 如何通過以可忽略的性能開銷提高QLC閃存的可靠性?
如何通過以可忽略的性能開銷提高QLC閃存的可靠性?
本工作來自多倫多大學和谷歌Shehbaz Jaffer,發表于FAST 2022。為了解決下一代高密度閃存低耐久性帶來的可靠性挑戰,提出新的編碼WOM-v (Voltage-based Write-Once-Memory),來提高SSD的使用壽命。通過重編程的方式,增加擦除操作間的編寫次數來應對高密度閃存有限擦除次數的瓶頸問題。本文基于FEMU+LightNVM平臺,實現WOM-v碼,并基于FEMU實現QLC模擬。展示如何通過以可忽略的性能開銷提高QLC閃存的壽命4.4x-11.1x。WOM-v開源代碼:
01背景&問題
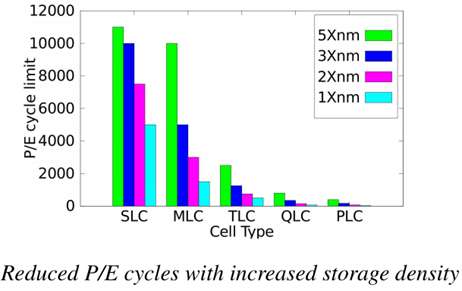
隨著閃存密度的增加,其可承受的擦除次數逐漸減少。如下圖所示。QLC的擦除次數不到1000次,而PLC僅為幾十至幾百次。特別是存儲元尺寸小,擦除次數就更少了。針對這個問題,本文將從WOM編碼的角度探索如何通過增加重編程次數來降低擦除次數。下面首先討論傳統binary-WOM碼的原理及缺陷。
Binary-WOM codes
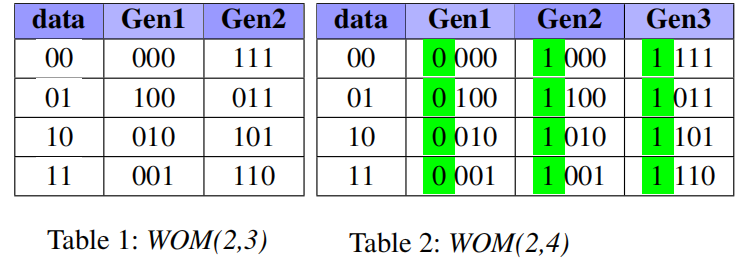
Binary-WOM應用于較早的存儲設備上,例如Punch Card。在這類介質上,數據以位為粒度寫入,并且一旦寫入,位只能在一個方向上更改。例如,只能從比特0變換到比特1。表1和表2給出的是WOM(2,3)和WOM(2,4),對于WOM(2,3),表示數據存儲兩位,但實際存儲三位。可以看作底層是TLC閃存,抽象出MLC閃存。對于每個TLC頁面,可以編程兩次(兩代)。第一代和第二代中的比特位是TLC三位組成的8種形式。因此,通過這種方式,兩次編程后,實際寫入的數據為2+2=4bits,比TLC的3bits要多。
然而,Binary-WOM不適合新一代的閃存,如QLC。對于閃存存儲元的真正限制是,電壓值總是增加(達到最大電壓Vmax),但不能降低,這與編碼的位值無關。堅持采用二進制模型會產生不必要的約束。
經過作者的測試發現,存儲元中比特數量與其能夠支持的重編程次數成反比關系。存儲元每多增加一個比特,可實現的重編程次數少一個數量級。因此,WOM碼本身的寫放大,對QLC使用binary-WOM沒有凈增益。
