 超星未來NE100開箱體驗,15分鐘部署目標檢測模型
超星未來NE100開箱體驗,15分鐘部署目標檢測模型
「NE100」是超星未來基于自研計算芯片「驚蟄R1」和全流程開發工具鏈「魯班」打造的智能計算平臺開發套件,包括完備的推理環境。其中魯班工具鏈以 docker 形式提供,完整包括剪枝、量化、編譯工具以及相應實例。NE100 配套完整,開箱即用,無需繁瑣的安裝過程。
下面以目標檢測模型 YOLOv5 為例,展示部署過程。
注:開發環境為Linux 系統的 PC 或服務器,神經網絡需要導出為 ONNX 格式文件。
可通過標準命令加載工具鏈 docker 文件:
gunzip -c nova_development_kit.tar.gz | sudo docker load
參考用戶手冊中示例腳本啟動容器,進入開發環境。
基于原始模型導出 ONNX 文件時,請確保網絡已經處于推理模式,并且計算圖的輸入節點為首個 CONV 算子的輸入(格式[1,C,H,W]),輸出節點為最后一個(組)CONV 算子的輸出,詳細信息請參考用戶手冊。
#1模型量化與編譯
1個API,5行代碼,輕松完成
量化工具以 ONNX 文件和部分圖片為輸入,將神經網絡從 FP32 量化為 INT8 精度,目前支持 PTQ 與 QAT 功能。僅需在代碼中將量化和編譯工具導入并通過 API 調用,即可對 ONNX 模型完成量化和編譯,分別只需要1個 API 和5行代碼。詳細的 API 說明請參考用戶手冊。
1. 導入量化工具
from nquantizer import run_quantizer
2. 調用量化工具
quant_model = run_quantizer(
onnx_model,
dataloader=val_loader,
num_batches=200,
output_dir=work_dir + "/quantizer_output",
input_vars=input_vars,
3. 導入編譯工具
from ncompiler import run_compiler
4. 調用編譯工具
run_compiler(
input_dir=work_dir + "/quantizer_output",
output_dir=work_dir + "/compiler_output",
enable_simulator=True,
enable_profiler=True,
)
編譯后 compiler_output 目錄中的 npu.param(模型結構描述文件)和 npu.bin(模型權重文件)是 NE100 部署時所需要的文件。

#2模型部署
接口簡潔,功能豐富,快速調用NPU
