 DISC-LawLLM:復旦大學團隊發布中文智慧法律系統,構建司法評測基準,開源30萬微調數據
DISC-LawLLM:復旦大學團隊發布中文智慧法律系統,構建司法評測基準,開源30萬微調數據
背景介紹
隨著智慧司法的興起,智能化方法驅動的智能法律系統可以惠及不同的群體。例如,為法律專業人員減輕文書工作,為普通民眾提供法律咨詢服務,為法學學生提供學習和考試輔導。
由于法律知識的獨特性和司法任務的多樣性,之前智慧司法研究方面,主要著眼于為特定任務設計自動化算法,難以滿足對司法領域提供支撐性服務的需求,離應用落地有不小的距離。最近,大型語言模型(LLMs)展示出強大的能力在不同的傳統任務上,為智能法律系統的進一步發展帶來希望。
復旦大學數據智能與社會計算實驗室(FudanDISC)發布大語言模型驅動的中文智慧法律系統——DISC-LawLLM。該系統可以面向不同用戶群體,提供多樣的法律服務。此外,構建了評測基準DISC-Law-Eval,從客觀和主觀兩個方面來評測法律大語言模型,模型在評測中的表現相較現有的法律大模型有明顯優勢。
課題組同時公開包含30萬高質量的監督微調(SFT)數據集——DISC-Law-SFT,模型參數和技術報告也一并開源。
DISC
01
樣例展示