02WOM-v Code
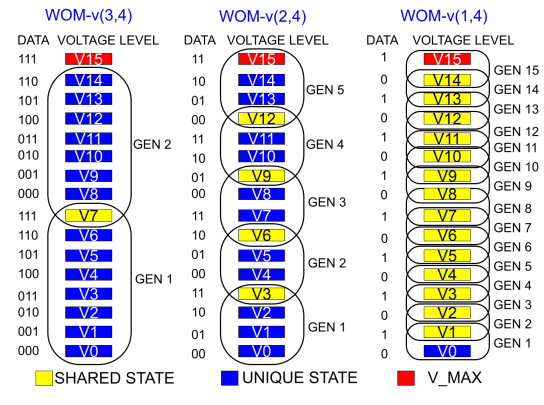
為了解決上述問題,本文設計了新的編碼WOM-v (Voltage-based Write-Once-Memory),實現更高的寫入量。WOM-v碼借助于閃存編程的特征(往存儲元中存儲電荷)。編程以ISPP方式總是由低電壓編程到高電壓。因此,可以將電壓分布范圍劃分成多個GEN,一個GEN中包含的電壓區間表示一次編程可以到達的電壓值。以QLC為例,存儲元中存儲4個比特,可以形成16種電壓狀態(V0-V15)。如下圖所示,可以有WOM-v(3,4), WOM-v(2,4), WOM-v(1,4)。事實上,WOM-v(3,4)就是將QLC看作TLC使用,用戶存儲3個數據字,而實際存儲4位碼字。由于每次表示3位,因此單次編程只需要8個狀態。這樣QLC的16個狀態就可以編程兩次。更高階WOM-v(2,4)則可以編程16/4=4次。
基于上述思想,有以下幾個優化點:
1)同代轉換:是指重編程后,存儲元的電壓狀態還在同個GEN中。具體來說,在編程時,若編程后的DATA可以用當前電壓值和當前GEN的最大電壓值之間的電壓狀態表示時,同一個GEN內部也可以重編程。例如,當前是001(V1),編程后為101。那么無需進入GEN2,編程到GEN1中的V5即可,并做好記錄;此優化點的問題是會產生寫前讀,每次重編程之前需要通過一次讀取來確定存儲元的電壓狀態。本文進一步提出NR模式來權衡是否采取此優化點。
2)碼字共享:WOM-v(3,4)中的電壓狀態V7在GEN1和GEN2之間是共享的。數據111在GEN1和GEN2中都映射到V7。這種共享讓我們可以擠出更多的重編程代數。例如,WOM-v(2,4)原先是4代,共享后為5代。
3)利用ECC容錯空間:當寫發生在頁面粒度(而不是存儲元)上時,一旦頁面的任何一個存儲元達到GEN_MAX,就不能再重編程。”當頁面中少量存儲元達到GEN_MAX的情況下,繼續進行頁面重編程而不擦除“。要實現上述目標,可以利用設備中的ECC糾錯碼的容錯空間。通過標記少量已達到GEN_MAX的存儲元為無效,剩余存儲元組成的頁面可繼續執行重編程。而這些標記無效的存儲元的值可以通過現有ECC來確定。當然,無效存儲元的數量超過ECC_Threshold時,當前頁面無法進行后續重編程,需要先執行擦除。
