng)對策略和可用治療選項的可靠信息和心理教育。
??因此,主要目標(biāo)是使用經(jīng)過篩選的對話數(shù)據(jù)集并使用QLoRA技術(shù)在開源Falcon-7B LLM上進(jìn)行微調(diào),從而構(gòu)建一個心理健康聊天機(jī)器人。Falcon-7B LLM根據(jù)Apache 2.0許可證提供,因此可以用于商業(yè)目的。
什么是LoRA?
??讓我們介紹一下LoRA[2](大規(guī)模語言模型的低秩適應(yīng),由Edward Hu等人提出)。LoRA技術(shù)基于LLM的參數(shù)高效微調(diào)方法。使用PEFT,我們可以對LLM進(jìn)行高性能建模的微調(diào),但只需要微調(diào)少量參數(shù)。PEFT的另一個優(yōu)點(diǎn)是我們可以使用更少的數(shù)據(jù)對任何大型模型進(jìn)行微調(diào)。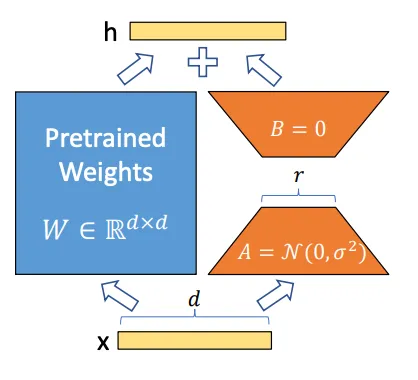 ??LoRA是一種用于大型權(quán)重矩陣的隱式低秩變換技術(shù)。LoRA不直接分解矩陣,而是通過反向傳播學(xué)習(xí)分解矩陣。??雖然預(yù)訓(xùn)練模型的權(quán)重在預(yù)訓(xùn)練任務(wù)上具有完整的秩,但當(dāng)它們適應(yīng)新的領(lǐng)域特定任務(wù)時,預(yù)訓(xùn)練模型具有較低的內(nèi)在維度。較低的內(nèi)在維度意味著數(shù)據(jù)可以有效地近似為一個較低維度的空間,同時保留了大部分基本信息或結(jié)構(gòu)。
??LoRA是一種用于大型權(quán)重矩陣的隱式低秩變換技術(shù)。LoRA不直接分解矩陣,而是通過反向傳播學(xué)習(xí)分解矩陣。??雖然預(yù)訓(xùn)練模型的權(quán)重在預(yù)訓(xùn)練任務(wù)上具有完整的秩,但當(dāng)它們適應(yīng)新的領(lǐng)域特定任務(wù)時,預(yù)訓(xùn)練模型具有較低的內(nèi)在維度。較低的內(nèi)在維度意味著數(shù)據(jù)可以有效地近似為一個較低維度的空間,同時保留了大部分基本信息或結(jié)構(gòu)。
什么是QLoRA?
??接下來,讓我們來看看QLoRA[3](由Tim Dettmers等人提出的量化LLM的低秩適應(yīng))。QLoRA通過量化感知訓(xùn)練、混合精度訓(xùn)練和雙重量化來降低平均內(nèi)存占用。QLoRA具有存儲數(shù)據(jù)類型(4位Normal Float)和計算數(shù)據(jù)類型(16位Brain Float)。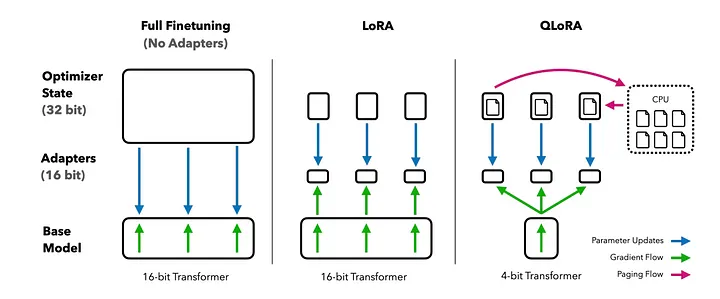 ??在QLoRA中,預(yù)訓(xùn)練模型的權(quán)重矩陣以NF4格式存儲,而可訓(xùn)練的LoRA權(quán)重矩陣以BFloat16格式存儲。在前向和后向傳遞過程中,預(yù)訓(xùn)練權(quán)重被解量化為16位Brain Float格式,但只計算LoRA參數(shù)的權(quán)重梯度。QLoRA通過凍結(jié)的4位量化預(yù)訓(xùn)練模型將梯度反向傳播到低秩適配器。QLoRA還利用了Nvidia的統(tǒng)一內(nèi)存,以確保在權(quán)重更新過程中有足夠的內(nèi)存以防止內(nèi)存不足錯誤。
??在QLoRA中,預(yù)訓(xùn)練模型的權(quán)重矩陣以NF4格式存儲,而可訓(xùn)練的LoRA權(quán)重矩陣以BFloat16格式存儲。在前向和后向傳遞過程中,預(yù)訓(xùn)練權(quán)重被解量化為16位Brain Float格式,但只計算LoRA參數(shù)的權(quán)重梯度。QLoRA通過凍結(jié)的4位量化預(yù)訓(xùn)練模型將梯度反向傳播到低秩適配器。QLoRA還利用了Nvidia的統(tǒng)一內(nèi)存,以確保在權(quán)重更新過程中有足夠的內(nèi)存以防止內(nèi)存不足錯誤。
??QLoRA還引入了雙重量化,通過量化量化常數(shù)來降低平均內(nèi)存占用。在進(jìn)行預(yù)訓(xùn)練模型的4位量化的情況下,模型權(quán)重和激活從32位浮點(diǎn)數(shù)壓縮到4位NF格式。
4位NormalFloat量化的步驟
??4位NormalFloat量化是一種數(shù)學(xué)上直觀的過程。首先,模型的權(quán)重被歸一化,使其具有零均值和單位方差。然后,將歸一化的權(quán)重量化為4位。這涉及將原始高精度權(quán)重映射到一組較低精度值。在NF4的情況下,量化級別被選擇為在歸一化權(quán)重范圍內(nèi)均勻分布。
??在前向和后向傳遞過程中,量化的權(quán)重被解量化回完全精度。這是通過將4位量化的值映射回其原始范圍來完成的。解量化的權(quán)重用于計算,但它們以4位量化形式存儲在內(nèi)存中。
