 如何快速設計和部署智能機器視覺系統
如何快速設計和部署智能機器視覺系統
作者:Jeff Shepard
許多應用對機器視覺的需求在不斷增長,包括安防、交通和城市攝像頭、零售分析、自動檢測、過程控制和視覺引導機器人技術。實現機器視覺是一個復雜的過程,需要整合不同的技術和子系統,包括高性能硬件和先進的人工智能/機器學習(AI/ML) 軟件。機器視覺從優化視頻采集技術和視覺 I/O以滿足應用需求開始,并延伸到多個圖像處理管道以實現高效連接。機器視覺最終取決于嵌入式視覺系統是否能夠通過高性能硬件執行基于視覺的實時分析。這些硬件如現場可編程門陣列(FPGA)、系統級模塊 (SOM)、系統級芯片 (SoC),甚至是運行所需的 AI/ML 圖像處理和識別軟件的系統級芯片上多處理器系統(MPSoC)。這可能是一個復雜、昂貴且耗時的過程,可能會頻繁導致成本超支、進度延誤。
與其從頭開始,設計者還不如采用一種經過精心策劃的高性能開發平臺,從而在加快上市時間、控制成本并降低開發風險的同時,支持應用實現高度靈活性和高性能。基于SOM 的開發平臺可以提供集成硬件和軟件環境,讓開發人員專注于應用定制并節省多達九個月的開發時間。除了開發環境外,同樣的 SOM架構還可用于商業和工業環境下的生產優化配置,以提高應用的可靠性和質量,進一步降低風險并加快上市時間。
本文首先回顧與開發高性能機器視覺系統有關的挑戰,然后介紹 AMD Xilinx 的 Kria KV260 視覺 AI入門套件提供的全面開發環境,最后以基于 Kira 26 平臺設計的即用型 SOM 為例進行介紹。該平臺用于插入帶有特定解決方案外設的載板。
該開發板從數據類型優化開始
深度學習算法的需求在不斷增加。不是每個應用都需要高精度計算。目前正在使用的較低精度數據類型如 INT8,或者使用自定義數據格式。基于 GPU的系統可能面臨這樣的挑戰,即試圖修改為高精度數據優化的架構,以有效地適應低精度數據格式。Kria K26 SOM 可重新配置,使其能夠支持從 FP32 到INT8 等多種數據類型。可重復配置也有助于實現較低總體能耗。例如,與 FP32 運行相比,針對 INT8 優化的運行所消耗的能量會少一個數量級(圖 1)。
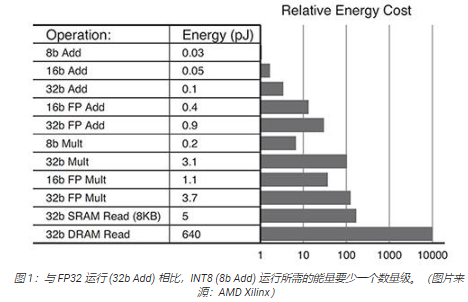
最優架構帶來最小功耗
根據典型的電源使用模式,基于多核 GPU 或 CPU 架構的設計可能功耗大。
內核部分能耗占 30%
內部存儲器 (L1, L2, L3) 能耗占 30%
外部存儲器(如 DDR)能耗為 40%
GPU 需要頻繁地訪問低效率 DDR 內存以支持可編程性,這是高帶寬計算需求的瓶頸。Kria K26 SOM 中使用的 Zynq MPSoC架構支持開發只需少量訪問或不訪問外部存儲器的應用。例如,在典型的汽車應用中,GPU 和各種模塊之間的通信需要多次訪問外部 DDR 存儲器來完成,而基于 ZynqMPSoC 的解決方案包含了一個旨在避免大多數 DDR 訪問的管道(圖 2)。
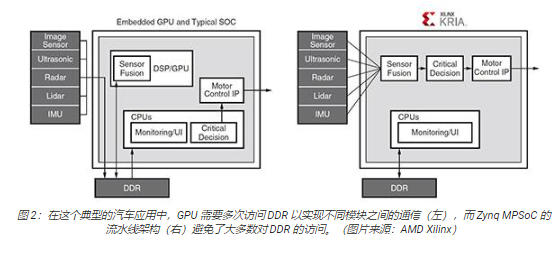
修剪的優勢
可以通過人工智能優化工具來增強 K26 SOM
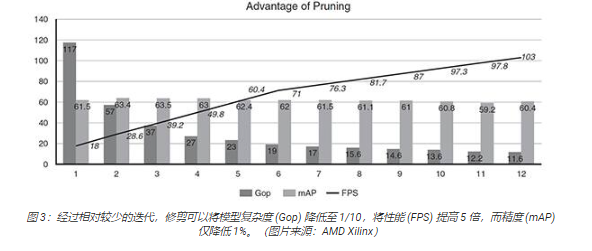
