") 大模型壓縮首篇綜述來啦
大模型壓縮首篇綜述來啦
近來,LLM以驚人的推理效果驚艷全世界,這得益于它巨大的參數(shù)量與計(jì)算任務(wù)。以GPT-175B模型為例,它擁有1750億參數(shù),至少需要320GB(以1024的倍數(shù)計(jì)算)的半精度(FP16)格式存儲(chǔ)空間。此外,為了有效管理操作,部署該模型進(jìn)行推理至少需要五個(gè)A100 GPU,每個(gè)GPU配備80GB內(nèi)存。巨大的存儲(chǔ)與計(jì)算代價(jià)讓有效的模型壓縮成為一個(gè)亟待解決的難題。
來自中國科學(xué)院和人民大學(xué)的研究者們深入探討了基于LLM的模型壓縮研究進(jìn)展并發(fā)表了該領(lǐng)域的首篇綜述《A Survey on Model Compression for Large Language Models》。

論文鏈接:https://arxiv.org/pdf/2308.07633.pdf
模型壓縮涉及將大型資源密集型模型轉(zhuǎn)化為適合在受限移動(dòng)設(shè)備上存儲(chǔ)的緊湊版本。此外,它還可以優(yōu)化模型以實(shí)現(xiàn)更快的執(zhí)行速度和最小的延遲,或在這些目標(biāo)之間取得平衡。
該綜述主要圍繞針對LLMs的模型壓縮技術(shù)的方法、指標(biāo)與基準(zhǔn)展開,并將相關(guān)研究內(nèi)容組成了一個(gè)新的分類,包括:
剪枝(Pruning)
知識(shí)蒸餾(Knowledge Distillation)
量化(Quantization)
低秩分解(Low-Rank Factorization)
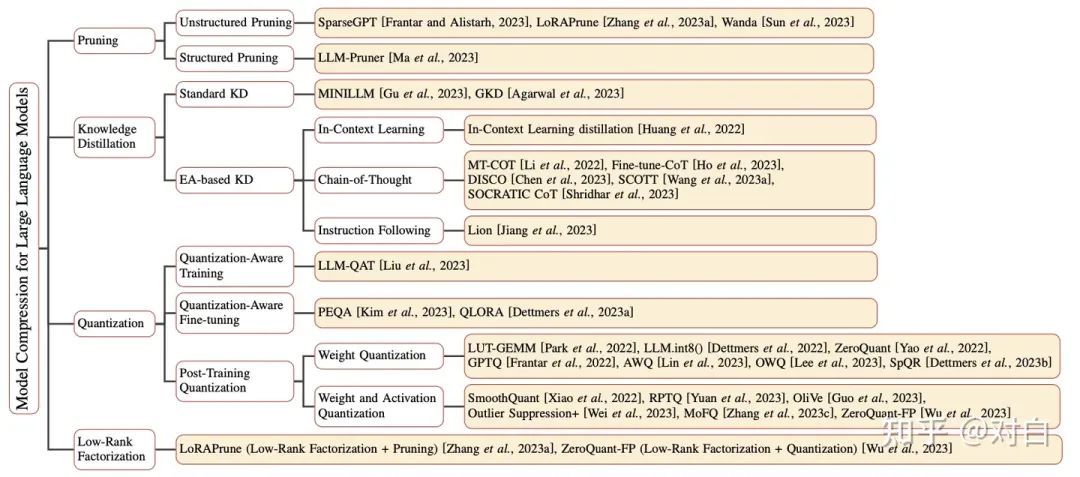
圖1:針對大型語言模型的模型壓縮方法分類。
一、方法剪枝(pruning)剪枝指移除模型中不必要或多余的組件,比如參數(shù),以使模型更加高效。通過對模型中貢獻(xiàn)有限的冗余參數(shù)進(jìn)行剪枝,在保證性能最低下降的同時(shí),可以減小存儲(chǔ)需求、提高內(nèi)存和計(jì)算效率。論文將剪枝分為兩種主要類型:非結(jié)構(gòu)化剪枝和結(jié)構(gòu)化剪枝。 非結(jié)構(gòu)化剪枝:指移除個(gè)別參數(shù),而不考慮整體網(wǎng)絡(luò)結(jié)構(gòu)。這種方法通過將低于閾值的參數(shù)置零的方式對個(gè)別權(quán)重或神經(jīng)元進(jìn)行處理。它會(huì)導(dǎo)致特定的參數(shù)被移除,模型出現(xiàn)不規(guī)則的稀疏結(jié)構(gòu)。并且這種不規(guī)則性需要專門的壓縮技術(shù)來存儲(chǔ)和計(jì)算被剪枝的模型。此外,非結(jié)構(gòu)化剪枝通常需要對LLM進(jìn)行大量的再訓(xùn)練以恢復(fù)準(zhǔn)確性,這對于LLM來說尤其昂貴。SparseGPT [Frantar and Alistarh, 2023] 引入了一種一次性剪枝策略,無需重新訓(xùn)練。該方法將剪枝視為一個(gè)廣泛的稀疏回歸問題,并使用近似稀疏回歸求解器來解決,實(shí)現(xiàn)了顯著的非結(jié)構(gòu)化稀疏性。