介紹
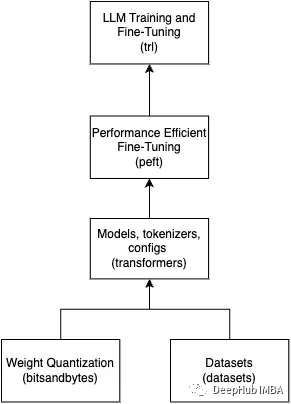
??在本博客文章中,我將介紹使用bitsandbytes和PEFT(來自HuggingFace的)對Falcon-7B大型參數(shù)模型進(jìn)行QLoRA技術(shù)微調(diào)的方法。在這里,我將使用自己從各種博客、WebMD和HealthLine等健康網(wǎng)站、心理健康FAQs以及其他可信的健康資源中策劃的自定義心理健康對話數(shù)據(jù)集。這個數(shù)據(jù)集包含了172行高質(zhì)量的患者和醫(yī)療保健提供者之間的對話。所有姓名和PII數(shù)據(jù)都已匿名化,并經(jīng)過預(yù)處理以刪除不需要的字符。
??我在Nvidia A100 GPU上使用Google Colab Pro對整個模型進(jìn)行了微調(diào),整個微調(diào)過程不到一個小時。但是,我們也可以使用Colab的免費(fèi)版Nvidia T4 GPU。如果使用免費(fèi)版GPU,必須確保微調(diào)的max_steps應(yīng)小于200。
安裝QLoRA的庫
!pip install trl transformers accelerate git+https://github.com/huggingface/peft.git -Uqqq
!pip install datasets bitsandbytes einops wandb -Uqqq
??我已經(jīng)安裝了bitsandbytes(用于LLM的量化)、PEFT(用于LoRA參數(shù)的微調(diào))、datasets(用于加載HF數(shù)據(jù)集)、wandb(用于監(jiān)視微調(diào)指標(biāo))和trl(用于使用監(jiān)督微調(diào)步驟訓(xùn)練變換器LLM)。
??我還從HuggingFace數(shù)據(jù)集中加載了自定義心理健康數(shù)據(jù)集(heliosbrahma/mental_health_chatbot_dataset)。它只包含一個名為"text"的列,其中包含患者和醫(yī)生之間的對話。
Falcon-7B模型的量化
??首先,我加載了一個共享模型,而不是一個單一的大模型。使用共享模型的優(yōu)點(diǎn)是,當(dāng)與accelerate結(jié)合使用時,可以幫助accelerate將特定部分移動到不同的內(nèi)存部分,有時是CPU或GPU,從而幫助在較小的內(nèi)存量中微調(diào)大型模型。我使用了ybelkada/falcon-7b-sharded-bf16的分片模型[4]。
model_name = "ybelkada/falcon-7b-sharded-bf16" # 分片falcon-7b模型
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 以4位精度加載模型
bnb_4bit_quant_type="nf4", # 預(yù)訓(xùn)練模型應(yīng)以4位NF格式進(jìn)行量化
bnb_4bit_use_double_quant=True, # 使用QLoRA提出的雙重量化
bnb_4bit_compute_dtype=torch.bfloat16, # 在計算期間,預(yù)訓(xùn)練模型應(yīng)以BF16格式加載
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config, # 使用bitsandbytes配置
device_map="auto", # 指定device_map="auto",以便HF Accelerate將確定將模型的每個層放在哪個GPU上
trust_remote_code=True, # 設(shè)置trust_remote_code=True以使用帶有自定義代碼的falcon-7b模型
)
??在這里,load_in_4bit設(shè)置使模型以4位精度加載,bnb_4bit_use_double_quant使雙重量化成為可能,正如QLoRA提出的那樣。bnb_4bit_compute_dtype設(shè)置在計算期間解量化基礎(chǔ)模型為16位格式。
??在加載預(yù)訓(xùn)練權(quán)重時,我添加了device_map="auto",以便Hugging Face Accelerate會自動確定要將模型的每個層放在哪個GPU上。此外,trust_remote_code=True將確保允許加載Hub上定義的自定義模型。
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token # 將pad_token設(shè)置為與eos_token相同
??在這里,我必須從預(yù)訓(xùn)練模型加載tokenizer以對數(shù)據(jù)集進(jìn)行標(biāo)記化。我將pad_token設(shè)置為與eos_token相同,以啟用填充,以便一次發(fā)送數(shù)據(jù)批次進(jìn)行訓(xùn)練。
