") 未來人機(jī)交互趨勢:多模態(tài)大模型
未來人機(jī)交互趨勢:多模態(tài)大模型
目前,市面上的交互產(chǎn)品是以單模交互為主,尤其是語音交互。
語音類產(chǎn)品的形態(tài)主要為語音助手。語音可以帶來比按鍵更便捷的體驗,尤其是,在行車過程中可以避免分散駕駛員的精力。
長城汽車多模態(tài)技術(shù)負(fù)責(zé)人林俊告訴筆者:
在交互類功能中,我們現(xiàn)在真正上車的主要是語音交互。例如,主駕可以說“幫我打開座椅加熱”,副駕說“我也要”,那么,車機(jī)就會同時打開主駕和副駕的座椅加熱功能。
在上述交互中,副駕通過說“我也要”來“復(fù)制”駕說的“打開座椅加熱”指令,從而實現(xiàn)和主駕相同的功能。假如主駕通過按鍵來實現(xiàn)座椅加熱功能,那么副駕就無法“復(fù)制”主駕的指令。
視覺類產(chǎn)品包括了DMS、HUD等。
隨著汽車智能化趨勢的深入,座艙的智能化相關(guān)功能越來越多,對交互便捷性的要求也越來越高,然而,現(xiàn)在的汽車離“便捷的人機(jī)交互空間”還有很大距離。
一部分的原因在于,各個模態(tài)的技術(shù)仍然存在一些局限,在某些場景下無法給用戶提供良好的體驗。
還有一部分的原因在于,車內(nèi)雖然有手勢識別、眼動追蹤、語音識別等各種功能,但用戶在實際使用時,各個模塊往往是獨立發(fā)揮作用,各個傳感器接收到的信息很難被統(tǒng)一整合起來,那么整體體驗就總有些“差強(qiáng)人意”。
具體來說,問題主要體現(xiàn)在以下5個方面——
01 語音識別在噪聲環(huán)境下無法滿足精度要求
雖然語音理解并不難,但在噪聲環(huán)境下,系統(tǒng)很難把噪音和要識別的語音區(qū)分開,語音識別的結(jié)果會變得不夠準(zhǔn)確。
02 語音助手很難進(jìn)行多輪對話
目前的語音識別技術(shù)還不夠成熟,用戶在和語音助手對話的時候,尤其是在多輪對話的場景中,由于缺乏對上下文的聯(lián)合解讀,語音助手會顯得不那么“聰明”。
03 語音助手和車機(jī)其他應(yīng)用尚未打通
現(xiàn)在的語音模型和車機(jī)里的app沒有“打通”,語音助手無從得知車機(jī)里安裝了哪些app,也不知道車機(jī)屏幕上展示了什么內(nèi)容,在這種情況下,語音助手就陷入一種“孤立”的狀態(tài)。
天貓精靈在家居場景里的表現(xiàn)比在車端好,是因為天貓精靈與需要互動的家居產(chǎn)品,例如窗簾、燈等的交互鏈路很短且是確定的,那么當(dāng)向天貓精靈發(fā)出“打開燈光”、“打開窗簾”等指令時,天貓精靈執(zhí)行起來就會比較順暢。
但是在車端,導(dǎo)航的地點和之間的LBS的信息,是不打通的,語音助手無法判斷某個時刻應(yīng)該在艙內(nèi)現(xiàn)實地圖導(dǎo)航的信息還是其他的應(yīng)用,抑或時空調(diào)、座椅等的設(shè)置信息。那么在車端環(huán)境里,用戶在要和語音助手交互時,就會感覺語音助手比較“弱智”。
04 視覺在某些情形下無法滿足精度要求
簡單地做一個人臉識別系統(tǒng)并不難,但假如希望把精度做到很高就會比較困難。假如把人臉的角度偏轉(zhuǎn)幾十度,系統(tǒng)有時就會識別錯誤。
有業(yè)內(nèi)人士吐槽道:“現(xiàn)在車上DMS的提醒有時讓人‘很懵’,我頭真的偏向一側(cè)的時候它不會提醒,但正常行駛的時候它反而會提醒。”
前段時間,一位駕駛員由于眼睛較小而被車上的DMS系統(tǒng)識別為“在睡覺”,引起了業(yè)內(nèi)的關(guān)注。
05 視覺尚難以準(zhǔn)確判斷用戶行為
當(dāng)前的視覺識別尚難以準(zhǔn)確判斷用戶行為,很難準(zhǔn)確地判斷出用戶是否在打電話,是否在抽煙。