為了實現 驚蟄R1 芯片多核 NPU 的簡單高效推理與應用開發,超星未來基于 NCNN 推理框架增量開發運行時,并提供高性能加速庫,滿足異構推理的端到端優化需求。
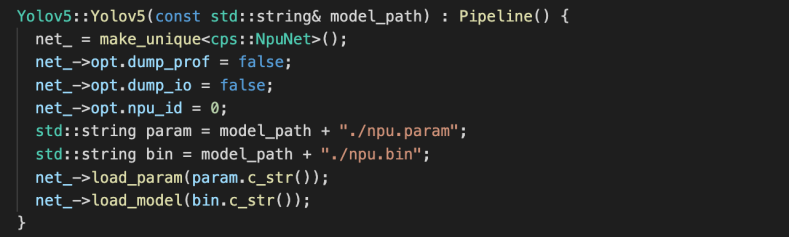
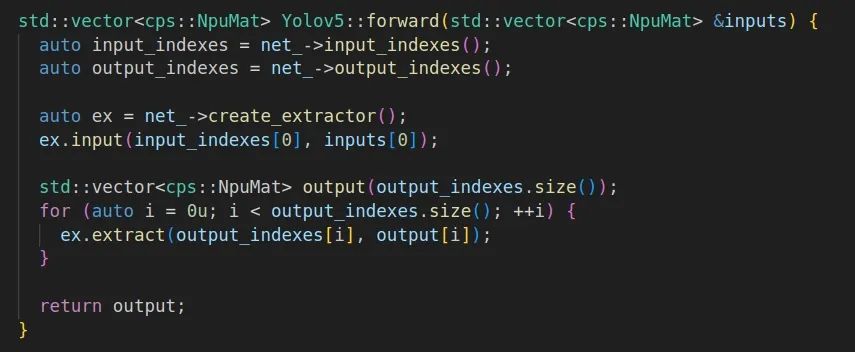
運行時特別設計了 npumat, npunet 和 npuextractor 等組件,功能如下:
npumat:提供NPU使用的數據排布格式HWC,提高數據存儲讀取性能
npunet:提供模型不變信息的基礎數據結構,支持核心綁定、優先級調度、數據導出、性能監測等功能
npuextractor:提供NPU推理所需的set_input, get_output, get_time、extract等基本功能
YOLOv5 推理中前后處理部分與主流平臺上的代碼一致,應用遷移時僅需更換 NPU 的推理代碼,包括:
1. 初始化幀數據結構
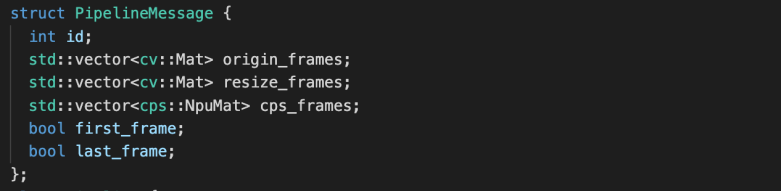
2. 加載網絡結構描述文件與網絡權重文件,并且配置核心綁定、數據導出及性能監測等功能
3. 基于加載的模型文件和前處理后的幀數據進行推理,提取結果用于后處理
#3模型推理
架構高效,能耗出色,助力AI應用落地
推理代碼經過編譯后運行,即可得到如下推理結果:
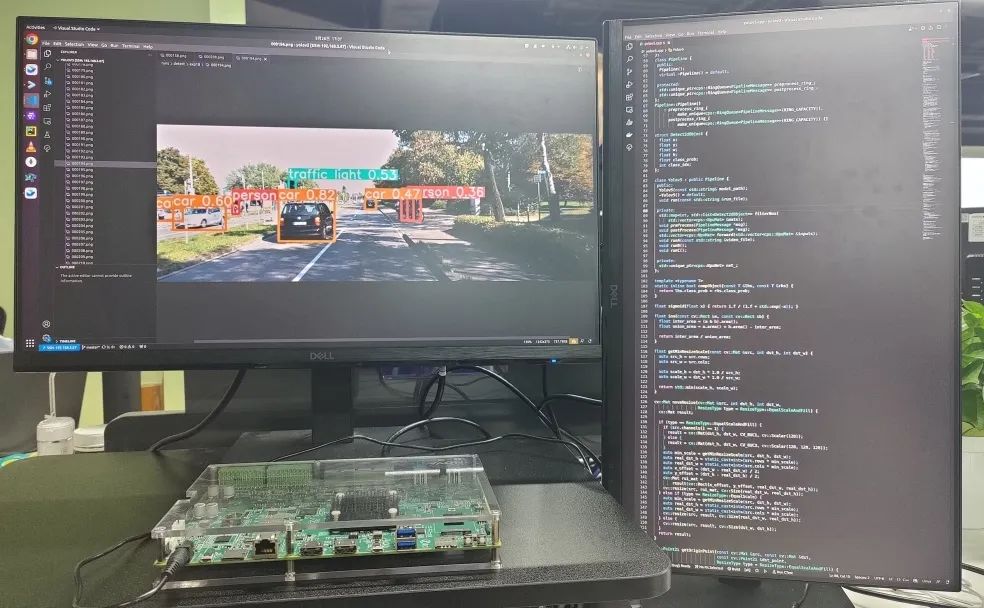
得益于超星未來自研平湖架構的高效設計,YOLOv5 等主流網絡的算力利用率均超過 70%,同時芯片整體功耗可控制在 8W 左右,有效支持各類邊緣端 AI 應用部署。
-
神經網絡
+關注
關注
42文章
4764瀏覽量
100541 -
模型
+關注
關注
1文章
3173瀏覽量
48715 -
目標檢測
+關注
關注
0文章
205瀏覽量
15590
原文標題:超星未來 NE100 開箱體驗,15分鐘部署目標檢測模型
文章出處:【微信號:NOVAUTO,微信公眾號:超星未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【小e物聯網試用體驗】+ 超清開箱體驗
【VEML6040環境顏色檢測試用體驗】一、開箱體驗,驚喜有余
15分鐘充滿快充移動電源---未來的潛力有多大?
在Arm虛擬硬件上部署PP-PicoDet模型
在Arm虛擬硬件上部署PP-PicoDet模型的設計方案
高通公布新型快速充電技術,15分鐘內將4500mAh電池充滿100%
如何在移動設備上訓練和部署自定義目標檢測模型
如何使用TensorRT框架部署ONNX模型
AI愛克斯開發板上使用OpenVINO加速YOLOv8目標檢測模型






 工商網監
工商網監
評論