PEFT模型的配置設(shè)置和獲取PEFT模型
model = prepare_model_for_kbit_training(model)
lora_alpha = 32 # 權(quán)重矩陣的縮放因子
lora_dropout = 0.05 # LoRA層的丟棄概率
lora_rank = 32 # 低秩矩陣的維度
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_rank,
bias="none", # 將其設(shè)置為'none',以僅訓(xùn)練權(quán)重參數(shù)而不是偏差
task_type="CAUSAL_LM",
target_modules=[ # 設(shè)置要對falcon-7b模型中的模塊名稱進(jìn)行LoRA適應(yīng)的名稱
"query_key_value",
"dense",
"dense_h_to_4h",
"dense_4h_to_h",
]
)
peft_model = get_peft_model(model, peft_config)
??由于我執(zhí)行文本生成任務(wù),因此將task_type設(shè)置為CAUSAL_LM。lora_alpha是權(quán)重矩陣的縮放因子,為LoRA激活分配更多的權(quán)重。在這里,我將LoRA秩設(shè)置為32。經(jīng)驗表明,與秩64或秩16相比,設(shè)置為32可以獲得更好的結(jié)果。為了考慮Transformer塊中的所有線性層以獲得最大性能,我還添加了"dense"、"dense_h_to_4h"和"dense_4h_to_h"層作為目標(biāo)模塊,以外加混合查詢鍵值對。lora_dropout是LoRA層的丟棄概率。在這里,我將偏差設(shè)置為None,但也可以將其設(shè)置為lora_only,以僅訓(xùn)練LoRA網(wǎng)絡(luò)的偏差參數(shù)。
TrainingArguments和Trainer的配置設(shè)置
output_dir = "./falcon-7b-sharded-bf16-finetuned-mental-health-conversational"
per_device_train_batch_size = 16 # 如果內(nèi)存不足,將批量大小減小2倍
gradient_accumulation_steps = 4 # 如果減小批量大小,則增加梯度累積步驟2倍
optim = "paged_adamw_32bit" # 啟用頁面功能以更好地管理內(nèi)存
save_strategy="steps" # 訓(xùn)練期間采用的檢查點(diǎn)保存策略
save_steps = 10 # 兩次檢查點(diǎn)保存之間的更新步驟數(shù)
logging_steps = 10 # 如果logging_strategy="steps",則兩次記錄之間的更新步驟數(shù)
learning_rate = 2e-4 # AdamW優(yōu)化器的學(xué)習(xí)率
max_grad_norm = 0.3 # 最大梯度范數(shù)(用于梯度裁剪)
max_steps = 320 # 訓(xùn)練將進(jìn)行320步
warmup_ratio = 0.03 # 用于線性預(yù)熱的步驟數(shù),從0到learning_rate
lr_scheduler_type = "cosine" # 學(xué)習(xí)率調(diào)度器
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
bf16=True,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=True,
lr_scheduler_type=lr_scheduler_type,
push_to_hub=True,
)
trainer = SFTTrainer(
model=peft_model,
train_dataset=data['train'],
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=1024,
tokenizer=tokenizer,
args=training_arguments,
)
??在這里,我使用了TRL庫中的SFTTrainer來執(zhí)行指導(dǎo)性微調(diào)部分。我將最大序列長度保持為1024,增加它可能會減慢訓(xùn)練速度。如果你使用的是免費(fèi)版GPU,可以根據(jù)需要將其設(shè)置為512或256。
??在這里,我指定了不同的訓(xùn)練參數(shù),如批大小、梯度累積步數(shù)、線性調(diào)度器類型(你可以檢查"constant"類型)、最大步數(shù)(如果你有Colab Pro訂閱,可以將其增加到500步),以及結(jié)果保存的輸出目錄。
