") ICCV 2023 | 超越SAM!EntitySeg:更少的數(shù)據(jù),更高的分割質(zhì)量
ICCV 2023 | 超越SAM!EntitySeg:更少的數(shù)據(jù),更高的分割質(zhì)量
稠密圖像分割問題一直在計算機視覺領(lǐng)域中備受關(guān)注。無論是在 Adobe 旗下的 Photoshop 等重要產(chǎn)品中,還是其他實際應(yīng)用場景中,分割模型的泛化和精度都被賦予了極高的期望。對于這些分割模型來說,需要在不同的圖像領(lǐng)域、新的物體類別以及各種圖像分辨率和質(zhì)量下都能夠保持魯棒性。為了解決這個問題,早在 SAM[6] 模型一年之前,一種不考慮類別的實體分割任務(wù) [1] 被提出,作為評估模型泛化能力的一種統(tǒng)一標(biāo)準(zhǔn)。
在本文中,High-Quality Entity Segmentation 對分割問題進(jìn)行了全新的探索,從以下三個方面取得了顯著的改進(jìn):
1. 更優(yōu)的分割質(zhì)量:正如上圖所示,EntitySeg 在數(shù)值指標(biāo)和視覺表現(xiàn)方面都相對于 SAM 有更大的優(yōu)勢。令人驚訝的是,這種優(yōu)勢是基于僅占訓(xùn)練數(shù)據(jù)量千分之一的數(shù)據(jù)訓(xùn)練取得的。
2. 更少的高質(zhì)量數(shù)據(jù)需求:相較于 SAM 使用的千萬級別的訓(xùn)練數(shù)據(jù)集,EntitySeg 數(shù)據(jù)集僅含有 33,227 張圖像。盡管數(shù)據(jù)量相差千倍,但 EntitySeg 卻取得了可媲美的性能,這要歸功于其標(biāo)注質(zhì)量,為模型提供了更高質(zhì)量的數(shù)據(jù)支持。
3. 更一致的輸出細(xì)粒度(基于實體標(biāo)準(zhǔn)):從輸出的分割圖中,我們可以清晰地看到 SAM 輸出了不同粒度的結(jié)果,包括細(xì)節(jié)、部分和整體(如瓶子的蓋子、商標(biāo)、瓶身)。然而,由于 SAM 需要對不同部分的人工干預(yù)處理,這對于自動化輸出分割的應(yīng)用而言并不理想。相比之下,EntitySeg 的輸出在粒度上更加一致,并且能夠輸出類別標(biāo)簽,對于后續(xù)任務(wù)更加友好。
在闡述了這項工作對稠密分割技術(shù)的新突破后,接下來的內(nèi)容中介紹 EntitySeg 數(shù)據(jù)集的特點以及提出的算法 CropFormer。

代碼鏈接:
https://github.com/qqlu/Entity/blob/main/Entityv2/README.md主頁鏈接:
http://luqi.info/entityv2.github.io/根據(jù) Marr 計算機視覺教科書中的理論,人類的識別系統(tǒng)是無類別的。即使對于一些不熟悉的實體,我們也能夠根據(jù)相似性進(jìn)行識別。因此,不考慮類別的實體分割更貼近人類識別系統(tǒng),不僅可以作為一種更基礎(chǔ)的任務(wù),還可以輔助于帶有類別分割任務(wù) [2]、開放詞匯分割任務(wù) [3] 甚至圖像編輯任務(wù) [4]。與全景分割任務(wù)相比,實體分割將“thing”和“stuff”這兩個大類進(jìn)行了統(tǒng)一,更加符合人類最基本的識別方式。
 ?
