 最新研究綜述——探索基礎模型中的“幻覺”現象
最新研究綜述——探索基礎模型中的“幻覺”現象
“幻覺”問題即模型生成的內容可能包含虛構的信息。它不僅在大語言模型(LLMs)中存在,也存在于圖像、視頻和音頻等其他一系列基礎模型中。
針對這一問題,一篇最近的綜述論文對目前所有基礎模型的“幻覺”問題進行了第一次全面的調查,詳細分類了各類基礎模型中的幻覺現象,審視了現有的減輕幻覺問題的策略,并提出了一套用于評估幻覺程度的標準。

Paper:A Survey of Hallucination in “Large” Foundation Models
Link:https://arxiv.org/pdf/2309.05922.pdf
注:本篇解讀僅對部分文獻進行總結,更多細節請進一步閱讀原論文綜述。
前言
基礎模型Foundation Models(FMs)是通過自監督學習方法,在大量未標簽數據上訓練得來的AI模型。這些模型不僅可以在圖像分類、自然語言處理和問答等多個領域中提供高精度的表現,還可以處理涉及創作和人際互動的任務,比如制作營銷內容或根據簡短提示創作復雜藝術品。
雖然基礎模型非常強大,但在將其適配到企業應用時也會遇到一系列的挑戰,其中一個重要的問題就是“幻覺”現象。“幻覺”現象是指模型生成包含虛假信息或完全捏造的細節。這主要是因為模型根據訓練數據中學到的模式來創造看似合理的內容,即便這樣的內容與真實情況相去甚遠。
這種“幻覺”現象可能是無意中產生的,它可以由多種因素導致,包括訓練數據集中存在的偏見、模型不能獲取最新的信息,或是其在理解和生成準確回應時的固有限制。為了確保我們可以安全、有效地利用基礎模型,特別是在新聞、醫療和法律等需要事實準確的領域,我們必須認真對待和解決“幻覺”問題。目前,研究人員正在努力探索各種方式來減少“幻覺”現象,從而提高模型的可靠性和信任度。
下圖展示了本篇綜述的一個基本框架,主要從文本、圖片、音頻和語音等領域來總結目前的研究。其中,文本又可以進一步細分為LLMs,多語言LLMs和特定領域的LLMs(如新聞、醫療等領域)。
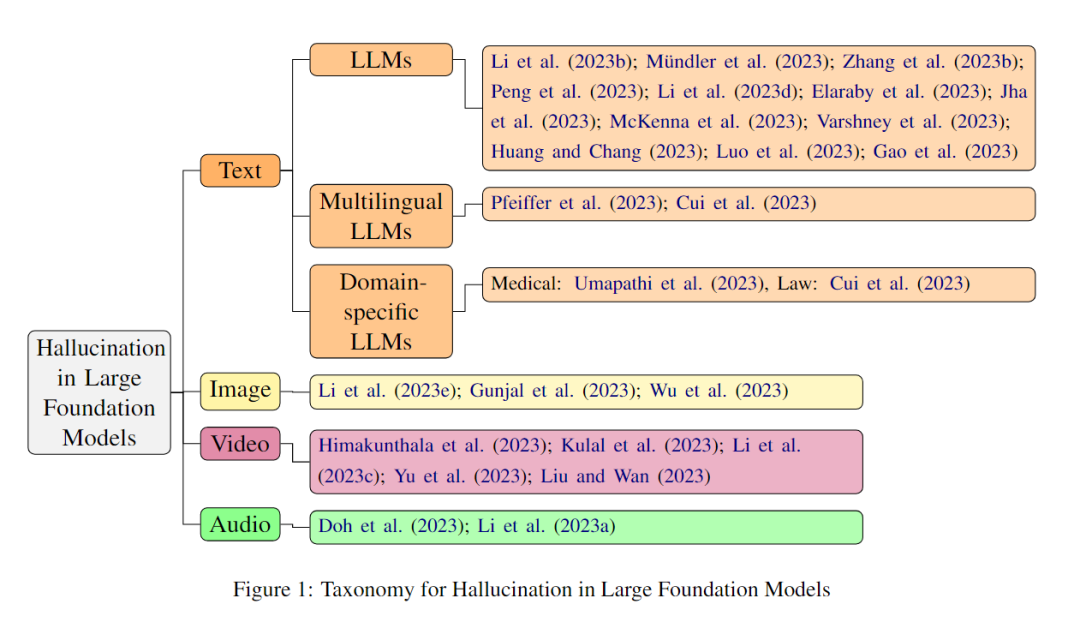
LLM的幻覺問題
幻覺檢測和修正方法
SELFCHECKGPT [1] 是一個用于監控和糾正LLMs中的“幻覺”現象的工具,它能夠識別模型生成的不準確或未驗證的信息,無需額外資源或標記數據。這種方法能夠在沒有外部指南或數據集的情況下提高LLMs的可靠性和可信度。
PURR [2] 則專注于編輯和糾正語言模型中的誤導信息,它通過利用去噪語言模型的損壞來識別和修正幻覺,目的是提升模型輸出的質量和準確性。
幻覺檢測數據集
幻覺問題通常和知識缺口有關。但研究 [3] 提出,有時模型會嘗試合理化之前生成的錯誤信息,從而產生更多的誤導內容。為了深入研究這一現象,這項研究創建了三個問答數據集來收集模型產生錯誤答案和附帶虛假斷言的實例。
HaluEval [4] 提供了一個綜合基準來評估LLMs中的幻覺問題,幫助研究人員和開發人員更好地理解和提高模型的可靠性。
利用外部知識來緩解幻覺問題
為了減輕LLM的幻覺問題,研究人員正在探索如何利用外部知識來提高模型的輸出質量和準確性。其中,[5] 提出了一種交互式問題-知識對齊方法,側重于將生成的文本與相關的事實知識對齊,使用戶能夠交互式地指導模型的回答,以產生更準確和可靠的信息。類似地,[6] 提出了LLMAUGMENTER方法,結合外部知識來源和自動化反饋機制來提高LLM輸出的準確性和可靠性。而 [7] 提出了“知識鏈”框架來鏈接LLMs和結構化知識庫。