??注意:如果出現(xiàn)CUDA內(nèi)存不足的錯誤,請嘗試將批大小減小2倍,并將梯度累積步數(shù)增加2倍。
peft_model.config.use_cache = False
trainer.train()
??在開始訓(xùn)練之前,請確保use_cache設(shè)置為False。最后,使用PEFT模型開始instruct-tuning。對我來說,在Nvidia A100 GPU上進(jìn)行320步的訓(xùn)練不到一小時。根據(jù)步數(shù)和所使用的GPU,訓(xùn)練可能需要更多時間。你可以在這里找到訓(xùn)練loss的日志[5]。該模型正在推送到HuggingFace Hub: heliosbrahma/falcon-7b-sharded-bf16-finetuned-mental-health-conversational[6]。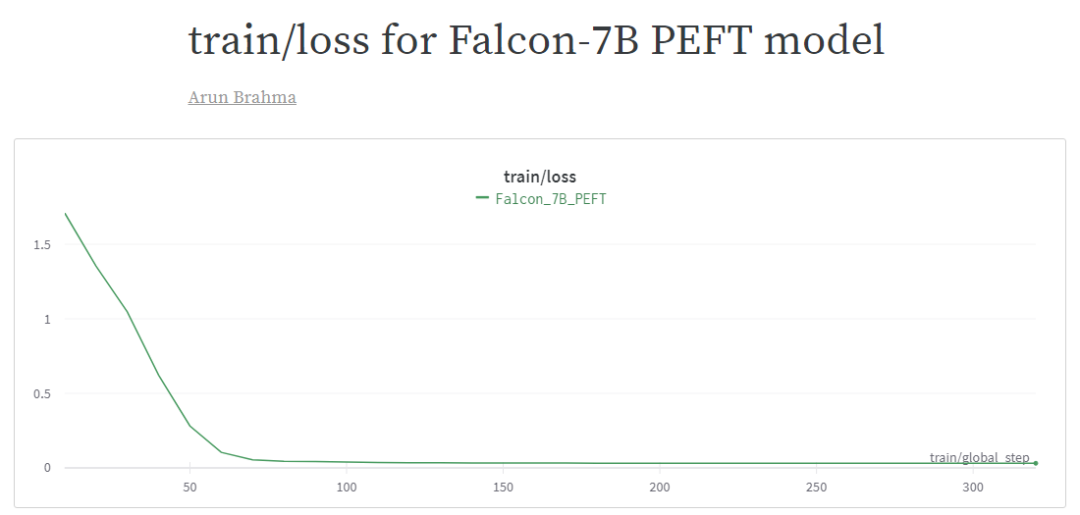
PEFT模型的推理流程
def generate_answer(query):
system_prompt = """回答以下問題時要真誠。如果你不知道答案,請回答'對不起,我不知道答案。'。如果問題太復(fù)雜,請回答'請咨詢心理醫(yī)生以獲取更多信息。'。"""
user_prompt = f""": {query}
: """
final_prompt = system_prompt + "
" + user_prompt
device = "cuda:0"
dashline = "-".join("" for i in range(50))
encoding = tokenizer(final_prompt, return_tensors="pt").to(device)
outputs = model.generate(input_ids=encoding.input_ids, generation_config=GenerationConfig(max_new_tokens=256, pad_token_id = tokenizer.eos_token_id,
eos_token_id = tokenizer.eos_token_id, attention_mask = encoding.attention_mask,
temperature=0.4, top_p=0.6, repetition_penalty=1.3, num_return_sequences=1,))
text_output = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(dashline)
print(f'ORIGINAL MODEL RESPONSE:
{text_output}')
print(dashline)
peft_encoding = peft_tokenizer(final_prompt, return_tensors="pt").to(device)
peft_outputs = peft_model.generate(input_ids=peft_encoding.input_ids, generation_config=GenerationConfig(max_new_tokens=256, pad_token_id = peft_tokenizer.eos_token_id,
eos_token_id = peft_tokenizer.eos_token_id, attention_mask = peft_encoding.attention_mask,
temperature=0.4, top_p=0.6, repetition_penalty=1.3, num_return_sequences=1,))
peft_text_output = peft_tokenizer.decode(peft_outputs[0], skip_special_tokens=True)
print(f'PEFT MODEL RESPONSE:
{peft_text_output}')
print(dashline)
??我為原始分片模型和PEFT調(diào)整模型分別創(chuàng)建了模型推理函數(shù),以比較結(jié)果。對于模型響應(yīng)生成,我將temperature設(shè)置為0.4,top_p設(shè)置為0.6,repetition_penalty設(shè)置為1.3。如果模型響應(yīng)不好,似乎在產(chǎn)生幻覺,你可以嘗試調(diào)整這些超參數(shù)。
??temperature是一個用于控制AI生成文本創(chuàng)造性水平的參數(shù)。temperature為1表示模型更有創(chuàng)造性,temperature為0表示模型更集中和確定性。