03系統實現
本文在Linux LightNVM Open-Channel SSD子系統模塊中實現了WOM-v碼,它允許在FTL中進行更改。并擴展FEMU來模擬QLC設備。通過WOM-v的系統實現,可以測試在SSD中實際減少的擦除次數(以EU為粒度執行擦除操作),以及評估在理論上無法準確收集的input data contents、workload patterns和performance overhead。
LightNVM架構
LightNVM是一個Linux模塊,它向主機公開了NVMe SSD的底層體系結構。有助于對讀寫方式進行修改,也能夠控制垃圾回收,以及何時應該在底層設備上執行擦除操作。LightNVM的內部體系結構如下圖所示。LightNVM模塊的兩個主要數據結構是1) Ring Buffer和2) Parallel Units。
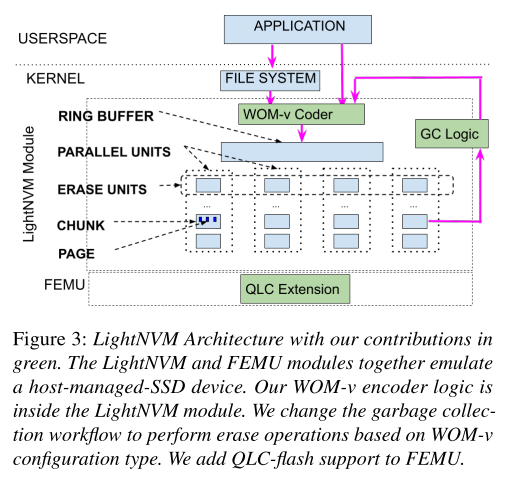
要將WOM-v碼合并到LightNVM代碼中,需要做以下更改:
1)對設備的所有寫入操作都需要進行編碼。
2)發布給設備的所有讀取都需要解碼以前編寫的數據。編碼和解碼涉及到簡單的表查找。
3)需要修改默認的垃圾回收邏輯。與其在垃圾回收過程中擦除所有的EU,現在應該根據EU內部頁面的狀態(是否達到GEN_MAX)有選擇地進行擦除。也就是說,如果垃圾回收選擇的EU中頁面未達到GEN_MAX,則只需要回收有效頁面而無需擦除,回收后可與空閑資源一樣拿過來直接覆蓋寫。
4)底層設備模擬器需要支持下一代配備QLC或更密集閃存介質的SSD設備。
5)本文進一步實現了兩種優化,GC_OPT和NR模式,有助于提高性能和減少WOM-v的開銷。
基本實現
將以下組件添加到LightNVM模塊中:1) 編碼和解碼邏輯;2) WOM-v感知的垃圾回收邏輯;3) 基于FEMU的QLC支持。
寫入操作:應用程序或文件系統可以向LightNVM提交寫請求。所有寫數據在寫入設備之前都進行編碼。默認情況下,WOM編碼首先讀取設備上先前寫入的數據(查看當前編程到哪一代了)。由于這種默認方法會帶來寫前讀。在將環形緩沖區數據寫入設備之前,在環形緩沖區中暫存頁面的邏輯塊地址(LBA)與設備物理頁地址(PPA)之間創建一個映射。在此階段,攔截所有的寫操作,并執行以下轉換:1)對正在寫入的所有頁面的PPA中讀取預先存在的編碼數據;2)使用現有的數據對頁面進行再編碼;3)將新的編碼頁面寫入設備。