用戶有法律方面的疑問時,可以向模型咨詢,描述疑問,模型會給出相關的法律規定和解釋、推薦的解決方案等。

圖1 法律咨詢示例 專業法律者和司法機關,可以利用模型完成法律文本摘要、司法事件檢測、實體和關系抽取等,減輕文書工作,提高工作效率。

圖2 司法文書分析 法律專業的學生在準備司法考試過程中,可以向模型提出問題,幫助鞏固法律知識,解答法律考試題。

圖3 考試助手示例 在需要外部法條做支撐時,模型會根據問題在知識庫中檢索相關內容,給出回復。
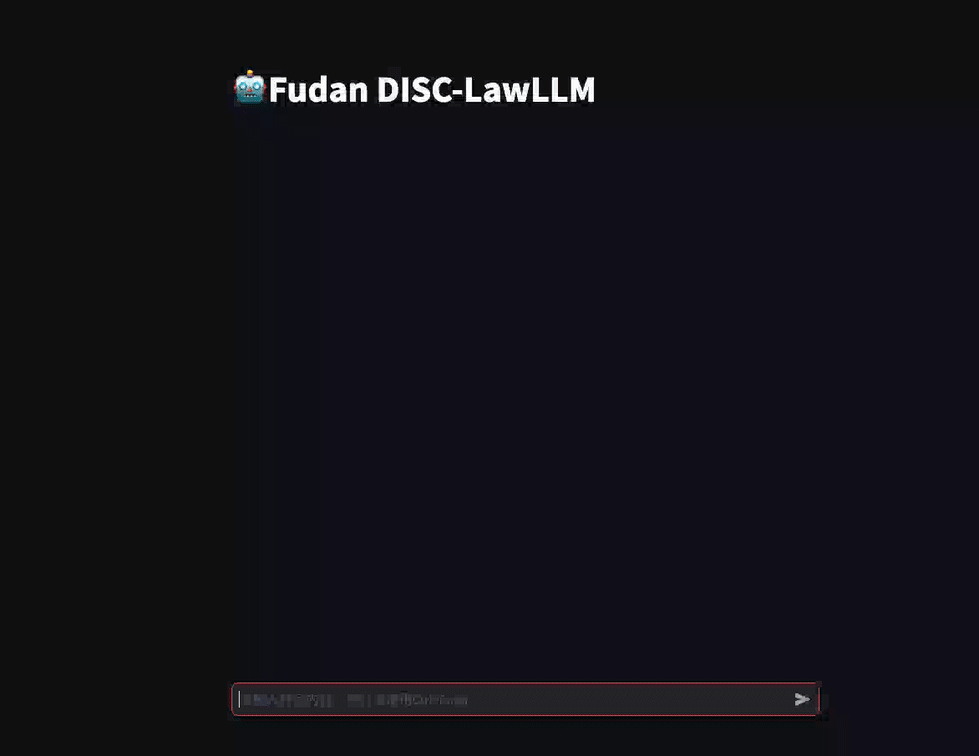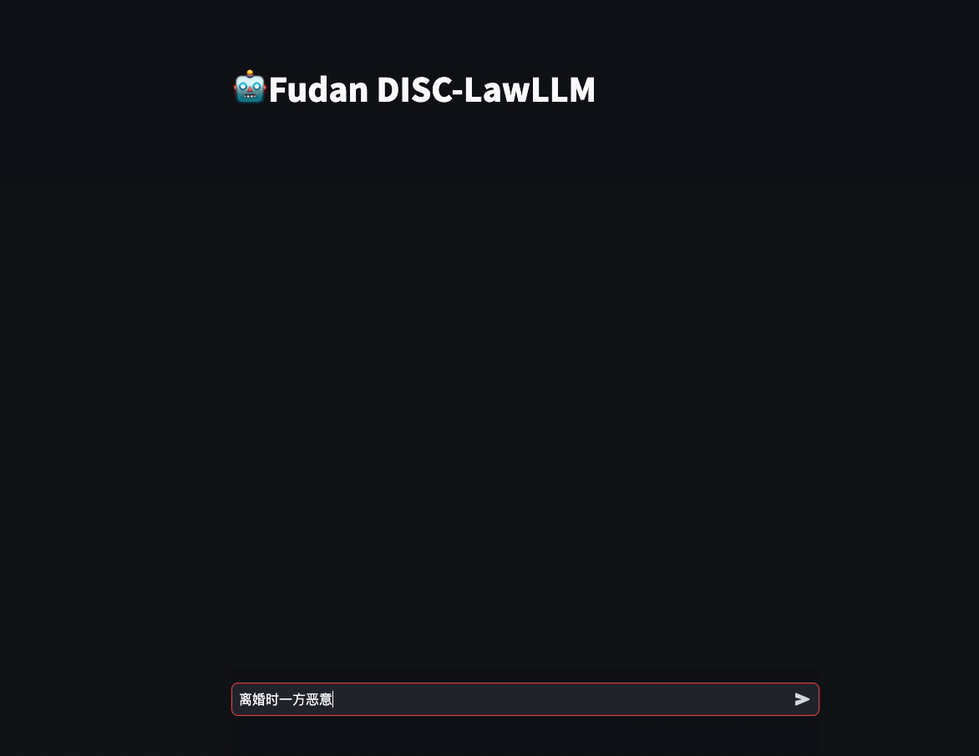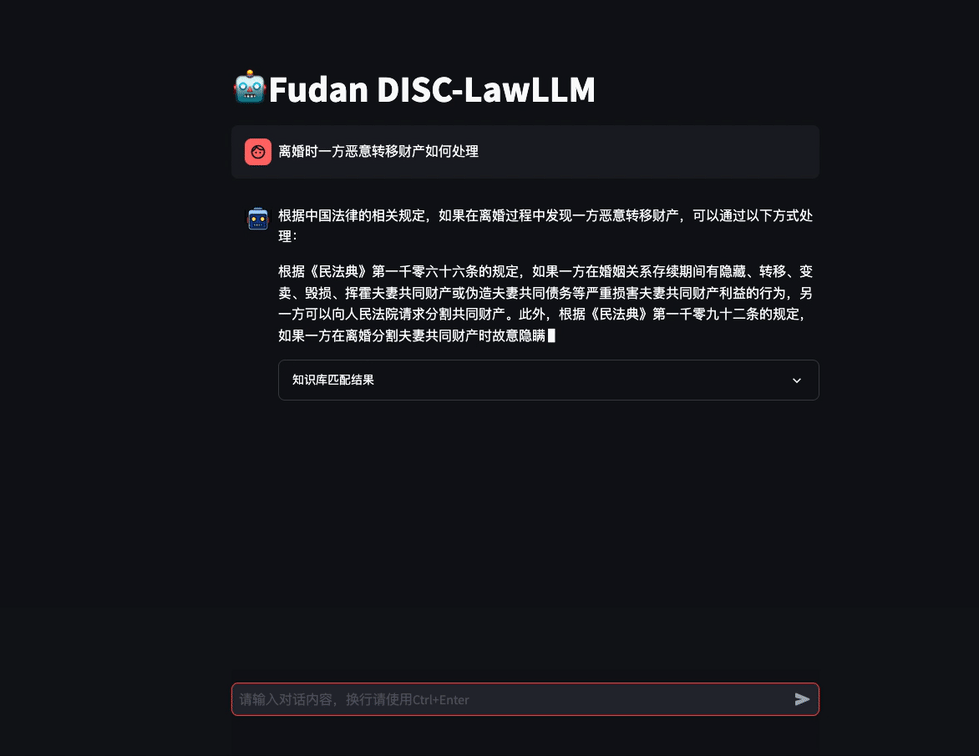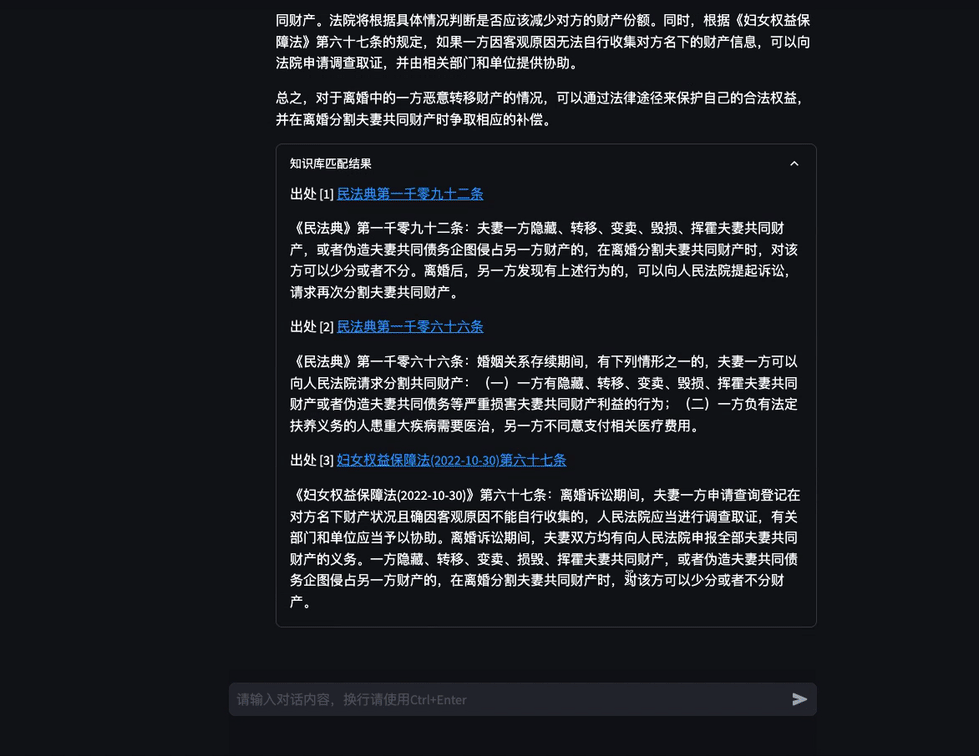
圖4 檢索增強場景下的對話
02
DISC-LawLLM介紹
DISC-LawLLM是基于我們構建的高質量數據集DISC-Law-SFT在通用領域中文大模型Baichuan-13B上進行全參指令微調得到的法律大模型。值得注意的是,我們的訓練數據和訓練方法可以被適配到任何基座大模型之上。 DISC-LawLLM具有三個核心能力: 1. 基礎的法律文本處理能力。