一 通過多模融合技術(shù)來解決單模態(tài)交互存在的痛點
1. 多模融合的定義
為了提升用戶的體驗,除了優(yōu)化系統(tǒng)對每個模態(tài)的信息的識別能力之外,還可以將不同模態(tài)的信息整合起來,也就是采用多模融合技術(shù),來為用戶提供更好的體驗。
2. 多模融合技術(shù)的應(yīng)用
如何用多模態(tài)技術(shù)提升用戶體驗?zāi)兀?/p>
根據(jù)筆者與行業(yè)內(nèi)專家交流得到的信息,目前在車端落地的多模融合技術(shù)主要應(yīng)用于兩個方面。
2.1限定語音交互的區(qū)域和范圍
第一類是通過熱區(qū)(熱點區(qū)域)來限定語音交互的區(qū)域和范圍。
目前的座艙大致分為十個左右的熱區(qū),包括了中控、儀表、左右車窗、后視鏡、前擋風(fēng)玻璃、HUD等。劃分好熱區(qū)后,工程師方便把語音指令定位到比較確定的區(qū)域(語音一般是全艙的)。
也就是說,在用戶發(fā)出一個語音指令后,后臺可以比較精確地知道需要調(diào)用哪些區(qū)域的傳感器或者執(zhí)行器來完成指令。例如,駕駛員說“打開車窗”,系統(tǒng)會自動打開左邊的窗戶,而無需駕駛員強(qiáng)調(diào)“打開左車窗”。
2.2讓信號輸入更精準(zhǔn)
第二類是語音疊加視覺等其他模態(tài)的信息,來讓信號輸入更加精準(zhǔn)。
例如,可以用視覺感知(包括唇語識別、唇動識別、手勢識別等)作為語音的補(bǔ)充,在車內(nèi)環(huán)境比較嘈雜時,系統(tǒng)也可以較好地識別用戶的意圖。
當(dāng)車窗處于打開狀態(tài)或者其他情形導(dǎo)致車內(nèi)噪音較大時,語音交互的識別精度會非常低,相應(yīng)地,召回率(即用戶講話時,語音助手應(yīng)答的概率)也會變得很低。
傳統(tǒng)的方式主要是采取過濾的方式來應(yīng)對嘈雜的環(huán)境。
現(xiàn)在可以采用視覺信息輔助判斷,用攝像頭捕捉車內(nèi)用戶的唇語信息,系統(tǒng)就能在嘈雜環(huán)境中更準(zhǔn)確地判斷用戶具體在講什么。
此外,在車?yán)镉卸嗳送瑫r講話的時候,例如,主駕和副駕都在講話,結(jié)合主駕和副駕的唇語信息,系統(tǒng)可以將主駕和副駕的語音分離,從而判斷他們分別在講什么。
商湯絕影智能車艙產(chǎn)品高級總監(jiān)李軻告訴筆者:
在開窗駕駛汽車的時候,語音助手的召回率可能會受到較大影響比較低。那么,假如僅借助語音這個單一的態(tài),我們做人機(jī)交互的時候會面臨很大的困難。商湯的視覺模型可以對座艙內(nèi)的視覺信息做進(jìn)一步的分析,包括駕駛員的眼部動作、面部朝向、唇動、唇語等相關(guān)信息。我們把這些視覺信息和語音信息做一個融合,在背景噪音較大的情況下,可以將召回率大幅提高,如此以來,用戶體驗可以得到極大的提升。
二 目前落地的多模態(tài)融合技術(shù)
目前已經(jīng)在量產(chǎn)車上落地的多模態(tài)融合技術(shù)主要包括結(jié)果層面的融合(也叫后融合)、特征層面的融合(也叫前融合)。
1. 后融合
1.1后融合的定義
結(jié)果層面的融合,是主機(jī)廠拿到不同模態(tài)的信息處理后的結(jié)果之后,包括視覺算法的結(jié)果、語音算法的結(jié)果等,在邏輯層對這些結(jié)果做一些結(jié)合。
根據(jù)筆者與業(yè)界專家交流得到的信息,目前,各個模塊通常是由不同供應(yīng)商分別研發(fā),然后把識別后的結(jié)果給到主機(jī)廠,例如,主機(jī)廠可能把語音識別功能委托給擅長語音識別的供應(yīng)商,把圖像識別委托給擅長計算機(jī)視覺的供應(yīng)商。