讀取操作:在讀取工作流中,來自應用程序的原始讀取bio請求首先被轉換為相應的連續LBA地址bio請求。由于邏輯頁面的局部性,連續的頁面對應于單個頁面。接下來,所有被讀取的編碼頁面都在讀取返回路徑中被解碼。解碼后的數據被復制到最初提交的bio請求中,并且可以被應用程序讀取而無需修改。
垃圾回收:傳統的GC是回收有效頁面后直接擦除才能使用,然而本文使用的WOM-v碼下,頁面可重編程。因此只有當EU中任何一個頁面達到最大可重編程次數后才會被擦除。所以每次GC只需要回收有效頁面而不需要執行擦除操作。
一個WOM-v(k,N)方案可以自然地擴展到任何N級存儲元,通過將N的值更改為設備的每個存儲元的位數。k的值決定了容量和壽命的權衡——較低的k值會產生更高的閃存壽命,但也會消耗更多的物理空間。
WOM-v優化
GC_OPT模式:解決GC期間有效頁面回收帶來的寫放大問題,進一步提高了SSD的耐久性。關鍵的觀察是,在大多數情況下,如果EU中的無效頁面可以被重寫,則無需執行擦除。這意味著,在EU不需要擦除的情況下,我們可以保留有效頁面,只要我們在未來寫入EU時跳過這些有效頁面。塊中剩余的無效頁面將以與以前相同的特定順序被覆蓋,以減少單元間的干擾,并像以前一樣在EU的并行單元上條帶化寫入。
No_Read(NR)模式:解決寫前讀問題。由于采用同代轉換,在數據寫入存儲元之前,需要知道存儲元的內容,確定其處于哪一代的哪一個電壓狀態。因此,每次寫都需要先讀一次。如何消除寫前讀:去掉同代轉換,只在GEN之間轉換。通過記錄當前編程的代數,下一次編程直接跳轉到下一代。NR模式可優化性能,但對耐久性有輕微影響。
04實驗評估
實驗采用微基準測試負載和真實世界收集的負載進行評估。
1.微基準測試負載
1)數據緩沖區內容變化的影響
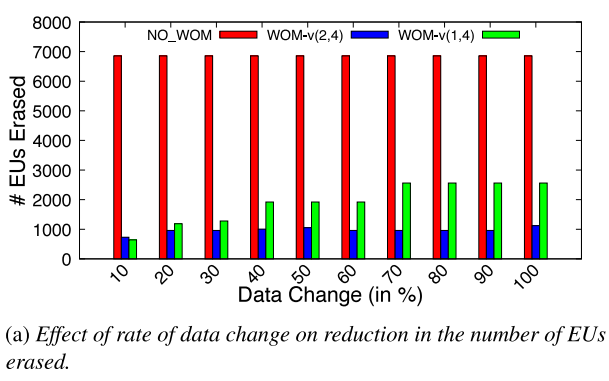
