 英偉達為什么要投資網絡芯片初創公司Enfabrica?
英偉達為什么要投資網絡芯片初創公司Enfabrica?
近日,英偉達投資了一家號稱專注于人工智能數據中心網絡芯片的初創公司Enfabrica,消息一出瞬間刷屏朋友圈。 據悉,此次Enfabrica的B 輪融資由 Atreides Management 牽頭,Sutter Hill Ventures、英偉達、IAG Capital Partners、Liberty Global Ventures、Valor Equity Partners、Infinitum Partners 和 Alumni Ventures 參與,B輪融資共獲得1.25億美元資金,讓 Enfabrica 的融資總額達到 1.48 億美元。 就這樣一個成立于 2020 年的初創公司,怎么就入了英偉達的法眼呢? 01
英偉達為什么要投資Enfabrica?
別看Enfabrica 成立時間不長,但它背后的初始成員可謂臥虎藏龍,都是來自博通、谷歌、思科、AWS、英特爾等公司的大佬。
Enfabrica豪華創始團隊
聯合創始人兼CEO Rochan Sankar曾是博通的產品營銷和管理總監,推動了五代“Trident”和“Tomahawk”數據中心交換機ASIC;
首席開發官 Shrijeet Mukherjee 曾在思科、Cumulus Networks、谷歌等公司就職;
芯片設計總監Mike Jorda曾在博通負責數據中心芯片設計21年;
系統測試總監Michael Goldflam 曾在博通負責交換軟件15年;
軟件工程VP Carlo Contavalli 曾在谷歌負責軟件工程12年;
首席架構師Thomas Norrie 曾在谷歌硬件負責12年;
芯片架構師Gavin Starks曾是智能終端公司Netronome Systems的首席技術官。
Enfabrica的創始顧問Christos Kozyrakis是斯坦福大學電氣工程和科學教授,也是 MAST 的負責人,曾在谷歌和英特爾等組織從事研究;另一位重量級顧問Albert Greenberg目前在 Uber擔任平臺工程副總裁,在微軟負責Azure Networking十多年,在此之前,他是AT&T貝爾實驗室的網絡專家。擁有大規模數據分析專業知識的康奈爾大學副教授Rachit Agarwal也是Enfabrica的顧問。
Enfabrica ACF解決方案
Enfabrica致力于開發數據中心網絡芯片和軟件以支持 AI 計算工作負載,并于2023 年 3 月發布了首款名為 Accelerated Compute Fabric (ACF) 設備的芯片。據稱該芯片可為分布式人工智能、擴展現實、高性能計算和應用程序提供強大的可擴展性和性能,并節約成本。
Enfabrica表示,新資金將用于推進其突破性 ACF Switch (ACF-S) 設備和解決方案的生產,這些設備和解決方案補充了 GPU、CPU 和加速器,以解決數據中心AI和高性能計算集群中的關鍵網絡、I/O(輸入/輸出)和內存擴展問題。
英偉達投資動機
英偉達的GPU芯片面臨著一個問題:它們有時會閑置,因為連接它們的網絡無法足夠快地向它們提供數據。Enfabrica芯片創建了一個看起來像中心輻射的網絡,允許進行數據處理的Nvidia GPU從多個不同的地方提取數據,而不會碰到“減速帶”。
英偉達參與的理由正是這一點,這讓客戶能夠更有效地利用 GPU 計算資源,GPU 空閑等待數據的時間更短。據稱,在相同的性能點上,使用 ACF 能夠讓大型語言模型 (LLM) 推理的性能提高約 50%,深度學習推薦模型 (DLRM) 推理的性能提高75%。
“當前人工智能熱潮的根本挑戰是基礎設施的擴展”,Enfabrica 首席執行官兼聯合創始人 Rochan Sankar 表示。
“無可否認,人工智能為眾多行業帶來了變革性價值。但對于尋求控制其分布式人工智能基礎設施和服務的客戶來說,迫切需要將爆炸性的需求與擴展人工智能計算的總體成本、效率和易用性聯系起來。大部分擴展問題在于 I/O 子系統、內存移動和附加到 GPU 計算的網絡,而這些正是 Enfabrica 的 ACF 解決方案的亮點。”
02
Enfabrica ACF Switch (ACF-S)有什么魔力?