此外,相比于其更大的對應體,小型開源LLMs通常會遇到更嚴重的幻覺問題。為了解決這個問題,[8] 提出了一系列方法來評估和減輕BLOOM 7B這類弱小型開源LLMs的幻覺問題。
采用prompting來緩解幻覺問題
也有研究致力于通過prompting來減少LLMs生成的不準確或幻覺信息。[9] 在2023年提出了一種由迭代提示指導的方法來去除LLMs的幻覺,提高輸出的準確性和可靠性。
多語言LLM的幻覺問題
大型多語言機器翻譯系統在直接翻譯多種語言方面展示了令人印象深刻的能力。但是,這些模型可能會產生“幻覺翻譯”,在部署時會引發信任和安全問題。目前關于幻覺的研究主要集中在小型雙語模型和高資源語言上,這留下了一個空白:在多種翻譯場景中大規模多語言模型的幻覺理解。
為了解決這個問題,[10] 對傳統的神經機器翻譯模型的M2M家族和ChatGPT進行了全面的分析,后者可以用于提示翻譯。這項調查涵蓋了廣泛的語言背景,包括100多個翻譯方向。
特定領域LLM的幻覺問題
在諸如醫學、銀行、金融、法律等關鍵領域中,可靠性和準確性是至關重要的,任何形式的幻覺都可能對結果和操作產生重大和有害的影響。
醫學:LLMs中的幻覺問題,特別是在醫學領域,生成看似合理但不準確的信息可能是有害的。為了解決這個問題,[11] 引入了一個名為Med-HALT(醫學領域幻覺測試)的新基準和數據集。它專門設計用于評估和減輕LLMs中的幻覺。它包括來自不同國家的醫學檢查的多元化的多國數據集,并包括創新的測試方法。Med-HALT包括兩類測試:基于推理和基于記憶的幻覺測試,旨在評估LLMs在醫學背景下的問題解決和信息檢索能力。
法律:ChatLaw [12]是一個專門用于法律領域的開源LLM。為了確保高質量的數據,作者們創建了一個精心設計的法律領域微調數據集。為了解決法律數據篩選過程中模型幻覺的問題,他們提出了一種將矢量數據庫檢索與關鍵字檢索相結合的方法。這種方法有效地減少了在法律背景下僅依賴矢量數據庫檢索來檢索參考數據時可能出現的不準確性。
大圖像模型中的幻覺問題
對比學習模型利用Siamese結構在自監督學習中展示了令人印象深刻的表現。它們的成功依賴于兩個關鍵條件:存在足夠數量的正樣本對,并在它們之間存在充足的變化。如果不滿足這些條件,這些框架可能缺乏有意義的語義區別并容易過擬合。為了解決這些挑戰,[13] 引入了Hallucinator,它可以高效地生成額外的正樣本來增強對比。Hallucinator是可微分的,在特征空間中運作,使其適合直接在預訓練任務中進行優化,同時帶來最小的計算開銷。
受LLMs的啟發,為復雜的多模態任務加強LVLMs面臨一個重大的挑戰:對象幻覺,其中LVLMs在描述中生成不一致的對象。[14] 系統地研究了指令調整的大視覺語言模型(LVLMs)中的對象幻覺問題,并發現這是一個常見問題。視覺指令,特別是經常出現或共同出現的對象,影響了這個問題。現有的評估方法也受到輸入指令和LVLM生成樣式的影響。為了解決這個問題,該研究引入了一種改進的評估方法,稱為POPE,為LVLMs中的對象幻覺提供了更穩定和靈活的評估。
LVLMs在處理各種多模態任務方面取得了重大進展,包括視覺問題回答(VQA)。然而,為這些模型生成詳細和視覺上準確的回答仍然是一個挑戰。即使是最先進的LVLMs,如InstructBLIP,也存在高幻覺文本率,包括30%的不存在的對象、不準確的描述和錯誤的關系。為了解決這個問題,[15] 引入了MHalDetect1,這是一個多模態幻覺檢測數據集,專為訓練和評估旨在檢測和預防幻覺的模型而設計。MHalDetect包含16000個關于VQA示例的精細詳細注釋,使其成為檢測詳細圖像描述中幻覺的首個全面數據集。