針對法律文本理解與生成的不同基礎能力,包括信息抽取、文本摘要等,我們基于現有的NLP司法任務公開數據和真實世界的法律相關文本進行了微調數據的構建。 2. 法律推理思維能力。針對智慧司法領域任務的需求,我們使用法律三段論這一法官的基本法律推理過程重構了指令數據,有效地提高了模型的法律推理能力。 3. 司法領域知識檢索遵循能力。智慧司法領域的問題解決,往往需要依循與問題相關的背景法條或者案例,我們為智能法律處理系統配備了檢索增強的模塊,加強了系統對于背景知識的檢索和遵循能力。 模型的整體框架如圖5 所示。
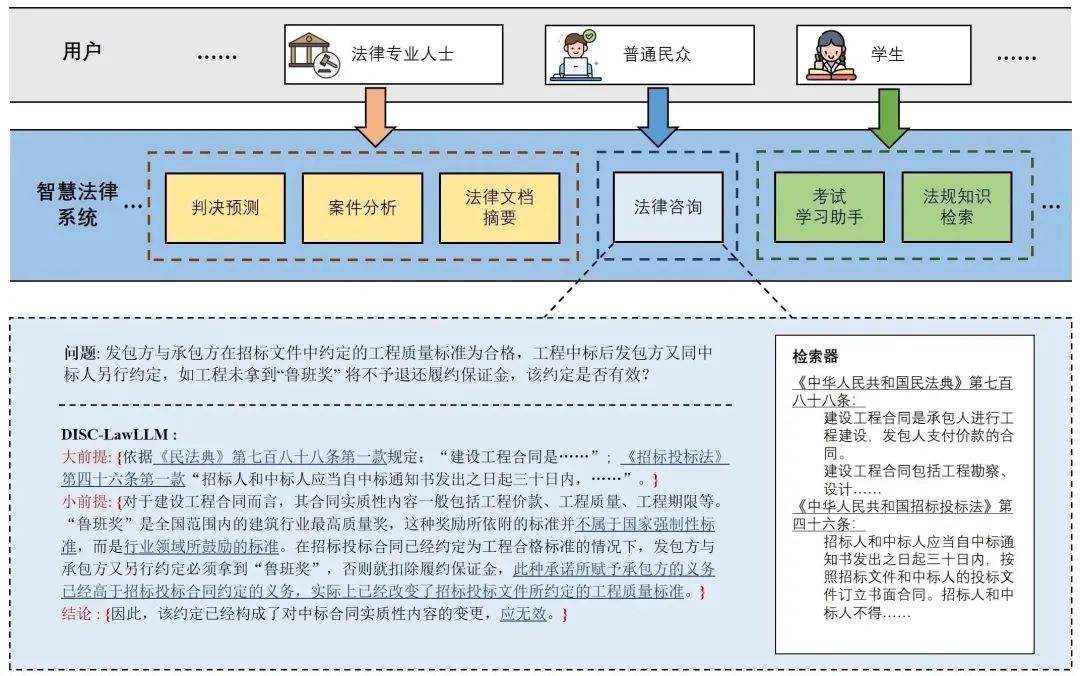
圖5 模型在不同的法律場景下服務于不同的用戶
03
方法:
數據集DISC-Law-SFT的構造
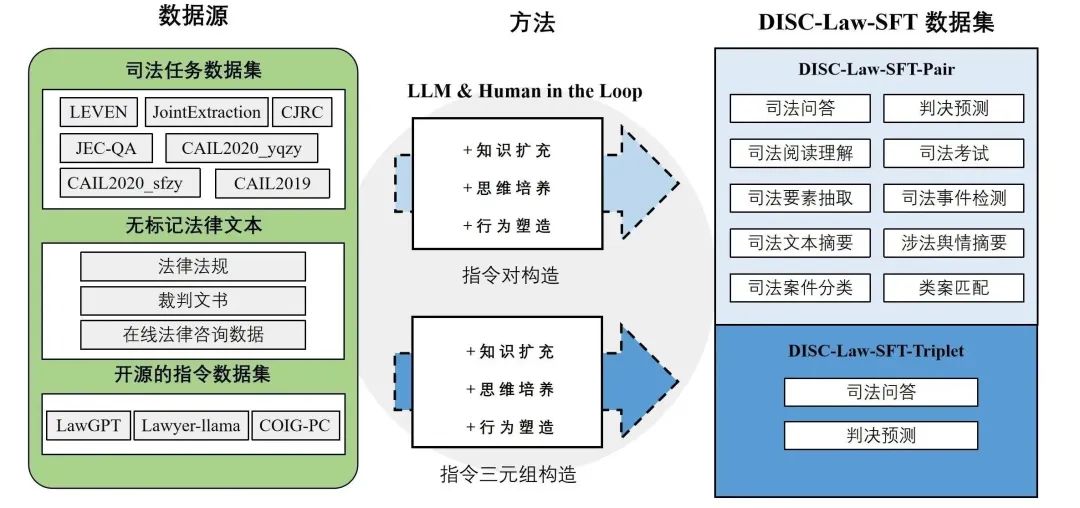
圖6 DISC-Law-SFT的構造
DISC-Law-SFT分為兩個子數據集,分別是DISC-Law-SFT-Pair和DISC-Law-SFT-Triplet,前者向LLM中引入了法律推理能力,而后者則有助于提高模型利用外部知識的能力。
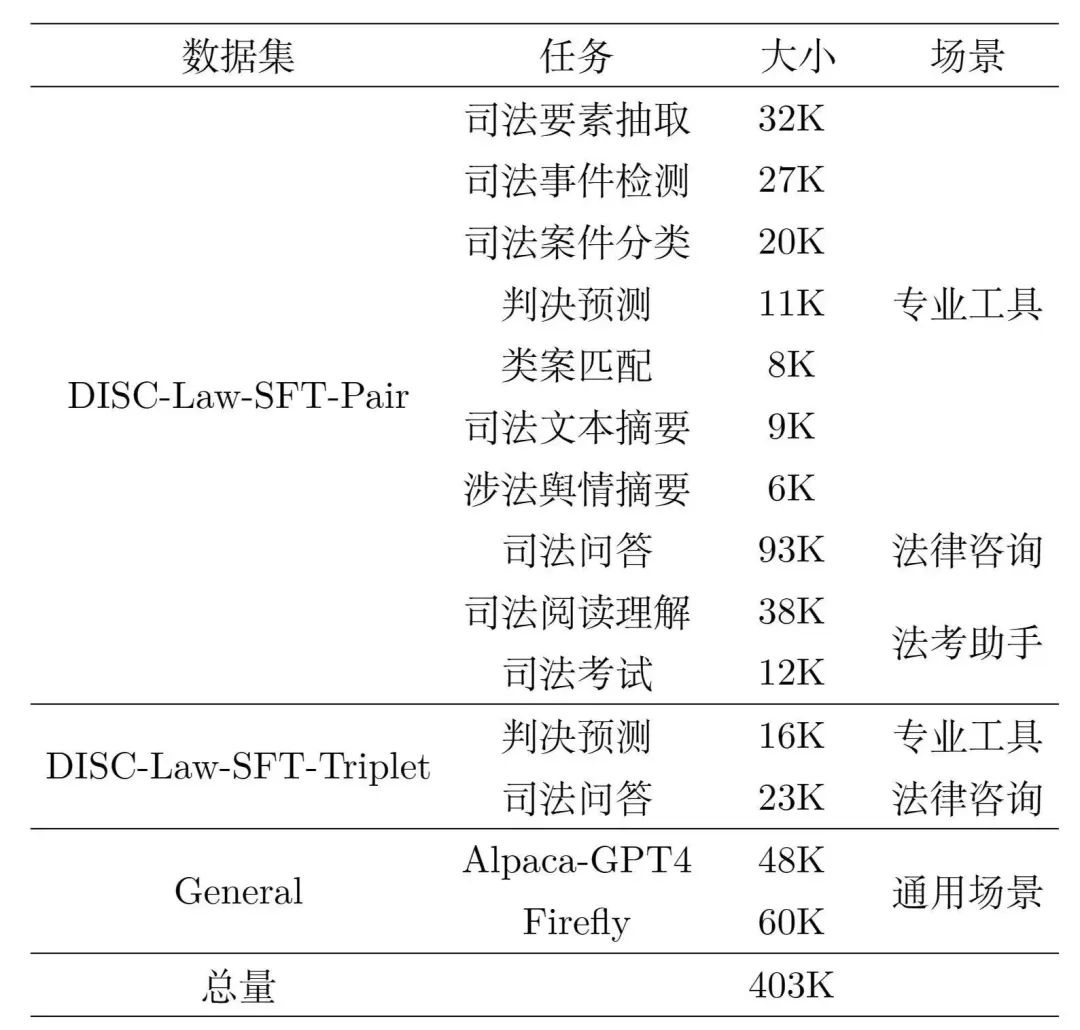
表1:DISC-Law-SFT數據集內容介紹