通常來說,一家供應(yīng)商僅擅長一個方向,很少有供應(yīng)商既擅長語音識別又擅長計算機(jī)視覺。主機(jī)廠通常是從不同供應(yīng)商處拿到不同模塊處理后的結(jié)果而非特征,因此,目前市面上的多模態(tài)融合方案一般是采取后融合的方式。
一位行業(yè)專家告訴筆者:
假如主機(jī)廠能夠把供應(yīng)商處理后的各個傳感器回傳的信息處理好,也就是做好后融合,其實已經(jīng)很大進(jìn)步了。但很遺憾的是現(xiàn)在即使是后融合也沒做好。有的主機(jī)廠會擔(dān)心即使做好了后融合,用戶也感受不到與不做的區(qū)別,用戶感受不到明顯效果的話汽車銷量就很難被帶動,那么這個投入產(chǎn)出比就不劃算。
在已量產(chǎn)的車型上,后融合現(xiàn)在是行業(yè)內(nèi)多模融合的主流技術(shù)。但是,它卻被詬病“天花板不夠高”,這是因為什么呢?
1.2后融合的局限
1.2.1 結(jié)果很依賴于單車調(diào)優(yōu)
根據(jù)筆者了解到的信息,后融合非常依賴于單車調(diào)優(yōu)。同一套語音識別算法可能可以用在不同型號的手機(jī)上,而無需根據(jù)型號分別調(diào)優(yōu)。但是在車端,車的空間大小、造型設(shè)計等可能都會影響到語音算法的效果,因此,算法需要針對不同的車型分別調(diào)優(yōu),工作量也會相應(yīng)增加。視覺算法也是如此,也需要針對不同的車型來調(diào)優(yōu)。
1.2.2 對不同模態(tài)識別結(jié)果的一致性要求較高
后融合想要實現(xiàn)好的效果,每個單模識別都具備一定的精度。
有業(yè)內(nèi)專家告訴筆者:
首先要保證單模是非常精準(zhǔn)的,只有單模的精度達(dá)標(biāo),帶給用戶的體驗好,我們才能談多模。
在實踐中,主做視覺算法的公司和主做語音算法的公司在做方案的時候各自有側(cè)重點,不一定能完全根據(jù)主機(jī)廠的意愿來優(yōu)化。假如提供視覺算法的供應(yīng)商把結(jié)果優(yōu)化地很好,但是提供語音算法的供應(yīng)商優(yōu)化得不夠好,整體效果也會不好,反之亦然。
有業(yè)內(nèi)專家告訴筆者:
最終能夠做出用戶體驗非常好的產(chǎn)品還是需要全棧能力都要有。而且最好是能夠通過端上來解決。因為端相對云來說延時很低,對信息的處理效率高。
然而,要具備全棧能力,需要很大的投入,假如公司體量不夠大,就無力投入太多資源。并且,按照目前的市場情況,這樣的投入可能無法迅速見效,那么對于公司來說,就是極不合算的做法。
1.2.3 容易丟失信息
后融合會丟失信息,很難把不同模態(tài)的信息做有效的疊加,因為它在處理過程當(dāng)中就已經(jīng)丟失了很多原始信息。
2. 前融合
2.1前融合的定義
特征層面的融合,是指供應(yīng)商將不同模態(tài)信息的特征提取出來,然后用同一個模型訓(xùn)練,交給主機(jī)廠的是已經(jīng)合成了不同模態(tài)信息的結(jié)果。
相對于后融合,前融合由于融合階段更早,天然地存在一些優(yōu)勢。
一方面,由于是用一個模型訓(xùn)練,前融合能規(guī)避掉不同供應(yīng)商的能力不一致或者優(yōu)化意愿不一致的問題。
另一方面,由于在訓(xùn)練的時候包含了不同模態(tài)的特征信息,信息利用程度相對后融合更高。
那么在性能上,前融合方式一般比后融合更好,因為采用一個模型來處理語音和視覺信息,融合的程度更深,最終實現(xiàn)的效果更好。
2.2 前融合的局限
科大訊飛汽車智能交互總監(jiān)章偉告訴筆者:
在多模的信號關(guān)聯(lián)度很高,輸出精度要求很高,以及信號同步要求很高的情況下,電子電氣架構(gòu)需要做一些調(diào)整來保障信號的同步。
2.2.2 芯片適配、算法優(yōu)化的工作量大