上的神經網絡性能,這種工具可以實現數據優化和修剪。神經網絡被過度參數化的情況非常常見,從而導致了高水平冗余。這種情況可通過數據修剪和模型壓縮來進行優化。使用Xilinx 的人工智能優化器可使模型復雜度降低至原來的 1/50,而對模型精度的影響卻微乎其微。例如,一個單次檢測器 (SSD) 加上一個 VGG 卷積神經網(CNN) 架構且具有 117 千兆運算 (Gops) 能力,使用人工智能優化器經過 11 次迭代修剪后得到了改進。優化前,該模型在 ZynqUltraScale+ MPSoC 上每秒運行 18 幀 (FPS)。經過 11 次迭代——該模型的第 12 次運行,其復雜性從 117 Gops 降低至11.6Gops(約前者的 1/10),性能從 18 FPS 提升至 103 FPS(前者的 5 倍),物體檢測準確性從 61.55 平均精度 (mAP)下降到 60.4 mAP(僅降低 1%)(圖 3)。
基于 Uncanny Vision 的視覺分析軟件,開發出用于汽車車牌檢測、識別的機器學習應用,也稱為汽車車牌識別 (ANPR) 應用。ANPR用于自動收費系統、高速公路監控、安全門和停車場入口以及其他應用。這種車牌識別應用包括一個基于人工智能的信息管道,對視頻進行解碼并預處理圖像,然后進行 ML檢測和 OCR 字符識別(圖 4)。
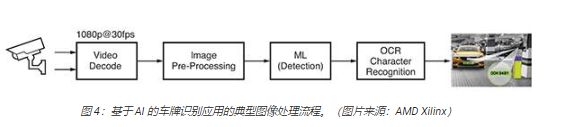
實現車牌識別需要一個或多個 H.264 或 H.265 編碼的實時流媒體協議 (RTSP)饋送,這些饋送經過解碼或未經過壓縮。解碼后的視頻幀經過縮放、裁剪、色彩空間轉換和標準化(預處理),然后發送至 ML 檢測算法。實現高性能車牌識別需要多階段 AI信息管道。在第一階段中,檢測并定位圖像中的車輛,創建關注區域 (ROI)。同時,其他算法優化圖像質量,供 OCR字符識別算法隨后使用,并以跨多幀的方式追蹤車輛運動。車輛 ROI 會被進一步裁剪,生成供 OCR 算法處理的號牌 ROI,以確定號牌中的字符。與其他基于 GPU或 CPU 的商業 SOM 相比,Uncanny Vision 的 ANPR 應用在 Kira KV260 SOM 上的運行速度快 2 到 3 倍,每個RTSP feed 的成本不到 100 美元。
智能視覺開發環境
對于交通和城市攝像頭、零售分析、安防、工業自動化和機器人等智能視覺應用的設計者來說,他們可以采用 Kria K26 SOM AI Starter開發環境。這種開發環境采用 Zynq? UltraScale+? MPSoC 架構建立,并有一個不斷增長的策劃應用軟件包庫(圖 5)。AI StarterSOM 包括一個四核 Arm Cortex-A53 處理器,超過 25 萬個邏輯單元以及一個 H.264/265 視頻編解碼器。SOM 還具有 4GB DDR4存儲器、245 個 IO 和 1.4 tera-ops人工智能計算,以支持創建高性能視覺人工智能應用,進而實現了與其他硬件方法相比,能以更低延遲、更低功耗提供超 3倍的性能。預構建應用可使初始設計在不到一小時內即可開始運行。

為了幫助快速啟動采用 Kria K26 SOM 的開發過程,AMD Xilinx 提供了 KV260 視覺 AI入門套件,其中包括電源適配器、以太網線、microSD 卡、USB 線、HDMI 線和攝像頭模塊(圖 6)。如果不需要整個入門套件,開發人員可以簡單地購買可選的電源適配器,以開始使用 Kira K26 SOM。

