") 10分鐘快速了解神經(jīng)網(wǎng)絡(luò)(Neural Networks)
10分鐘快速了解神經(jīng)網(wǎng)絡(luò)(Neural Networks)
Sadaf Saleem| 作者
羅伯特|編輯
神經(jīng)網(wǎng)絡(luò)是深度學(xué)習(xí)算法的基本構(gòu)建模塊。神經(jīng)網(wǎng)絡(luò)是一種機(jī)器學(xué)習(xí)算法,旨在模擬人腦的行為。它由相互連接的節(jié)點(diǎn)組成,也稱為人工神經(jīng)元,這些節(jié)點(diǎn)組織成層次結(jié)構(gòu)。
神經(jīng)網(wǎng)絡(luò)與機(jī)器學(xué)習(xí)有何不同?
神經(jīng)網(wǎng)絡(luò)是一種機(jī)器學(xué)習(xí)算法,但它們與傳統(tǒng)機(jī)器學(xué)習(xí)在幾個(gè)關(guān)鍵方面有所不同。最重要的是,神經(jīng)網(wǎng)絡(luò)可以自行學(xué)習(xí)和改進(jìn),無需人的干預(yù)。它可以直接從數(shù)據(jù)中學(xué)習(xí)特征,因此更適合處理大型數(shù)據(jù)集。然而,在傳統(tǒng)機(jī)器學(xué)習(xí)中,特征需要手動(dòng)提供。
為什么使用深度學(xué)習(xí)?
深度學(xué)習(xí)的一個(gè)關(guān)鍵優(yōu)勢(shì)是其處理大數(shù)據(jù)的能力。隨著數(shù)據(jù)量的增加,傳統(tǒng)機(jī)器學(xué)習(xí)技術(shù)在性能和準(zhǔn)確性方面可能變得低效。而深度學(xué)習(xí)則能夠持續(xù)表現(xiàn)出色,因此是處理數(shù)據(jù)密集型應(yīng)用的理想選擇。
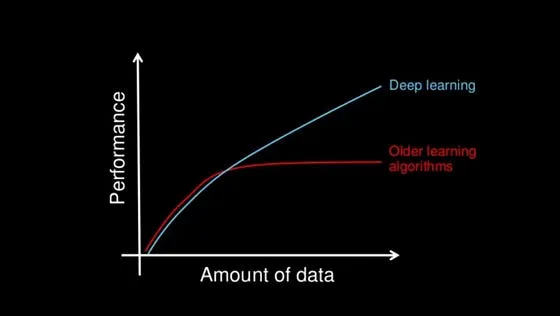
有人會(huì)問,為什么我們要費(fèi)心研究深度學(xué)習(xí)的結(jié)構(gòu),而不是簡(jiǎn)單地依賴計(jì)算機(jī)為我們生成輸出結(jié)果,這是一個(gè)合理的問題。然而,深入了解深度學(xué)習(xí)的底層結(jié)構(gòu)可以帶來更好的結(jié)果,這其中有很多令人信服的理由。
研究深度學(xué)習(xí)結(jié)構(gòu)的好處是什么?
通過分析神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),我們可以找到優(yōu)化性能的方法。例如,我們可以調(diào)整層數(shù)或節(jié)點(diǎn)的數(shù)量,或者調(diào)整網(wǎng)絡(luò)處理輸入數(shù)據(jù)的方式。我們還可以開發(fā)更適合分析醫(yī)學(xué)圖像或預(yù)測(cè)股市的神經(jīng)網(wǎng)絡(luò)。如果我們知道網(wǎng)絡(luò)中的哪些節(jié)點(diǎn)對(duì)于特定輸入被激活,我們可以更好地理解網(wǎng)絡(luò)是如何做出決策或預(yù)測(cè)的。
神經(jīng)網(wǎng)絡(luò)如何工作?
