 Linux性能優化:Cache對性能的影響
Linux性能優化:Cache對性能的影響
Cache對性能的影響首先我們要知道,CPU訪問內存時,不是直接去訪問內存的,而是先訪問緩存(cache)。
當緩存中已經有了我們要的數據時,CPU就會直接從緩存中讀數據,而不是從內存中讀。
CPU和緩存的關系如下:
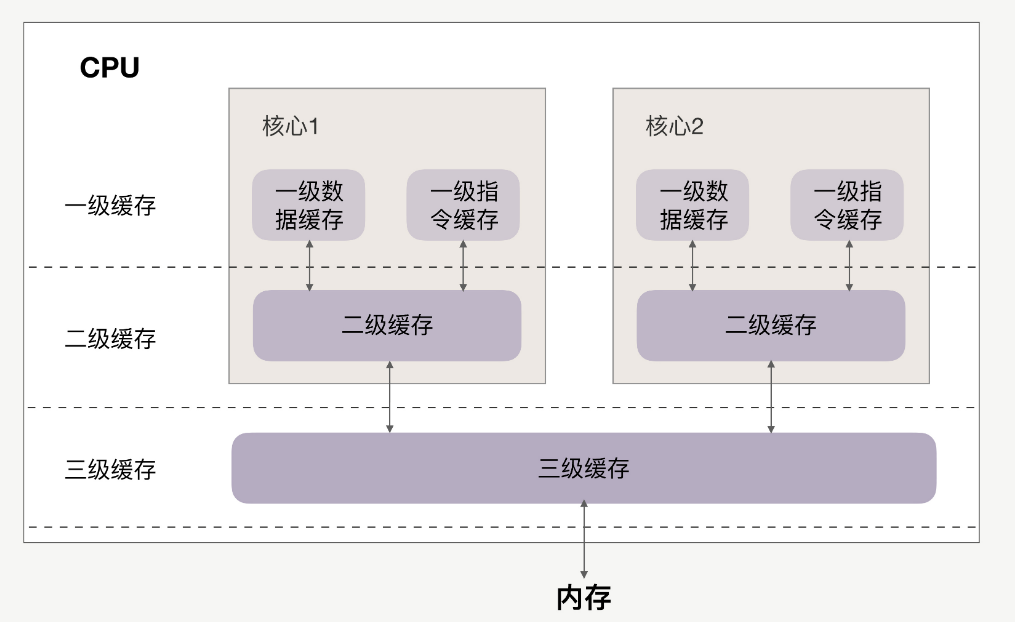
緩存分為一級、二級、三級,最靠近CPU的是一級緩存,最遠的是內存,離CPU越近速度越快。
訪問速度上,L1》L2》L3》內存,緩存比內存速度要快得非常多。
如果CPU操作的數據在緩存中,則直接從緩存中讀取,這個過程就叫緩存命中。
因此提升性能的關鍵,就是要提高緩存命中率。下面來看如何提高緩存命中率。
提高數據緩存命中率來看一個實例,有一個N*N的二維數組,例如:
int array[N][N];
現在用兩個for循環遍歷這個數組,訪問每個元素的內容:
for(i = 0; i 《 N; i+=1) { for(j = 0; j 《 N; j+=1) { array[i][j] = 0;//速度快
//array[j][i] = 0;//速度慢 } }
有兩種訪問方式:array[i][j]和array[j][i]。
在性能上,array[i][j]會比array[j][i]執行地更快,并且速度相差8倍。
1、速度更快的原因
首先數組在內存上是連續的,假設N等于2,則array[2][2]在內存中的排布是:
array[0][0]、array[0][1]、array[1][0]、array[1][1]、
以array[i][j]方式訪問,即按內存中的順序訪問,當訪問array[0][0]時,CPU就已經把數組的剩余三個數據(array[0][1]、array[1][0]、array[1][1])加載到了緩存當中。
當繼續訪問后三個元素時,CPU會直接從緩存中讀取數據,而不需要從內存中讀取(cache命中)。因此速度會很快。
如果以array[j][i]方式訪問數組,則訪問順序為:
array[0][0]、array[1][0]、array[0][1]、array[1][1]
此時訪問順序是跳躍的,并不是按數組在內存中的的排布順序來訪問。如果N很大的話,那么執行array[j][i]時,array[j+1][i]的內容是沒法讀進緩存里的,等到要訪問array[j+1][i]時就只能從內存中讀取。
所以array[j][i]的速度會慢于array[i][j]。
2、速度相差8倍的原因
剛剛提到,如果這個二維數組的N很大,array[j+1][i]的內容是沒法讀到緩存里的,那CPU一次能夠將多少數據加載進緩存里呢?
這個其實跟cache line有關,cache line代表緩存一次載入數據的大小。可以通過以下命令查看cache line為多大:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size

cache line為64,代表CPU緩存一次數據的大小為64字節。
當訪問array[0][0]時,該元素所占用的字節數不到64字節,CPU就會按順序補足后續元素,就會把后面的array[0][1]、array[1][0]等內容一起讀到緩存里,直到湊夠64字節。
正因如此,按順序訪問的array[i][j]才會比不按順序訪問的array[j][i]速度快。
再看看為什么速度相差8倍。我們知道,二維數組中,第一維元素放的是地址,第二維元素才是數據。64位系統中,地址占用8個字節,cache
line為64的話,地址已經占用了8字節,那每個cache line最多能載入不到8個二維數組元素,N很大的情況下,他們的性能平均下來就會相差將近8倍。
結論:按內存布局順序訪問,可以提高數據緩存命中率。
-
cpu
+關注
關注
68文章
10826瀏覽量
211160 -
Linux
+關注
關注
87文章
11230瀏覽量
208932 -
Cache
+關注
關注
0文章
129瀏覽量
28300
發布評論請先 登錄
相關推薦
NAS存儲系統性能優化攻略
HBase性能優化方法總結
Linux系統的性能優化策略
Linux和Android系統故障和優化性能的方法和流程探討
linux的性能問題
基于Linux的Socket網絡編程的性能優化

你知道linux的cache memory?
Linux CPU的性能應該如何優化
Linux內核文件Cache機制

cache的排布與CPU的典型分布
Cache與性能優化精彩問答38條
影響Linux性能的因素與優化方法
Linux內核slab性能優化的核心思想





 工商網監
工商網監
評論