LoRAPrune [Zhang等, 2023a] 將參數(shù)高效調(diào)整(PEFT)方法與剪枝相結(jié)合,以提高下游任務(wù)的性能。它引入了一種獨(dú)特的參數(shù)重要性標(biāo)準(zhǔn),使用了來自Low-Rank Adaption(LoRA)的值和梯度。Wanda [Sun等, 2023]提出了一種新的剪枝度量。它根據(jù)每個(gè)權(quán)重的大小以及相應(yīng)輸入激活的范數(shù)的乘積進(jìn)行評估,這個(gè)乘積是通過使用一個(gè)小型校準(zhǔn)數(shù)據(jù)集來近似計(jì)算的。這個(gè)度量用于線性層輸出內(nèi)的局部比較,使得可以從LLM中移除優(yōu)先級較低的權(quán)重。 結(jié)構(gòu)化剪枝:根據(jù)預(yù)定義規(guī)則移除連接或分層結(jié)構(gòu),同時(shí)保持整體網(wǎng)絡(luò)結(jié)構(gòu)。這種方法一次性地針對整組權(quán)重,優(yōu)勢在于降低模型復(fù)雜性和內(nèi)存使用,同時(shí)保持整體的LLM結(jié)構(gòu)完整。LLM-Pruner [Ma等, 2023] 采用了一種多功能的方法來壓縮LLMs,同時(shí)保護(hù)它們的多任務(wù)解決和語言生成能力。它引入了一個(gè)依賴檢測算法,以定位模型內(nèi)部的相互依賴結(jié)構(gòu)。它還實(shí)施了一種高效的重要性估計(jì)方法,考慮了一階信息和近似Hessian信息。
知識(shí)蒸餾(Knowledge Distillation,KD)
KD通過從一個(gè)復(fù)雜的模型(稱為教師模型)向一個(gè)簡化的模型(稱為學(xué)生模型)轉(zhuǎn)移知識(shí)來實(shí)現(xiàn)。在這一部分中,我們概述了使用LLM作為教師的蒸餾方法,并根據(jù)這些方法是否強(qiáng)調(diào)將LLM的涌現(xiàn)能力(EA)蒸餾到小型語言模型(SLM)中來進(jìn)行分類,包括:Standard KD和EA-based KD。
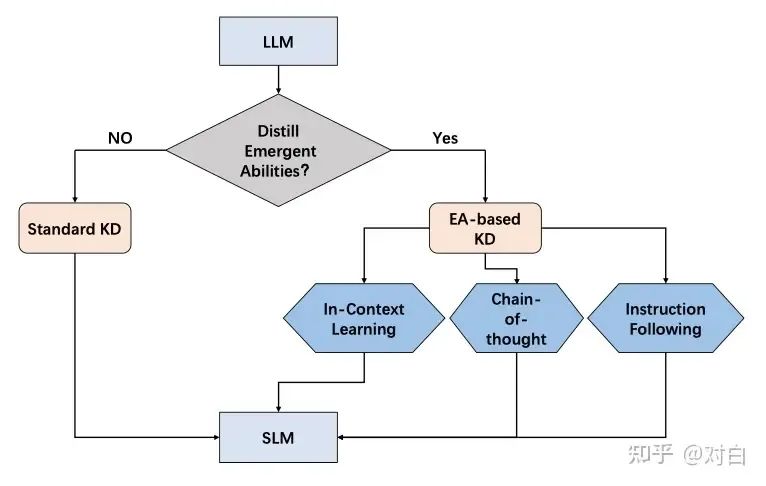
圖2:對語言模型知識(shí)蒸餾的簡要分類。 Standard KD旨在使學(xué)生模型學(xué)習(xí)LLM所擁有的常見知識(shí),如輸出分布和特征信息。這種方法類似于傳統(tǒng)的KD,但區(qū)別在于教師模型是LLM。
MINILLM [Gu等,2023] 深入研究了從白盒生成LLMs進(jìn)行蒸餾的方法,并選擇最小化反向KLD,防止了學(xué)生過高估計(jì)教師分布中的低概率區(qū)域,從而提高了生成樣本的質(zhì)量。 GKD [Agarwal等,2023] 探索了從自回歸模型進(jìn)行蒸餾的方法,其中白盒生成LLMs作為其中一個(gè)子集。它通過在訓(xùn)練期間從學(xué)生模型中采樣輸出序列來處理分布不匹配問題,并通過優(yōu)化替代的散度,如反向KL散度,來解決模型不足的問題。 相比之下,EA-based KD不僅僅是將LLM的常見知識(shí)轉(zhuǎn)移到學(xué)生模型中,還涵蓋了蒸餾它們獨(dú)特的涌現(xiàn)能力。