 ICML 2023 | 對多重圖進行解耦的表示學習方法
ICML 2023 | 對多重圖進行解耦的表示學習方法

Introduction
無監督多重圖表示學習(UMGRL)受到越來越多的關注,但很少有工作同時關注共同信息和私有信息的提取。在本文中,我們認為,為了進行有效和魯棒的 UMGRL,提取完整和干凈的共同信息以及更多互補性和更少噪聲的私有信息至關重要。
為了實現這一目標,我們首先研究了用于多重圖的解纏表示學習,以捕獲完整和干凈的共同信息,并設計了對私有信息進行對比約束,以保留互補性并消除噪聲。此外,我們在理論上分析了我們方法學到的共同和私有表示可以被證明是解纏的,并包含更多與任務相關和更少與任務無關的信息,有利于下游任務。大量實驗證實了所提方法在不同下游任務方面的優越性。

論文標題:
Disentangled Multiplex Graph Representation Learning
論文鏈接:https://openreview.net/pdf?id=lYZOjMvxws
代碼鏈接:https://github.com/YujieMo/DMG

Motivation
以前的 UMGRL 方法旨在隱式提取不同圖之間的共同信息,這對于揭示樣本的身份是有效和魯棒的。然而,它們通常忽視了每個圖的私有信息中的互補性,并可能失去節點之間的重要屬性。
例如,在多重圖中,其中論文是節點,邊代表兩個不同圖中的共同主題或共同作者。如果一個私有邊(例如,共同主題關系)僅存在于某個圖中,并連接來自相同類別的兩篇論文,它有助于通過提供互補信息來降低類內差距,從而識別論文。因此,有必要同時考慮共同信息和私有信息,以實現 UMGRL 的有效性和魯棒性。
基于有助于識別樣本的共同信息,捕獲不同圖之間的所有共同信息(即完整的)是直觀的。此外,這種完整的共同信息應該僅包含共同信息(即干凈的)。相反,如果共同信息包含其他混淆的內容,共同信息的質量可能會受到損害。
因此,第一個問題出現了:如何獲得完整和干凈的共同信息?另一方面,私有信息是互補性和噪聲的混合。考慮引文網絡的同一個示例,如果私有邊連接來自不同類別的兩篇論文,它可能會干擾消息傳遞,應該作為噪聲被刪除。因此,第二個問題出現了:如何保留私有信息中的互補性并去除噪聲?
然而,以前的 UMGRL 方法很少探討了上述問題。最近,已經開發了解耦表示學習方法,以獲得共同和私有表示,但由于多重圖中節點之間的復雜關系以及圖結構中的互補性和噪聲,將它們應用于解決 UMGRL 中的上述問題是具有挑戰性的。為此,我們提出了一種新的解耦多重圖表示學習框架,以回答上述兩個問題。