Enfabrica 的首款芯片ACF-S是該公司自 2020 年以來全新開發,采用完全基于標準的硬件和軟件接口,包括多端口 800 千兆位以太網網絡和高基數 PCIe Gen5 和CXL 2.0+ 接口。ACF-S 設備可在參與 AI 或加速計算工作負載的 GPU、CPU、加速器 ASIC、內存、閃存和網絡元件的任意組合之間提供可擴展、可組合、高帶寬的數據移動。
在不改變設備驅動程序上的物理接口、協議或軟件層的情況下,ACF-S 可在單個硅芯片中的異構計算和內存資源之間提供多太比特的交換和橋接,同時顯著減少設備數量、I/O 延遲跳數,以及AI 集群中由架頂式網絡交換機、RDMA-over-Ethernet NIC、Infiniband HCA、PCIe/CXL 交換機和 CPU 附加DRAM消耗的設備功率。
通過整合獨特的 CXL 內存橋接功能,Enfabrica 的 ACF-S 是第一個可以為任何加速器提供無頭內存擴展的數據中心芯片產品,使單個 GPU 機架能夠直接、低延遲、無競爭地訪問本地 CXL。內存容量是 GPU 原生高帶寬內存 (HBM) 的50倍以上。
突破 I/O 和網絡瓶頸
隨著人工智能工作負載變得愈發強大,GPU 網絡痛點以及內存和存儲擴展的挑戰也愈發緊迫。
Rochan Sankar 表示:“生成式 AI 正在迅速改變數據中心計算流量的性質和數量。人工智能訓練總量和用戶服務規模將繼續呈指數級增長。當前的服務器 I/O 和網絡解決方案存在嚴重的瓶頸,導致它們要么無法滿足需求規模,要么嚴重未充分利用昂貴的計算資源,這反過來又施加了成本和功效的壓力。”
Enfabrica 表示,其 ACF-S 芯片效率更高,可通過本機 800 Gb以太網網絡直接橋接和互連 GPU、CPU和內存資源,消除對專用網絡互連和傳統架頂通信硬件的需求,充當通用數據移動器,克服現有數據中心的 I/O 限制。
第一代 ACF-S 芯片代號為“Millennium”,現已提供樣品,Millennium 芯片的概念如下:
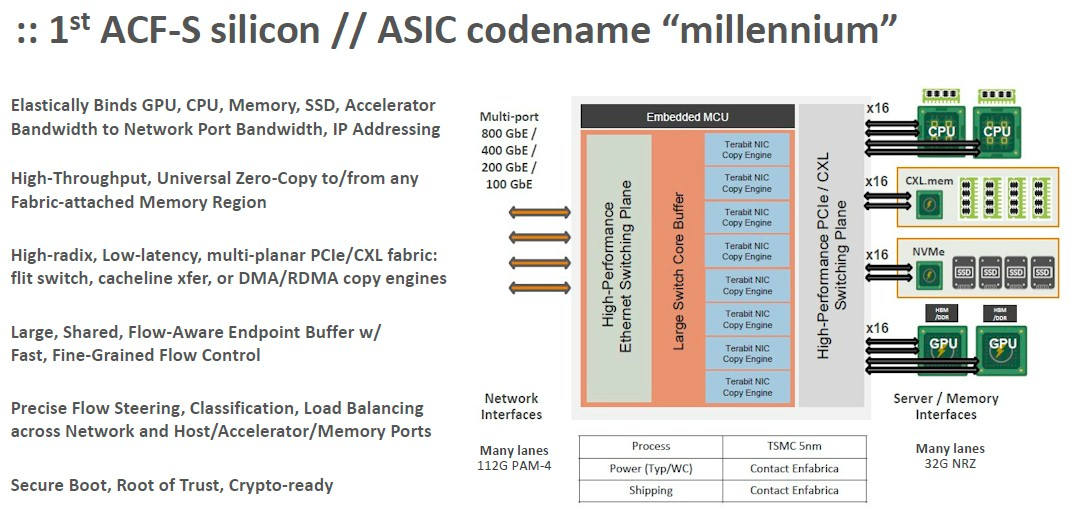
ACF-S 芯片剛發布時給自己的定位是人工智能訓練系統的核心。Enfabrica表示,它可以創建一個比英偉達和Meta創建的系統更好的可組合GPU服務器,并可以在ACF-S設備網絡中進一步擴展這種可組合性,來創建一個更大的虛擬計算和內存池,同時節約 40%左右的成本。