每個(gè)神經(jīng)元代表一個(gè)計(jì)算單元,接收一組輸入,執(zhí)行一系列計(jì)算,并產(chǎn)生一個(gè)輸出,該輸出傳遞給下一層。
就像我們大腦中的神經(jīng)元一樣,神經(jīng)網(wǎng)絡(luò)中的每個(gè)節(jié)點(diǎn)都接收輸入,處理它,并將輸出傳遞給下一個(gè)節(jié)點(diǎn)。隨著數(shù)據(jù)在網(wǎng)絡(luò)中傳遞,節(jié)點(diǎn)之間的連接會(huì)根據(jù)數(shù)據(jù)中的模式而加強(qiáng)或減弱。這使得網(wǎng)絡(luò)可以從數(shù)據(jù)中學(xué)習(xí),并根據(jù)其學(xué)到的知識(shí)進(jìn)行預(yù)測(cè)或決策。
想象一個(gè)28x28的網(wǎng)格,其中某些像素比其他像素更暗。通過識(shí)別較亮的像素,我們可以解讀出在網(wǎng)格上寫的數(shù)字。這個(gè)網(wǎng)格作為神經(jīng)網(wǎng)絡(luò)的輸入。
網(wǎng)格的行排列成水平的一維數(shù)組,然后轉(zhuǎn)化為垂直數(shù)組,形成第一層神經(jīng)元,就像這樣;
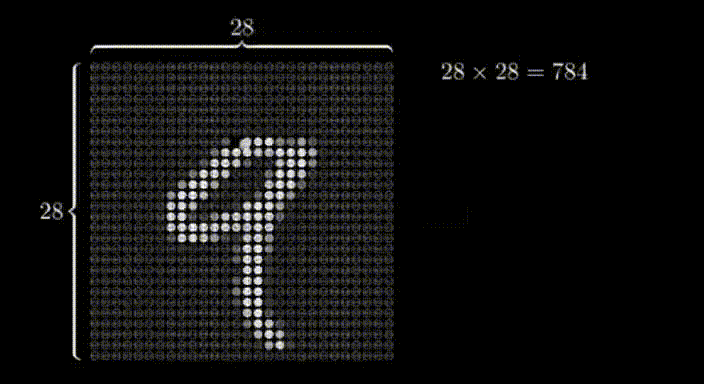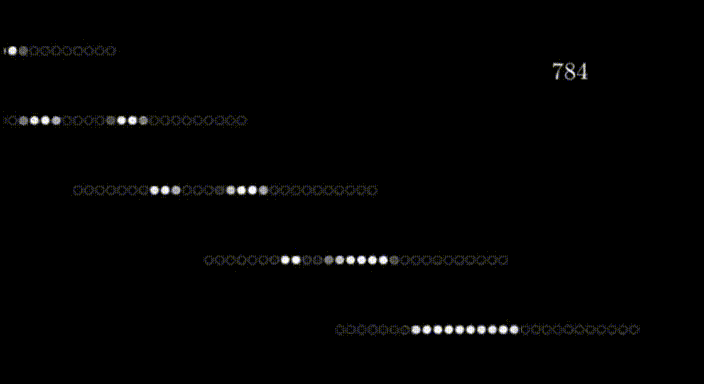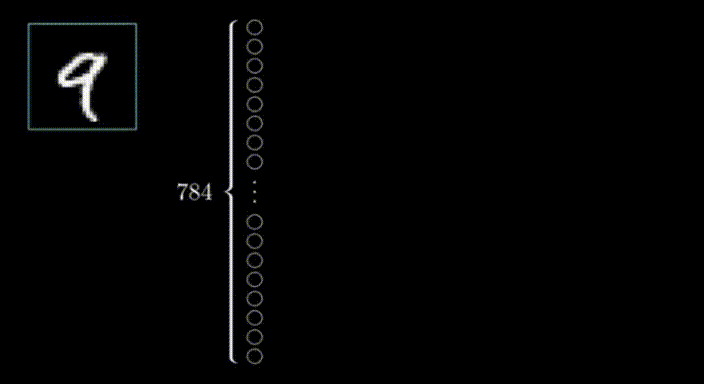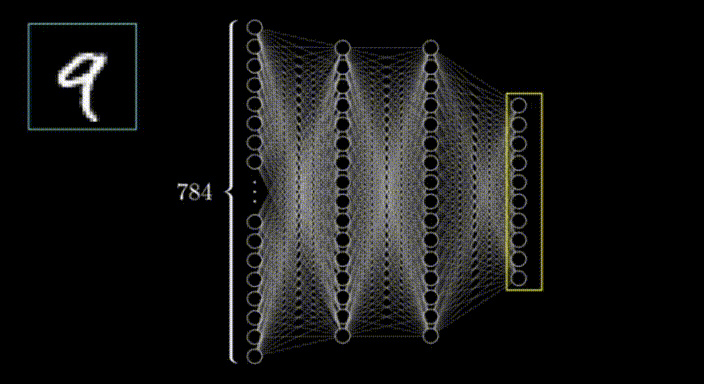
在第一層的情況下,每個(gè)神經(jīng)元對(duì)應(yīng)于輸入圖像中的一個(gè)像素,每個(gè)神經(jīng)元內(nèi)的值代表該像素的激活或強(qiáng)度。神經(jīng)網(wǎng)絡(luò)的輸入層負(fù)責(zé)接收原始數(shù)據(jù)(在本例中是圖像)并將其轉(zhuǎn)化為可以被網(wǎng)絡(luò)其余部分處理的格式。
在這種情況下,我們有28x28個(gè)輸入像素,這給了我們784個(gè)輸入層的神經(jīng)元。每個(gè)神經(jīng)元的激活值要么是0,要么是1,這取決于輸入圖像中相應(yīng)的像素是黑色還是白色。

神經(jīng)網(wǎng)絡(luò)的輸出層在這種情況下包括10個(gè)神經(jīng)元,每個(gè)代表一個(gè)可能的輸出類別(在本例中是數(shù)字0到9)。輸出層中每個(gè)神經(jīng)元的輸出代表輸入圖像屬于該特定類別的概率。最高概率值確定了對(duì)于該輸入圖像的預(yù)測(cè)類別。
隱藏層