Method
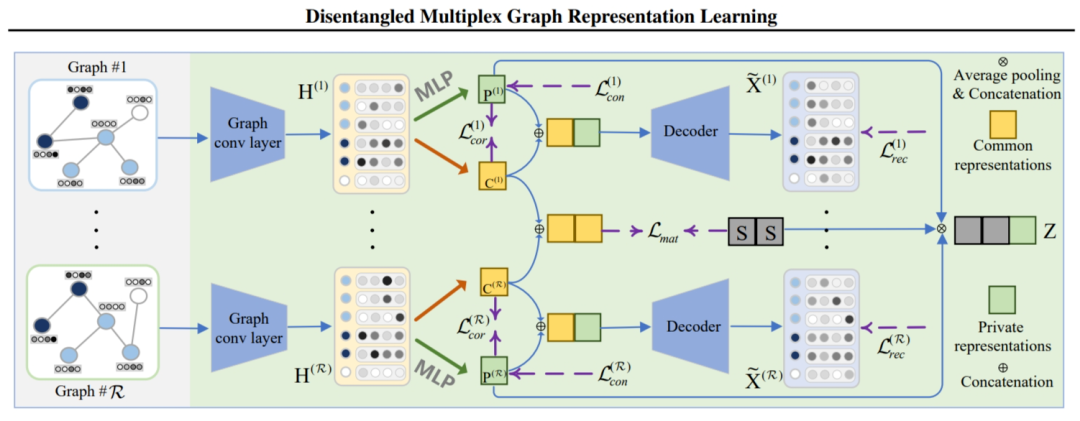
Notations
表示多重圖,表示多重圖中的第 張圖,表示圖的數量。
本文模型 DMG 首先通過一個共同變量 學習到經過解耦的共同表示以及私有表示,接著獲取到融合表示。
3.1 Common Information Extraction
以前的 UMGRL 方法(例如,圖之間的對比學習方法)通常通過最大化兩個圖之間的互信息來隱式捕獲不同圖之間的共同模式。例如,為了提取共同信息,STENCIL(Zhu等人,2022)最大化每個圖與聚合圖之間的互信息,而 CKD(Zhou等人,2022)最大化不同圖中區域表示和全局表示之間的互信息。
然而,由于它們未能將共同信息與私有信息解耦,因此這些努力不能明確地捕獲完整且干凈的共同信息。為了解決這個問題,本文研究了解耦表示學習,以獲得完整且 clean 的共同信息。
具體地,首先使用圖卷積層 生成節點表示 :
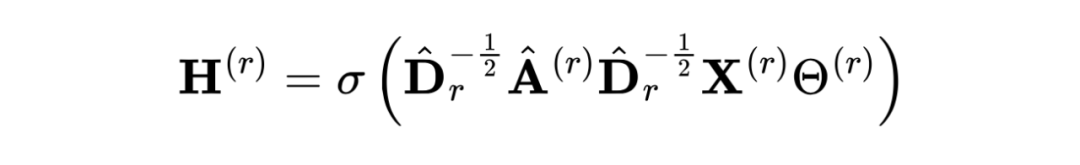
表示一個帶權重的自環; 表示度矩陣; 表示卷積層 的權重矩陣。
接著使用 MLP 來促進每張圖共同和私有信息的解耦過程,分別將節點嵌入 映射為共同表示和私有表示 。 給定每張圖的共同表示 ,對齊這些表示最簡單的方法使讓它們彼此相等。然而這樣做會影響共同表示的質量。在本文中,我們通過奇異值分解操作引入了一個具有正交性和零均值的公共變量 到共同表示中。然后,我們對公共表示 與公共變量 之間進行匹配損失,旨在逐漸對齊來自不同圖的共同表示,以捕獲它們之間的完整共同信息。匹配損失的公式如下: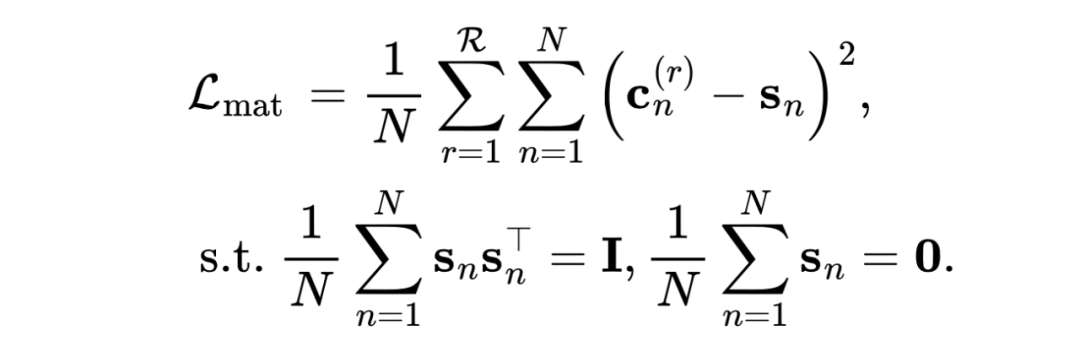 的作用是作為所有圖共同表示之間的一個橋梁,使得這些表示具有較好的一致性:。
的作用是作為所有圖共同表示之間的一個橋梁,使得這些表示具有較好的一致性:。
然后,為了解耦公共和私有表示,我們必須強化它們之間的統計獨立性。值得注意的是,如果公共和私有表示在統計上是獨立的,那么必須滿足:
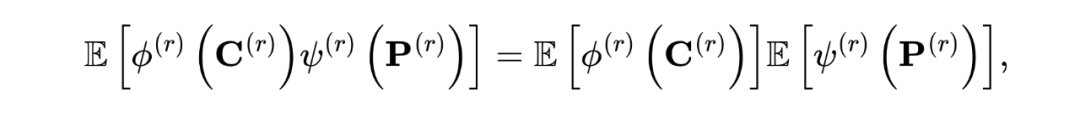
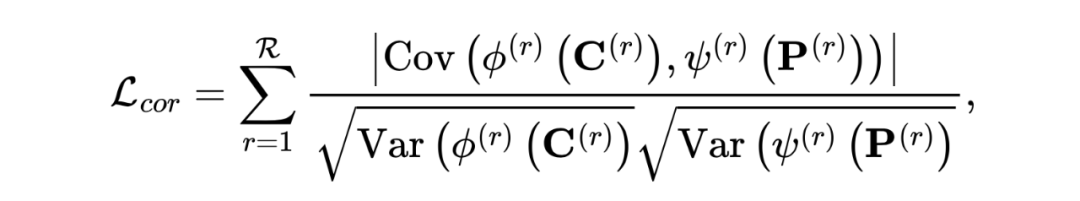 我們期望通過匹配損失(即獲得完整的共同信息)和相關性損失(即獲得干凈的共同信息)來獲得清晰的共同表示 中的共同信息。然而,在無監督框架下,學得的共同和私有表示可能是微不足道的解決方案。
常見的解決方案包括對比學習方法和自編碼器方法。對比學習方法引入大量負樣本以避免微不足道的解決方案,但可能會引入大量的內存開銷。自編碼器方法采用自編碼器框架,通過重構損失來促進編碼器的可逆性,以防止微不足道的解決方案。然而,現有的圖自編碼器旨在重構直接的邊緣,忽略了拓撲結構,并且計算成本高昂。
為了解決上述問題,我們研究了一種新的重構損失,以同時重構節點特征和拓撲結構。具體而言,我們首先將共同和私有表示連接在一起,然后使用重構網絡 獲得重構的節點表示 。我們進一步進行特征重構和拓撲重構損失,以分別重構節點特征和局部拓撲結構。因此,重構損失可以表述為:
我們期望通過匹配損失(即獲得完整的共同信息)和相關性損失(即獲得干凈的共同信息)來獲得清晰的共同表示 中的共同信息。然而,在無監督框架下,學得的共同和私有表示可能是微不足道的解決方案。
常見的解決方案包括對比學習方法和自編碼器方法。對比學習方法引入大量負樣本以避免微不足道的解決方案,但可能會引入大量的內存開銷。自編碼器方法采用自編碼器框架,通過重構損失來促進編碼器的可逆性,以防止微不足道的解決方案。然而,現有的圖自編碼器旨在重構直接的邊緣,忽略了拓撲結構,并且計算成本高昂。
為了解決上述問題,我們研究了一種新的重構損失,以同時重構節點特征和拓撲結構。具體而言,我們首先將共同和私有表示連接在一起,然后使用重構網絡 獲得重構的節點表示 。我們進一步進行特征重構和拓撲重構損失,以分別重構節點特征和局部拓撲結構。因此,重構損失可以表述為: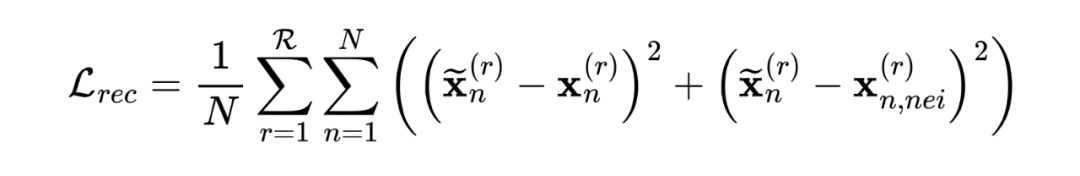
, 表示采樣的鄰居數。
在上式中第一項鼓勵 重構原始節點特征,第二項鼓勵 重構拓撲結構。
3.2 Private Information Constraint
私有信息是補充信息和噪音的混合物。因此,鑒于學習到的私有表示,我們希望進一步回答 3.1 節中的第二個問題,即保留補充信息并消除私有信息中的噪聲。此外,多重圖的私有信息主要位于每個圖的圖結構中,因為不同圖的節點特征是從共享特征矩陣 X 生成的。因此,我們研究了在每個圖結構中保留互補邊并去除噪聲邊。
首先提供了以下有關圖結構中補充信息和噪聲的定義:
- 對圖 上的任意私有邊,即 ,若節點對 所屬的類別相同,那么 將是圖 的一條補充邊,否則是一條噪聲邊。
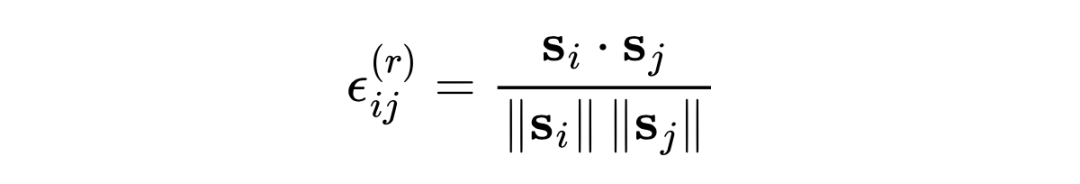 ?給定邊集 中所有節點對的余弦相似度,進一步假設具有最高相似度的節點對屬于同一類,具有低相似度的節點對屬于不同類。因此,對于連接節點的高相似性邊是補充邊,表示為 ,而對于連接節點的低相似性邊是噪聲邊,表示為 。直觀地,應保留補充邊,而應刪除噪聲邊。
?給定邊集 中所有節點對的余弦相似度,進一步假設具有最高相似度的節點對屬于同一類,具有低相似度的節點對屬于不同類。因此,對于連接節點的高相似性邊是補充邊,表示為 ,而對于連接節點的低相似性邊是噪聲邊,表示為 。直觀地,應保留補充邊,而應刪除噪聲邊。
設計了一個對比模塊,用于進行對比損失:
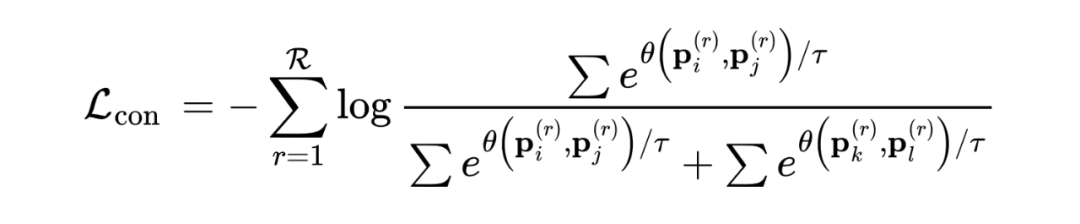
3.3 Objective Function
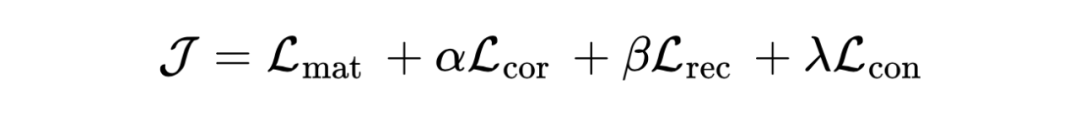
經過優化,預計所提出的 DMG 將獲得完整且干凈的公共表示,以及更多互補性和更少噪聲的私有表示,以實現有效且穩健的 UMGRL)。然進行平均池化(LeCun等人,1989)來融合所有圖的私有表示,以獲得總體的私有表示 P,即
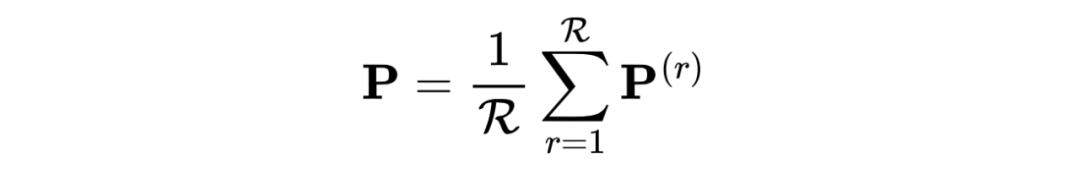
最后,我們將總體的私有表示 P 與共同變量 S 連接起來,獲得最終的表示 Z。