另外,產(chǎn)品需要能夠在不同的芯片平臺上運行,包括高通、英偉達(dá)、ti 等,對這些不同的芯片做適配需要很大的工作量。
據(jù)悉,商湯絕影有一個大幾十人的團(tuán)隊專門去做不同架構(gòu)芯片和指定企業(yè)的適配,同時降低資源占用。為什么要降低資源占用呢,因為車企現(xiàn)在發(fā)展越來越多的功能,除了DMS等視覺識別系統(tǒng)之外還有音樂、地圖等,而且儀表的功能會越來越豐富,那么車企就會希望每一家供應(yīng)商的產(chǎn)品的資源占用率要盡可能低。
也就是說,我們不僅要適配各種各樣的芯片,還要不停地降低資源占用,以前處理不同模態(tài)信息的模型可能占芯片算力的10%,現(xiàn)在需要降低到5%。
降低資源占用主要是從兩方面入手,一方面是優(yōu)化模型來降低模型對芯片算力及存儲空間等資源的占用;另一方面就是針對芯片底層的指令集進(jìn)行優(yōu)化,去降低芯片的資源占用。
2.2.3 供應(yīng)商不一定有全棧能力
還有一點是前融合需要一家供應(yīng)商,同時把語音和視覺都做得比較好,這存在一定難度。而且前融合也不是在所有情形下都比后融合效果好,另外還有一些場景不需要融合。
2.2.4 主機(jī)廠的采購可能不適應(yīng)
一位業(yè)內(nèi)專家提到:
由于習(xí)慣原因,一些主機(jī)廠的采購會習(xí)慣性地分開采購語音算法和視覺算法。假如突然變成需要采購融合后的結(jié)果,采購不一定能很快認(rèn)可。
就筆者了解到的情況來看,大家可能會在前融合這個方向投入一些資源來研發(fā),但由于目前車上的架構(gòu)做后融合更方便,因此真正落地前融合的廠商不多。
地平線由于具備視覺、語音等全棧能力,是目前少有的有量產(chǎn)落地前融合方案的廠商。
然而,不管是前融合還是后融合,本質(zhì)上都是基于兩套邏輯的組合。
這樣組合會帶來兩個缺點,一個是組合的邏輯是人為定義出來的,很難被普適得認(rèn)可。
在客戶認(rèn)可組合的邏輯時,這樣做不會有什么問題。但如果客戶不認(rèn)可組合的邏輯,可能供應(yīng)商就需要重寫組合邏輯。
例如,假如供應(yīng)商給a廠商提供了一套前處理或者后處理的方案,這個方案到了b 廠商可能會被否決,因為廠商可能要追求產(chǎn)品的差異化,那么在處理不同模態(tài)信息時可能會有側(cè)重,這樣很難將一套方案復(fù)制到很多車型上,需要的工作量很大。
第二個問題是基于規(guī)則的組合很難避免生硬,即使花費很多精力,可能也只是讓組合變得更完善了一些。
中科創(chuàng)達(dá)座艙產(chǎn)品線總經(jīng)理趙銳告訴筆者:
我們不會走前融合或者后融合的路線的東西。我認(rèn)為過渡態(tài)的內(nèi)容,雖然是一個賣點,但我們是做產(chǎn)品的,要看終局。
第三個問題是基于規(guī)則的組合會對交互場景有限制,降低用戶體驗。
每一次大型的智能終端的變革,都伴隨著人機(jī)交互方式的升級。早期PC主要依賴鼠標(biāo)加鍵盤,智能手機(jī)依靠觸屏。觸碰這一交互方式不適合用于車端,到了智能汽車時代,駕駛員的手和眼都被占用了,在這種情況之下,就會以這種自然交互為核心。所謂自然交互,最簡單的就是語音交互,然后輔以視覺,例如手勢等。
在這樣的交互方式中,假如要通過邏輯來限定一些場景和一些具體的交互措施,會給用戶負(fù)面的體驗。
多模態(tài)應(yīng)該是一種能力,而不應(yīng)該是一些設(shè)定好的一個規(guī)則。
用戶在使用過程中會識別到更多更有趣的東西,假如用戶只能在有限的幾個場景里體驗多模態(tài)技術(shù),在其他場景中無法使用,這會給用戶帶來一種很割裂的感覺,整體的體驗并不好。
假如不希望采用基于規(guī)則的組合,可以如何整合不同模態(tài)的信息呢?
