 DreamLLM:多功能多模態大型語言模型,你的DreamLLM~
DreamLLM:多功能多模態大型語言模型,你的DreamLLM~
今天為大家介紹西安交大,清華大學、華中科大聯合MEGVII Technology的一篇關于多模態LLM學習框架的論文,名為DREAMLLM。
- 論文:DreamLLM: Synergistic Multimodal Comprehension and Creation
- 論文鏈接:https://arxiv.org/abs/2309.11499
- GitHub:https://github.com/RunpeiDong/DreamLLM
摘要
DREAMLLM是一個學習框架,實現了通用的多模態大型語言模型(Multimodal Large Language Models,MLLMs),該模型利用了多模態理解和創造之間經常被忽視的協同作用。DREAMLLM的運作遵循兩個基本原則:一是在原始多模態空間中通過直接采樣對語言和圖像后驗進行生成建模有助于獲取更徹底的多模態理解。二是促進了原始、交錯文檔的生成,對文本和圖像內容以及非結構化布局進行建模,使得模型能夠有效地學習所有條件、邊際和聯合多模式分布。
簡介
在多模態任務中,內容理解和創作是機器智能的終極目標之一。為此,多模式大語言模型成功進入視覺領域。MLLMs在多模態理解能力方面取得了前所未有的進展。通常通過將圖像作為多模式輸入來增強LLM,以促進語言輸出的多模式理解。其目的是通過語言后驗來捕捉多模式的條件分布或邊際分布。然而,涉及生成圖像、文本或兩者的多模式創作,需要一個通用的生成模型來同時學習語言和圖像后驗,而這一點目前尚未得到充分的探索。最近,一些工作顯示出使用MLLMs的條件圖像生成的成功。如下圖所示,
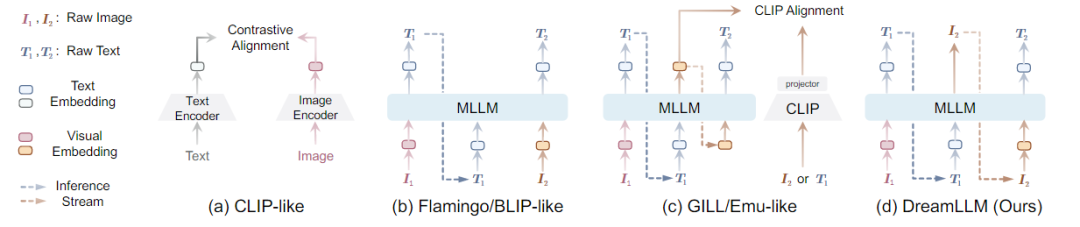
由于固有的模態缺口,如CLIP語義主要關注模態共享信息,往往忽略了可以增強多模態理解的模態特定知識。因此,這些研究并沒有充分認識到多模式創造和理解之間潛在的學習協同作用,只顯示出創造力的微小提高,并且在多模式理解方面仍然存在不足。
創新點:DREAMLLM以統一的自回歸方式生成原始語言和圖像輸入,本質上實現了交錯生成。
知識背景
- Autoregressive Generative Modeling:自回歸生成建模