Experiments
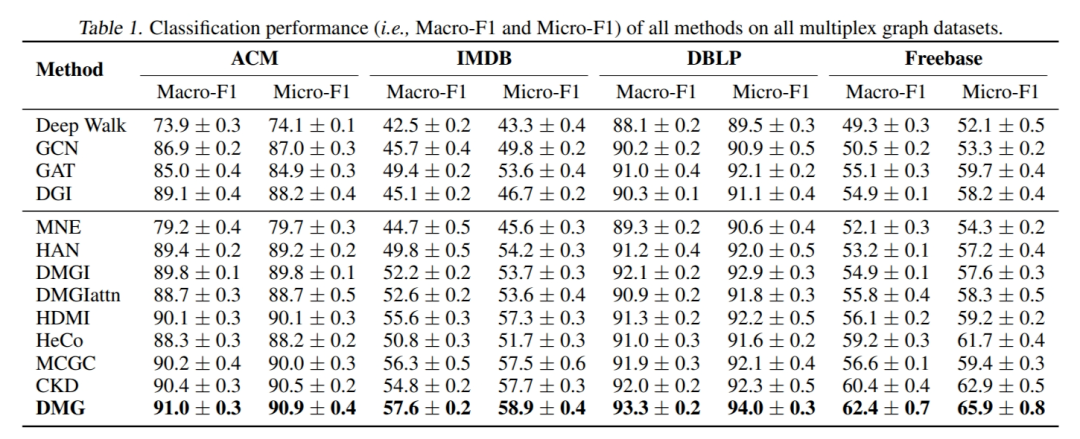
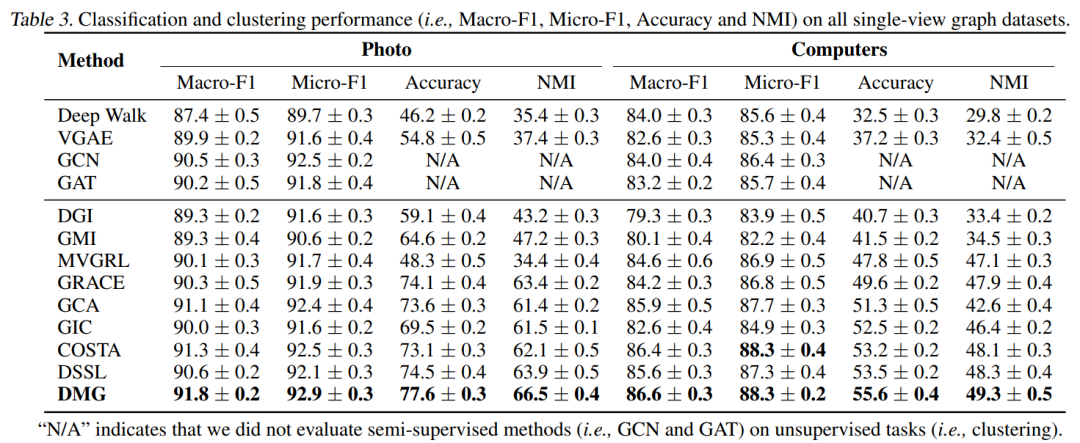
4.1 Node Classification
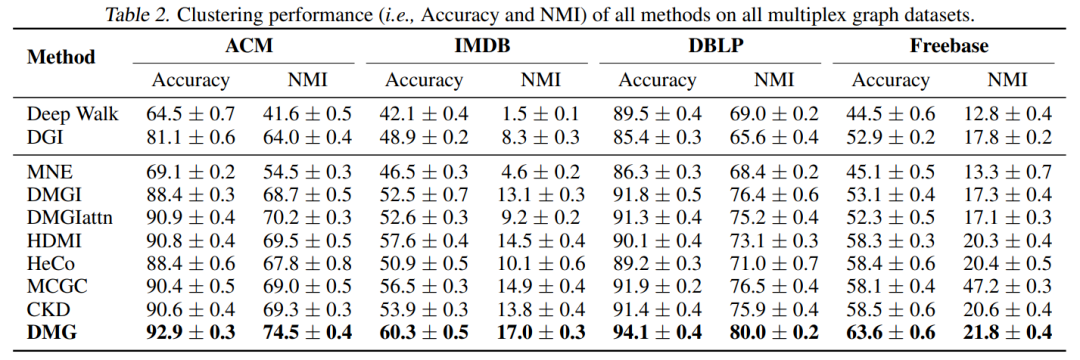
4.2 Node Clustering
4.3 Single-view graph datasets

