") 如何快速部署邊緣就緒的機(jī)器學(xué)習(xí)應(yīng)用
如何快速部署邊緣就緒的機(jī)器學(xué)習(xí)應(yīng)用
作者:Stephen Evanczuk
機(jī)器學(xué)習(xí) (ML) 為創(chuàng)造智能產(chǎn)品提供了巨大的潛力,但神經(jīng)網(wǎng)絡(luò) (NN) 建模和為邊緣創(chuàng)建 ML應(yīng)用非常復(fù)雜且困難,限制了開發(fā)人員快速交付有用解決方案的能力。雖然現(xiàn)成的工具使 ML 模型的創(chuàng)建在總體上更加容易,但傳統(tǒng)的 ML 開發(fā)實(shí)踐并不是為了滿足物聯(lián)網(wǎng)(IoT)、汽車、工業(yè)系統(tǒng)和其他嵌入式應(yīng)用解決方案的獨(dú)特要求而設(shè)計(jì)的。
本文首先對(duì) NN 建模進(jìn)行簡(jiǎn)要介紹,然后介紹并描述如何使用 NXP Semiconductors 的綜合 ML 平臺(tái)讓開發(fā)人員更有效地交付邊緣就緒的 ML應(yīng)用。
NN 建模快速回顧
ML算法為開發(fā)人員提供了截然不同的應(yīng)用開發(fā)選擇。開發(fā)人員不是編寫軟件代碼來明確解決諸如圖像分類等問題,而是提供一組數(shù)據(jù)——例如標(biāo)注了所含實(shí)體的真實(shí)名稱(或類別)的圖像——來訓(xùn)練NN 模型。訓(xùn)練過程使用各種方法來計(jì)算模型的參數(shù),即每個(gè)神經(jīng)元和每層的權(quán)重和偏置值,使模型能夠?qū)斎雸D像的正確類別提供相當(dāng)準(zhǔn)確的預(yù)測(cè)(圖 1)。
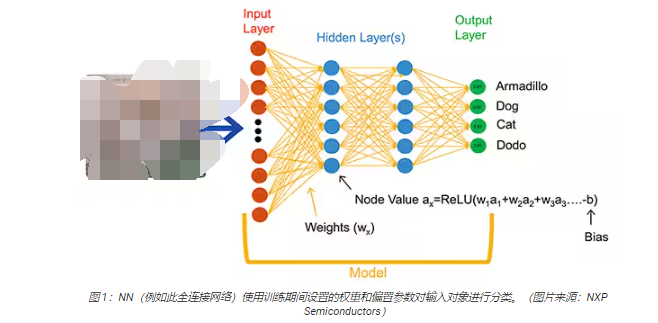
除圖 1 所示的通用全連接 NN 外,ML 研究人員還發(fā)展了范圍廣泛的 NN 架構(gòu)。例如,圖像分類應(yīng)用通常利用一種專門的架構(gòu)——卷積神經(jīng)網(wǎng)絡(luò)(CNN),它將圖像識(shí)別分成兩個(gè)階段:初始階段查找圖像的關(guān)鍵特征,分類階段預(yù)測(cè)它可能屬于訓(xùn)練期間確定的多個(gè)類別中的哪一類(圖 2)。

盡管只有 ML
專家能夠選擇適當(dāng)?shù)哪P图軜?gòu)和訓(xùn)練方案,但多種開源和商用工具的出現(xiàn)極大地簡(jiǎn)化了大規(guī)模部署的模型開發(fā)。如今,開發(fā)人員使用幾行代碼便可定義模型(清單1),然后利用開源 Netron 模型查看器等工具生成模型的圖形表示(圖 3),以檢查每一層的定義和連接。
def model_create(shape_in, shape_out):
from keras.regularizers import l2
tf.random.set_seed(RANDOM_SEED)
model = tf.keras.Sequential()
model.add(tf.keras.Input(shape=shape_in, name=‘acceleration’))
model.add(tf.keras.layers.Conv2D(8, (4, 1), activation=‘relu’))
model.add(tf.keras.layers.Conv2D(8, (4, 1), activation=‘relu’))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.MaxPool2D((8, 1), padding=‘valid’))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(64, kernel_regularizer=l2(1e-4),
bias_regularizer=l2(1e-4), activation=‘relu’))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(32, kernel_regularizer=l2(1e-4),
bias_regularizer=l2(1e-4), activation=‘relu’))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(shape_out, activation=‘softmax’))
