 一種簡單而有效的多攝像頭算法,用于平衡性能和效率
一種簡單而有效的多攝像頭算法,用于平衡性能和效率
R3D3是一種用于密集三維重建和自我運動估計的多攝像頭算法,該方法通過迭代地結合多攝像頭的幾何估計和單目深度細化來實現一致的密集三維重建。R3D3的核心思想是將單目線索與來自多攝像頭的空間-時間信息的幾何深度估計相結合,通過在共視圖中迭代密集對應關系,計算準確的幾何深度和位姿估計。為了在多攝像頭設置中確定共視幀,作者提出了一種簡單而有效的多攝像頭算法,用于平衡性能和效率。深度細化網絡以幾何深度和對應的不確定性為輸入,并生成細化深度,以改善例如移動物體和低紋理區域的重建,細化的深度估計作為下一次幾何估計迭代的基礎,從而在增量幾何重建和單目深度估計之間閉合循環。R3D3在DDAD和NuScenes基準測試中實現了最優異的多攝像頭深度估計性能,與單目SLAM方法相比有更高的精度和魯棒性。
1. 引言
密集三維重建和自我運動估計是自動駕駛和機器人領域的關鍵挑戰。與當前復雜的多模態系統相比,多攝像頭系統提供了一種更簡單、低成本的替代方案,然而,基于攝像頭的復雜動態場景的三維重建一直面臨極大的困難,因為現有的解決方案通常會產生不完整或不連貫的結果。作者提出了R3D3,一種用于密集3D重建和自我運動估計的多攝像頭系統,通過迭代地結合多攝像頭的幾何估計和單目深度細化來實現一致的密集三維模型。
將感知輸入轉化為環境的密集三維模型,并跟蹤觀察者的位置是機器人學和自動駕駛的主要研究內容之一。現代系統依賴于融合多種傳感器模態,如攝像頭、激光雷達、雷達、慣性測量單元等,使硬件和軟件棧變得復雜且昂貴,相比之下,多攝像頭系統提供了一種更簡單、低成本的替代方案,已廣泛應用于現代消費者汽車。然而,基于圖像的密集3D重建和自我運動估計在大規模動態場景中仍是一個開放性的研究問題,因為移動物體、重復紋理以及光學退化等方面都帶來了顯著的算法挑戰。
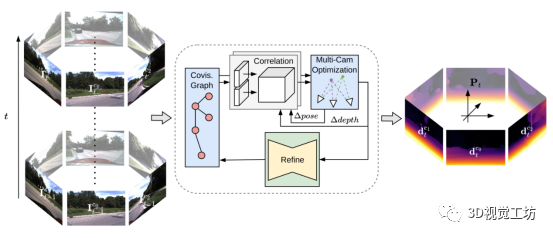
圖 1 R3D3網絡結構概略圖 這篇論文的主要貢獻包括以下三點:
提出了一種用于密集三維重建和自我運動估計的多攝像頭算法R3D3。
通過一種新穎的多攝像頭密集束調整(DBA)方法和多攝像頭共視圖,實現了準確的幾何深度和位姿估計。
通過深度細化網絡,整合了先驗幾何深度和不確定性以及單目線索,從而提高了密集三維重建的質量。
2. 相關工作
這篇論文的相關工作部分主要討論了多視點立體(MVS)方法、視覺SLAM方法和自監督深度估計方法。MVS方法旨在從具有已知位姿的一組圖像中恢復密集的3D場景結構;視覺SLAM方法關注從視覺輸入中聯合映射環境和跟蹤觀察者的軌跡,即一個或多個RGB攝像頭;自監督深度估計方法關注從單目線索預測密集深度,如透視物體表面和場景上下文。
Multi-view Stereo(MVS)方法旨在從具有已知位姿的一組圖像中恢復密集的3D場景結構。盡管早期的研究主要關注經典優化方法,但近年來,許多研究開始利用卷積神經網絡(CNN)來估計多個深度假設平面上的特征匹配,從而在3D代價體中進行匹配。早期方法采用多個圖像對之間的多個代價體,而最近的方法則使用整個圖像集的單一代價體,這些方法假設在一個受控環境中有許多高度重疊的圖像和已知的位姿來創建三維代價體。相反,本文的目標是從未知軌跡的移動平臺上的任意多攝像頭設置中實現穩健的密集3D重建。
傳統的SLAM系統通常分為不同階段,首先將圖像處理為關鍵點匹配,然后使用這些匹配來估計3D場景幾何和相機軌跡,另一類方法直接基于像素強度優化3D幾何和相機軌跡。最近的方法將基于CNN的深度和姿態預測集成到SLAM流程中,這些方法面臨的共同挑戰是由于低紋理區域、動態物體或光學退化引起的像素對應中的離群值,需要使用魯棒估計技術來過濾這些離群值。