?EntitySeg數(shù)據(jù)集
由于缺乏現(xiàn)有的實體分割數(shù)據(jù),作者在其工作 [1] 使用了現(xiàn)有的 COCO、ADE20K 以及 Cityscapes 全景分割數(shù)據(jù)集驗證了實體任務(wù)下模型的泛化能力。然而,這些數(shù)據(jù)本身是在有類別標(biāo)簽的體系下標(biāo)注的(先建立一個類別庫,在圖片中搜尋相關(guān)的類別進(jìn)行定位標(biāo)注),這種標(biāo)注過程并不符合實體分割任務(wù)的初衷——圖像中每一個區(qū)域均是有效的,哪怕這些區(qū)域無法用言語來形容或者被 Blur 掉,都應(yīng)該被定位標(biāo)注。此外,受限于提出年代的設(shè)備,COCO 等數(shù)據(jù)集的圖片域以及圖片分辨率也相對單一。因此基于現(xiàn)有數(shù)據(jù)集下訓(xùn)練出的實體分割模型也并不能很好地體現(xiàn)實體分割任務(wù)所帶來的泛化能力。最后,原作者團(tuán)隊在提出實體分割任務(wù)的概念后進(jìn)一步貢獻(xiàn)了高質(zhì)量細(xì)粒度實體分割數(shù)據(jù)集 EntitySeg 及其對應(yīng)方法。EntitySeg 數(shù)據(jù)集是由 Adobe 公司 19 萬美元贊助標(biāo)注完成,已經(jīng)開源貢獻(xiàn)給學(xué)術(shù)界使用。
項目主頁:
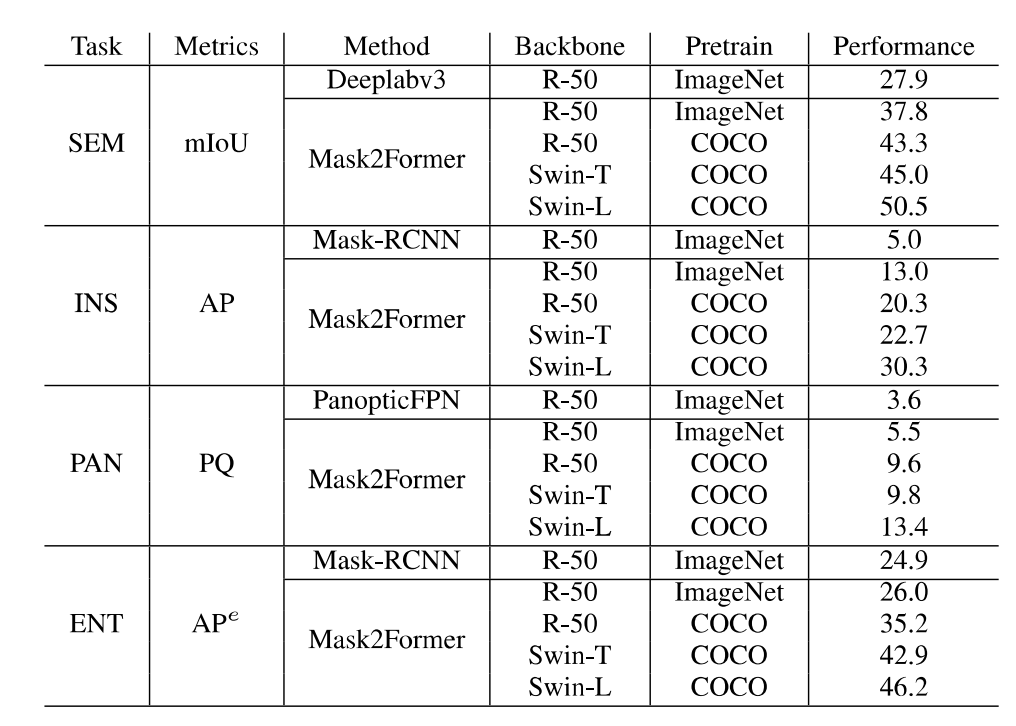
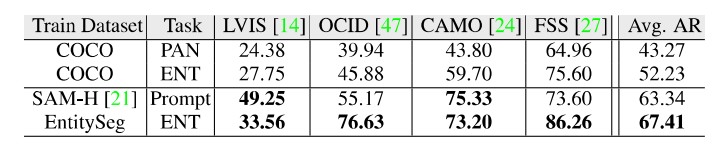
http://luqi.info/entityv2.github.io/數(shù)據(jù)集有三個重要特性:1. 數(shù)據(jù)集匯集了來自公開數(shù)據(jù)集和學(xué)術(shù)網(wǎng)絡(luò)的 33,227 張圖片。這些圖片涵蓋了不同的領(lǐng)域,包括風(fēng)景、室內(nèi)外場景、卡通畫、簡筆畫、電腦游戲和遙感場景等。2. 標(biāo)注過程在無類別限制下進(jìn)行的掩膜標(biāo)注,并且可以覆蓋整幅圖像。3. 圖片分辨率更高,標(biāo)注更精細(xì)。如上圖所示,即使相比 COCO 和 ADE20K 數(shù)據(jù)集的原始低分辨率圖片及其標(biāo)注,EntitySeg 的實體標(biāo)注更全且更精細(xì)。