大視頻模型中的幻覺問題
幻覺可能發生在模型對視頻幀做出錯誤或富有想象的假設時,導致產生人工或錯誤的視覺信息,如下圖所示。

一個解決方法是通過一種能夠生動地將人插入場景的方法來理解場景可供性的挑戰。[16] 使用標有區域的場景圖像和一個人的圖像,該模型無縫地將人集成到場景中,同時考慮場景的特點。該模型能夠根據場景環境推斷出現實的姿勢,相應地調整人的姿勢,并確保視覺上令人愉悅的構圖。自我監督訓練使模型能夠在尊重場景環境的同時生成各種可能的姿勢。此外,該模型還可以自行生成逼真的人和場景,允許進行交互式編輯。
VideoChat [17] 是一個全面的系統,采用面向聊天的方法來理解視頻。VideoChat將基礎視頻模型與LLMs結合,使用一個可適應的神經界面,展示出在理解空間、時間、事件定位和推斷因果關系方面的卓越能力。為了有效地微調這個系統,他們引入了一個專門為基于視頻的指導設計的數據集,包括成千上萬的與詳細描述和對話配對的視頻。這個數據集強調了時空推理和因果關系等技能,使其成為訓練面向聊天的視頻理解系統的有價值的資源。
最近在視頻修復方面取得了顯著的進步,特別是在光流這樣的顯式指導可以幫助將缺失的像素傳播到各個幀的情況下。然而,當跨幀信息缺失時,就會出現挑戰。因此,模型集中解決逆向問題,而不是從其他幀借用像素。[18] 引入了一個雙模態兼容的修復框架,稱為Deficiency-aware Masked Transformer(DMT)。預訓練一個圖像修復模型來作為訓練視頻模型的先驗有一個優點,可以改善處理信息不足的情況。
視頻字幕的目標是使用自然語言來描述視頻事件,但它經常引入事實錯誤,降低了文本質量。盡管在文本到文本的任務中已經廣泛研究了事實一致性,但在基于視覺的文本生成中卻受到了較少的關注。[19] 對視頻字幕中的事實進行了詳細的人類評估,揭示了57.0%的模型生成的句子包含事實錯誤。現有的評估指標主要基于n-gram匹配,與人類評估不太一致。為了解決這個問題,他們引入了一個基于模型的事實度量稱為FactVC,它在評估視頻字幕中的事實度方面優于之前的指標。
大型音頻模型中的幻覺
自動音樂字幕,即為音樂曲目生成文本描述,有可能增強對龐大音樂數據的組織。現有音樂語言數據集的大小有限,收集過程昂貴。為了解決這種稀缺,[20] 使用了LLMs從廣泛的標簽數據集生成描述。他們創建了一個名為LP-MusicCaps的數據集,包含約220萬個與50萬個音頻剪輯配對的字幕。他們還使用各種量化自然語言處理指標和人類評估對這個大規模音樂字幕數據集進行了全面評估。他們在這個數據集上訓練了一個基于變換器的音樂字幕模型,并在零射擊和遷移學習場景中評估了其性能。
理想情況下,視頻應該增強音頻,[21]使用了一個先進的語言模型進行數據擴充,而不需要人工標注。此外,他們利用音頻編碼模型有效地適應了一個預訓練的文本到圖像生成模型,用于文本到音頻生成。
幻覺并非總是有害
從一個不同的角度來看,[22]討論了幻覺模型如何可以提供創意,提供可能不完全基于事實但仍然提供有價值線索來探索的輸出。創意地利用幻覺可以帶來不容易被大多數人想到的結果或新奇的創意組合。“幻覺”變得有害是當生成的陳述事實上不準確或違反普遍的人類、社會或特定文化規范時。這在一個人依賴LLM來提供專家知識的情況下尤其關鍵。然而,在需要創意或藝術的背景下,產生不可預見結果的能力可能相當有利。對查詢的意外響應可以驚喜人類并激發發現新奇想法聯系的可能性。