由于WOM-v(k,N)碼可能發生同代轉換,因此其收益取決于被覆蓋到已有數據塊的數據內容。通過順序填充設備,一旦設備滿,翻轉數據緩沖區中所有位的一部分(10%-100%),然后用修改后的數據再次填充整個設備。重復這一過程多次,并比較隨著數據緩沖區內容變化速率的增加而被擦除的EU數量。
下圖顯示了在寫入期間因不同數據緩沖區內容而擦除的EU總數。與NO_WOM相比,WOM-v減少了被擦除的EU數量。然而,當后續寫入之間的數據變化速率較小時,存儲元達到Vmax的速率將會更慢。對于數據變化量較大的負載,將更快地達到Vmax,因此EU擦除增益將更低。NO_WOM與數據緩沖區內容無關。
2)訪問模式的影響
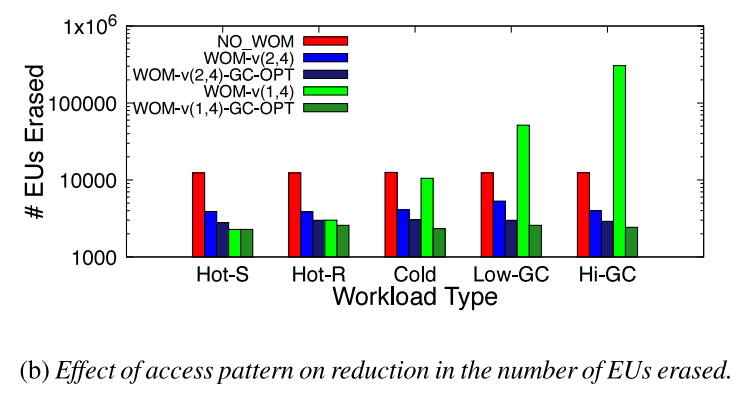
為了衡量訪問模式的影響,以特定順序寫入來無效先前寫入的數據,來產生不同程度的設備寫放大。Hot-S是順序更新數據,Hot-R是隨機更新數據,Hot-S和Hot-R下保證所有的頁面都是熱寫的并且垃圾回收中不產生寫放大。Cold是只更新一小部分頁面,Low-GC和High-GC則產生不同程度的垃圾回收操作。
下圖顯示了在不同負載模式下被擦除的EU的數量。WOM-v(2,4)顯著減少了被擦除的EU數量。然而,由于GC導致的寫放大增加,WOM-v(1,4)的收益不斷減少。最后,GC-OPT模式能保持較低的寫放大開銷。
2. 真實世界負載
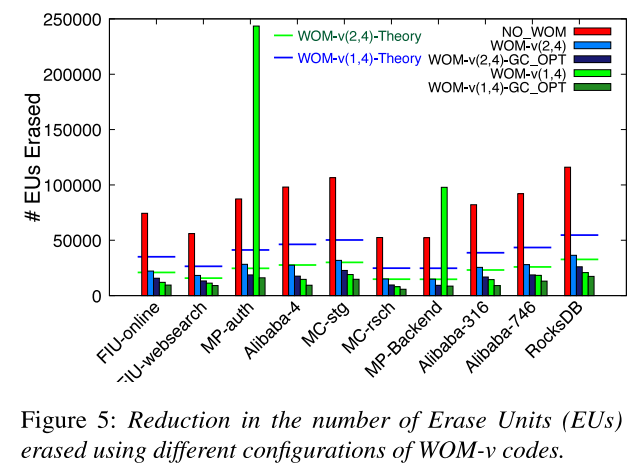
所有方法下物理空間一樣大,并預先填充一半容量的數據。根據負載的footprint設置QLC容量大小。所有WOM-v(2,4)設置的邏輯地址空間是NO_WOM的邏輯地址空間的一半。同樣,WOM-v(1,4)設置的邏輯地址空間是NO_WOM的邏輯地址空間的四分之一。
1)壽命評估
WOM-v(2,4)減少EU擦除次數為68%-71%。針對GC密集型工作負載(MP-auth和MP-Backend),WOM-v(1,4)的性能不佳。這表明,WOM-v碼通過重編程所帶來的擦除操作的減少并不能彌補較高速率碼所帶來的寫放大。引入GC_OPT后可以顯著降低垃圾回收過程產生的寫放大。與NO_WOM相比,WOM-v(2,4)-GC-OPT的擦除次數減少了77-83%,WOM-v(1,4)-GC-OPT減少了82-91%。這意味著在現實負載中,擦除操作減少了4.4-11.1×。
2) 性能評估
