") 數據庫優(yōu)化那些事
數據庫優(yōu)化那些事
我們出去面試經常會被問到數據庫這一塊,而涉及數據庫這一塊問的最多的就是數據庫優(yōu)化。那么我們怎么做才能做好優(yōu)化問題呢?今天我們就來聊聊數據庫優(yōu)化那些事。
數據庫優(yōu)化我們一般可以從以下幾個方面考慮:
- 數據庫
- 表設計
- sql語句優(yōu)化
數據庫
大型項目拆分為小項目,每個項目有自己獨立的數據庫
原來所有數據表都放在一個數據庫節(jié)點上,所有的讀寫請求也都發(fā)到這個MySQL上面,所以數據庫的負載太高。如果把一個節(jié)點的數據庫拆分成多個MySQL數據庫,這樣就可以有效的降低每個MySQL數據庫的負載。
分表分庫(取模分表、水平分表、垂直分表)
通過取模算法進行水平分表,例如總共有3張表, 1%3=1 放入第一張表,2%3=2,放入低二張表,3%3=0 放入第0張表,相當于用幾張表來平分一張表,最好的做法是一張主表,再來幾張字表。因為分表不好做分頁,數據存放在多張表中,所以需要一張主表用來存放所有的數據,當子表無法滿足時采用主表。
讀寫分離
把對數據庫的讀寫操作分到不同的數據庫服務上,以實現(xiàn)數據庫的高性能和高并發(fā)能力;讀寫分離最大的弊端就是復制延遲,對于以查詢?yōu)橹鞯捻椖勘容^合適,看項目進行取舍。
表設計
數據庫表設計遵循三范式
- 第一范式:原子約束,每列不能再分
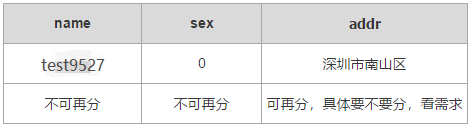
- 第二范式:每張表只描述一件事情,就是主鍵就對應著所有信息。
- 第三范式:要保證表中的數據和主鍵直接相關,而不是間接相關。
比如訂單表中出現(xiàn)了快遞的屬性(快遞單號,收件人姓名、收貨地址),可以把收件人姓名和收貨地址提出來單獨放到一張表,只留快遞單號在訂單表中作為關聯(lián)。并不是所有的表設計都必須按照三大范式設計,具體需要根據需求來定
表字段設計
盡量設計成not null,盡量使用數字型字段(如性別,男:1 女:2),若只含數值信息的字段盡量不要設計為字符型,這會降低查詢和連接的性能,并會增加存儲開銷,字段長度設計合理,比如郵編,只需要位長度,沒必要過長,
用varchar/nvarchar 代替 char/nchar
因為首先變長字段存儲空間小,可以節(jié)省存儲空間,其次對于查詢來說,在一個相對較小的字段內搜索效率顯然要高些。不要以為 NULL 不需要空間,比如:char(100) 型,在字段建立時,空間就固定了, 不管是否插入值(NULL也包含在內),都是占用 100個字符的空間的,如果是varchar這樣的變長字段, null 不占用空間。
sql語句優(yōu)化
- 最大化使用索引,合理的創(chuàng)建索引情況下,最大化使用索引
- 減少數據訪問:設置合理的字段類型
- 返回更少的數據:只返回需要的字段和數據分頁處理
- 減少交互次數:批量DML操作,函數存儲等減少數據連接次數
- 盡量減少數據庫排序操作以及全表查詢
sql語句優(yōu)化的時候首先,我們需要定位有沒有慢查詢 慢查詢 ,顧名思義,執(zhí)行很慢的查詢。有多慢?超過long_query_time參數設定的時間閾值(默認10s)慢查詢基本配置
- slow_query_log 啟動停止技術慢查詢日志
- slow_query_log_file 指定慢查詢日志得存儲路徑及文件(默認和數據文件放一起)
- long_query_time 指定記錄慢查詢日志SQL執(zhí)行時間得伐值(單位:秒,默認10秒)
- log_queries_not_using_indexes 是否記錄未使用索引的SQL
- log_output 日志存放的地方【TABLE】【FILE】【FILE,TABLE】
mysql5.7以上的版本,在my.ini中配置慢查詢配置
# 啟動慢查詢日志
slow_query_log = ON
# 慢查詢日志存放地方
slow_query_log_file = D:softwaremysqlmysql-5.7.24-winx64datalogsshow.log