具體來說,EA-based KD又分為了上下文學(xué)習(xí)(ICL)、思維鏈(CoT)和指令跟隨(IF)。 ICL采用了一個(gè)結(jié)構(gòu)化的自然語言提示,其中包含任務(wù)描述和可能的一些演示示例。通過這些任務(wù)示例,LLM可以在不需要顯式梯度更新的情況下掌握和執(zhí)行新任務(wù)。黃等人的工作引入了ICL蒸餾,將LLMs的上下文少樣本學(xué)習(xí)和語言建模能力轉(zhuǎn)移到SLMs中。它將上下文學(xué)習(xí)目標(biāo)與傳統(tǒng)的語言建模目標(biāo)相結(jié)合,并在兩種少樣本學(xué)習(xí)范式下探索了ICL蒸餾,即Meta-ICT 和 Multitask-ICT。 CoT與ICL相比,在提示中加入了中間推理步驟,這些步驟可以導(dǎo)致最終的輸出,而不是使用簡單的輸入-輸出對。MT-COT [Li等, 2022]旨在利用LLMs產(chǎn)生的解釋來增強(qiáng)較小的推理器的訓(xùn)練。它利用多任務(wù)學(xué)習(xí)框架,使較小的模型具備強(qiáng)大的推理能力以及生成解釋的能力。Fine-tune-CoT [Ho等, 2023]通過隨機(jī)采樣從LLMs生成多個(gè)推理解決方案。這種訓(xùn)練數(shù)據(jù)的增加有助于學(xué)生模型的學(xué)習(xí)過程。傅等人發(fā)現(xiàn)了語言模型的多維能力之間的權(quán)衡,并提出了微調(diào)的指令調(diào)整模型。他們從大型教師模型中提取CoT推理路徑以改進(jìn)分布外泛化。謝等人在多任務(wù)框架內(nèi)使用LLM原理作為額外的指導(dǎo),訓(xùn)練較小的模型。SOCRATIC CoT [Shridhar等, 2023]訓(xùn)練了兩個(gè)蒸餾模型:問題分解器和子問題解決器。分解器將原始問題分解為一系列子問題,而子問題解決器則處理解決這些子問題。DISCO [Chen等, 2023]引入了一種基于LLMs的完全自動(dòng)反事實(shí)知識(shí)蒸餾方法。它通過工程化的提示生成短語擾動(dòng),然后通過任務(wù)特定的教師模型將這些擾動(dòng)數(shù)據(jù)過濾,以提取高質(zhì)量的反事實(shí)數(shù)據(jù)。SCOTT [Wang等, 2023a]采用對比解碼,將每個(gè)原理與答案聯(lián)系起來。它鼓勵(lì)從教師那里提取相關(guān)的原理。此外,指導(dǎo)學(xué)生進(jìn)行反事實(shí)推理并基于導(dǎo)致不同答案的原理進(jìn)行預(yù)測。 IF僅依賴于任務(wù)描述而不依賴于少量示例。通過使用一系列以指令形式表達(dá)的任務(wù)進(jìn)行微調(diào),語言模型展現(xiàn)出能夠準(zhǔn)確執(zhí)行以前未見過的指令描述的任務(wù)的能力。Lion等, 2023]利用LLMs的適應(yīng)性來提升學(xué)生模型的性能。它促使LLM識(shí)別和生成“困難”指令,然后利用這些指令來增強(qiáng)學(xué)生模型的能力。
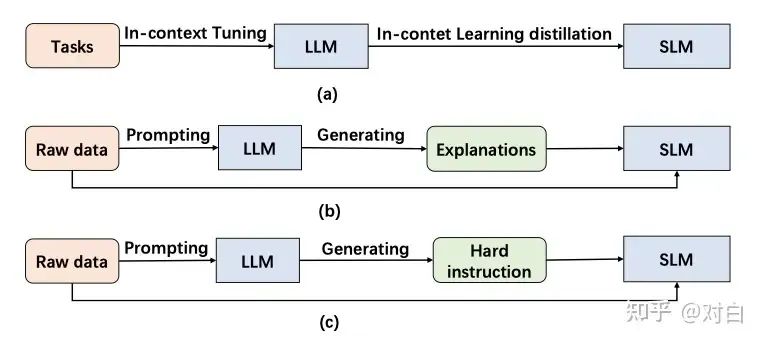
圖3:EA-based KD概述。a)上下文學(xué)習(xí)蒸餾,(b)思維鏈?zhǔn)秸麴s,(c)指令跟隨蒸餾。