model.compile(optimizer=‘a(chǎn)dam’, loss=‘categorical_crossentropy’,
metrics=[‘a(chǎn)cc’])
return model
清單 1:開發(fā)人員只需使用幾行代碼便可定義 NN 模型。(代碼來源:NXP Semiconductors)

對(duì)于最終部署,其他工具會(huì)剝離僅訓(xùn)練期間需要的模型結(jié)構(gòu),并執(zhí)行其他優(yōu)化以創(chuàng)建高效的推理模型。
為智能產(chǎn)品開發(fā)基于 ML 的應(yīng)用為什么如此困難
為物聯(lián)網(wǎng)或其他智能產(chǎn)品定義和訓(xùn)練模型,與為企業(yè)級(jí)機(jī)器學(xué)習(xí)應(yīng)用創(chuàng)建模型的工作流程相似。然而,盡管相似,但為邊緣開發(fā) ML應(yīng)用存在多種額外的挑戰(zhàn)。除模型開發(fā)外,設(shè)計(jì)人員還面臨一些常見的挑戰(zhàn),即開發(fā)所需的主應(yīng)用以運(yùn)行其基于微控制器 (MCU) 的產(chǎn)品。因此,將 ML引入邊緣需要管理兩個(gè)相互關(guān)聯(lián)的工作流程(圖 4)。

雖然嵌入式開發(fā)人員熟悉 MCU 項(xiàng)目的工作流程,但當(dāng)開發(fā)人員努力創(chuàng)建一個(gè)優(yōu)化的 ML 推理模型時(shí),ML 項(xiàng)目會(huì)對(duì)基于 MCU的應(yīng)用提出額外的要求。事實(shí)上,ML項(xiàng)目會(huì)極大地影響嵌入式設(shè)備的要求。模型執(zhí)行通常涉及繁重的計(jì)算負(fù)載和存儲(chǔ)器需求,這可能超出了物聯(lián)網(wǎng)和智能產(chǎn)品中使用的微控制器資源的能力。為了減少資源需求,ML專家會(huì)運(yùn)用各種技術(shù),例如:模型網(wǎng)絡(luò)修剪、壓縮、量化到較低精度,甚至使用單比特參數(shù)和中間值,以及其他方法。
然而,即使采用這些優(yōu)化方法,開發(fā)人員仍可能發(fā)現(xiàn)常規(guī)微控制器在處理與 ML 算法相關(guān)的大量數(shù)學(xué)運(yùn)算方面性能不足。另一方面,使用高性能應(yīng)用處理器可以處理 ML計(jì)算負(fù)載,但這種方法可能導(dǎo)致延遲增加和非確定性響應(yīng),影響其嵌入式設(shè)計(jì)的實(shí)時(shí)特性。
除了硬件選擇方面的挑戰(zhàn),為邊緣提供優(yōu)化的 ML 模型還存在嵌入式應(yīng)用開發(fā)所特有的額外挑戰(zhàn)。為企業(yè)級(jí) ML應(yīng)用開發(fā)的大量工具和方法,可能無法很好地?cái)U(kuò)展到嵌入式應(yīng)用開發(fā)人員的應(yīng)用和工作環(huán)境中。即使經(jīng)驗(yàn)豐富的嵌入式應(yīng)用開發(fā)人員,為了能夠快速部署基于 ML的設(shè)備,也可能需要在大量可用的 NN 模型架構(gòu)、工具、框架和工作流程中竭力尋找有效的解決方案。
NXP 解決了邊緣 ML 開發(fā)的硬件性能和模型實(shí)現(xiàn)兩方面的問題。在硬件層面,NXP 的高性能 i.MX RT1170 跨界微控制器滿足了邊緣 ML的廣泛性能要求。為了充分利用這一硬件基礎(chǔ),NXP 的 eIQ(邊緣智能)ML 軟件開發(fā)環(huán)境和應(yīng)用軟件包提供了一種高效解決方案以創(chuàng)建邊緣就緒的 ML應(yīng)用,它既適合沒有經(jīng)驗(yàn)的 ML 開發(fā)人員,也適合 ML 開發(fā)專家。
用于開發(fā)邊緣就緒 ML 應(yīng)用的高效平臺(tái)
NXP 的 i.MX RT 跨界處理器兼具傳統(tǒng)嵌入式微控制器的實(shí)時(shí)、低延遲響應(yīng)與高性能應(yīng)用處理器的執(zhí)行能力。NXP 的 i.MX RT1170跨界處理器系列集成了高能效 Arm?Cortex?-M4 和高性能 Arm Cortex-M7處理器,以及運(yùn)行嚴(yán)苛應(yīng)用所需的大量功能塊和外設(shè),包括嵌入式設(shè)備中基于 ML 的解決方案(圖 5)。