# 設置慢查詢時間,默認10秒,我們此處設置為1秒,也就是超過1秒就是慢查詢
long_query_time = 1
通過下面命令查看下上面的配置:
- show VARIABLES like '%slow_query_log%'
- show VARIABLES like '%slow_query_log_file%'
- show VARIABLES like '%long_query_time%'
- show VARIABLES like '%log_queries_not_using_indexes%'
- show VARIABLES like 'log_output'
- set global long_query_time=1; -- 默認10秒,這里為了演示方便設置為1
- set GLOBAL slow_query_log = 1; -- 開啟慢查詢日志
- set global log_output='FILE' -- 項目開發(fā)中日志只能記錄在日志文件中,不能記表中
例如現(xiàn)在我執(zhí)行 select sleep(2) 沉睡兩秒,超過我設置慢查詢時間1秒,就會會被記錄到慢查詢日志中如下
 有查詢時間,以及慢查詢語句,當我們知道慢查詢語句了我們就可以針對性優(yōu)化sql了。而針對sql的優(yōu)化最多的就是添加索引了
有查詢時間,以及慢查詢語句,當我們知道慢查詢語句了我們就可以針對性優(yōu)化sql了。而針對sql的優(yōu)化最多的就是添加索引了
索引
索引用來快速地尋找那些具有特定值的記錄,所有MySQL索引都以B-樹的形式保存。如果沒有索引,執(zhí)行查詢時MySQL必須從第一個記錄開始掃描整個表的所有記錄,直至找到符合要求的記錄。表里面的記錄數量越多,這個操作的代價就越高。如果作為搜索條件的列上已經創(chuàng)建了索引,MySQL無需掃描任何記錄即可迅速得到目標記錄所在的位置。
索引原理 :折半查找,減少全表掃描,索引文件中是一個B_tree ,索引的最大查找數為2^n次方,查找數獨比較快
我們可以使用explain分析SQL的執(zhí)行計劃。該執(zhí)行計劃可以模擬SQL優(yōu)化器執(zhí)行SQL語句,可以幫助我們了解到自己編寫SQL是否有用到索引。1)查看執(zhí)行計劃 語法:explain + SQL語句 eg:explain select * from tb;

id :編號
select_type :查詢類型
table :表
type :類型
possible_keys :預測用到的索引
key :實際使用的索引
key_len :實際使用索引的長度
ref :表之間的引用
rows :通過索引查詢到的數據量
Extra :額外的信息
創(chuàng)建索引 create index index_name on table_name(colum_name...);
索引使用注意事項
- 索引加在常使用字段上,主鍵除外,主鍵自帶唯一索引,例如商品表查詢名字和價格比較多的情況,就在這兩個字段上加索引
- 盡量避免使用子查詢,用關聯(lián)查詢替代
select t1.name,(select sex from user u1 where u1.user_id = t1.user_id) as sex from userInfo t1
改成
select t1.name,u1.sex from userInfo left join user u1 on u1.user_id = t1.user_id;
- 用in來替換or ,且含In的范圍查詢,放到where條件的最后,防止索引失效。select * from ep_product where channel_id = 1 or channel_id = 2 改成 select * from ep_product where channel_id in(1,2)
- 盡量不要使用or,否則索引失效
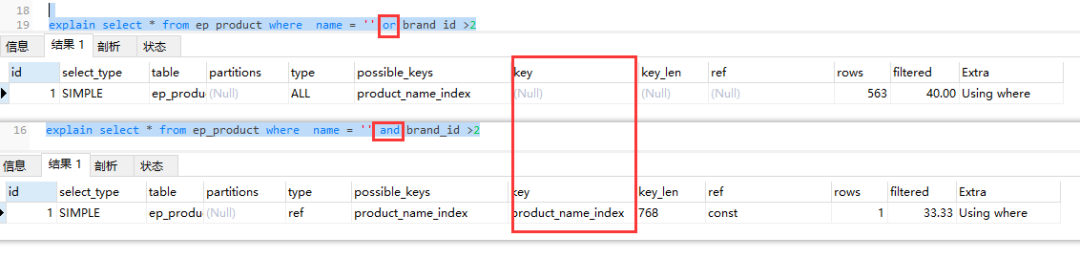