數據來源
DISC-Law-SFT數據集的數據來源于三部分,一是與中國法律相關的NLP司法任務公開數據集,包括法律信息抽取、實體與關系抽取、司法文本摘要、司法考試問答、司法閱讀理解、罪名/刑期預測等;二是收集了來自真實世界的法律相關的原始文本,如法律法規、司法案件、裁判文書、司法相關的考試等;三是通用的開源數據集,我們使用了alpaca_gpt4_data_zh和Firefly,這樣可以豐富訓練集的多樣性,減輕模型在SFT訓練階段出現基礎能力降級的風險。
指令對構造
對上述一、二來源的數據轉換為“輸入-輸出”指令對后,我們采用以下三種方式對指令數據重構,以提高數據質量。行為塑造在法律三段論中,大前提為適用的法律規則,小前提為案件事實,結論為法律判斷。這構成了法官的一個基本的法律推理過程。每一個案例都可以通過三段論得出一個明確的結論,如下所述: 大前提:法律規則 小前提:案件事實 結論:法律判斷 我們利用GPT-3.5-turbo來完成行為塑造的重構,細化輸出,確保每個結論都從一個法律條款和一個案例事實中得出。知識擴充對于行為塑造不適用的多項選擇題,我們直接使用法律知識擴展輸出,以提供更多的推理細節。許多與法律相關的考試和知識競賽只提供答案選項,我們使用LLM來擴展所涉及的法律知識,給出正確的答案,并重建指令對。