最后,為了讓 EntitySeg 數(shù)據(jù)集更好地服務(wù)于學(xué)術(shù)界,11580 張圖片在標(biāo)注實體掩膜之后,以開放標(biāo)簽的形式共標(biāo)注了 643 個類別。EntitySeg、COCO 以及 ADE20K 數(shù)據(jù)集的統(tǒng)計特性對比如下: 通過和 COCO 以及 ADE20K 的數(shù)據(jù)對比,可以看出 EntitySeg 數(shù)據(jù)集圖片分辨率更高(平均圖片尺寸 2700)、實體數(shù)量更多(每張圖平均 18.1 個實體)、掩膜標(biāo)注更為復(fù)雜(實體平均復(fù)雜度 0.719)。極限情況下,EntitySeg 的圖片尺寸可達(dá)到 10000 以上。與 SAM 數(shù)據(jù)集不同,EntitySeg 更加強調(diào)小而精,試圖做到對圖片中的每個實體得到最為精細(xì)的邊緣標(biāo)注。此外,EntitySeg 保留了圖片和對應(yīng)標(biāo)注的原始尺寸,更有利于高分辨率分割模型的學(xué)術(shù)探索。基于 EntitySeg 數(shù)據(jù)集,作者衡量了現(xiàn)有分割模型在不同分割任務(wù)(無類別實體分割,語義分割,實例分割以及全景分割)的性能以及和 SAM 在 zero-shot 實體級別的分割能力。
通過和 COCO 以及 ADE20K 的數(shù)據(jù)對比,可以看出 EntitySeg 數(shù)據(jù)集圖片分辨率更高(平均圖片尺寸 2700)、實體數(shù)量更多(每張圖平均 18.1 個實體)、掩膜標(biāo)注更為復(fù)雜(實體平均復(fù)雜度 0.719)。極限情況下,EntitySeg 的圖片尺寸可達(dá)到 10000 以上。與 SAM 數(shù)據(jù)集不同,EntitySeg 更加強調(diào)小而精,試圖做到對圖片中的每個實體得到最為精細(xì)的邊緣標(biāo)注。此外,EntitySeg 保留了圖片和對應(yīng)標(biāo)注的原始尺寸,更有利于高分辨率分割模型的學(xué)術(shù)探索。基于 EntitySeg 數(shù)據(jù)集,作者衡量了現(xiàn)有分割模型在不同分割任務(wù)(無類別實體分割,語義分割,實例分割以及全景分割)的性能以及和 SAM 在 zero-shot 實體級別的分割能力。
 ?