量化(Quantization)
量化技術(shù)將傳統(tǒng)的表示方法中的浮點(diǎn)數(shù)轉(zhuǎn)換為整數(shù)或其他離散形式,以減輕深度學(xué)習(xí)模型的存儲(chǔ)和計(jì)算負(fù)擔(dān)。謹(jǐn)慎的量化技術(shù),可以在僅有輕微精度降低的情況下實(shí)現(xiàn)大規(guī)模的模型壓縮。依據(jù)應(yīng)用量化壓縮模型的階段,可以分為以下三種方法:量化感知訓(xùn)練(Quantization-Aware Training,QAT):在QAT中,量化目標(biāo)無縫地集成到模型的訓(xùn)練過程中。這種方法使LLM在訓(xùn)練過程中適應(yīng)低精度表示,增強(qiáng)其處理由量化引起的精度損失的能力。這種適應(yīng)旨在保持在量化過程之后的更高性能。LLM-QAT [Liu等,2023] 利用預(yù)訓(xùn)練模型生成的結(jié)果來實(shí)現(xiàn)無數(shù)據(jù)蒸餾。此外,LLM-QAT不僅量化權(quán)重和激活,還量化關(guān)鍵-值(KV)緩存。這個(gè)策略旨在增強(qiáng)吞吐量并支持更長的序列依賴。LLM-QAT能夠?qū)в辛炕瘷?quán)重和KV緩存的大型LLaMA模型蒸餾為僅有4位的模型。這一突破性的結(jié)果證明了制造準(zhǔn)確的4位量化LLM的可行性。量化感知微調(diào)(Quantization-Aware Fine-tuning,QAF)QAF涉及在微調(diào)過程中對LLM進(jìn)行量化。主要目標(biāo)是確保經(jīng)過微調(diào)的LLM在量化為較低位寬后仍保持性能。通過將量化意識(shí)整合到微調(diào)中,LLM旨在在模型壓縮和保持性能之間取得平衡。PEQA [Kim等,2023]和QLORA [Dettmers等,2023a]都屬于量化感知參數(shù)高效微調(diào)(PEFT)技術(shù)的范疇。這些技術(shù)側(cè)重于促進(jìn)模型壓縮和加速推理。PEQA采用了雙階段過程。在第一階段,每個(gè)全連接層的參數(shù)矩陣被量化為低位整數(shù)矩陣和標(biāo)量向量。在第二階段,對每個(gè)特定下游任務(wù)的標(biāo)量向量進(jìn)行微調(diào)。QLORA引入了新的數(shù)據(jù)類型、雙重量化和分頁優(yōu)化器等創(chuàng)新概念。這些想法旨在在不影響性能的情況下節(jié)省內(nèi)存。QLORA使得大型模型可以在單個(gè)GPU上進(jìn)行微調(diào),同時(shí)在Vicuna基準(zhǔn)測試上實(shí)現(xiàn)了最先進(jìn)的結(jié)果。訓(xùn)練后量化(Post-Training Quantization,PTQ)PTQ涉及在LLM的訓(xùn)練階段完成后對其參數(shù)進(jìn)行量化。PTQ的主要目標(biāo)是減少LLM的存儲(chǔ)和計(jì)算復(fù)雜性,而無需對LLM架構(gòu)進(jìn)行修改或進(jìn)行重新訓(xùn)練。PTQ的主要優(yōu)勢在于其簡單性和高效性。然而,值得注意的是,PTQ可能會(huì)在量化過程中引入一定程度的精度損失。