自監督深度估計的開創性工作是由Zhou等人[1]提出的,他們通過最小化視圖合成損失來學習深度估計,該損失使用幾何約束將參考視圖中的顏色信息變形到目標視圖。后續的研究主要關注改進網絡架構、損失正則化和訓練策略,最近的方法從多視圖立體視覺中汲取靈感,提出使用3D代價體來整合時間信息。然而,這些方法仍然關注單攝像頭、前向場景,而這并不能反映自動駕駛汽車中真實世界的傳感器設置。另一類最近的研究關注利用多攝像頭設置中重疊攝像頭的空間信息,這些方法利用空間上下文來提高準確性,并實現絕對尺度深度學習。然而,這些方法忽略了時間域,而時間域對深度估計提供了有用的線索。
3.方法
R3D3 算法通過結合單目視覺線索和來自多攝像頭的空間-時間信息的幾何深度估計,實現了在動態室外環境中的密集、一致的三維重建。該方法首先利用多攝像頭系統的空間-時間信息進行幾何深度估計和相機位姿估計,為了提高幾何深度不可靠的區域(如移動物體或低紋理區域)的重建質量,作者引入了一個深度細化網絡,該網絡接受幾何深度和不確定性作為輸入,并產生細化后的深度。此外,細化后的深度估計作為下一次幾何估計迭代的基礎,從而在增量幾何重建和單目深度估計之間形成閉環。
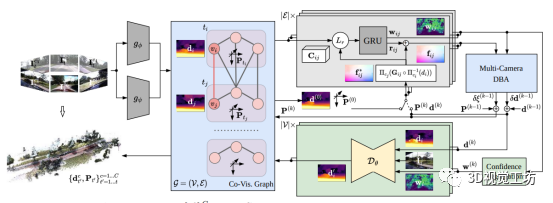
圖 2 R3D3網絡結構圖
3.1 特征提取和相關性
本小節詳細介紹了如何從每個圖像中提取相關特征和上下文特征,以及如何構建共視圖和計算特征相關性。主要內容包括:
特征提取:通過深度相關編碼器()和上下文編碼器()從每個圖像中分別提取相關特征和上下文特征。
共視圖:將相關特征和上下文特征存儲在一個圖中。作者構建了具有三種邊的共視圖:時間邊、空間邊和空間-時間邊。為了在多攝像頭設置中實現高效的共視圖構建,作者設計了一個簡單而有效的共視圖構建算法。
特征相關性:對于圖中的每條邊,計算特征相關性。通過點積計算4D特征相關體,并使用查找操作符限制相關搜索區域。
這一部分的核心是如何從圖像中提取特征并構建共視圖,以便在后續步驟中進行幾何深度估計和相機位姿估計。
3.2 深度和位姿估計
闡述了如何根據共視圖中的每條邊來估計相對位姿和深度。這部分主要包括流量校正、多相機密集束調整以及深度和位姿聚合。首先,給定和的初始估計,計算誘導流以采樣相關體;然后將采樣的相關特征、上下文特征和誘導流輸入到卷積GRU中。GRU預測流殘差和置信權重;接著,作者提出了一種多相機密集束調整(DBA)算法,用于在共視圖中的每條邊上迭代地優化深度和相對位姿估計;最后,在多次迭代后,作者使用加權平均法聚合每個節點的深度和位姿估計,以得到最終的深度圖和相機位姿。
3.3 深度細化
本小節提出了一種深度優化方法,通過結合幾何深度估計和單目視覺線索,可以在幾何估計不可靠的情況下改善重建效果。作者使用了一個由參數表示的卷積神經網絡,將深度、置信度和對應的圖像作為輸入。網絡預測改進后的密集深度。通過使用每個邊緣置信度權重的最大值,計算每個幀的深度置信度。對于低于閾值β的置信度區域,將輸入深度和置信度權重設為零。將這些與圖像進行連接,并將深度和置信度與1/8縮放的特征進行連接。與之前的方法類似,輸出深度在四個尺度上進行預測。為了適應傳感器設置中不同攝像頭之間的焦距差異,對輸出進行焦距縮放。
不同于幾何方法,單目深度估計器從語義線索中推斷深度,這使得它們在不同領域之間的泛化能力受到限制。因此,作者在原始的真實世界視頻上通過自監督的方式訓練,最小化視圖合成損失。通過計算目標圖像Itc和參考圖像It'c'在目標視點上的光度誤差,實現自監督深度估計。自監督深度估計是一個經過充分研究的領域,作者遵循了應用正則化技術過濾光度誤差的通用做法。