答案是采用多模態(tài)大模型做模型層融合。
三 模型層融合
1.模型層融合的定義
模型層面的融合,是指訓(xùn)練模型的數(shù)據(jù),既可以有語音數(shù)據(jù)的,也可以有圖片數(shù)據(jù)的,以及其他各種各樣的模態(tài)的數(shù)據(jù)。相當(dāng)于融合的階段更早,在數(shù)據(jù)這一層就已經(jīng)開始融合了。
2023年3月,微軟發(fā)布了Kosmos-1,一種MLLM(多模態(tài)大語言模型,Multimodal Large Language Model) ,模型的參數(shù)總量為16億。Kosmos-1可以接收不同模態(tài)信息的輸入,包括文本、圖像、語音等,可完成語言理解、視覺問答、多模態(tài)對話等不同類型的任務(wù),如下圖所示。

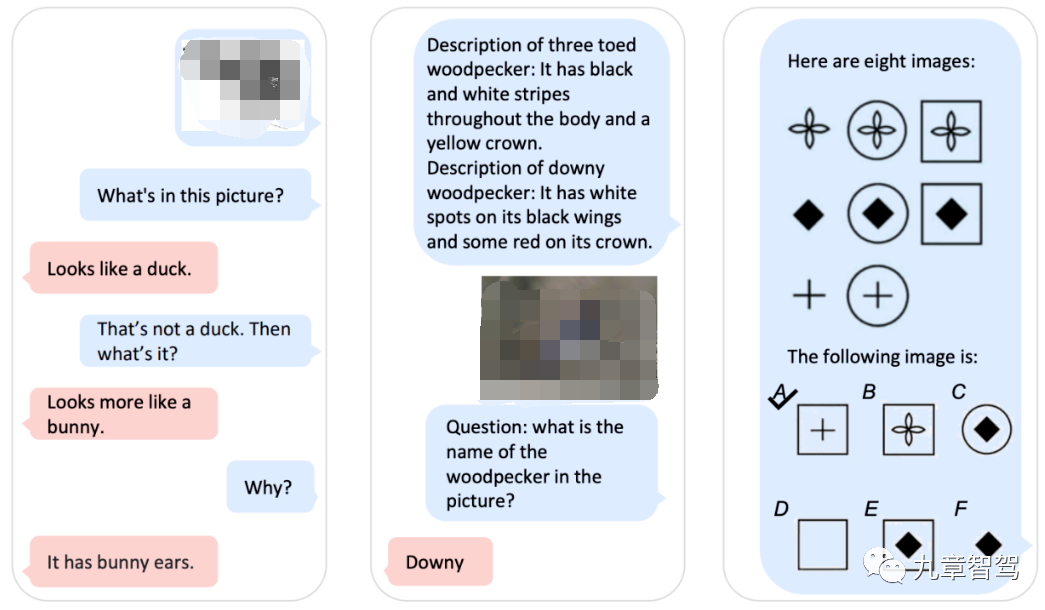
Kosmos-1的主干是一個以Transformer為基礎(chǔ)的語言模型,自然語言以及其他模態(tài)的信息都會被處理成統(tǒng)一的格式輸入到Transformer decoder中。
在輸入中,研究人員采用和來分別代表一個序列的開頭和結(jié)尾,
下圖列出了幾種不同的輸入信息,包括文本、圖片以及文本和圖片的混合信息。

Kosmos-1的提出給人機(jī)交互帶來了新的可能,雖然離大規(guī)模落地還有一定的過程。
商湯絕影智能車艙產(chǎn)品高級總監(jiān)李軻告訴筆者:
只有把語音和視覺融合在一起才能叫多模,商湯的特色就是大模型和多模態(tài)的融合。
有了多模態(tài)的能力,車輛就可以收集動態(tài)信息,包括語音的、視覺的,然后綜合地圖上的信息,可以實現(xiàn)對車內(nèi)駕乘人員的主動推薦功能。
主動推薦是一個關(guān)鍵的提升。以前,我們通常是直接下達(dá)指令,告訴車機(jī)我們需要什么,例如要車機(jī)幫忙打開車窗、打開空調(diào)、美食推薦。
現(xiàn)在,我們可以讓車機(jī)根據(jù)用戶當(dāng)前的狀態(tài)和一些習(xí)慣“主動”地做一些推薦,例如,在用戶開車上班途中,為他/她推薦吃早餐的地點。
某業(yè)內(nèi)專家告訴筆者:
我認(rèn)為模型層面的融合是比較接近自然交互的終極狀態(tài),相當(dāng)于我們是直接去走終極的路,而不是先做一個過渡態(tài)。
為什么模型層融合是自然交互的終極狀態(tài)呢?在模型層做融合具體有哪些優(yōu)勢?