- Diffusion Model:擴散模型
MLLMs具體做法:現有策略會導致MLLMs出現語義減少的問題,偏離其原始輸出空間,為了避免,提出了替代學習方法如下圖所示,即DREAMLLM模型框架。
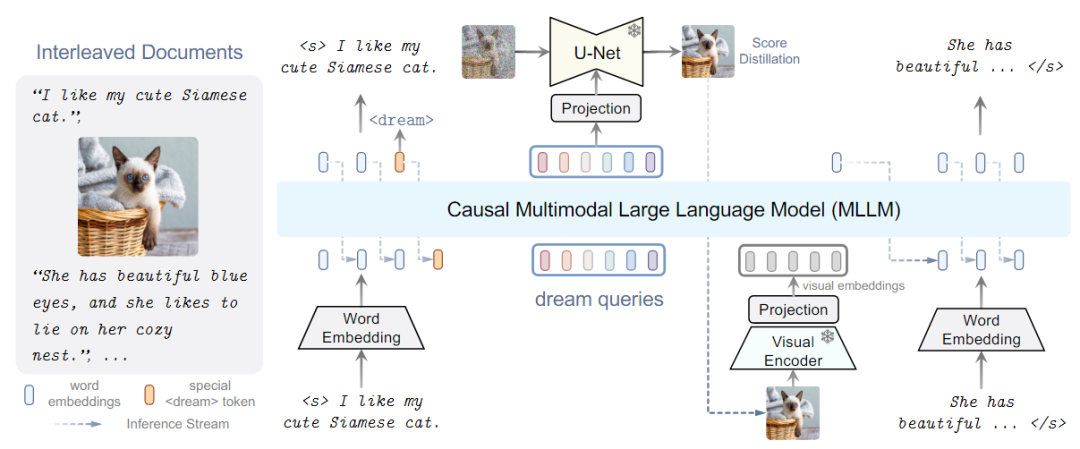
DREAMLLM架構
DREAMLLM框架如上圖所示,使用交錯的文檔用作輸入,解碼以產生輸出。文本和圖像都被編碼成用于MLLM輸入的順序的、離散的token嵌入。特殊的<dream>標記可以預測在哪里生成圖像。隨后,一系列dream查詢被輸入到MLLM中,捕獲整體歷史語義。圖像由stable diffusion圖像解碼器以查詢的語義為條件進行合成。然后將合成的圖像反饋到MLLM中用于隨后的理解。
其中MLLM是基于在shareGPT上訓練的LLama的Vicuna,采用CLIP-Large作為圖像編碼器,為了合成圖像使用Stable Diffusion作為圖像解碼器。
模型訓練
模型訓練分為對齊訓練、I-GPT預訓練和監督微調。
實驗結果
-
多模態理解:多模式理解使人類能夠與以單詞和視覺內容為條件的主體進行互動。本文評估了DREAMLLM在幾個基準上的多模式視覺和語言能力。此外,對最近開發的MMBench和MM-Vet基準進行了零樣本評估,以評估模型在復雜多模式任務中的性能。
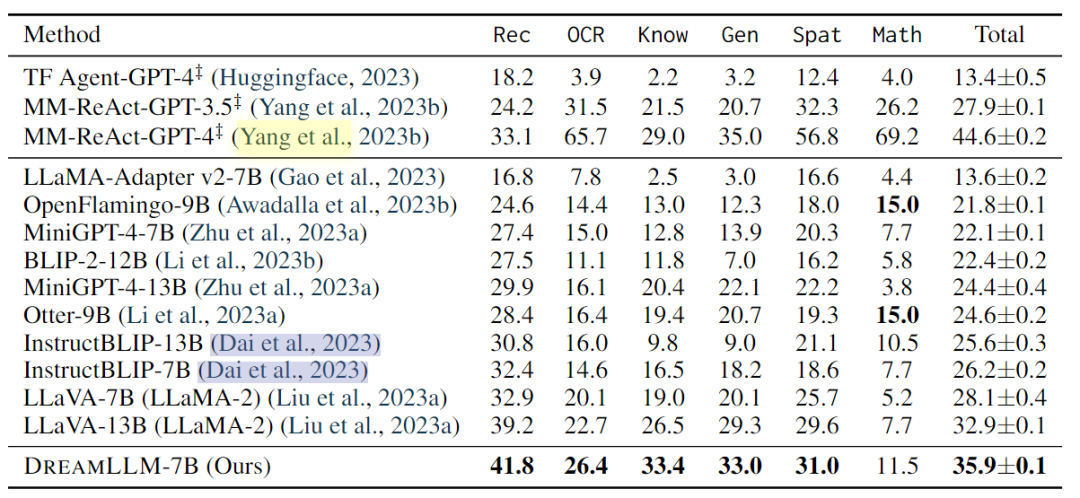
-
發現,DREAMLLM在所有基準測試中都優于其他MLLM。值得注意的是,DREAMLLM-7B在圖像合成能力方面大大超過了并發MLLMs,與Emu-13B相比,VQAv2的精度提高了16.6。在MMBench和MMVet等綜合基準測試中,DREAMLLM與所有7B同行相比都取得了最先進的性能。
-
條件文本圖像合成:條件文本圖像合成是創造性內容生成最常用的技術之一,它通過自由形式的語言生成遵循人類描述的圖像。
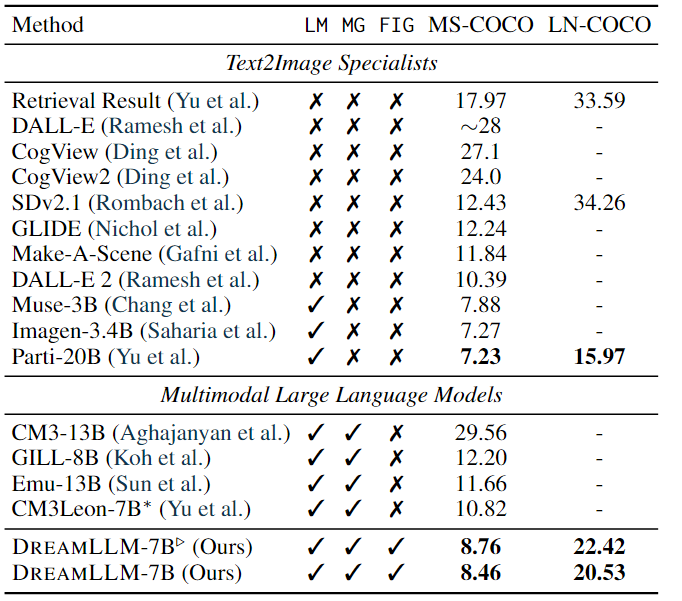
-