思維培養思維鏈(CoT)已被證明能有效地提高模型的推理能力。為了進一步賦予模型法律推理能力,我們設計了具有特定法律意義的思維鏈,稱為LCoT,要求模型用法律三段論來推導答案。LCoT將輸入X轉換為如下的提示: 在法律三段論中,大前提是適用的法律規則,小前提是案件事實,結論是對案件的法律判斷。 案件:X 讓我們用法律三段論來思考和輸出判斷:
指令三元組構造
為了訓練檢索增強后的模型,我們構造了DISC-Law-SFT-Triplet子數據集,數據為<輸入、輸出、參考>形式的三元組,我們使用指令對構造中列出的三種策略對原始數據進行處理,獲得輸入和輸出,并設計啟發式規則來從原始數據中提取參考信息。
04
實驗
訓練
DISC-LawLLM的訓練過程分為SFT和檢索增強兩個階段。檢索增強雖然我們使用了高質量的指令數據對LLM進行微調,但它可能會由于幻覺或過時的知識而產生不準確的反應。為了解決這個問題,我們設計了一個檢索模塊來增強DISC-LawLLM。 給定一個用戶輸入,檢索器通過計算它們與輸入的相似性,從知識庫返回最相關的Top-K文檔。這些候選文檔,連同用戶輸入,用我們設計的模板構造后輸入到DISC-LawLLM中。通過查詢知識庫,模型可以更好地理解主要前提,從而得到更準確可靠的答案