NXP 的 eIQ 環(huán)境完全集成到 NXP 的 MCUXpresso SDK 和 Yocto 開發(fā)環(huán)境中,專門用于促進(jìn)在利用 NXP微處理器和微控制器構(gòu)建的嵌入式系統(tǒng)上實(shí)現(xiàn)推理模型。eIQ 環(huán)境中包含 eIQ 工具包,后者通過多個(gè)工具支持“自帶數(shù)據(jù)”(BYOD) 和“自帶模型”(BYOM)工作流程,這些工具包括 eIQ Portal、eIQ Model Tool 和命令行工具(圖 6)。
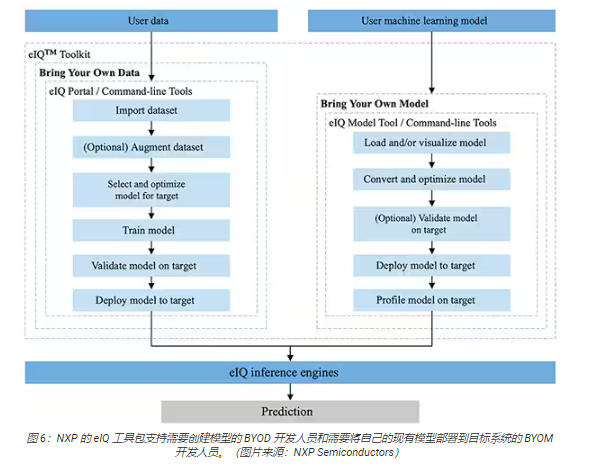
eIQ Portal 旨在同時(shí)支持 ML 模型開發(fā)專家和新手開發(fā)人員的 BYOD 工作流程,它提供了一個(gè)圖形用戶界面(GUI),以幫助開發(fā)人員更輕松地完成模型開發(fā)工作流程的每個(gè)階段。
在開發(fā)的初始階段,eIQ Portal 的數(shù)據(jù)集管理工具幫助開發(fā)人員導(dǎo)入數(shù)據(jù),從連接的相機(jī)中捕獲數(shù)據(jù),或從遠(yuǎn)程設(shè)備中捕獲數(shù)據(jù)(圖 7)。

開發(fā)人員使用數(shù)據(jù)集管理工具給數(shù)據(jù)集中的每個(gè)項(xiàng)目添加注釋或標(biāo)記,既可標(biāo)記整幅圖像,也可只標(biāo)記指定邊界框內(nèi)包含的特定區(qū)域。擴(kuò)展功能通過使圖像模糊、添加隨機(jī)噪聲、更改特征(如亮度或?qū)Ρ榷龋┘捌渌椒ǎ瑤椭_發(fā)人員為數(shù)據(jù)集提供所需的多樣性。
在下一階段,eIQ Portal幫助開發(fā)人員選擇最適合應(yīng)用的模型類型。對(duì)于不確定模型類型的開發(fā)人員,模型選擇向?qū)?huì)根據(jù)應(yīng)用類型和硬件基礎(chǔ)引導(dǎo)開發(fā)人員完成選擇過程。如果已經(jīng)知道自己需要的模型類型,開發(fā)人員可以選擇eIQ 安裝時(shí)提供的自定義模型或其他自定義實(shí)現(xiàn)方法。
eIQ Portal 引導(dǎo)開發(fā)人員完成下一關(guān)鍵訓(xùn)練步驟,并提供一個(gè)直觀的圖形用戶界面,以便用戶修改訓(xùn)練參數(shù)和查看模型預(yù)測(cè)精度隨每個(gè)訓(xùn)練步驟的變化(圖8)。

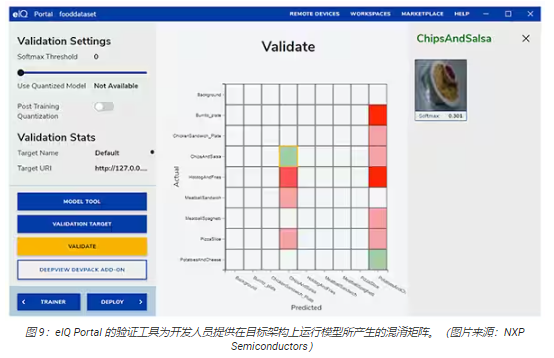
在下一步,eIQ Portal GUI幫助開發(fā)人員驗(yàn)證模型。在此階段,模型轉(zhuǎn)換至目標(biāo)架構(gòu)上運(yùn)行,以確定其實(shí)際性能。完成驗(yàn)證后,驗(yàn)證屏幕會(huì)顯示混淆矩陣——這是一個(gè)基本的 ML驗(yàn)證工具,允許開發(fā)人員將輸入對(duì)象的實(shí)際類別與模型預(yù)測(cè)的類別進(jìn)行比較(圖 9)。
對(duì)于最終部署,該環(huán)境允許開發(fā)人員根據(jù)處理器選擇目標(biāo)推理引擎,包括:
Arm CMSIS-NN(通用微控制器軟件接口標(biāo)準(zhǔn),神經(jīng)網(wǎng)絡(luò))— 為在 Arm Cortex-M處理器內(nèi)核上實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)的性能最大化和內(nèi)存占用最小化而開發(fā)的神經(jīng)網(wǎng)絡(luò)內(nèi)核
Arm NN SDK(神經(jīng)網(wǎng)絡(luò),軟件開發(fā)套件)— 一套工具和推理引擎,用于在現(xiàn)有神經(jīng)網(wǎng)絡(luò)框架和 Arm Cortex-A 處理器之間搭建橋梁等
DeepViewRT — 用于 i.MX RT 跨界 MCU 的 NXP 專有推理引擎
Glow NN — 基于 Meta 的 Glow (graph lowering) 編譯器,由 NXP 針對(duì) Arm Cortex-M 內(nèi)核進(jìn)行優(yōu)化,使用CMSIS-NN 內(nèi)核的函數(shù)調(diào)用或 Arm NN 庫(如有),或者從其自身的本地庫編譯代碼
ONXX Runtime — Microsoft Research 的工具,旨在針對(duì) Arm Cortex-A 處理器優(yōu)化性能
用于微控制器的 TensorFlow Lite — TensorFlow Lite 的較小版本,為在 i.MX RT 跨界 MCU上運(yùn)行機(jī)器學(xué)習(xí)模型而優(yōu)化