?CropFormer算法框架
除此之外,高分辨率圖片和精細(xì)化掩膜給分割任務(wù)帶來了新的挑戰(zhàn)。為了節(jié)省硬件內(nèi)存需求,分割模型需要壓縮高分辨率圖片及標(biāo)注進(jìn)行訓(xùn)練和測試進(jìn)而導(dǎo)致分割質(zhì)量的降低。為了解決這一問題,作者提出了 CropFormer 框架來解決高分辨率圖片分割問題。CropFormer 受到 Video-Mask2Former [5] 的啟發(fā), 利用一組 query 連結(jié)壓縮為低分辨率的全圖和保持高分辨率的裁剪圖的相同實體。因此,CropFormer 可以同時保證圖片全局和區(qū)域細(xì)節(jié)屬性。CropFormer 是根據(jù) EntitySeg 高質(zhì)量數(shù)據(jù)集的特點提出的針對高分辨率圖像的實例/實體分割任務(wù)的 baseline 方法,更加迎合當(dāng)前時代圖片質(zhì)量的需求。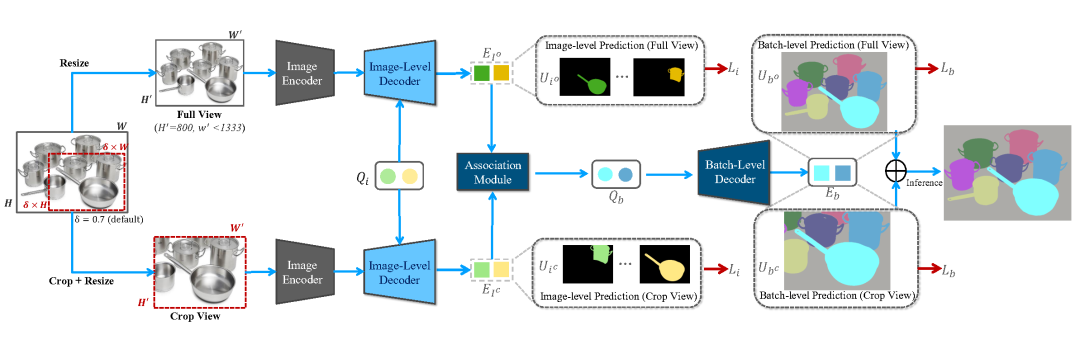
最后在補充材料中,作者展示了更多的 EntitySeg 數(shù)據(jù)集以及 CropFormer 的可視化結(jié)果。下圖為更多數(shù)據(jù)標(biāo)注展示:
下圖為 CropFormer 模型測試結(jié)果:
參考文獻(xiàn)
[1] Open-World Entity Segmentation. TAPMI 2022.[2] CA-SSL: Class-agnostic Semi-Supervised Learning for Detection and Segmentation. ECCV 2022.[3] Open-Vocabulary Panoptic Segmentation with MaskCLIP. ICML 2023.[4] SceneComposer: Any-Level Semantic Image Synthesis. CVPR 2023.[5] Masked-attention Mask Transformer for Universal Image Segmentation. CVPR 2022.[6] Segment Anything. ICCV 2023.
原文標(biāo)題:ICCV 2023 | 超越SAM!EntitySeg:更少的數(shù)據(jù),更高的分割質(zhì)量
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2904文章
44296瀏覽量
371401
原文標(biāo)題:ICCV 2023 | 超越SAM!EntitySeg:更少的數(shù)據(jù),更高的分割質(zhì)量
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
畫面分割器怎么調(diào)試
畫面分割器怎么連接

圖像語義分割的實用性是什么
圖像分割和語義分割的區(qū)別與聯(lián)系
機器學(xué)習(xí)中的數(shù)據(jù)分割方法
圖像分割與語義分割中的CNN模型綜述
天馬榮獲海微科技頒發(fā)“2023年度優(yōu)秀質(zhì)量獎”和“2023年度保供獎”
華為首次超越蘋果成為國內(nèi)平板電腦市場出貨量第一
一種新的分割模型Stable-SAM

【愛芯派 Pro 開發(fā)板試用體驗】+ 圖像分割和填充的Demo測試
華秋DFM榮獲2023年度電子信息行業(yè)可靠性質(zhì)量提升典型案例
華秋DFM軟件榮獲2023年度電子信息行業(yè)可靠性質(zhì)量提升典型案例
卓越領(lǐng)航!廣和通獲評“2023高質(zhì)量發(fā)展領(lǐng)軍企業(yè)”

- 設(shè)計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設(shè)備
- 機器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計資源
- 設(shè)計技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗
- 設(shè)計大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號手機智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論