結論與未來方向
這篇綜述對現有關于基礎模型內部的幻覺問題進行了簡單的分類和分析,研究涵蓋了幻覺檢測,緩解,數據集,以及評估標準。以下是一些可能的未來研究方向。
對幻覺的自動評估
幻覺指的是AI模型生成的不正確或捏造的信息。在像文本生成這樣的應用中,這可能是一個重大的問題,因為目標是提供準確和可靠的信息。以下是對錯覺自動評估的潛在未來方向:
評估指標的開發:研究者可以努力創建能夠檢測生成內容中的幻覺的專門的評估指標。這些指標可能會考慮事實的準確性、連貫性和一致性。可以訓練高級機器學習模型根據這些指標評估生成的文本。
人工智能合作:將人類判斷與自動評估系統結合是一個有前景的方向。眾包平臺可以用來收集人類對AI生成內容的評估,然后用于訓練自動評估的模型。這種混合方法可以幫助捕捉對自動系統來說具有挑戰性的細微差別。
對抗性測試:研究者可以開發對抗性測試方法,其中AI系統被暴露于專門設計的輸入,以觸發幻覺。這有助于識別AI模型的弱點并提高其抵抗錯覺的魯棒性。
微調策略:特別為減少幻覺而微調預訓練的語言模型是另一個潛在的方向。模型可以在強調事實檢查和準確性的數據集上進行微調,以鼓勵生成更可靠的內容。
改進檢測和緩解幻覺的策略
檢測和緩解AI生成文本中的偏見、錯誤信息和低質量內容對于負責任的AI開發至關重要。策劃的知識來源在實現這一目標中可以起到重要作用。以下是一些未來的方向:
知識圖譜集成:將知識圖譜和策劃的知識庫集成到AI模型中可以增強它們對事實信息和概念之間關系的理解。這既可以幫助生成內容,也可以幫助事實檢查。
事實檢查和驗證模型:開發專門的模型,專注于事實檢查和內容驗證。這些模型可以使用策劃的知識來源來交叉引用生成的內容,識別不準確或不一致之處。
偏見檢測和緩解:策劃的知識來源可以用來訓練AI模型識別和減少生成內容中的偏見。AI系統可以被編程來檢查內容是否存在潛在的偏見,并提議更加平衡的替代方案。
主動學習:通過主動學習不斷更新和完善策劃的知識來源。AI系統可以被設計為尋求人類對模糊或新信息的輸入和驗證,從而提高策劃知識的質量。
道德指導和監管:未來的方向還可能包括為AI開發中使用外部知識來源制定道德指南和監管框架。這可以確保負責任和透明地使用策劃知識來緩解潛在風險。
-
AI
+關注
關注
87文章
30239瀏覽量
268474 -
模型
+關注
關注
1文章
3178瀏覽量
48730 -
語言模型
+關注
關注
0文章
508瀏覽量
10247 -
知識圖譜
+關注
關注
2文章
132瀏覽量
7696
原文標題:最新研究綜述——探索基礎模型中的“幻覺”現象
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大型語言模型在關鍵任務和實際應用中的挑戰
TaD+RAG-緩解大模型“幻覺”的組合新療法
【大語言模型:原理與工程實踐】核心技術綜述
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》2.0
數字流域研究綜述
OpenAI稱找到新方法減輕大模型“幻覺”
大模型現存的10個問題和挑戰
大模型現存的10個問題和挑戰

幻覺降低30%!首個多模態大模型幻覺修正工作Woodpecker

LLM的幻覺問題最新綜述






 工商網監
工商網監
評論