在PTQ中,某些方法專注于僅對LLM的權(quán)重進(jìn)行量化,以提高效率并減少計(jì)算需求。LUT-GEMM [Park等,2022]通過僅對權(quán)重進(jìn)行量化以及使用BCQ格式在LLM中優(yōu)化矩陣乘法,通過提高計(jì)算效率來增強(qiáng)延遲降低和性能。LLM.int8() [Dettmers等,2022]對LLM transformers中的矩陣乘法采用8位量化,在推理過程中有效地減少GPU內(nèi)存使用量,同時(shí)保持性能精度。該方法采用矢量量化和混合精度分解來處理異常值,以實(shí)現(xiàn)高效的推理。ZeroQuant [Yao等,2022]將硬件友好的量化方案、逐層知識(shí)蒸餾和優(yōu)化的量化支持整合在一起,將Transformer-based模型的權(quán)重和激活精度減少到最小的INT8,并且對準(zhǔn)確性幾乎沒有影響。GPTQ [Frantar等,2022]提出了一種基于近似二階信息的新型分層量化技術(shù),使得每個(gè)權(quán)重的比特寬度減少到3或4位,與未壓縮版本相比,幾乎沒有準(zhǔn)確性損失。Dettmers和Zettlemoyer通過分析推理縮放定律,深入探討了LLM中模型大小和位精度之間在零樣本性能方面的權(quán)衡。他們在各種LLM家族之間進(jìn)行了廣泛的實(shí)驗(yàn),發(fā)現(xiàn)4位精度幾乎普遍是在總模型位數(shù)和零樣本準(zhǔn)確性之間實(shí)現(xiàn)正確平衡的最佳選擇。AWQ [Lin等,2023]發(fā)現(xiàn)對于LLM的性能,權(quán)重并不是同等重要的,僅保護(hù)1%的顯著權(quán)重可以大大減少量化誤差。在此基礎(chǔ)上,AWQ采用了激活感知方法,考慮與較大激活幅度對應(yīng)的權(quán)重通道的重要性,這在處理重要特征時(shí)起著關(guān)鍵作用。該方法采用逐通道縮放技術(shù)來確定最佳縮放因子,從而在量化所有權(quán)重的同時(shí)最小化量化誤差。OWQ [Lee等,2023]通過分析激活異常如何放大權(quán)重量化中的誤差,引入了混合精度量化方案,將更高的精度應(yīng)用于易受激活異常影響的權(quán)重。SpQR [Dettmers等,2023b]確定并隔離了異常權(quán)重,將其存儲(chǔ)在更高的精度中,并將所有其他權(quán)重壓縮為3-4位。此外,許多PTQ中的工作嘗試對LLM的權(quán)重和激活進(jìn)行量化。SmoothQuant [Xiao等,2022]解決了量化激活的挑戰(zhàn),這往往由于異常值的存在而變得更加復(fù)雜。SmoothQuant觀察到不同的標(biāo)記在它們的通道上展示出類似的變化,引入了逐通道縮放變換,有效地平滑了幅度,使得模型更易于量化。鑒于量化LLM中激活的復(fù)雜性,RPTQ [Yuan等,2023]揭示了不同通道之間不均勻范圍的挑戰(zhàn),以及異常值的存在所帶來的問題。為了解決這個(gè)問題,RPTQ將通道策略性地分組為簇進(jìn)行量化,有效地減輕了通道范圍的差異。此外,它將通道重排集成到層歸一化操作和線性層權(quán)重中,以最小化相關(guān)的開銷。