能夠加速開發的另一個原因是功能全面,包括豐富的 1.8 V、3.3 V 單端和差分 I/O、四個 6 Gb/s 收發器和四個 12.5 Gb/s收發器。有了這些功能,就能夠開發這樣的應用——即在這些應用中每個 SOM 具有更多的圖像傳感器且這些應用配備如 MIPI、LVDS、SLVS 和 SLVS-EC等各種傳感器接口。對于這些接口來說,其支持設備并不總限于應用特定型標準產品 (ASSP) 或 GPU。開發人員還可以通過嵌入式可編程邏輯實現DisplayPort、HDMI、PCIe、USB2.0/3.0 和用戶定義的標準。
最后,通過將 K26 SOM 廣泛的硬件能力、軟件環境與生產就緒型視覺應用相結合,簡化人工智能應用的開發并使其變得更加容易。這些視覺應用可以在不需要FPGA 硬件設計的情況下實現,并使軟件開發人員能夠快速集成定制的 AI 模型和應用代碼,甚至修改視覺管道。Xilinx 的 Vitis統一軟件開發平臺和庫支持常見的設計環境,如 TensorFlow、Pytorch 和 Café 框架以及多種編程語言,包括 C、C++、OpenCL? 和Python。還有一個嵌入式應用商店,用于使用來自 Xilinx 及其生態系統合作伙伴的 Kria SOM 的邊緣應用。Xilinx產品免費、開源,包括智能攝像頭跟蹤和人臉檢測、帶有智能視覺的自然語言處理功能等。
生產優化型 Kira 26 SOM
一旦開發過程完成,就可以提供 K26 SOM 的生產就緒型版本,該版本用于插入配有特定解決方案外設的載板,可以加速向制造過渡(圖 7)。基本的 K26SOM 是商業級器件,其溫度等級為 0℃ 至 +85℃ 結溫(通過內部溫度傳感器測量)。還可提供 工業級版本 K26 SOM,其額定工作溫度為 -40°C 至+100°C。
工業市場要求在惡劣的環境下具有更長的運行壽命。工業級 Kria SOM 在 100°C 結溫和 80% 相對濕度下可運行 10 年,并可承受高達 40 g的沖擊和 5 g 的均方根 (RMS) 振動。該版本還具有最短十年的生產可用性,以支持長的產品生命周期。

結語
諸如安全、交通和城市攝像頭、零售分析、自動檢測、過程控制和視覺引導的機器人等機器視覺應用設計者,可以采用 Kria K26 SOM AI啟動器,以加快上市時間,協助控制成本并降低開發風險。這種基于 SOM的開發平臺提供了一個軟硬件集成環境,讓開發者能專注于應用定制并節省多達九個月的開發時間。同樣的 SOM架構可用于商業和工業環境中的生產優化配置,進一步加快上市時間。工業版的最低生產可用性為 10 年,可支持很長的產品生命周期。
-
嵌入式
+關注
關注
5071文章
19026瀏覽量
303497 -
機器視覺
+關注
關注
161文章
4348瀏覽量
120133 -
AI
+關注
關注
87文章
30239瀏覽量
268473 -
SOM
+關注
關注
0文章
58瀏覽量
15694
發布評論請先 登錄
相關推薦
機器視覺系統在注塑行業的應用
機器視覺系統應用于標簽外觀視覺檢查!
機器視覺系統有何應用
機器視覺系統原理及基礎知識







 工商網監
工商網監
評論