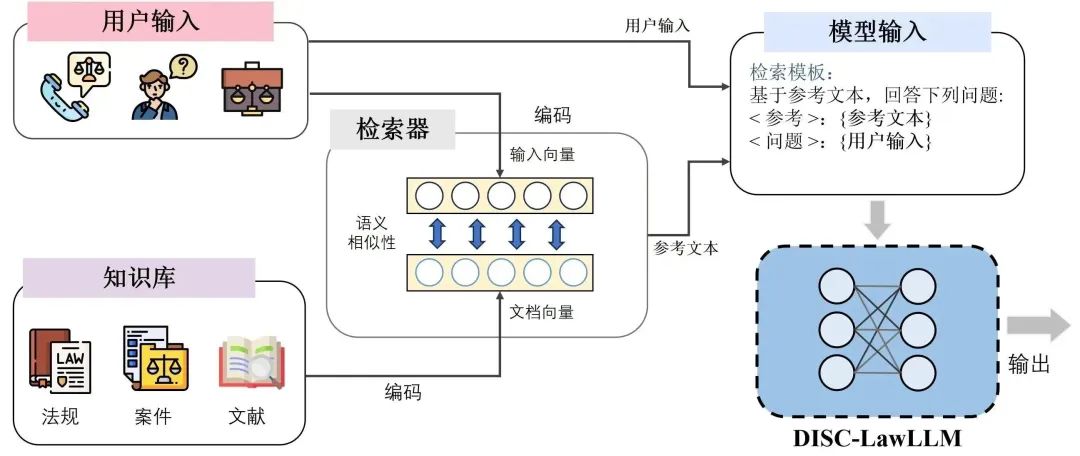
圖7:檢索增強的DISC-LawLLM
評測
評測基準 DISC-Law-Eval我們構建了一個公平的智能法律系統評估基準DISC-Law-Eval,從客觀和主觀的角度來評估,填補了目前還沒有基準來對智能法律體系全面評估這一空白。
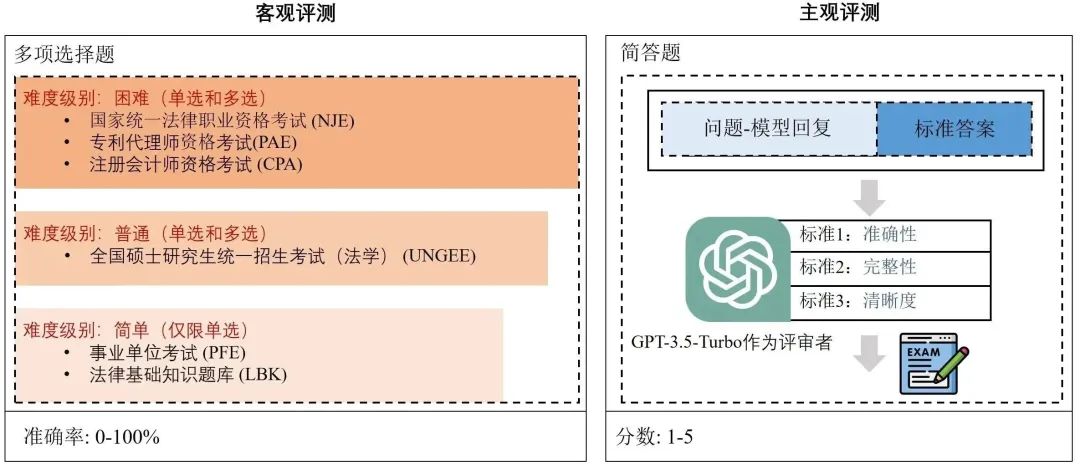
圖8:DISC-Law-Eval評測基準客觀評測為了客觀、定量地評估智能法律系統的法律知識和推理能力,我們設計了一個客觀的評價數據集,由一系列中國法律標準化考試和知識競賽的單項和多項選擇題組成,并根據內容復雜性和演繹難度,將問題分為困難、正常和容易三個層次。它可以提供一個更具挑戰性和可靠的方法來衡量模型是否可以利用其知識來推理正確的答案。我們通過計算精度來表明性能。主觀評測主觀評測部分,我們采用問答的范式進行評估,模擬主觀考試問題的過程。我們從法律咨詢、在線論壇、與司法相關的出版物和法律文件中手工構建了一個高質量的測試集。我們用GPT- 3.5-turbo作為裁判模型來評估模型的輸出,并用準確性、完整性和清晰度這三個標準提供1到5的評分。
評測結果
