 高并發場景下請求合并
高并發場景下請求合并
前言
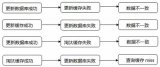
請求合并到底有什么意義呢?我們來看下圖。
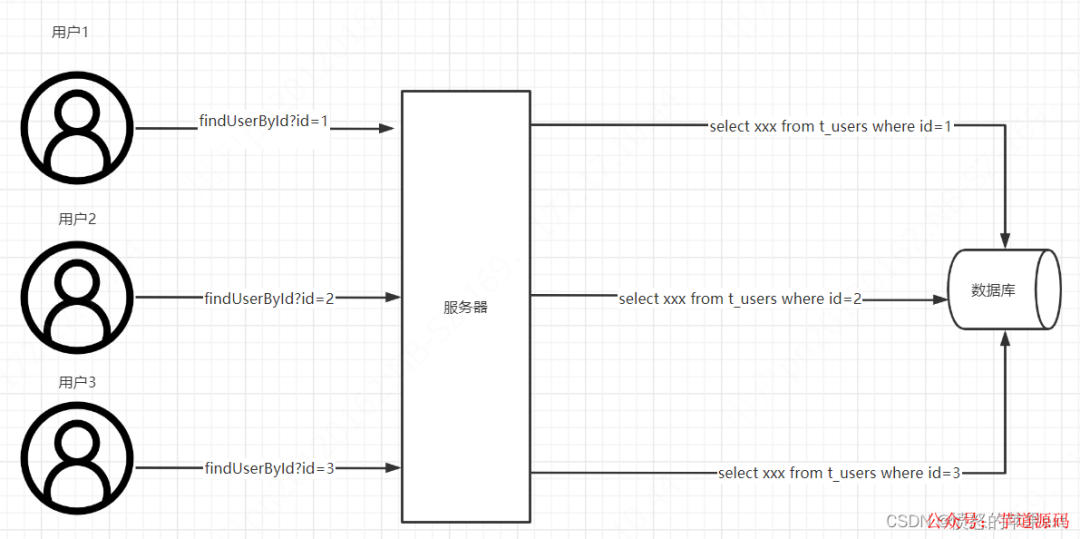
假設我們3個用戶(用戶id分別是1、2、3),現在他們都要查詢自己的基本信息,請求到服務器,服務器端請求數據庫,發出3次請求。我們都知道數據庫連接資源是相當寶貴的,那么我們怎么盡可能節省連接資源呢?
這里把數據庫換成被調用的遠程服務,也是同樣的道理。
我們改變下思路,如下圖所示。
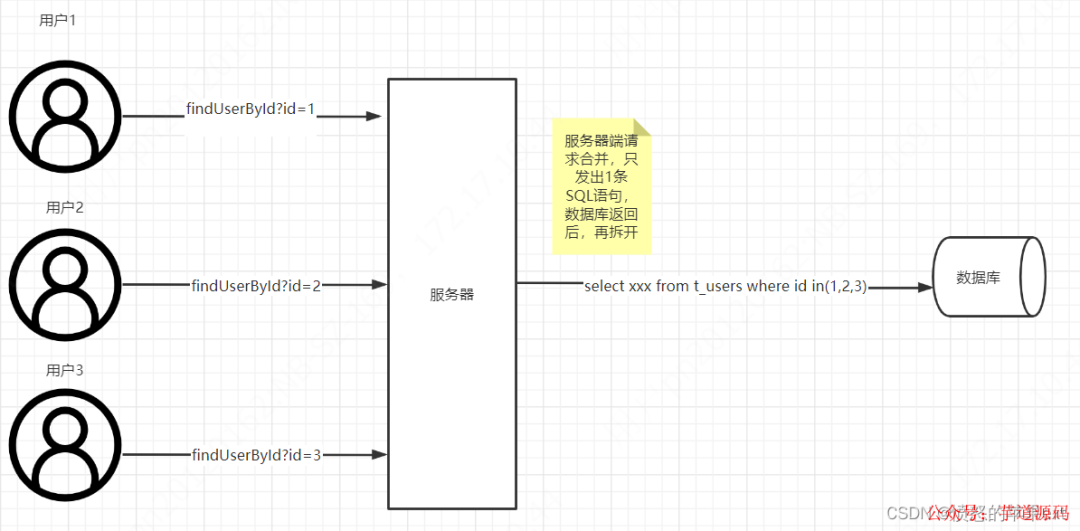
我們在服務器端把請求合并,只發出一條SQL查詢數據庫,數據庫返回后,服務器端處理返回數據,根據一個唯一請求ID,把數據分組,返回給對應用戶。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
- 項目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 視頻教程:https://doc.iocoder.cn/video/
技術手段
-
LinkedBlockQueue阻塞隊列 -
ScheduledThreadPoolExecutor定時任務線程池 -
CompleteableFuture future阻塞機制(Java 8 的 CompletableFuture 并沒有 timeout 機制,后面優化,使用了隊列替代)
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
代碼實現
查詢用戶的代碼
publicinterfaceUserService{
MapqueryUserByIdBatch(ListuserReqs) ;
}
@Service
publicclassUserServiceImplimplementsUserService{
@Resource
privateUsersMapperusersMapper;
@Override
publicMapqueryUserByIdBatch(ListuserReqs) {
//全部參數
ListuserIds=userReqs.stream().map(UserWrapBatchService.Request::getUserId).collect(Collectors.toList());
QueryWrapperqueryWrapper=newQueryWrapper<>();
//用in語句合并成一條SQL,避免多次請求數據庫的IO
queryWrapper.in("id",userIds);
Listusers=usersMapper.selectList(queryWrapper);
Map>userGroup=users.stream().collect(Collectors.groupingBy(Users::getId));
HashMapresult=newHashMap<>();
userReqs.forEach(val->{
ListusersList=userGroup.get(val.getUserId());
if(!CollectionUtils.isEmpty(usersList)){
result.put(val.getRequestId(),usersList.get(0));
}else{
//表示沒數據
result.put(val.getRequestId(),null);
}
});
returnresult;
}
}
合并請求的實現
packagecom.springboot.sample.service.impl;
importcom.springboot.sample.bean.Users;
importcom.springboot.sample.service.UserService;
importorg.springframework.stereotype.Service;
importjavax.annotation.PostConstruct;
importjavax.annotation.Resource;
importjava.util.*;
importjava.util.concurrent.*;
/***
*zzq
*包裝成批量執行的地方
**/
@Service
publicclassUserWrapBatchService{
@Resource
privateUserServiceuserService;
/**
*最大任務數
**/
publicstaticintMAX_TASK_NUM=100;
/**
*請求類,code為查詢的共同特征,例如查詢商品,通過不同id的來區分
*CompletableFuture將處理結果返回
*/
publicclassRequest{
//請求id唯一
StringrequestId;
//參數
LonguserId;
//TODOJava8的CompletableFuture并沒有timeout機制