OliVe [Guo等,2023]進(jìn)一步采用了outlier-victim對(OVP)量化,并在低硬件開銷和高性能增益的情況下局部處理異常值,因?yàn)樗l(fā)現(xiàn)異常值很重要,而其旁邊的正常值卻不重要。Outlier Suppression+ [Wei等,2023]通過確認(rèn)激活中的有害異常呈現(xiàn)出不對稱分布,主要集中在特定通道中,引入了一種新的策略,涉及通道級的平移和縮放操作,以糾正異常的不對稱呈現(xiàn),并減輕問題通道的影響,并定量分析了平移和縮放的最佳值,同時(shí)考慮了異常的不對稱性以及下一層權(quán)重引起的量化誤差。ZeroQuant-FP [Wu等,2023]探索了浮點(diǎn)(FP)量化的適用性,特別關(guān)注FP8和FP4格式。研究揭示,對于LLM,F(xiàn)P8激活在性能上持續(xù)優(yōu)于INT8,而在權(quán)重量化方面,F(xiàn)P4在性能上與INT4相比具有可比性,甚至更優(yōu)越。為了解決由權(quán)重和激活之間的差異引起的挑戰(zhàn),ZeroQuant-FP要求所有縮放因子為2的冪,并將縮放因子限制在單個(gè)計(jì)算組內(nèi)。值得注意的是,ZeroQuant-FP還集成了Low Rank Compensation (LoRC) 策略,以進(jìn)一步增強(qiáng)其量化方法的有效性。 此外,將相關(guān)工作根據(jù)LLM權(quán)重中的位數(shù)(精度)進(jìn)行分類,又可以分為8位量化和低位量化。

圖4:對語言模型(LLM)的量化方法概述。我們將它們分為8位量化和低位量化兩類,根據(jù)LLM權(quán)重中的位數(shù)(即精度)來進(jìn)行劃分。
低秩分解(Low-Rank Factorization)
低秩分解旨在通過將給定的權(quán)重矩陣分解成兩個(gè)或多個(gè)較小維度的矩陣,從而對其進(jìn)行近似。低秩分解背后的核心思想是找到一個(gè)大的權(quán)重矩陣W的分解,得到兩個(gè)矩陣U和V,使得W≈U V,其中U是一個(gè)m×k矩陣,V是一個(gè)k×n矩陣,其中k遠(yuǎn)小于m和n。U和V的乘積近似于原始的權(quán)重矩陣,從而大幅減少了參數(shù)數(shù)量和計(jì)算開銷。 在LLM研究的模型壓縮領(lǐng)域,研究人員通常將多種技術(shù)與低秩分解相結(jié)合,包括修剪、量化等,例如LoRAPrune [Zhang等,2023a]和ZeroQuant-FP [Wu等,2023],以實(shí)現(xiàn)更有效的壓縮同時(shí)保持性能。隨著這一領(lǐng)域的研究繼續(xù)進(jìn)行,可能會(huì)在將低秩分解應(yīng)用于壓縮LLM方面出現(xiàn)進(jìn)一步的發(fā)展,但仍需要持續(xù)的探索和實(shí)驗(yàn)來充分發(fā)揮其在LLM方面的潛力。