TensorFlow Lit — TensorFlow 的一個(gè)版本,為較小系統(tǒng)提供支持
對(duì)于 BYOM 工作流程,開發(fā)人員可以使用 eIQ Model Tool 直接進(jìn)入模型分析和每層時(shí)間剖析。對(duì)于 BYOD 和 BYOM工作流程,開發(fā)人員可以使用 eIQ 命令行工具訪問工具功能以及非直接通過 GUI 提供的 eIQ 特性。
除了本文描述的特性外,eIQ 工具包還支持一系列廣泛的功能,包括遠(yuǎn)遠(yuǎn)超出本文范圍的模型轉(zhuǎn)換和優(yōu)化。然而,為了快速開發(fā)邊緣就緒 ML應(yīng)用的原型,開發(fā)人員通常可以快速完成開發(fā)和部署,幾乎不需要使用 eIQ 環(huán)境中許多較復(fù)雜的功能。事實(shí)上,NXP 的專業(yè)應(yīng)用軟件 (App SW)包提供了完整的應(yīng)用,開發(fā)人員可以使用這些應(yīng)用立即開展評(píng)估,或?qū)⑵渥鳛樽约憾ㄖ茟?yīng)用的基礎(chǔ)。
如何使用應(yīng)用軟件包快速評(píng)估模型開發(fā)
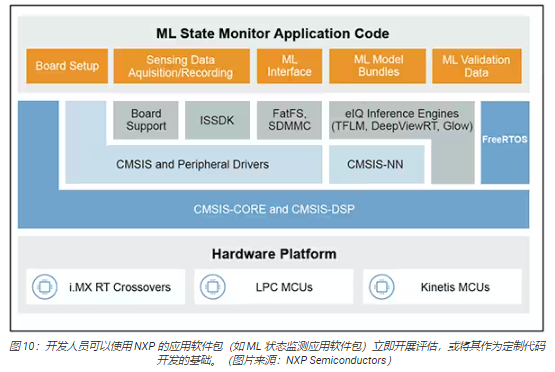
NXP 的應(yīng)用軟件包集生產(chǎn)就緒的源代碼、驅(qū)動(dòng)程序、中間件和工具于一體,提供完整的基于 ML 的應(yīng)用。例如,NXP 的 ML狀態(tài)監(jiān)測(cè)應(yīng)用軟件包為基于傳感器輸入確定復(fù)雜系統(tǒng)的狀態(tài)這一常見問題提供了一個(gè)基于 ML 的快速解決方案(圖 10)。
ML 狀態(tài)監(jiān)測(cè)應(yīng)用軟件包實(shí)現(xiàn)了一個(gè)完整的應(yīng)用解決方案,可檢測(cè)風(fēng)扇工作在四種狀態(tài)中的哪一種狀態(tài):
ON
OFF
CLOGGED,當(dāng)風(fēng)扇開啟但氣流被阻擋時(shí)
FRICTION,當(dāng)風(fēng)扇開啟,但一個(gè)或多個(gè)風(fēng)扇葉片在運(yùn)行過程中遇到過大摩擦?xí)r
對(duì)于模型開發(fā)人員,同樣重要的是,ML 狀態(tài)監(jiān)測(cè)應(yīng)用軟件包除包括 ML 模型外,還包括一個(gè)完整數(shù)據(jù)集,它代表了風(fēng)扇在這四種狀態(tài)下運(yùn)行的加速度計(jì)讀數(shù)。
開發(fā)人員可以研究 ML狀態(tài)監(jiān)測(cè)應(yīng)用軟件包提供的代碼、模型和數(shù)據(jù),以了解如何使用傳感器數(shù)據(jù)訓(xùn)練模型,創(chuàng)建推理模型,并針對(duì)驗(yàn)證傳感器數(shù)據(jù)集驗(yàn)證推理。事實(shí)上,NXP 的應(yīng)用軟件包中包含的ML_State_Monitor.ipynb Jupyter Notebook 提供了一個(gè)開箱即用的工具,支持在任何硬件部署之前研究模型開發(fā)工作流程。
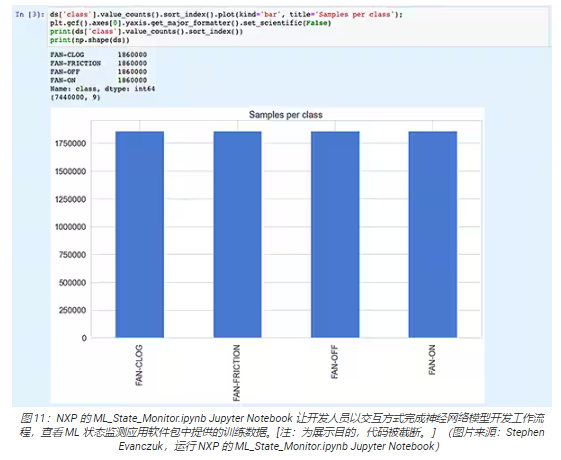
Jupyter Notebook 是一個(gè)基于瀏覽器的互動(dòng)式 Python 執(zhí)行平臺(tái),允許開發(fā)人員立即查看 Python 代碼的執(zhí)行結(jié)果。運(yùn)行Jupyter Notebook 會(huì)生成一個(gè) Python代碼塊,緊接著出現(xiàn)該代碼塊的運(yùn)行結(jié)果。這些結(jié)果不是簡(jiǎn)單的靜態(tài)展示,而是通過運(yùn)行代碼得到的實(shí)際結(jié)果。例如,開發(fā)人員運(yùn)行 NXP 的ML_State_Monitor.ipynb Jupyter Notebook 時(shí),可以立即查看輸入數(shù)據(jù)集的摘要(圖 11)。
Notebook 中的下一部分代碼為用戶提供了輸入數(shù)據(jù)的圖形顯示,以時(shí)間序列和頻率的單獨(dú)圖形呈現(xiàn)(圖 12)。

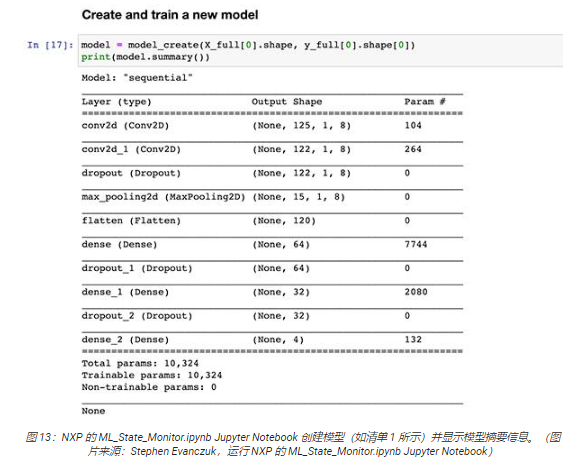