2. 在模型層做融合的優(yōu)勢
2.1 更貼近人的習(xí)慣
從第一性原理來說,從模型層面融合更貼近人與外界交互的方式。
人與外界交互時,是一邊聽一邊看,同時接收聽覺、視覺以及其他感官的信息,然后形成綜合的判斷,而不是通過視覺做一個判斷,然后再通過聽覺再做一個判斷。這就類似于多模態(tài)模型接收不同模態(tài)的信息輸入,綜合處理之后輸出結(jié)果。
2.2 更充分利用信息
有了多模態(tài)的模型出來之后,我們就不用考慮是要前融合還是后融合的問題,可以直接在模型層面融合,也就是說,視覺信息、語音信息等不同模態(tài)的信息可以同時輸入模型,模型可以直接對不同模態(tài)的信息做處理,可以不用擔(dān)心在中間處理過程中信息丟失的問題。
某業(yè)內(nèi)專家告訴筆者:
模型層面的融合效果會比較好,它可以從多個維度提取一些比較深度的信息。
2.3 更方便持續(xù)學(xué)習(xí)
多模態(tài)大模型具備上下文學(xué)習(xí)(in-context learning)的能力,在接入一個場景之后,可以根據(jù)該場景的數(shù)據(jù)持續(xù)學(xué)習(xí)。
例如,多模態(tài)大模型接入了github之后,它就能學(xué)習(xí)代碼的一些邏輯,包括如何生成代碼、如何給代碼編譯做查錯處理等,它接入到office全家桶之后,文本編輯能力就大幅提升。
也就是說,隨著模型接入越來越多的不同模態(tài)的信息之后,它就會有更進(jìn)一步的訓(xùn)練,更好的強(qiáng)化學(xué)習(xí)的能力。在這種情況之下,它本身就是可以“生長”的,而不是通過人定義的a、b、c、d等規(guī)則來實現(xiàn)。
大模型不需要人為地定一個規(guī)則,只需要喂給它數(shù)據(jù),它可以根據(jù)數(shù)據(jù)自己學(xué)習(xí)如何融合不同模態(tài)的信息。
并且,經(jīng)過了十多年的發(fā)展,無監(jiān)督訓(xùn)練已經(jīng)相對成熟,未經(jīng)標(biāo)注的數(shù)據(jù)也可以作為多模態(tài)大模型學(xué)習(xí)的“素材”,也就是說可以用來“學(xué)習(xí)”的數(shù)據(jù)大大增加。這非常有利于模型能力的進(jìn)化。
在實踐中,多模態(tài)大模型可以如何落地呢?