二、指標(biāo)和基準(zhǔn)指標(biāo)Number of Parameters:LLM中可學(xué)習(xí)權(quán)重或變量的總數(shù),LLM在訓(xùn)練期間需要優(yōu)化這些權(quán)重。 Model Size:指存儲(chǔ)整個(gè)LLM所需的磁盤空間或內(nèi)存占用,包括權(quán)重、偏置和其他必要組件。 Compression Ratio:未壓縮LLM的原始大小與壓縮LLM的大小之間的比率。 Inference time:衡量LLM在推理或預(yù)測期間處理輸入數(shù)據(jù)并生成響應(yīng)所花費(fèi)的時(shí)間。 Floating point operations (FLOPs):衡量LLM在處理輸入數(shù)據(jù)時(shí)執(zhí)行的涉及浮點(diǎn)數(shù)(通常是32位或16位)的算術(shù)操作數(shù)量。
基準(zhǔn)
常見的NLP基準(zhǔn):GLUE、LAMBADA、LAMA、SQuAD;
HULK:全面評估了預(yù)訓(xùn)練語言模型(PLMs)的能效;
ELUE:整合了六個(gè)NLP數(shù)據(jù)集,涵蓋了情感分析、自然語言推斷、相似性和改寫任務(wù)。
三、挑戰(zhàn)和未來方向
專用的基準(zhǔn)。首先,模型壓縮的評估缺乏普遍接受的標(biāo)準(zhǔn)設(shè)置。其次,可能不是在移動(dòng)設(shè)備上典型任務(wù)的最佳代表。并且,為預(yù)訓(xùn)練模型設(shè)計(jì)的基準(zhǔn)也可能不適用在移動(dòng)設(shè)備上的常見任務(wù)。
性能與大小的權(quán)衡。當(dāng)前的工作仍缺乏對這種權(quán)衡理論和實(shí)證的洞見。
動(dòng)態(tài)LLM壓縮。目前壓縮方法仍然依賴于手動(dòng)設(shè)計(jì)來確定LLMs的壓縮大小和結(jié)構(gòu),這種手動(dòng)嘗試會(huì)在實(shí)際工作帶來阻礙。
可解釋性。可解釋性壓縮方法的整合應(yīng)成為LLM壓縮應(yīng)用進(jìn)展的重要必要條件。采用可解釋性壓縮不僅針對解釋性問題,還簡化了壓縮模型的評估過程。反過來也增強(qiáng)了模型在生產(chǎn)階段的可靠性和可預(yù)測性。
-
模型
+關(guān)注
關(guān)注
1文章
3172瀏覽量
48711 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24641 -
nlp
+關(guān)注
關(guān)注
1文章
487瀏覽量
22011 -
大模型
+關(guān)注
關(guān)注
2文章
2326瀏覽量
2481
原文標(biāo)題:大模型壓縮首篇綜述來啦~~
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
模型壓縮技術(shù),加速AI大模型在終端側(cè)的應(yīng)用
【大語言模型:原理與工程實(shí)踐】核心技術(shù)綜述
有關(guān)負(fù)荷預(yù)測的綜述總結(jié)
啃論文俱樂部 | 壓縮算法團(tuán)隊(duì):我們是如何開展對壓縮算法的學(xué)習(xí)
壓縮模型會(huì)加速推理嗎?
深度網(wǎng)絡(luò)模型壓縮綜述
基于無線傳感器網(wǎng)絡(luò)的簇首提取壓縮算法
深度學(xué)習(xí)模型壓縮與加速綜述

深度神經(jīng)網(wǎng)絡(luò)模型的壓縮和優(yōu)化綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論