Conclusion
本文提出了一個用于多重圖的解耦表示學習框架。為實現這一目標,我們首先解耦了共同表示和私有表示,以捕獲完整和干凈的共同信息。我們進一步設計了對私有信息進行對比約束,以保留互補性并消除噪聲。理論分析表明,我們方法學到的共同和私有表示可以被證明是解耦的,包含更多與任務相關的信息和更少與任務無關的信息,有利于下游任務。廣泛的實驗結果表明,所提出的方法在不同的下游任務中在有效性和魯棒性方面始終優于現有方法。
·
-
物聯網
+關注
關注
2903文章
44275瀏覽量
371265
原文標題:ICML 2023 | 對多重圖進行解耦的表示學習方法
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是機器學習?通過機器學習方法能解決哪些問題?

如何使用 PyTorch 進行強化學習
《DNK210使用指南 -CanMV版 V1.0》第一章本書學習方法
不平衡電網下基于功率解耦的PWM整流器控制策略研究
深度學習中的無監督學習方法綜述
智能數采網關助力破解軟硬件解耦難題

光耦檢測儀的制作方法有哪些
KUKA機器人8.7系統對PROFINET軟件進行編程控制的步驟
正向光耦和反向光耦區別
請問初學者要怎么快速掌握FPGA的學習方法?
光耦損壞對輸出的影響 光耦損壞有哪些現象 怎樣測試光耦元件的好壞
無監督域自適應場景:基于檢索增強的情境學習實現知識遷移






 工商網監
工商網監
評論