在輸入層和輸出層之間,我們有一個(gè)或多個(gè)隱藏層,對(duì)輸入數(shù)據(jù)執(zhí)行一系列非線性變換。這些隱藏層的目的是從輸入數(shù)據(jù)中提取對(duì)當(dāng)前任務(wù)更有意義的高級(jí)特征。您可以決定在網(wǎng)絡(luò)中添加多少隱藏層。
隱藏層中的每個(gè)神經(jīng)元都從前一層的所有神經(jīng)元接收輸入,并在將結(jié)果通過非線性激活函數(shù)之前,對(duì)這些輸入應(yīng)用一組權(quán)重和偏差。這個(gè)過程在隱藏層的所有神經(jīng)元上重復(fù),直到達(dá)到輸出層。
前向傳播
前向傳播是將輸入數(shù)據(jù)通過神經(jīng)網(wǎng)絡(luò)生成輸出的過程。它涉及計(jì)算網(wǎng)絡(luò)每一層中每個(gè)神經(jīng)元的輸出,通過將權(quán)重和偏差應(yīng)用于輸入并通過激活函數(shù)傳遞結(jié)果來完成。
數(shù)學(xué)公式:或 其中, 是神經(jīng)網(wǎng)絡(luò)的輸出, 是非線性激活函數(shù),是第 個(gè)輸入特征或輸入變量, 是與第個(gè)輸入特征或變量相關(guān)聯(lián)的權(quán)重, 是偏差項(xiàng),它是一個(gè)常數(shù)值,加到輸入的線性組合上。 :這是輸入特征和它們相關(guān)權(quán)重的線性組合。有時(shí)這個(gè)術(shù)語也被稱為輸入的“加權(quán)和”。
反向傳播
反向傳播是訓(xùn)練神經(jīng)網(wǎng)絡(luò)中常用的算法。它涉及計(jì)算梯度,即損失函數(shù)相對(duì)于網(wǎng)絡(luò)中每個(gè)權(quán)重的變化的度量。損失函數(shù)衡量了神經(jīng)網(wǎng)絡(luò)在給定輸入下能夠正確預(yù)測(cè)輸出的能力。通過計(jì)算損失函數(shù)的梯度,反向傳播允許神經(jīng)網(wǎng)絡(luò)以減小訓(xùn)練過程中的整體誤差或損失的方式更新其權(quán)重。
該算法通過將來自輸出層的誤差沿著網(wǎng)絡(luò)的層傳播回去,使用微積分的鏈?zhǔn)椒▌t計(jì)算損失函數(shù)相對(duì)于每個(gè)權(quán)重的梯度。然后,這個(gè)梯度用于梯度下降優(yōu)化,以更新權(quán)重并最小化損失函數(shù)。
神經(jīng)網(wǎng)絡(luò)中使用的術(shù)語