3. 如何用多模態(tài)大模型實現(xiàn)自然交互
中科創(chuàng)達(dá)座艙產(chǎn)品線總經(jīng)理趙銳告訴筆者:
我認(rèn)為chatgpt可能會成為一個場景中樞,語音識別、視覺識別等算法可以由供應(yīng)商提供,具體和用戶如何互動,例如屏幕上需要投放什么內(nèi)容,根據(jù)與用戶互動的數(shù)據(jù)持續(xù)更新需要大模型來做,可以依靠云端的算力來做一些比較深度的處理。當(dāng)然了,在車端信號不好,也就是通信時效無法得到保障的時候,可以用一個簡單的小模型來過濾。
相比起自動駕駛,業(yè)界普遍認(rèn)為多模態(tài)的能力會先被集成到智能座艙,在座艙中可能會出現(xiàn)一到兩個爆款的場景應(yīng)用,讓用戶都能夠體驗到多模態(tài)技術(shù)帶來的好處。
在實踐中,可能會做成一個產(chǎn)品引擎的方案,這個方案會分成幾層。
底層就是各種感知信號的輸入源,包括視覺類的、音頻類的、賬戶類的、第三方信息類,以及用戶身上的一些展示信息。
底層往上是策略層,策略層按照發(fā)展歷程又分幾個階段。
第一階段主要是偏固定腳本編輯式的,這樣的方案已經(jīng)在給主機(jī)廠做場景方案的時候落地了。
在這樣的方案中,我們可以預(yù)設(shè)幾個場景。例如,用戶出門工作可以定義為一個場景,在這個場景中,車機(jī)可以預(yù)先打開空調(diào),預(yù)設(shè)一下導(dǎo)航查看路況。也就是說,只要用戶一鍵觸發(fā)這個場景,與這個場景相關(guān)的任務(wù)都會被自動執(zhí)行。
到了第二個階段,是結(jié)合推薦算法來使用。也就是說,產(chǎn)品經(jīng)理希望在車端的app中使用推薦算法,主動為用戶做一些推薦。
但是目前這個功能還并不好用,因為車端的各類數(shù)據(jù)相對獨立,車機(jī)實際上并不太理解用戶。因為車的 id 和普通 app的 id 是不一樣的,車載的信息都在主機(jī)廠。主機(jī)廠一般不會對供應(yīng)商開放數(shù)據(jù),所以車端app的推薦不如抖音、頭條等“合乎用戶心意”。
到了第三階段,是在車端用上多模態(tài)大模型的能力,讓大模型主動抓取不同模態(tài)、不同來源的信號,從而實現(xiàn)和用戶的自然交互。前文提到的商湯絕影根據(jù)用戶當(dāng)前的狀態(tài)和一些習(xí)慣“主動”地做一些推薦即為此類。
然而,在當(dāng)前的市場環(huán)境下,用戶還很難為多模態(tài)產(chǎn)品買單。除了長安的UNIT-T車型在宣傳的時候以多模態(tài)產(chǎn)品作為賣點,其他廠商在宣傳過程中很少會突出多模態(tài)。
chatgpt的出現(xiàn)可能會給這個行業(yè)增加一些新意,以后用戶可能可以真正感受到多模產(chǎn)品帶來的體驗的提升,然后用戶才會愿意為之買單,那么這個行業(yè)才會進(jìn)入一個爆發(fā)的時點。
4. 目前多模態(tài)大模型在應(yīng)用方面的局限
愿景是美好的,但實踐起來可能是困難的。目前,雖然很多業(yè)界人士都認(rèn)為多模態(tài)大模型可能是“未來”,但目前車端的大規(guī)模落地尚未實現(xiàn)。多模態(tài)大模型在車端落地可能會存在哪些困難呢?
4.1 訓(xùn)練數(shù)據(jù)尚缺
在基于多模態(tài)大模型的產(chǎn)品在車端沒有形成成熟生態(tài)的時候,訓(xùn)練模型用到的數(shù)據(jù)都是基于其他行業(yè)的。不管是語音還是視覺的數(shù)據(jù),都是基于目前已經(jīng)大規(guī)模落地的產(chǎn)品方案來獲取的。但假如我們希望多模態(tài)大模型在車端能實現(xiàn)很好的效果,需要很多車端的數(shù)據(jù)來幫助訓(xùn)練。
目前,主機(jī)廠對用戶的的數(shù)據(jù)有較強(qiáng)的隔離,不會隨便開放。有的主機(jī)廠會給供應(yīng)商提供一個賬號,然后讓供應(yīng)商去訓(xùn)練,但是數(shù)據(jù)的所有權(quán)仍然屬于主機(jī)廠。
這對后續(xù)的形態(tài)會有很大的挑戰(zhàn),包括迭代的速度、功能體驗的提升。