其他代碼部分提供了進(jìn)一步的數(shù)據(jù)分析、規(guī)一化、整形和其他準(zhǔn)備工作,直至代碼執(zhí)行到清單 1 中顯示的模型創(chuàng)建函數(shù)定義 model_create()。接下來的代碼部分將執(zhí)行此 model_create() 函數(shù),并打印出摘要以供快速驗(yàn)證(圖 13)。
在部分模型訓(xùn)練和評(píng)估代碼之后,ML_State_Monitor.ipynb Jupyter Notebook顯示完整數(shù)據(jù)集、訓(xùn)練數(shù)據(jù)集和驗(yàn)證數(shù)據(jù)集(從訓(xùn)練數(shù)據(jù)集中排除的數(shù)據(jù)集的子集)的每個(gè)混淆矩陣。在這種情況下,完整數(shù)據(jù)集的混淆矩陣展現(xiàn)出良好的精度和一定的誤差,其中最明顯的是模型將一小部分?jǐn)?shù)據(jù)集混淆為處于ON 狀態(tài),而根據(jù)原始數(shù)據(jù)集的注釋,它們實(shí)際上處于 CLOGGED 狀態(tài)(圖 14)。

在后面的代碼部分,模型被導(dǎo)出為幾種不同的模型類型和格式,由 eIQ 開發(fā)環(huán)境支持的各種推理引擎使用(圖 15)。

推理引擎的選擇對(duì)于滿足特定性能要求至關(guān)重要。對(duì)于該應(yīng)用,NXP測(cè)量了以幾種不同推理引擎為目標(biāo)的模型大小、代碼大小和推理時(shí)間(對(duì)單一輸入對(duì)象完成推理所需的時(shí)間),一個(gè)以 996 MHz 運(yùn)行,一個(gè)以 156 MHz 運(yùn)行(圖16 和 17)。

正如 NXP 指出的那樣,此樣例應(yīng)用使用的是一個(gè)非常小的模型,所以這些數(shù)字的差異相當(dāng)明顯,但對(duì)于復(fù)雜分類所用的大型模型,差異可能要小得多。
構(gòu)建用于狀態(tài)監(jiān)測(cè)的系統(tǒng)解決方案
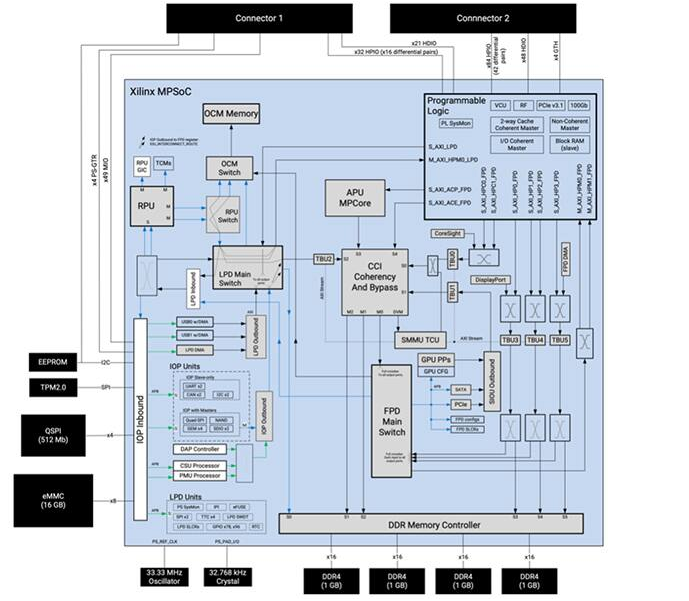
除了用于交互式探索模型開發(fā)工作流程的 Jupyter Notebook,NXP 的 ML 狀態(tài)監(jiān)測(cè)應(yīng)用軟件包還提供完整的源代碼,用于在 NXP 的MIMXRT1170-EVK 評(píng)估板上實(shí)現(xiàn)設(shè)計(jì)。評(píng)估板圍繞 NXP 的 MIMXRT1176DVMAA 跨界 MCU構(gòu)建,提供一個(gè)全面的硬件平臺(tái),并配備了額外的存儲(chǔ)器和多個(gè)接口(圖 18)。

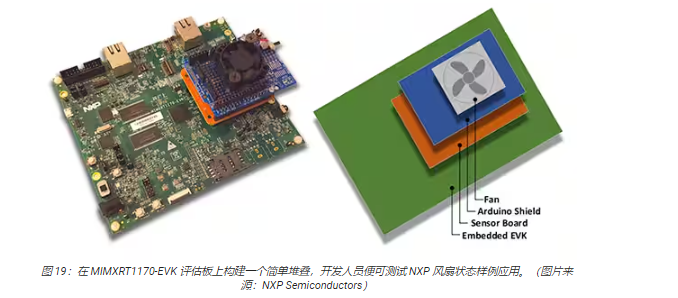
將 MIMXRT1170-EVK 評(píng)估板與可選的 NXP FRDM-STBC-AGM01 傳感器板、Arduino 擴(kuò)展板和合適的 5 V無刷直流風(fēng)扇(如 Adafruit 的 4468)堆疊起來,開發(fā)人員便可使用 NXP 的風(fēng)扇狀態(tài)應(yīng)用來預(yù)測(cè)風(fēng)扇的狀態(tài)(圖 19)。
借助 MCUXpresso 集成開發(fā)環(huán)境 (IDE),開發(fā)人員可以配置應(yīng)用以簡(jiǎn)單地獲取和存儲(chǔ)風(fēng)扇狀態(tài)數(shù)據(jù),或立即使用 TensorFlow推理引擎、DeepViewRT 推理引擎或 Glow 推理引擎對(duì)獲取的數(shù)據(jù)運(yùn)行推理(清單 2)。
#define SENSOR_COLLECT_LOG_EXT 1 // Collect and log data externally
#define SENSOR_COLLECT_RUN_INFERENCE 2 // Collect data and run inference
/* Inference engine to be used */
#define SENSOR_COLLECT_INFENG_TENSORFLOW 1 // TensorFlow
#define SENSOR_COLLECT_INFENG_DEEPVIEWRT 2 // DeepViewRT
#define SENSOR_COLLECT_INFENG_GLOW 3 // Glow
/* Data format to be used to feed the model */
#define SENSOR_COLLECT_DATA_FORMAT_BLOCKS 1 // Blocks of samples