神經(jīng)網(wǎng)絡(luò)的訓(xùn)練是根據(jù)輸入數(shù)據(jù)和期望輸出來調(diào)整神經(jīng)網(wǎng)絡(luò)權(quán)重的過程,以提高網(wǎng)絡(luò)預(yù)測(cè)的準(zhǔn)確性。權(quán)重:權(quán)重是在訓(xùn)練過程中學(xué)到的參數(shù),它們決定了神經(jīng)元之間連接的強(qiáng)度。每個(gè)神經(jīng)元之間的連接被分配一個(gè)權(quán)重,該權(quán)重與輸入值相乘,以確定其輸出。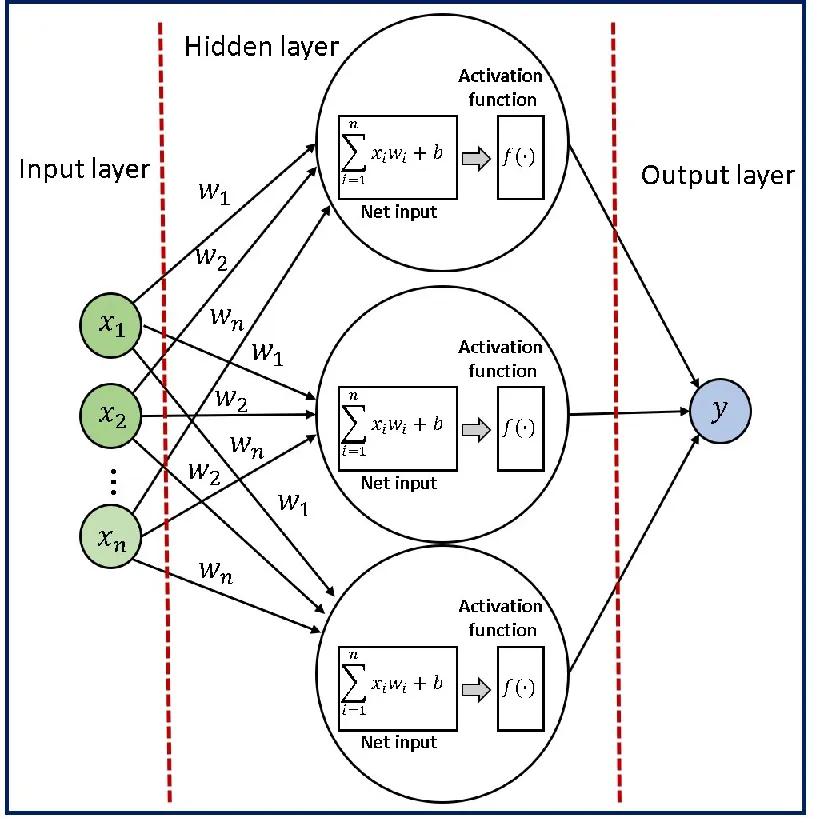
偏差(Bias):偏差是另一個(gè)在給定層中神經(jīng)元的加權(quán)和上添加的學(xué)習(xí)參數(shù)。它是神經(jīng)元的附加輸入,有助于調(diào)整激活函數(shù)的輸出。
非線性激活函數(shù)(Non-linear activation function):非線性激活函數(shù)應(yīng)用于神經(jīng)元的輸出,引入了網(wǎng)絡(luò)中的非線性。非線性很重要,因?yàn)樗试S網(wǎng)絡(luò)建模輸入和輸出之間的復(fù)雜、非線性關(guān)系。在神經(jīng)網(wǎng)絡(luò)中常用的激活函數(shù)包括 Sigmoid 函數(shù)、ReLU(修正線性單元)函數(shù)和 softmax 函數(shù)。損失函數(shù)(Loss function):這是一個(gè)數(shù)學(xué)函數(shù),用于衡量神經(jīng)網(wǎng)絡(luò)的預(yù)測(cè)輸出與真實(shí)輸出之間的誤差或差異。經(jīng)驗(yàn)損失度量了整個(gè)數(shù)據(jù)集上的總損失。交叉熵?fù)p失常用于輸出概率在0和1之間的模型,而均方誤差損失用于輸出連續(xù)實(shí)數(shù)的回歸模型。目標(biāo)是在訓(xùn)練過程中最小化損失函數(shù),以提高網(wǎng)絡(luò)預(yù)測(cè)的準(zhǔn)確性。損失優(yōu)化(Loss optimization):這是在神經(jīng)網(wǎng)絡(luò)進(jìn)行預(yù)測(cè)時(shí),最小化神經(jīng)網(wǎng)絡(luò)所產(chǎn)生的誤差或損失的過程。這是通過調(diào)整網(wǎng)絡(luò)的權(quán)重來完成的。
梯度下降(Gradient descent):這是一種用于尋找函數(shù)最小值的優(yōu)化算法,例如神經(jīng)網(wǎng)絡(luò)的損失函數(shù)。它涉及迭代地調(diào)整權(quán)重,沿著損失函數(shù)的負(fù)梯度方向。其思想是不斷將權(quán)重朝著減小損失的方向移動(dòng),直到達(dá)到最小值。