CompletableFuturecompletableFuture;
publicStringgetRequestId(){
returnrequestId;
}
publicvoidsetRequestId(StringrequestId){
this.requestId=requestId;
}
publicLonggetUserId(){
returnuserId;
}
publicvoidsetUserId(LonguserId){
this.userId=userId;
}
publicCompletableFuturegetCompletableFuture(){
returncompletableFuture;
}
publicvoidsetCompletableFuture(CompletableFuturecompletableFuture){
this.completableFuture=completableFuture;
}
}
/*
LinkedBlockingQueue是一個阻塞的隊列,內部采用鏈表的結果,通過兩個ReenTrantLock來保證線程安全
LinkedBlockingQueue與ArrayBlockingQueue的區別
ArrayBlockingQueue默認指定了長度,而LinkedBlockingQueue的默認長度是Integer.MAX_VALUE,也就是無界隊列,在移除的速度小于添加的速度時,容易造成OOM。
ArrayBlockingQueue的存儲容器是數組,而LinkedBlockingQueue是存儲容器是鏈表
兩者的實現隊列添加或移除的鎖不一樣,ArrayBlockingQueue實現的隊列中的鎖是沒有分離的,即添加操作和移除操作采用的同一個ReenterLock鎖,
而LinkedBlockingQueue實現的隊列中的鎖是分離的,其添加采用的是putLock,移除采用的則是takeLock,這樣能大大提高隊列的吞吐量,
也意味著在高并發的情況下生產者和消費者可以并行地操作隊列中的數據,以此來提高整個隊列的并發性能。
*/
privatefinalQueuequeue=newLinkedBlockingQueue();
@PostConstruct
publicvoidinit(){
//定時任務線程池,創建一個支持定時、周期性或延時任務的限定線程數目(這里傳入的是1)的線程池
ScheduledExecutorServicescheduledExecutorService=Executors.newScheduledThreadPool(1);
scheduledExecutorService.scheduleAtFixedRate(()->{
intsize=queue.size();
//如果隊列沒數據,表示這段時間沒有請求,直接返回
if(size==0){
return;
}
Listlist=newArrayList<>();
System.out.println("合并了["+size+"]個請求");
//將隊列的請求消費到一個集合保存
for(inti=0;i//后面的SQL語句是有長度限制的,所以還要做限制每次批量的數量,超過最大任務數,等下次執行
if(i//拿到我們需要去數據庫查詢的特征,保存為集合
ListuserReqs=newArrayList<>();
for(Requestrequest:list){
userReqs.add(request);
}
//將參數傳入service處理,這里是本地服務,也可以把userService看成RPC之類的遠程調用
Mapresponse=userService.queryUserByIdBatch(userReqs);
//將處理結果返回各自的請求
for(Requestrequest:list){
Usersresult=response.get(request.requestId);
request.completableFuture.complete(result);//completableFuture.complete方法完成賦值,這一步執行完畢,下面future.get()阻塞的請求可以繼續執行了
}
},100,10,TimeUnit.MILLISECONDS);
//scheduleAtFixedRate是周期性執行schedule是延遲執行initialDelay是初始延遲period是周期間隔后面是單位
//這里我寫的是初始化后100毫秒后執行,周期性執行10毫秒執行一次
}
publicUsersqueryUser(LonguserId){
Requestrequest=newRequest();
//這里用UUID做請求id
request.requestId=UUID.randomUUID().toString().replace("-","");
request.userId=userId;
CompletableFuturefuture=newCompletableFuture<>();
request.completableFuture=future;
//將對象傳入隊列
queue.offer(request);