另一方面,大模型在車端的落地尚處于非常早期的狀態(tài),因此這一部分的訓(xùn)練數(shù)據(jù)較為稀缺。我們可以看到文心一言一開始在做圖片的編輯生成的時候,例如生成“胸有成竹”、“夫妻肺片”等對應(yīng)的圖片時會就出現(xiàn)一些令人啼笑皆非的結(jié)果。
原因是工程師在開發(fā)這些場景的時候,沒有考慮到用戶這么玩兒。這一部分對應(yīng)的冷啟動期間的預(yù)訓(xùn)練,或者說是初步規(guī)則的制定還沒有達(dá)到一定的量級。
某業(yè)內(nèi)專家告訴筆者:
目前主要是大家還沒有形成共識,很多廠商可能抱著一種先小規(guī)模測試一下,結(jié)合用戶的反饋信息來決定接下來該如何決策。現(xiàn)狀更多的是一個令人振奮的新東西出來了,大家覺得這是未來的方向。那么,我們先把它實現(xiàn)出來,讓用戶開始習(xí)慣新的方案。前方的路比較確定了,只是過程中還存在一些難題,但我相信這些都會被解決的。
另外,在車內(nèi)采集數(shù)據(jù)會涉及到隱私問題,廠商可能需要做一些脫敏的方案,例如不需要把整段語音都上傳到云端,而是可以做一些特征點的裁剪,來做語料的補(bǔ)充。
或者端側(cè)部署的方案,也就是說,大模型本身可能是一個公版,但是交到每一個廠商那里時會有一個定制版,或者說是封裝的一個版本。
4.2 車端信息龐雜
車?yán)锏男畔⑹呛芏嗟模易撌且粋€很大的市場,同時也是一個很大的挑戰(zhàn),這背后很重要的點就是汽車是目前人類社會上最大的智能移動終端,大、智能、移動這幾個關(guān)鍵詞都很重要,汽車的這些特點決定了我們在設(shè)計產(chǎn)品的時候安全是第一位的。
疊加了大以及可移動這些屬性之后,汽車這個智能終端就和很多其他的終端(例如手機(jī))很不一樣。手機(jī)只有一個屏,所有內(nèi)容都從一個屏輸出,而且手機(jī)的傳感器感知的內(nèi)容特別少,主要就是語音、視覺、gps定位信息等。
但是在車端,即使不算上車身的氣墊等,傳感器數(shù)量就大概是手機(jī)里的十倍以上。而且座艙內(nèi)的很多部件自由度很高,可以改造的余地很大,座椅、氛圍燈等都可以改造,還有一些新的交互方式例如HUD、VR等在上車,在這樣的背景下,工程師希望用一個統(tǒng)一的模型來做場景開發(fā)就會比較困難,因為輸入越多,挑戰(zhàn)就越大。
在智能家居里做一個天貓精靈是容易的,但是在車?yán)镒鲆粋€ai 助手很難,因為信息太雜。
4.3 大模型的使用門檻較高
現(xiàn)在使用大模型的門檻不低,例如最近有很多用戶的gpt賬戶都被封掉了。這本質(zhì)上是因為目前的網(wǎng)絡(luò)基礎(chǔ)設(shè)施承載不了大規(guī)模的訪問。
另外就是可能會涉及到泄密,因為它的爬蟲可以抓取很多數(shù)據(jù),后面登錄的用戶可以看到之前登錄的用戶的信息。這樣會比較危險,因為用戶尚不清楚它到底會抓取什么數(shù)據(jù),以及如何處理抓取的數(shù)據(jù)。
在此次采訪中,筆者不止一次聽到有廠商在和微軟或者其他一些具備通用大模型能力的公司洽談合作的消息。據(jù)悉,有的公司已經(jīng)開始嘗試將大模型應(yīng)用在座艙上,并且已經(jīng)拿到某主流主機(jī)廠的定點。
假如過程順利,也許我們很快就能體驗到更智能的座艙,屆時,汽車上的人機(jī)交互可能會進(jìn)入一個新的時代。
編輯:黃飛
-
傳感器
+關(guān)注
關(guān)注
2548文章
50664瀏覽量
751940 -
人機(jī)交互
+關(guān)注
關(guān)注
12文章
1200瀏覽量
55320 -
手勢識別
+關(guān)注
關(guān)注
8文章
225瀏覽量
47772 -
語音助手
+關(guān)注
關(guān)注
7文章
235瀏覽量
26791 -
大模型
+關(guān)注
關(guān)注
2文章
2322瀏覽量
2479
原文標(biāo)題:多模態(tài)大模型會是未來人機(jī)交互的方向嗎?
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論