#define SENSOR_COLLECT_DATA_FORMAT_INTERLEAVED 2 // Interleaved samples
/* Parameters to be configured by the user: */
/* Configure the action to be performed */
#define SENSOR_COLLECT_ACTION SENSOR_COLLECT_RUN_INFERENCE
#if SENSOR_COLLECT_ACTION == SENSOR_COLLECT_LOG_EXT
/* If the SD card log is not enabled the sensor data will be streamed to the
terminal */
#define SENSOR_COLLECT_LOG_EXT_SDCARD 1 // Redirect the log to SD card,
otherwise print to console
清單 2:開發(fā)人員可以通過修改 sensor_collect.h 頭文件中包含的定義,輕松配置 NXP 的 ML 狀態(tài)監(jiān)測(cè)樣例應(yīng)用。(代碼來源:NXPSemiconductors)
該應(yīng)用的工作流程簡(jiǎn)單明了。main.c 中的主例程創(chuàng)建一個(gè)名為 MainTask 的任務(wù),后者是位于sensor_collect.c模塊中的一個(gè)例程。
void MainTask(void *pvParameters)
{
status_t status = kStatus_Success;
printf(“MainTask startedrn”);
#if !SENSOR_FEED_VALIDATION_DATA
status = SENSOR_Init();
if (status != kStatus_Success)
{
goto main_task_exit;
}
#endif
g_sensorCollectQueue = xQueueCreate(SENSOR_COLLECT_QUEUE_ITEMS,
sizeof(sensor_data_t));
if (NULL == g_sensorCollectQueue)
{
printf(“collect queue create failed!rn”);
status = kStatus_Fail;
goto main_task_exit;
}
#if SENSOR_COLLECT_ACTION == SENSOR_COLLECT_LOG_EXT
uint8_t captClassLabelIdx;
CAPT_Init(&captClassLabelIdx, &g_SensorCollectDuration_us,
&g_SensorCollectDuration_samples);
g_SensorCollectLabel = labels[captClassLabelIdx];
if (xTaskCreate(SENSOR_Collect_LogExt_Task, “SENSOR_Collect_LogExt_Task”,
4096, NULL, configMAX_PRIORITIES - 1, NULL) != pdPASS)
{
printf(“SENSOR_Collect_LogExt_Task creation failed!rn”);
status = kStatus_Fail;
goto main_task_exit;
}
#elif SENSOR_COLLECT_ACTION == SENSOR_COLLECT_RUN_INFERENCE
if (xTaskCreate(SENSOR_Collect_RunInf_Task, “SENSOR_Collect_RunInf_Task”,
4096, NULL, configMAX_PRIORITIES - 1, NULL) != pdPASS)
{
printf(“SENSOR_Collect_RunInf_Task creation failed!rn”);
status = kStatus_Fail;
goto main_task_exit;
}
#endif
清單 3:在 NXP 的 ML 狀態(tài)監(jiān)測(cè)樣例應(yīng)用中,MainTask 調(diào)用一個(gè)子任務(wù)來獲取數(shù)據(jù)或運(yùn)行推理。(代碼來源:NXPSemiconductors)