比較模型將我們的模型DISC-LawLLM(不外接知識庫)與4個通用LLM和4個中文法律LLM進行比較,包括GPT-3.5-turbo、ChatGLM-6B 、Baichuan-13B-Chat 、Chinese-Alpaca2-13B ;LexiLaw 、LawGPT、Lawyer LLaMA、ChatLaw 。客觀評測結果DISC-LawLLM在所有不同難度水平的測試中超過所有比較的同等參數量的大模型。即使與具有175B參數的GPT- 3.5-turbo相比,DISC-LawLLM在部分測試上也表現出了更優越的性能。表2是客觀評測結果,其中加粗表示最佳結果,下劃線表示次佳結果。
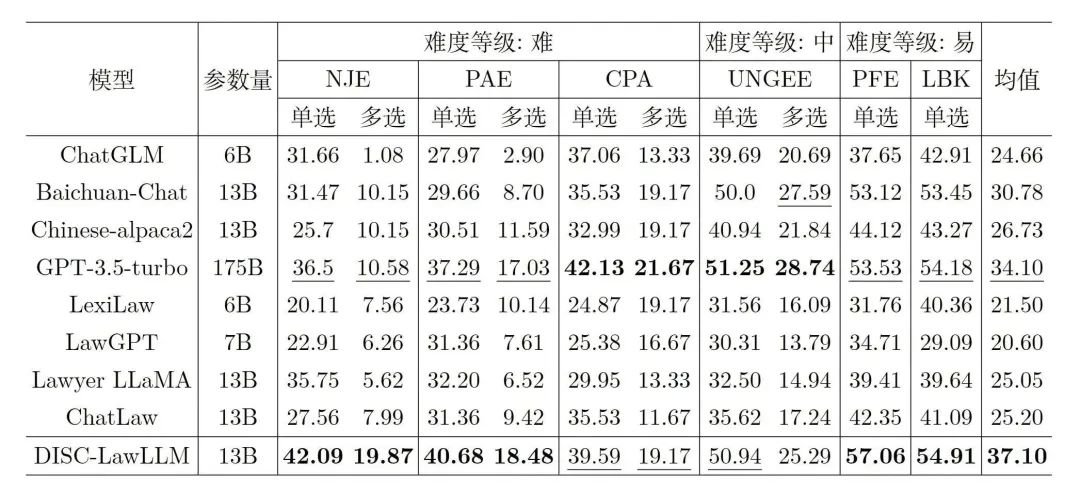
表2:客觀評測結果主觀評測結果在客觀評測中,DISC-LawLLM獲得了最高的綜合得分,并在準確性和清晰度這兩項標準中得分最高。表3是主觀評測結果,其中加粗表示最佳結果。
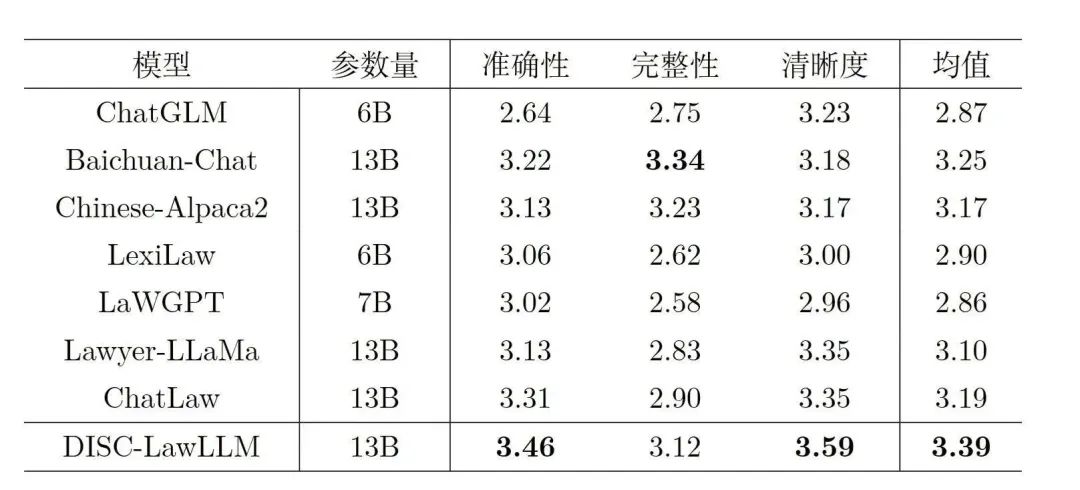
表3:主觀評測結果
05
總結
我們發布了DISC-LawLLM,一個提供多應用場景下法律服務的智能法律系統。基于公開的法律領域NLP任務數據集、法律原始文本和開源通用指令數據集,按照法律三段論重構了法律指令進行監督微調。