 Vivado那些事兒:節省編譯時間系列文章
Vivado那些事兒:節省編譯時間系列文章
編譯時間分析:
影響編譯時間的因素有很多,包括工具流程、工具設置選項、RTL 設計、約束編輯、目標器件以及設計實現期間各工具所面臨的任何關鍵問題。除此之外,所使用的機器及其負載也是關鍵因素。在這篇博客中,我們只探討與設計和工具流程有關的因素。另外值得一提的是,所述技巧并不適用于所有用戶。例如,如果某個設計由 50 個 FPGA 鏡像組成,每個鏡像含 50 個約束文件,那么在此類設計中更改約束可能不切實際。但對于單一設計運行來說,約束更改會更有意義。
此外,個別建議對某些設計的影響會比其他設計更大。例如,如果對某個并行運行 50 輪的設計應用某一項約束更改,此項更改會影響所有運行輪次。但如果在設計上只運行一輪實現,那么更改約束的影響有限。
本文中將描述每種技巧的優勢和成本,但最終須由您作為用戶來自行決定是否值得在自己的用例中實現這些技巧。
測量編譯時間:
比較約束更改前后的編譯時間時,重要的是在相似的機器上運行更改從而得到公平的比較結果。
如果這不可行,那么您可以通過比較數值變化來大致了解編譯時間變化,而不必依賴絕對數值。有多種方法可用于比較時間。
對于完整的 Vivado 運行輪次,可以在 vivado.log 文件中搜索編譯時間信息。例如,您可在其中找到如下行:
place_design: Time (s): cpu = 0334 ; elapsed = 0153 . Memory (MB): peak = 21362.934 ; gain = 3668.312 ; free physical = 12076 ; free virtual = 142273
此行包含在 place_design 階段耗費的總時間以及內存使用情況。“cpu”的時間是在 place_design 中分配有子任務的多個線程的累計時間。
值得注意的是“elapsed”耗用時間,即啟動和完成該 place_design 階段的時間差。
另外還有其他多行內容包含相同格式的時間報告,但這些行首不含命令名稱,如:
Time (s): cpu = 0050 ; elapsed = 0024 . Memory (MB): peak = 21322.859 ; gain = 3612.184 ; free physical = 42807 ; free virtual = 172805
這表示某一具體步驟中每個單獨階段耗費的時間。因此,要得到編譯總時間,只需將工程模式或非工程模式下運行的每個步驟所報告的編譯時間相加即可:
T(synth_design)+T(opt_design)+ T(place_design)+ T(phys_opt_design)+T(route_design).
請注意,工程模式需要時間來生成多個報告文件,這個時間也應該一并算上。這樣您就能清楚知曉哪個步驟在編譯總時間中耗時最多。
如要調查某一條命令而不是某個運行步驟所耗費的時間量,您可使用 Tcl 命令來跟蹤這條命令。
例如,使用以下命令即可得到運行一條 get_pins 命令的時間為 44 毫秒:
set start [clock milliseconds]; get_pins -filter {NAME =~ *FPGA*/O}; set stop [clock milliseconds] ; puts "TIME: [expr $stop -$start]"
TCL console output -> TIME: 44
set start [clock milliseconds]; get_pins -filter {NAME =~ *FPGA*/O}; set stop [clock milliseconds] ; puts "TIME: [expr $stop -$start]"TCL console output -> TIME: 44
如果您有一個含數千行命令的巨型約束文件,并且想要快速了解每條命令所耗費的時間,那么此技巧會很有幫助。
對于增量流程,可以在 log 日志文件中直接生成一個表格,計算每個步驟中默認運行和增量運行的編譯總時間,因此非常便于閱讀查看。
雖然想必您知道,在綜合或實現階段,增量運行可以從參考文件中讀取和復制信息,但僅在某些階段中能節省時間,如果網表發生大量更改,其中引用的內容就會減少,編譯時間也會受到相應影響。
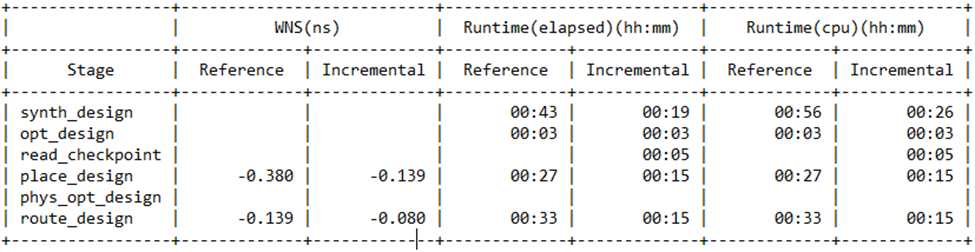
分析編譯時間:
獲得期望的編譯時間信息后,下一步是分析時間數據,決定哪個步驟影響最大,這樣即可便于您尋找解決辦法。
示例如下:
示例 1:
假設我們發現 route_design 步驟耗用的編譯時間最多。通過閱讀 log 日志報告發現,此設計的資源使用率很高導致布線擁塞,因此布線器編譯時間非常長。
因此,我們可以依靠 report_design_analysis 獲取擁塞報告,找出哪個區域或模塊導致出現此問題。我們可以據此判斷是對代碼進行最優化以獲得低擁塞的 RTL 編碼樣式,還是依靠該工具的擁塞策略來進行操作。
示例 2:
如果使用了大量 IP 或模塊,并且無需每輪都進行更新,則可考慮采用流程最優化。例如,對于在設計中進行例化的部分 IP 核,可以啟用 IP 高速緩存,以免每次都重新生成這些 IP,從而節省 IP 生成時間。
我們可以啟用自下而上的開發流程進行并行開發,這將最終節省設計實現的集成時間。也可以在完成一個流程后啟用增量流程,進行快速設計迭代,以獲取指導性文件。
根據可用于解決編譯時間問題的 2 種不同方法,以下內容分為 2 部分。
解決設計存在的具體編譯時間問題:
下列技巧可用于解決設計的具體編譯時間問題,這些技巧根據常見問題根源和解決方案可分為 4 類:
約束
增量實現
工具驅動的選項
使用非關聯運行
約束:
設計中包含清晰、合理且精確的約束有助于有效利用系統存儲器,從而減少整體編譯時間。我們需要分析在約束上耗費的編譯時間,了解這些編譯時間的具體分配,并改進約束語法以提高其效率。欲知詳情,請參閱博文利用高效約束節省編譯時間開發者分享|節省編譯時間系列-利用 Tcl 腳本對編譯時間進行剖析及其中隨附的示例。
增量流程
增量綜合流程開發者分享|節省編譯時間系列-使用增量綜合與增量實現流程開發者分享|節省編譯時間系列-使用增量實現都是非常直接且易于管理的方法,能夠達成最大輸出。當設計更改率極低時,您可基于成功的運行輪次快速迭代,這樣還能生成一致性和可預測性更高的結果,從而幫助節省編譯時間。請單擊鏈接查看這兩篇博文,其中提供了采用流程需滿足的一些先決條件,以及有關如何理解報告的信息。
工具和報告選項
工具驅動的選項有助于最大限度減少特定設計問題,如,設計 DRC 問題、不適當的時序約束覆蓋或設計擁塞,這類問題可能嚴重影響編譯時間,應先一探究竟,而后再執行任何其他工具最優化操作。我們可以憑借 Vivado 報告工具來生成報告并執行分析。
運行 report_methodology 解決設計方法論問題。報告中指出的一些不良措施可能會影響編譯時間,您可先從報告中輕松獲取修訂,然后再開始下一輪運行。
運行 report_design_anlaysis 解決時序、復雜性、擁塞等問題。通過讀取頂層關鍵路徑、設計復雜性 Rent 指數和設計布局熱點,可幫助您更好地了解設計中的瓶頸。此報告可以提供一些簡單的構想,幫助您尋找解決方案。
運行 report_qor_suggestions 通過低級別 Tcl 腳本獲取其他建議,然后可以將這些建議直接應用于設計。
運行 report_exceptions 獲取有關時序交互和覆蓋的信息。如果錯誤設置時序約束導致時序過緊,就可能會導致編譯時間延長。
非關聯運行/塊級綜合
在非關聯模式下運行設計核會生成并行子運行,這意味著能縮短設計集成時間,塊級綜合也可以為不同的子模塊定義不同的編譯時間或性能策略。它也能縮短集成時間,從而減少編譯總時間。
如需跨多個設計縮短編譯時間,就要基于設計結果來應用一些更為通用的方法并進行迭代。這些技巧分為以下 2 類。
Vivado 自動建議的流程和約束:
從 2019.1 版本起,Vivado 啟用了全新的功能特性,能以 Tcl 格式提供多項自動生成的策略,后續可通過 source 命令直接使用。
這有助于縮短清掃策略的周期,并且很容易找到一些編譯時間/性能平衡的最佳策略,且無需手動執行并行清掃所有設計的工作。
在 report_qor_suggestion 中啟用該功能特性。
清掃實現指令
分析了如何從現有策略中選擇以編譯時間為目標的指令,并提供了一些建議,以便于您定義自己的編譯時間縮短策略。
總結:
利用上述技巧時,我們認為應分析編譯總時間,限定范圍以便查找最優化方法并最終縮短編譯總時間。
-
FPGA
+關注
關注
1626文章
21665瀏覽量
601805 -
編譯
+關注
關注
0文章
653瀏覽量
32806 -
Vivado
+關注
關注
19文章
808瀏覽量
66322
原文標題:【Vivado那些事兒】節省編譯時間系列文章
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Vivado中的Incremental Compile增量編譯技術詳解



講述增量編譯方法,提高Vivado編譯效率
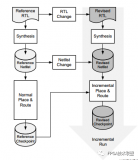

淺談Vivado編譯時間





 工商網監
工商網監
評論