MainTask 先執(zhí)行各種初始化任務(wù),再啟動(dòng)兩個(gè)子任務(wù)中的一個(gè),具體哪一個(gè)取決于用戶在 sensor_collect.h 中的設(shè)置:
如果 SENSOR_COLLECT_ACTION 被設(shè)置為 SENSOR_COLLECT_LOG_EXT,則 MainTask 啟動(dòng)子任務(wù)
SENSOR_Collect_LogExt_Task(),收集數(shù)據(jù)并將其存儲(chǔ)在 SD 卡上(如已配置)
如果 SENSOR_COLLECT_ACTION 被設(shè)置為 SENSOR_COLLECT_RUN_INFERENCE,則 MainTask 啟動(dòng)子任務(wù)SENSOR_Collect_RunInf_Task(),針對(duì)所收集的數(shù)據(jù)運(yùn)行 Sensor_collect.h中定義的推理引擎(Glow、DeepViewRT 或 TensorFlow);如果定義了SENSOR_EVALUATE_MODEL,則還會(huì)顯示相應(yīng)的性能和分類預(yù)測(cè)
if SENSOR_COLLECT_ACTION == SENSOR_COLLECT_LOG_EXT
void SENSOR_Collect_LogExt_Task(void *pvParameters)
{
[code deleted for simplicity]
while (1)
{
[code deleted for simplicity]
bufSizeLog = snprintf(buf, bufSize, “%s,%ld,%d,%d,%d,%d,%d,%d,%drn”,
g_SensorCollectLabel, (uint32_t)(sensorData.ts_us/1000),
sensorData.rawDataSensor.accel[0], sensorData.rawDataSensor.accel[1],
sensorData.rawDataSensor.accel[2],
sensorData.rawDataSensor.mag[0], sensorData.rawDataSensor.mag[1],
sensorData.rawDataSensor.mag[2],
sensorData.temperature);
#if SENSOR_COLLECT_LOG_EXT_SDCARD
SDCARD_CaptureData(sensorData.ts_us, sensorData.sampleNum,
g_SensorCollectDuration_samples, buf, bufSizeLog);
#else
printf(“%.*s”, bufSizeLog, buf);
[code deleted for simplicity]
}
vTaskDelete(NULL);
}
#elif SENSOR_COLLECT_ACTION == SENSOR_COLLECT_RUN_INFERENCE
[code deleted for simplicity]
void SENSOR_Collect_RunInf_Task(void *pvParameters)
{
[code deleted for simplicity]
while (1)
{
[code deleted for simplicity]
/* Run Inference */
tinf_us = 0;
SNS_MODEL_RunInference((void*)g_clsfInputData, sizeof(g_clsfInputData),
(int8_t*)&predClass, &tinf_us, SENSOR_COLLECT_INFENG_VERBOSE_EN);
[code deleted for simplicity]
#if SENSOR_EVALUATE_MODEL
/* Evaluate performance */
validation.predCount++;
if (validation.classTarget == predClass)
{
validation.predCountOk++;
}
PRINTF(“rInference %d?%d | t %ld us | count: %d/%d/%d | %s ”,
validation.classTarget, predClass, tinf_us, validation.predCountOk,