而現在Enfabrica又將ACF-S 設備定位為 AI 集群的網絡和內存訪問的中間層,如下所示:
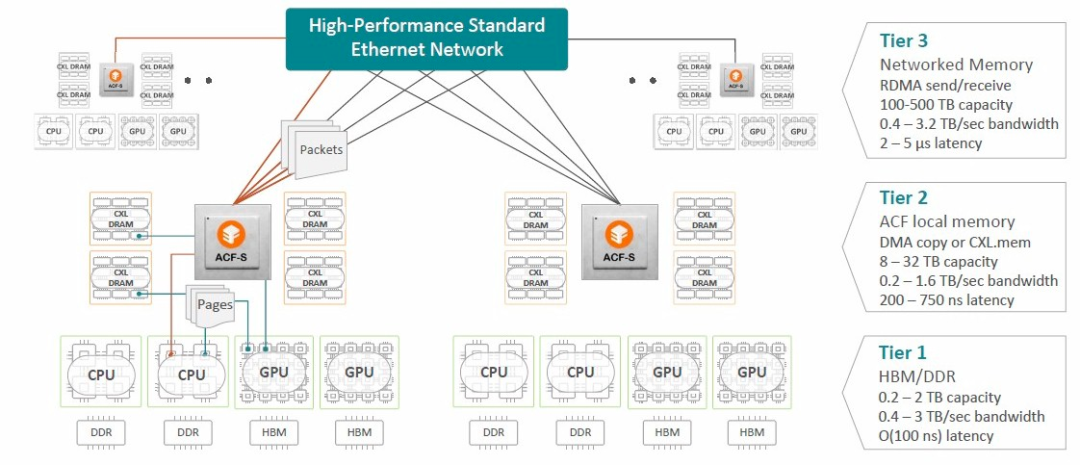
ACF-S 設備可以應用于任何 PCI-Express 加速器,無論是否為英偉達、甚至是否為 GPU。它還有助于解決限制人工智能工作負載的內存容量問題。
盡管這并不能真正解決 GPU 主機上內存的帶寬問題,但它確實意味著外殼內的 GPU 池可以共享節點內的內存,并且 ACF-S 設備的層次結構可以為此創建一個結構內存池。請注意,所有這些都是在 CXL 3.0 協議實際投入使用之前完成的,以便在大型 GPU 節點集群中更廣泛地共享。
或者如果你只是想使用 Grace-Hopper 超級芯片,可以這樣做:
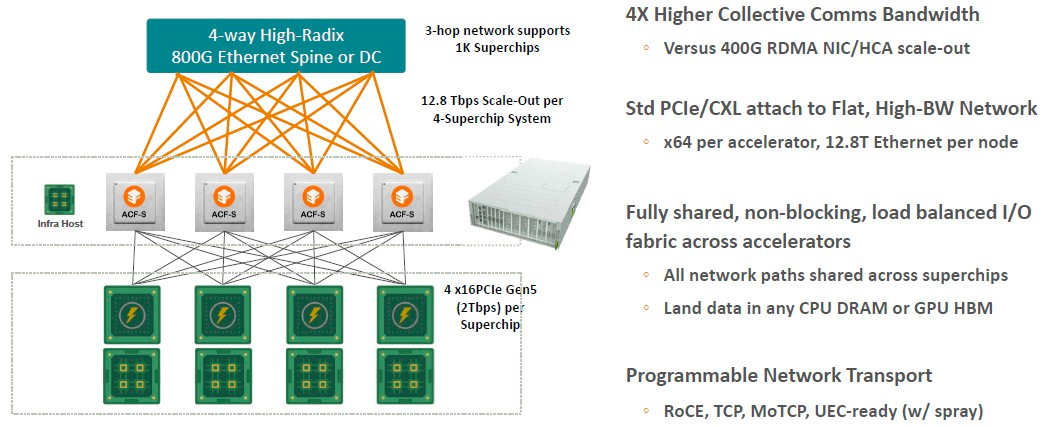
在leaf/spine網絡中,800 Gb/秒以太網交換機作為spine,ACF-S 設備作為leaf,三跳網絡中最多可支持 1,000 個 Grace-Hopper 設備,這就是一臺相當厲害的人工智能超級計算機了。Nvidia DXG GH100 集群最多擁有 256 個 Grace-Hopper 超級芯片。在spine網絡中添加另一跳可以進一步擴展它,但這也會增加網絡延遲。
“像這樣的平臺的想法是,我們可以構建一個數據中心規模的人工智能網絡,該網絡可以適當地分層和分解資源,這樣不僅可以優化性能,還可以優化可組合性,”Sankar 表示,“現在,所有的東西都被裝進了這些極其巨大、極其昂貴的設備中。但我們創建了一個黑匣子,可以實現數據中心范圍內的可組合性。因此,可以改變 GPU 的數量、改變 CPU 的數量,就像我們需要為人工智能推理和人工智能訓練所做的那樣。根據 GPU 的選擇,你可能會有不同的內存與計算觸發器的比率。我們的系統支持對最靠近 GPU 的內存進行分層,一直到我們所說的用于接收和移動數據的場內存。它提供上下文存儲、預處理、標記、檢查點,所有這些功能需要大量的快速存儲。目前,GPU 的運行方式類似于 L1 緩存,所有內容都位于 HBM 內存中。相比之下,我們提供了以極其靈活和高性能的方式移動和存儲數據的能力。”
再或者,你需要為LLM創建一個成本較低的推理引擎,你可以:
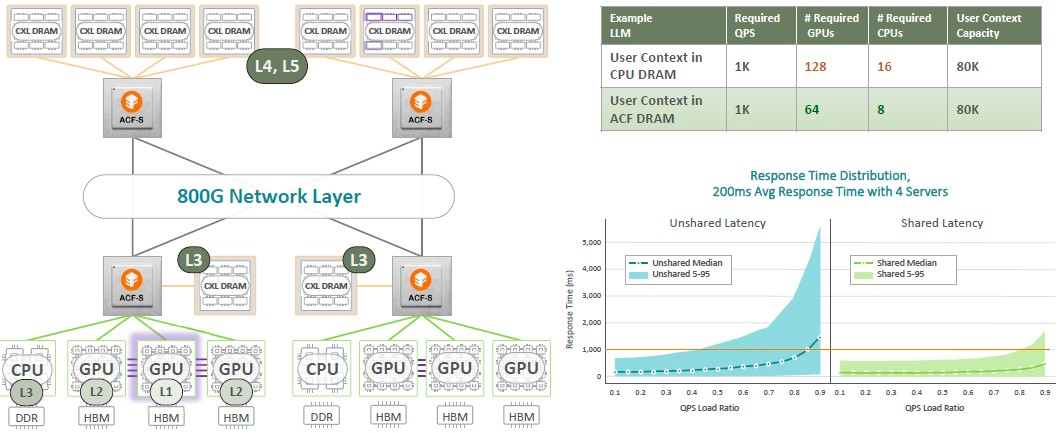
Enfabrica 認為通過將 CXL DRAM 掛在網絡不同部分的 ACF-S 設備上,可以用一半數量的 CPU 和 GPU 來驅動推理。