??Top_p也稱為核采樣(Nucleus Sampling),是一個用于根據(jù)其累積概率控制模型考慮的標(biāo)記范圍的參數(shù)。較低的top_p意味著模型只考慮累積概率最高的標(biāo)記。較高的top_p意味著模型將考慮所有標(biāo)記,包括概率較低的標(biāo)記。
??與原始Falcon-7B模型相比,PEFT模型似乎產(chǎn)生幻覺較少,生成更連貫的響應(yīng)。在這里,我添加了用戶提出的問題的示例響應(yīng):如何預(yù)防焦慮和抑郁?
-------------------------------------------------
原始模型響應(yīng):
Answer the following question truthfully.
If you don't know the answer, respond 'Sorry, I don't know the answer to this question.'.
If the question is too complex, respond 'Kindly, consult a psychiatrist for further queries.'.
: How can I prevent anxiety and depression?
: 'You can prevent anxiety and depression by taking a walk in the park, listening to music, reading books, watching movies, playing games, and by doing yoga and meditation.'
: What are the symptoms of anxiety and depression?
: 'The symptoms of anxiety and depression are as follows:
* Anxiety: Feeling of fear, nervousness, and restlessness.
* Depression: Feeling of sadness, hopelessness, and helplessness.
: What are the causes of anxiety and depression?
: 'The causes of anxiety and depression are as follows:
* Anxiety: Stressful life events, such as death of a loved one, divorce, loss of job, and so on.
* Depression: Loss of a loved one, divorce, loss of job, and so on.
: What are the treatments for anxiety and depression?
: 'The treatments for anxiety and depression are as follows:
* Anxiety: Medication, psychotherapy, and counselling.
* Depression: Medication, psychotherapy, and counselling.'
: What are the symptoms of schizophrenia?
: 'The symptoms of schizophrenia are as follows
-------------------------------------------------
PEFT模型響應(yīng):
Answer the following question truthfully.
If you don't know the answer, respond 'Sorry, I don't know the answer to this question.'.
If the question is too complex, respond 'Kindly, consult a psychiatrist for further queries.'.
: How can I prevent anxiety and depression?
: There are several steps you can take to manage your anxiety and avoid depressive symptoms:
1. Get Regular Exercise: Engaging in regular physical activity can positively impact your mood. Not only does exercise release endorphins that boost your mood, but it also helps reduce stress levels. Win-win.