3.4 推理過程
在論文的 3.4 小節中,作者詳細描述了整個推理過程,包括如何從多個攝像頭獲取數據、估計深度和相對姿態、以及如何優化和融合這些信息以獲得稠密的三維重建結果。
首先,從C個攝像頭在時間t處獲取幀,并將其編碼并整合到具有初始深度圖dtc和自我姿態Pt的共視圖G=(V,E)中;然后,對于共視圖中的每條邊(i,j)∈E,從深度di和相對攝像頭姿態(由自我姿態P和攝像頭外參T導出)計算誘導流,從中聚合特征相關性,作為GRU的輸入,該GRU估計流更新和置信度,通過多攝像頭DBA操作在k次迭代中使用新的流估計f全局對齊深度d和姿態P;最后,對于共視圖中的每個節點i∈V,文中使用深度優化網絡優化深度圖。
整個推理過程包括以下幾個關鍵步驟:
將來自多個攝像頭的幀編碼并整合到共視圖中。
估計每條邊的深度和相對姿態。
使用 GRU 預測流更新和置信度。
通過多攝像頭 DBA 方法全局對齊深度和姿態。
使用深度優化網絡優化每個節點的深度圖。
4. 實驗
在實驗部分,作者展示了他們的方法在兩個廣泛使用的多攝像頭深度估計基準測試(DDAD和NuScenes)上的性能,并與現有的SOTA方法進行了比較。此外,他們還展示了與單目SLAM方法的精度和魯棒性比較。實驗結果表明,通過共同利用多攝像頭約束以及單目深度線索,他們的方法在動態戶外環境中實現了魯棒的密集3D重建和自我運動估計。此外,他們還對共視圖構建算法進行了評估,并將其與現有算法進行了比較,實驗結果證實了他們的方法在幾何深度估計、單目深度估計和完整方法之間有效地結合了各自的優勢,同時避免了各自的弱點。這里也推薦「3D視覺工坊」新課程《徹底搞透視覺三維重建:原理剖析、代碼講解、及優化改進》。

圖 3 動態場景中稠密三維重建的對比實驗

圖 4 在DDAD數據集上的效果
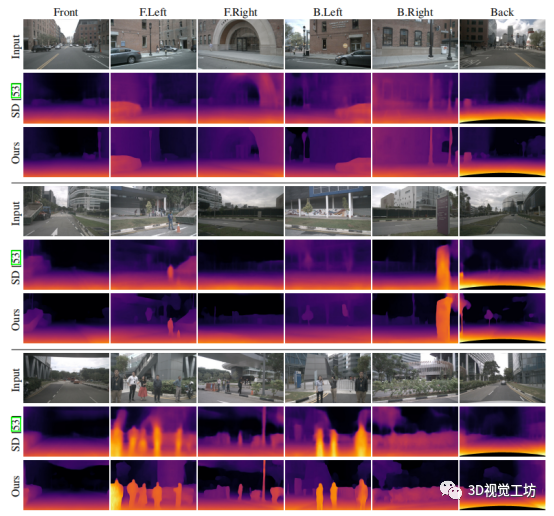
圖 5 在NuScenes數據集上的效果
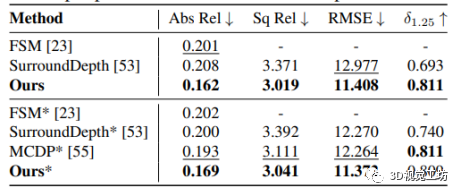
圖 6 在DDAD數據集上的定量評價
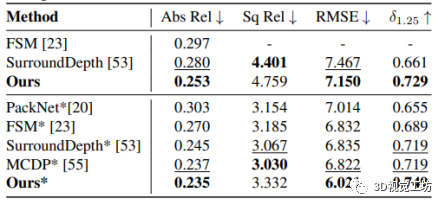
圖 7 在NuScenes數據集上的定量評價
5. 結論
R3D3算法通過共同利用多攝像頭約束以及單目深度線索,在動態戶外環境中實現了魯棒的密集3D重建和自我運動估計。作者提出了一種新穎的多攝像頭密集束調整方法,并設計了一個深度細化網絡,將幾何深度和不確定性與單目線索相結合。實驗結果表明,R3D3方法在兩個廣泛使用的多攝像頭深度估計基準測試(DDAD和NuScenes)上取得了最優異的性能,此外,與單目SLAM方法相比,R3D3算法具有更高的精度和魯棒性。總之,R3D3方法為動態場景的密集三維重建和自我運動估計提供了一種有效的解決方案。
-
算法
+關注
關注
23文章
4599瀏覽量
92643 -
攝像頭
+關注
關注
59文章
4810瀏覽量
95445 -
激光雷達
+關注
關注
967文章
3939瀏覽量
189598
原文標題:5. 結論
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
攝像頭常見故障
如何安裝倒車攝像頭?
【MYD-Y6ULX申請】基于攝像頭的人臉識別項目
回收手機攝像頭 收購手機攝像頭
一種攝像頭自動白平衡的算法及硬件實現
基于攝像頭的道路識別控制算法

基于DirectShow的多攝像頭視頻采集
手機攝像頭多攝是什么,它的優勢都有哪些
一種簡單而有效的多通道微流控電化學傳感器
一種實現高性能鋰金屬電池的簡單而有效的策略
智能攝像頭抄表器是什么?






 工商網監
工商網監
評論