 Redis為何選擇單線程
Redis為何選擇單線程
Redis為何選擇單線程?
在Redisv6.0以前,Redis的核心網絡模型選擇用單線程來實現。
核心意思就是,對于一個 DB 來說,CPU 通常不會是瓶頸,因為大多數請求不會是 CPU 密集型的,而是 I/O 密集型。
具體到 Redis的話,如果不考慮 RDB/AOF 等持久化方案,Redis是完全的純內存操作,執行速度是非常快的,因此這部分操作通常不會是性能瓶頸,Redis真正的性能瓶頸在于網絡 I/O,也就是客戶端和服務端之間的網絡傳輸延遲,因此 Redis選擇了單線程的 I/O 多路復用來實現它的核心網絡模型。
實際上更加具體的選擇單線程的原因如下:
避免過多的上下文切換開銷:如果是單線程則可以規避進程內頻繁的線程切換開銷,因為程序始終運行在進程中單個線程內,沒有多線程切換的場景。
避免同步機制的開銷:如果 Redis選擇多線程模型,又因為 Redis是一個數據庫,那么勢必涉及到底層數據同步的問題,則必然會引入某些同步機制,比如鎖,而我們知道 Redis不僅僅提供了簡單的 key-value 數據結構,還有 list、set 和 hash 等等其他豐富的數據結構,而不同的數據結構對同步訪問的加鎖粒度又不盡相同,可能會導致在操作數據過程中帶來很多加鎖解鎖的開銷,增加程序復雜度的同時還會降低性能。
簡單可維護:如果 Redis使用多線程模式,那么所有的底層數據結構都必須實現成線程安全的,這無疑又使得 Redis的實現變得更加復雜。
總而言之,Redis選擇單線程可以說是多方博弈之后的一種權衡:在保證足夠的性能表現之下,使用單線程保持代碼的簡單和可維護性。
Redis真的是單線程?
討論 這個問題前,先看下 Redis的版本中兩個重要的節點:
Redis 4.0(引入多線程處理異步任務)
Redis 6.0(正式在網絡模型中實現 I/O 多線程)
所以,網絡上說的Redis是單線程,通常是指在Redis 6.0之前,其核心網絡模型使用的是單線程;而Redis的異步任務使用的仍是多線程。
Redis在 4.0 版本的時候就已經引入了的多線程來做一些異步操作,此舉主要針對的是那些非常耗時的命令,通過將這些命令的執行進行異步化,避免阻塞單線程的事件循環。
在 Redis 4.0 之后增加了一些的非阻塞命令如 UNLINK、FLUSHALL ASYNC、FLUSHDB ASYNC。
Redisv6.0為何引入多線程?
很簡單,就是 Redis的網絡 I/O 瓶頸已經越來越明顯了。
隨著互聯網的飛速發展,互聯網業務系統所要處理的線上流量越來越大,Redis的單線程模式會導致系統消耗很多 CPU 時間在網絡 I/O 上從而降低吞吐量,要提升 Redis的性能有兩個方向:
優化網絡 I/O 模塊
提高機器內存讀寫的速度
后者依賴于硬件的發展,暫時無解。所以只能從前者下手,網絡 I/O 的優化又可以分為兩個方向:
零拷貝技術或者 DPDK 技術
利用多核優勢
零拷貝技術有其局限性,無法完全適配 Redis這一類復雜的網絡 I/O 場景,更多網絡 I/O 對 CPU 時間的消耗和 Linux 零拷貝技術。而 DPDK 技術通過旁路網卡 I/O 繞過內核協議棧的方式又太過于復雜以及需要內核甚至是硬件的支持。
因此,利用多核優勢成為了優化網絡 I/O 性價比最高的方案。
-
網絡
+關注
關注
14文章
7514瀏覽量
88626 -
線程
+關注
關注
0文章
504瀏覽量
19651 -
Redis
+關注
關注
0文章
371瀏覽量
10846
發布評論請先 登錄
相關推薦

單線程SRAM靜態內存使用
一種單線程編程思路簡析
多線程好還是單線程好?單線程和多線程的區別 優缺點分析
從I/O的阻塞與非阻塞、I/O處理的單線程與多線程角度探討服務器模型
阿里云Redis多線程性能提升思路解析
實現Java多線程爬蟲的兩點
這款16核怪物在單線程和多線程性能方面均躍居主流處理器榜首
Redis常見面試題及答案
單線程也能開發異步任務?ACE JS框架到底是如何做到的
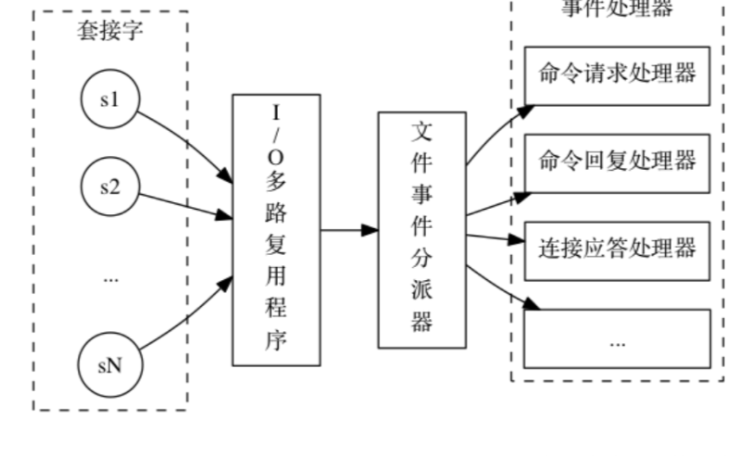
Redis基礎架構設計及核心網絡模型架構演進
單線程是否會引起 fail-fast機制
Go在單線程計算性能上的優勢





 工商網監
工商網監
評論