//如果這時候沒完成賦值,那么就會阻塞,直到能夠拿到值
try{
returnfuture.get();
}catch(InterruptedExceptione){
e.printStackTrace();
}catch(ExecutionExceptione){
e.printStackTrace();
}
returnnull;
}
}
控制層調用
/***
*請求合并
**/
@RequestMapping("/merge")
publicCallablemerge(LonguserId) {
returnnewCallable(){
@Override
publicUserscall()throwsException{
returnuserBatchService.queryUser(userId);
}
};
}
Callable是什么可以參考:
- https://blog.csdn.net/baidu_19473529/article/details/123596792
模擬高并發查詢的代碼
packagecom.springboot.sample;
importorg.springframework.web.client.RestTemplate;
importjava.util.Random;
importjava.util.concurrent.CountDownLatch;
publicclassTestBatch{
privatestaticintthreadCount=30;
privatefinalstaticCountDownLatchCOUNT_DOWN_LATCH=newCountDownLatch(threadCount);//為保證30個線程同時并發運行
privatestaticfinalRestTemplaterestTemplate=newRestTemplate();
publicstaticvoidmain(String[]args){
for(inti=0;i//循環開30個線程
newThread(newRunnable(){
publicvoidrun(){
COUNT_DOWN_LATCH.countDown();//每次減一
try{
COUNT_DOWN_LATCH.await();//此處等待狀態,為了讓30個線程同時進行
}catch(InterruptedExceptione){
e.printStackTrace();
}
for(intj=1;j<=?3;j++){
intparam=newRandom().nextInt(4);
if(param<=0){
param++;
}
StringresponseBody=restTemplate.getForObject("http://localhost:8080/asyncAndMerge/merge?userId="+param,String.class);
System.out.println(Thread.currentThread().getName()+"參數"+param+"返回值"+responseBody);
}
}
}).start();
}
}
}
測試效果
要注意的問題
- Java 8 的 CompletableFuture 并沒有 timeout 機制
- 后面的SQL語句是有長度限制的,所以還要做限制每次批量的數量,超過最大任務數,等下次執行(本例中加了MAX_TASK_NUM判斷)
使用隊列的超時解決Java 8 的 CompletableFuture 并沒有 timeout 機制
核心代碼
packagecom.springboot.sample.service.impl;
importcom.springboot.sample.bean.Users;
importcom.springboot.sample.service.UserService;
importorg.springframework.stereotype.Service;
importjavax.annotation.PostConstruct;
importjavax.annotation.Resource;
importjava.util.*;
importjava.util.concurrent.*;
/***
*zzq
*包裝成批量執行的地方,使用queue解決超時問題
**/
@Service
publicclassUserWrapBatchQueueService{
@Resource
privateUserServiceuserService;
/**
*最大任務數
**/
publicstaticintMAX_TASK_NUM=100;
/**
*請求類,code為查詢的共同特征,例如查詢商品,通過不同id的來區分
*CompletableFuture將處理結果返回
*/
publicclassRequest{
//請求id
StringrequestId;
//參數
LonguserId;
//隊列,這個有超時機制
LinkedBlockingQueueusersQueue;
publicStringgetRequestId(){
returnrequestId;