- 不要使用like "%%",會全表掃描,但是可以使用 like "_%",不以%開頭,會使用到索引進行查找 使用"%%"
 使用"_%"
使用"_%"

- 判斷是否為null不能用=,要用is null ,=null 不會使用索引,is null會使用索引


- 避免數據類型不一致,如果設置的是int類型,條件最好是傳入int類型,如果傳入String類型數據庫會先做轉換在執(zhí)行sql
select * from product where id = "1"
select * from product where id = 1
- 最好不要給數據庫留 NULL,盡可能的使用 NOT NULL 填充數據庫,可以在 name 上設置默認值 0,確保表中 name 列沒有 null 值,然后這樣查詢:
select id from t where name = 0
- 分組的時候需要效率比較高就禁止使用排序、在group by 后面加上order by null
select channel_id,count(*) from ep_product GROUP BY channel_id
改成
select channel_id,count(*) from ep_product GROUP BY channel_id order by null
- 應盡量避免在 where 子句中對字段進行表達式操作,這將導致引擎放棄使用索引而進行全表掃描。
select * from product where sell_price/2 = 100
改成
select * from product where sell_price = 100*2
- 在使用索引字段作為條件時,如果該索引是復合索引,那么必須使用到該索引中的第一個字段作為條件時才能保證系統(tǒng)使用該索引,否則該索引將不會被使用,并且應盡可能的讓字段順序與索引順序相一致。
- 復合索引,不要跨列或無序使用(左匹配原則)
- 復合索引,盡量使用全索引匹配,也就是說,你建立幾個索引,就使用幾個索引
- Update 語句,如果只更改1、2個字段,不要Update全部字段,否則頻繁調用會引起明顯的性能消耗,同時帶來大量日志
- 左關聯(lián)查詢,左表加索引,有關聯(lián)查詢,右表加索引
- 索引并不是越多越好,索引固然可以提高相應的 select 的效率,但同時也降低了 insert 及 update 的效率,因為 insert 或 update 時有可能會重建索引,所以怎樣建索引需要慎重考慮,視具體情況而定。
其他注意事項
- 避免出現(xiàn)select *
- 關聯(lián)查詢的表最好不超過3張,數據庫的性能更加重要,適當考慮規(guī)范性就好
- 多表關聯(lián)查詢時,小表在前,大表在后。
- 新增多條數據是避免使用
insert into user values(1,"張三");
insert into user values(2,"李四");
使用以下方式可以減少語句解析的操作
insert into user values(1,"張三"),(2,"李四");
-
數據庫
+關注
關注
7文章
3767瀏覽量
64279 -
函數
+關注
關注
3文章
4308瀏覽量
62444 -
MySQL
+關注
關注
1文章
802瀏覽量
26452 -
日志
+關注
關注
0文章
138瀏覽量
10633
發(fā)布評論請先 登錄
相關推薦
數據庫SQL的優(yōu)化
基于數據庫查詢過程優(yōu)化設計
如何優(yōu)化數據庫負載
提高Oracle的數據庫性能
醫(yī)院SQL數據庫系統(tǒng)語句優(yōu)化
基于Greenplum數據庫的查詢優(yōu)化
數據庫教程之如何進行數據庫設計
數據庫系統(tǒng)概論之如何進行關系查詢處理和查詢優(yōu)化
云數據庫和自建數據庫的區(qū)別及應用
數據庫索引使用策略及優(yōu)化






 工商網監(jiān)
工商網監(jiān)
評論