ACF-S 取代 DPU?
ACF-S的網絡節點:

我們可以看到 ACF-S 取代了 NIC,但我們不確定它能在多大程度上取代真正的、成熟的 DPU。但長遠來看,ACF-S 應該奔著這個目標去做,這可以讓企業不必為每臺服務器再額外購買 DPU。

ACF-S 系統可配置為 GPU 網絡節點,托管最多 10 個 PCI-Express 5.0 x16 設備和最多 4 個 800 Gb/秒或 8 個 400 Gb/秒。它具有足夠的能力在服務器底座中托管多達 8 個 GPU 加速器或多達 20 個 CPU。
作為內存池節點,ACF-S 系統最多可擁有4個 2 TB CXL 附加卡,總共 8 TB DDR5 內存,4個連接到服務器的 PCI-Express 5.0 x16 端口以及相同的4個 800 Gb/秒或8個 400 Gb/秒以太網端口連接到網絡。
下圖是 GPU/CPU 節點配置的例子,展示了兩個 ACF-S ASIC、八個 GPU 以及一對主機 CPU 卡:

每個機架的 I/O 組件減少了 75%,I/O 組件功率減少了 50%。
綜上看來,英偉達成為 Enfabrica B 輪融資的投資者之一也就不足為奇了。
目前英偉達正在投資各種初創公司,就像英特爾在過去二十年所做的那樣,這是為了與你的合作伙伴以及你的潛在競爭對手保持更親密的關系。
但也有分析師表示,Enfabrica完全具備作為英偉達競爭對手的潛力,未來英偉達可能會考慮收購這家初創公司。
-
數據分析
+關注
關注
2文章
1427瀏覽量
34012 -
英偉達
+關注
關注
22文章
3743瀏覽量
90831 -
網絡芯片
+關注
關注
0文章
30瀏覽量
12088
原文標題:英偉達為什么要投資網絡芯片初創公司Enfabrica?
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英偉達愈發強勢,AI芯片初創公司仍不服輸

今日看點丨英偉達1.5億美元注資聊天機器人初創公司Kore.ai;知名上市公司涉嫌重大財務造假
英偉達GPU慘遭專業礦機碾壓,黃仁勛宣布砍掉加密貨幣業務!
英偉達DPU的過“芯”之處
塑造科技未來:12家企業亮相GTC中國線上大會英偉達初創企業展示
高通挑釁蘋果:斥資14億美元收購芯片初創公司Nuvia
英偉達的投資版圖







 工商網監
工商網監
評論