}
publicvoidsetRequestId(StringrequestId){
this.requestId=requestId;
}
publicLonggetUserId(){
returnuserId;
}
publicvoidsetUserId(LonguserId){
this.userId=userId;
}
publicLinkedBlockingQueuegetUsersQueue() {
returnusersQueue;
}
publicvoidsetUsersQueue(LinkedBlockingQueueusersQueue) {
this.usersQueue=usersQueue;
}
}
/*
LinkedBlockingQueue是一個阻塞的隊列,內部采用鏈表的結果,通過兩個ReenTrantLock來保證線程安全
LinkedBlockingQueue與ArrayBlockingQueue的區別
ArrayBlockingQueue默認指定了長度,而LinkedBlockingQueue的默認長度是Integer.MAX_VALUE,也就是無界隊列,在移除的速度小于添加的速度時,容易造成OOM。
ArrayBlockingQueue的存儲容器是數組,而LinkedBlockingQueue是存儲容器是鏈表
兩者的實現隊列添加或移除的鎖不一樣,ArrayBlockingQueue實現的隊列中的鎖是沒有分離的,即添加操作和移除操作采用的同一個ReenterLock鎖,
而LinkedBlockingQueue實現的隊列中的鎖是分離的,其添加采用的是putLock,移除采用的則是takeLock,這樣能大大提高隊列的吞吐量,
也意味著在高并發的情況下生產者和消費者可以并行地操作隊列中的數據,以此來提高整個隊列的并發性能。
*/
privatefinalQueuequeue=newLinkedBlockingQueue();
@PostConstruct
publicvoidinit(){
//定時任務線程池,創建一個支持定時、周期性或延時任務的限定線程數目(這里傳入的是1)的線程池
ScheduledExecutorServicescheduledExecutorService=Executors.newScheduledThreadPool(1);
scheduledExecutorService.scheduleAtFixedRate(()->{
intsize=queue.size();
//如果隊列沒數據,表示這段時間沒有請求,直接返回
if(size==0){
return;
}
Listlist=newArrayList<>();
System.out.println("合并了["+size+"]個請求");
//將隊列的請求消費到一個集合保存
for(inti=0;i//后面的SQL語句是有長度限制的,所以還要做限制每次批量的數量,超過最大任務數,等下次執行
if(i//拿到我們需要去數據庫查詢的特征,保存為集合
ListuserReqs=newArrayList<>();
for(Requestrequest:list){
userReqs.add(request);
}
//將參數傳入service處理,這里是本地服務,也可以把userService看成RPC之類的遠程調用
Mapresponse=userService.queryUserByIdBatchQueue(userReqs);
for(RequestuserReq:userReqs){
//這里再把結果放到隊列里
Usersusers=response.get(userReq.getRequestId());
userReq.usersQueue.offer(users);
}
},100,10,TimeUnit.MILLISECONDS);
//scheduleAtFixedRate是周期性執行schedule是延遲執行initialDelay是初始延遲period是周期間隔后面是單位
//這里我寫的是初始化后100毫秒后執行,周期性執行10毫秒執行一次
}
publicUsersqueryUser(LonguserId){
Requestrequest=newRequest();
//這里用UUID做請求id
request.requestId=UUID.randomUUID().toString().replace("-","");
request.userId=userId;
LinkedBlockingQueueusersQueue=newLinkedBlockingQueue<>();
request.usersQueue=usersQueue;
//將對象傳入隊列
queue.offer(request);
//取出元素時,如果隊列為空,給定阻塞多少毫秒再隊列取值,這里是3秒
try{
returnusersQueue.poll(3000,TimeUnit.MILLISECONDS);
}catch(InterruptedExceptione){
e.printStackTrace();
}
returnnull;
}
}
...省略..