其結果如上表所示。結果顯示:DREAMLLM 在階段I對齊后顯示出比Stable Diffusion基線顯著提高FID,在 MS-COCO 和 LN-COCO 上分別將分數分別降低了 3.67 和 11.83。此外,預訓練和監督微調后實現了 3.97 和 13.73 的 FID 改進。LN-COCO 的實質性改進強調了 DREAMLLM 在處理長上下文信息方面的卓越性能。與之前的專家模型相比,DREAMLLM 基于 SD 圖像解碼器提供了有競爭力的結果。DREAMLLM 始終優于基于并發 MLLM 的圖像合成方法。
-
多模態聯合創建于比較:分別進行了自由形式的交錯文檔創建、圖片質量和人工評估三個實驗。實驗結果表明:DREAMLLM可以根據給定的指令生成有意義的響應。系統可以通過預測所提出的令牌在任何指定位置自主創建圖像,從而消除了對額外人工干預的需要。DREAMLLM生成的圖像準確地對應于相關文本。證明了所提方法的有效性。
總結
本文介紹了一個名為DREAMLLM的學習框架,它能夠同時實現多模態理解和創作。DREAMLLM具有兩個基本原則:第一個原則是通過在原始多模態空間中進行直接采樣,生成語言和圖像后驗概率的生成建模。第二個原則是促進生成原始、交錯文檔,模擬文本和圖像內容以及無結構的布局,使DREAMLLM能夠有效地學習所有條件、邊際和聯合多模態分布。實驗結果表明,DREAMLLM是第一個能夠生成自由形式交錯內容的MLLM,并具有卓越的性能。
-
框架
+關注
關注
0文章
399瀏覽量
17437 -
語言模型
+關注
關注
0文章
508瀏覽量
10247 -
機器智能
+關注
關注
0文章
55瀏覽量
8588
原文標題:DreamLLM:多功能多模態大型語言模型,你的DreamLLM~
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
利用大語言模型做多模態任務
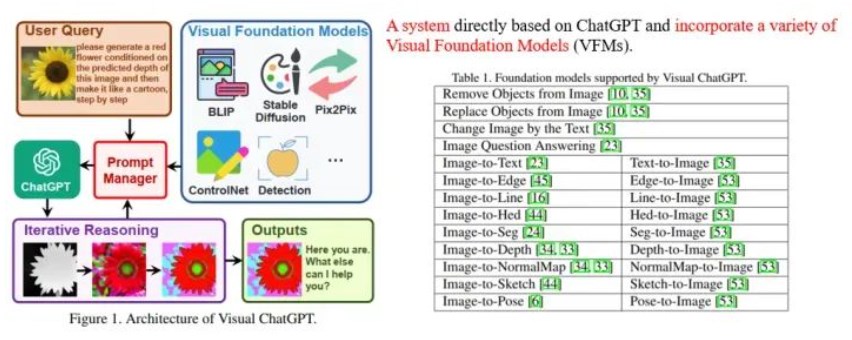
如何利用LLM做多模態任務?
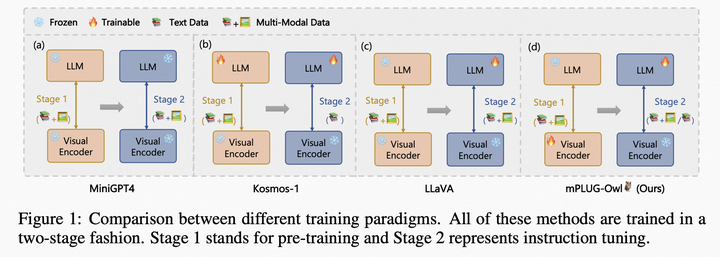
邱錫鵬團隊提出具有內生跨模態能力的SpeechGPT,為多模態LLM指明方向


更強更通用:智源「悟道3.0」Emu多模態大模型開源,在多模態序列中「補全一切」

哈工大提出Myriad:利用視覺專家進行工業異常檢測的大型多模態模型

自動駕駛和多模態大語言模型的發展歷程

機器人基于開源的多模態語言視覺大模型






 工商網監
工商網監
評論