為了提高輸出的可靠性,我們加入了一個外部檢索模塊。通過提高法律推理和知識檢索能力,DISC-LawLLM在我們構建的法律基準評測集上優于現有的法律LLM。該領域的研究將為實現法律資源平衡等帶來更多前景和可能性,我們發布了所構建的數據集和模型權重,以促進進一步的研究。
-
算法
+關注
關注
23文章
4601瀏覽量
92673 -
智能化
+關注
關注
15文章
4831瀏覽量
55267 -
語言模型
+關注
關注
0文章
508瀏覽量
10247
原文標題:DISC-LawLLM:復旦大學團隊發布中文智慧法律系統,構建司法評測基準,開源30萬微調數據
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
模擬電路二級運放實例【復旦大學教材】
研究生畢業繼續送資料——超經典復旦大學微電子工藝教案
Google 在上海與復旦大學簽署兩年期合作協議 Google將重點支持復旦大學在人工智能
應用材料公司攜手復旦大學舉辦半導體技術系列講座
華為與復旦大學合作開發醫學AI與機器學習課程
科沃斯機器人擔任復旦大學的助理輔導員
強強聯手 | 晶華微-復旦大學聯合實驗室正式揭牌

校源行 | 開放原子校源行活動走進復旦大學






 工商網監
工商網監
評論