@Override
publicMapqueryUserByIdBatchQueue(ListuserReqs) {
//全部參數
ListuserIds=userReqs.stream().map(UserWrapBatchQueueService.Request::getUserId).collect(Collectors.toList());
QueryWrapperqueryWrapper=newQueryWrapper<>();
//用in語句合并成一條SQL,避免多次請求數據庫的IO
queryWrapper.in("id",userIds);
Listusers=usersMapper.selectList(queryWrapper);
Map>userGroup=users.stream().collect(Collectors.groupingBy(Users::getId));
HashMapresult=newHashMap<>();
//數據分組
userReqs.forEach(val->{
ListusersList=userGroup.get(val.getUserId());
if(!CollectionUtils.isEmpty(usersList)){
result.put(val.getRequestId(),usersList.get(0));
}else{
//表示沒數據,這里要new,不然加入隊列會空指針
result.put(val.getRequestId(),newUsers());
}
});
returnresult;
}
...省略...
小結
請求合并,批量的辦法能大幅節省被調用系統的連接資源,本例是以數據庫為例,其他RPC調用也是類似的道理。缺點就是請求的時間在執行實際的邏輯之前增加了等待時間,不適合低并發的場景。
代碼地址
- https://gitee.com/apple_1030907690/spring-boot-kubernetes/tree/v1.0.5
參考
- https://www.cnblogs.com/oyjg/p/13099998.html
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
服務器
+關注
關注
12文章
9029瀏覽量
85205 -
JAVA
+關注
關注
19文章
2960瀏覽量
104562 -
數據庫
+關注
關注
7文章
3767瀏覽量
64279
原文標題:高并發場景下請求合并
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從服務端視角看高并發難題
`所謂服務器大流量高并發指的是:在同時或極短時間內,有大量的請求到達服務端,每個請求都需要服務端耗費資源進行處理,并做出相應的反饋。 從服務端視角看
發表于 11-02 15:11
如何去實現一種基于SpringMVC的電商高并發秒殺系統設計
參考博客Java高并發秒殺系統API目錄業務場景要解決的問題Redis的使用業務場景首頁倒計時秒殺活動,搶購商品要解決的問題高
發表于 01-03 07:50
P2P流媒體系統中并發請求的數據分發算法
大規模并發請求是流媒體直播系統面臨的一個挑戰,也是視頻點播系統中亟待解決的一個問題。本文針對相同數據的并發請求問題,提出了一種高效,低帶寬消耗、低延遲的數據
發表于 12-30 14:21
?14次下載
效率加倍,高并發場景下的接口請求合并方案
假設我們3個用戶(用戶id分別是1、2、3),現在他們都要查詢自己的基本信息,請求到服務器,服務器端請求數據庫,發出3次請求。我們都知道數據庫連接資源是相當寶貴的,那么我們怎么盡可能節省連接資源呢?
為什么Nginx可以支持高并發
先說答案,Nginx之所以支持高并發,是因為它是基于epoll的異步及非阻塞的事件驅動模型。 在這個模型下,Nginx服務端可以同一時間接收成千上萬個客戶端請求而不阻塞。這是因為Ngi
Linux 6.3內核的合并窗口已開啟
Linus 認為,如果你不能解釋清楚一個合并請求,那么就不要提交,這是很簡單的道理。如果不解釋提交合并請求的原因,那就是在生產垃圾。在這種情況下,Linus 覺得這種合并請求根本就不應
服務器的高并發能力如何提升?
服務器的高并發能力如何提升? 服務器高并發能力體現著服務器在單位時間內的很強數據處理能力,一般來說,如果企業的互聯網業務需要面對大量的同時在線請求
redis高并發能力直接相關概念有哪些
Redis是一種高性能的開源內存數據庫,具有出色的并發能力。為了實現高并發,需要有一些相關概念和技術。下面是關于Redis高并發能力的詳細解
什么場景需要jvm調優
JVM調優是指對Java虛擬機進行性能優化和資源管理,以提高應用程序的運行效率和吞吐量。JVM調優的場景有很多,下面將詳細介紹各種不同的場景。 高并發
高并發物聯網云平臺是什么
高并發物聯網云平臺是一種能夠處理大量設備同時連接并進行數據交換的云計算平臺。這種平臺通常被設計用來應對來自數以萬計甚至數十億計的物聯網設備的并發請求,保證系統的穩定性和響應速度。 首先





 工商網監
工商網監
評論