validation.predCount, validation.predSize, labels[predClass]);
tinfTotal_us += tinf_us;
if (validation.predCount 》= validation.predSize)
{
printf(“rnPrediction Accuracy for class %s %.2f%%rn”,
labels[validation.classTarget],
(float)(validation.predCountOk * 100)/validation.predCount);
printf(“Average Inference Time %.1f (us)rn”,
(float)tinfTotal_us/validation.predCount);
tinfTotal_us = 0;
}
#endif
}
exit_task:
vTaskDelete(NULL);
}
#endif /* SENSOR_COLLECT_ACTION */
清單 4:NXP 的 ML 狀態(tài)監(jiān)測(cè)樣例應(yīng)用演示了獲取傳感器數(shù)據(jù)和對(duì)獲取的數(shù)據(jù)運(yùn)行所選推理引擎的基本設(shè)計(jì)模式。(代碼來源:NXPSemiconductors)
由于 NXP 的 ML狀態(tài)監(jiān)測(cè)應(yīng)用軟件包提供了完整的源代碼以及全套必需的驅(qū)動(dòng)程序和中間件,因此開發(fā)人員可以輕松擴(kuò)展該應(yīng)用以增加特性,或?qū)⑵渥鳛槠瘘c(diǎn)來開發(fā)自己的定制應(yīng)用。
總結(jié)
在物聯(lián)網(wǎng)和其他應(yīng)用中的智能產(chǎn)品的邊緣實(shí)施 ML 可以提供一系列強(qiáng)大的功能,但現(xiàn)有 ML 工具和方法大多是為企業(yè)級(jí)應(yīng)用而開發(fā)的,邊緣 ML開發(fā)人員使用起來往往很吃力。有了由跨界處理器和專門的模型開發(fā)軟件組成的 NXP 開發(fā)平臺(tái),無論 ML 專家還是幾乎沒有 ML經(jīng)驗(yàn)的開發(fā)人員都能更有效地創(chuàng)建專門設(shè)計(jì)的 ML 應(yīng)用,以滿足對(duì)高效邊緣性能的要求。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4717瀏覽量
100009 -
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2894文章
43313瀏覽量
366440 -
開源
+關(guān)注
關(guān)注
3文章
3126瀏覽量
42070 -
ML
+關(guān)注
關(guān)注
0文章
143瀏覽量
34437 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8306瀏覽量
131844
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何通過生產(chǎn)就緒平臺(tái)快速構(gòu)建和部署自適應(yīng)邊緣視覺應(yīng)用
快速高效地實(shí)施網(wǎng)絡(luò)邊緣機(jī)器學(xué)習(xí)
超低功耗FPGA解決方案助力機(jī)器學(xué)習(xí)
高性能的機(jī)器學(xué)習(xí)讓邊緣計(jì)算更給力-iMX8M Plus為邊緣計(jì)算賦能
微型機(jī)器學(xué)習(xí)
高性能的機(jī)器學(xué)習(xí)讓邊緣計(jì)算更給力-iMX8M Plus為邊緣計(jì)算賦能
高性能的機(jī)器學(xué)習(xí)讓邊緣計(jì)算更給力
為什么需要將機(jī)器學(xué)習(xí)遷移到邊緣設(shè)備
部署基于嵌入的機(jī)器學(xué)習(xí)模型
創(chuàng)建一個(gè)邊緣機(jī)器學(xué)習(xí)系統(tǒng)
機(jī)器學(xué)習(xí)部署的難點(diǎn)

邊緣機(jī)器學(xué)習(xí)成功的關(guān)鍵因素
什么是邊緣學(xué)習(xí)

TDK機(jī)器學(xué)習(xí)解決方案促進(jìn)邊緣人工智能前景大幅擴(kuò)展





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論