由于WOM需要寫前讀來確定當前寫的代數,會影響寫性能,并提出了WOM-v_NR來優化性能(可能以降低耐久性增益為代價)。
由于WOM-v(k,N)產生的更高的寫入量(寫k比特的數據實際寫N比特,導致每次寫入都要添加額外的(N/k)數據)。
平均性能和吞吐量:與NO_WOM相比,WOM-v(2,4)的性能開銷相當小(需要寫前讀),在3-8%的范圍內。添加NR模式消除了這些性能開銷,與NO_WOM差不多。同時,與WOM-v(2,4)相比,啟用NR模式對耐久性影響不大。同時啟用GC_OPT和NR模式大大降低了WOM-v(1,4)方案的性能開銷,使性能在NO_WOM的0-8%以內。并且對比NO_WOM顯著改善耐久性。
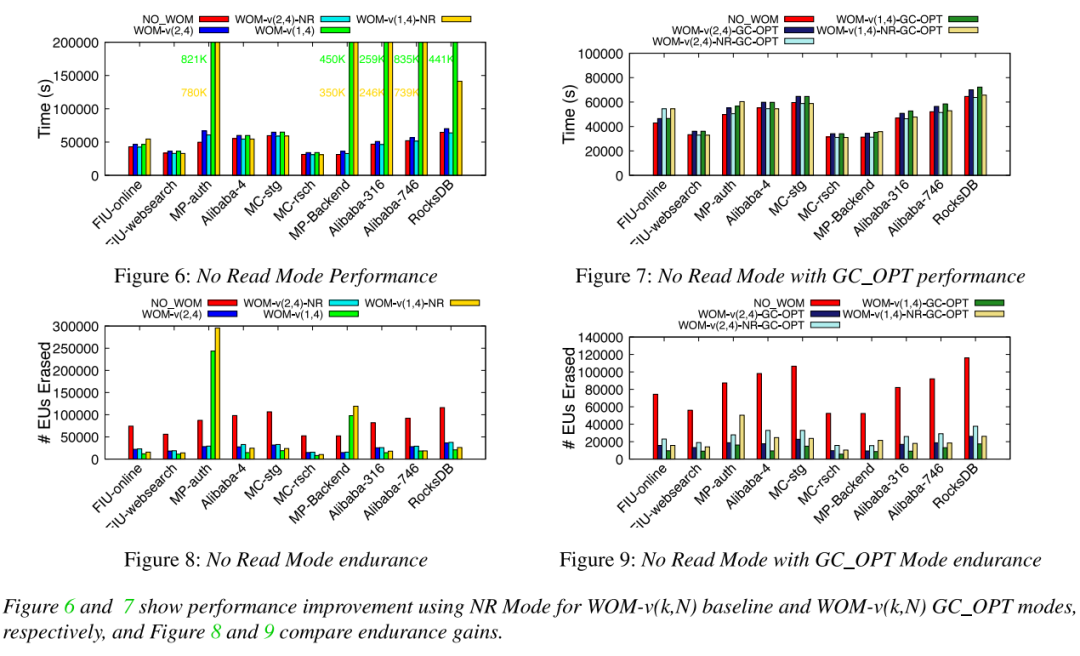
讀尾端延遲:評估讀取密集型負載的尾端延遲。觀察到NO_WOM和WOM-v(k,N)基線編碼方案的第95百分位尾端延遲為0.6-7%,并且沒有引入較大的尾端延遲。
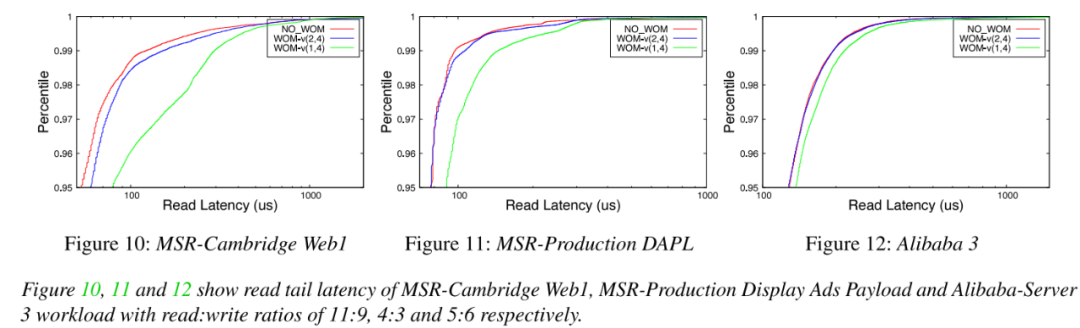
05總結
本文針對下一代高密度閃存提出一種新的編碼方案,可以有效降低擦除次數,從而改善閃存壽命。即使對于高寫放大的負載,WOM-v碼也可以通過GC_OPT模式優化;對性能關鍵型負載,可以采用NR模式進行優化WOM-v使用時的性能問題。另外,WOM-v碼本身的寫放大問題可能是對空間利用率要求高的SSD所關注的。對于這樣的設備,本文建議根據設備的使用情況或工作負載的容量要求,在具有不同碼率的WOM-v碼之間進行常規轉換。WOM-v碼可以很容易地擴展到更高密度的未來SSD,如PLC SSD和更復雜的編碼方案。
審核編輯:劉清
-
存儲器
+關注
關注
38文章
7317瀏覽量
162880 -
二進制
+關注
關注
2文章
741瀏覽量
41426 -
TLC
+關注
關注
0文章
135瀏覽量
51394 -
ECC
+關注
關注
0文章
91瀏覽量
20437 -
qlc閃存
+關注
關注
0文章
12瀏覽量
3997
原文標題:如何提升下一代高密度閃存的可靠性
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何提高電源系統設計的可靠性






 工商網監
工商網監
評論