讓我們通過實(shí)際例子記住這些術(shù)語:
1. 想象一家公司希望通過銷售產(chǎn)品來最大化利潤。他們可能有一個(gè)基于各種因素如價(jià)格、營銷支出等來預(yù)測(cè)利潤的模型。偏差可能指的是影響產(chǎn)品利潤但與價(jià)格或營銷支出無直接關(guān)系的任何固定因素。例如,如果產(chǎn)品是季節(jié)性物品,可能在一年中的某些時(shí)段存在對(duì)更高利潤的偏差。實(shí)際利潤與預(yù)測(cè)利潤之間的差異就是損失函數(shù)。梯度下降涉及計(jì)算損失函數(shù)相對(duì)于每個(gè)輸入特征的梯度,并使用這個(gè)梯度迭代地調(diào)整特征值,直到找到最佳值的過程,而涉及找到最小化損失函數(shù)的輸入特征的最佳值的過程就是損失優(yōu)化。利潤預(yù)測(cè)模型可能會(huì)使用非線性激活函數(shù)將輸入特征(例如價(jià)格、營銷支出)轉(zhuǎn)化為預(yù)測(cè)的利潤值。這個(gè)函數(shù)可以用來引入輸入特征和輸出利潤之間的非線性關(guān)系。2. 想象你正在玩一個(gè)視頻游戲,你是一個(gè)角色試圖到達(dá)一個(gè)目的地,但你只能在二維平面上移動(dòng)(前后和左右)。你知道目的地的確切坐標(biāo),但不知道如何到達(dá)那里。你的目標(biāo)是找到到達(dá)目的地的最短路徑。在這種情況下,損失函數(shù)可以是你當(dāng)前位置與目的地之間的距離。損失函數(shù)的梯度將是通往目的地最陡坡度的方向和大小,你可以使用它來調(diào)整你的移動(dòng),靠近目的地。隨著你靠近目的地,損失函數(shù)減小(因?yàn)槟汶x目標(biāo)更近了),梯度也相應(yīng)改變。通過反復(fù)使用梯度來調(diào)整你的移動(dòng),最終你可以以最短路徑到達(dá)目的地。希望你在了解神經(jīng)網(wǎng)絡(luò)方面有了更深入的了解。為了更好地理解這一概念,請(qǐng)參考文章中提到的視頻。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4717瀏覽量
100010 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8306瀏覽量
131845 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5422瀏覽量
120593
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論