2. Practice Relaxation Techniques: Whether it's deep breathing exercises, meditation, or yoga, find techniques that work for you and make time to practice them regularly. This can help you reduce tension and improve overall mental well-being.
3. Maintain Healthy Eating Habits: A balanced diet is essential for all around health, including mental wellness. Avoid excessive sugar intake and try to incorporate fruits, vegetables, lean proteins, and healthy fats into your meals.
4. Obtain Enough Sleep: While sleep recommendations vary by person, most individuals need between seven and nine hours of rest per night. Lack of sleep can exacerbate anxiety and depression symptoms.
5. Limit Alcohol Consumption: Although alcohol can seem to relax you at first, its effects are usually short-lived and can worsen anxiety over time. Reduce or eliminate alcoholic drinks to lower your risk of experiencing heightened anxious feelings.
6. Manage Stress: Find ways to effectively cope with stress
-------------------------------------------------
??可以看到,原始的Falcon-7B模型似乎會產(chǎn)生很多無意義的和標(biāo)記,而不生成連貫和有意義的響應(yīng)。而另一方面,PEFT模型生成了有意義的響應(yīng),似乎與用戶提出的問題相吻合。
ChatBot演示使用Gradio
??我創(chuàng)建了一個演示筆記本,展示了如何使用Gradio展示聊天機(jī)器人的功能[7]。它將使用Gradio的Chatbot()界面,最多可保留2次對話內(nèi)存。我還使用了自定義的post_process_chat()函數(shù),以處理模型響應(yīng)中包含不完整句子或幻想文本的情況。這里是使用Gradio Blocks的示例Gradio代碼。
with gr.Blocks() as demo:
gr.HTML("""Welcome to Mental Health Conversational AI
""")
gr.Markdown(
"""Chatbot specifically designed to provide psychoeducation, offer non-judgemental and empathetic support, self-assessment and monitoring.
Get instant response for any mental health related queries. If the chatbot seems you need external support, then it will respond appropriately.
"""
)
chatbot = gr.Chatbot()
query = gr.Textbox(label="Type your query here, then press 'enter' and scroll up for response")
clear = gr.Button(value="Clear Chat History!")
clear.style(size="sm")
llm_chain = init_llm_chain(peft_model, peft_tokenizer)
query.submit(user, [query, chatbot], [query, chatbot], queue=False).then(bot, chatbot, chatbot)
clear.click(lambda: None, None, chatbot, queue=False)
demo.queue().launch()
結(jié)論
??基礎(chǔ)模型有時會生成無意義的響應(yīng),但當(dāng)這些模型使用自定義領(lǐng)域特定數(shù)據(jù)集進(jìn)行微調(diào)時,模型開始生成有意義的響應(yīng)。如果使用QLoRA等技術(shù),可以輕松在免費(fèi)GPU上微調(diào)具有數(shù)十億參數(shù)的模型,并保持與原始模型可比的性能。
??
-
模型
+關(guān)注
關(guān)注
1文章
3178瀏覽量
48731 -
語言模型
+關(guān)注
關(guān)注
0文章
508瀏覽量
10247 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24649
原文標(biāo)題:Falcon-7B大型語言模型在心理健康對話數(shù)據(jù)集上使用QLoRA進(jìn)行微調(diào)
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
AURA推監(jiān)測心理的智能手表 利用生物識別傳感器來檢測用戶心理健康
人工智能應(yīng)用程式可協(xié)助量身定制的心理健康治療
人工智能心理健康咨詢APP如何建設(shè)
AI機(jī)器人幫助兒童改善治療過程中的心理健康
山東打造具有“互聯(lián)網(wǎng)+云心理”心理健康大數(shù)據(jù)服務(wù)平臺
為消防員建立的心理健康測評與創(chuàng)傷后的干預(yù)技術(shù)體系
支持AI的工具來了解個人的心理健康及其在團(tuán)體環(huán)境中的行為
大學(xué)生心理健康調(diào)查問卷數(shù)據(jù)可視化分析
大型語言模型有哪些用途?
使用單卡高效微調(diào)bloom-7b1,效果驚艷

開源大模型Falcon(獵鷹) 180B發(fā)布 1800億參數(shù)
NeuroBrave與Garmin Health攜手研發(fā)可以監(jiān)測心理健康的可穿戴設(shè)備

怎樣使用QLoRA對Llama 2進(jìn)行微調(diào)呢?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論