 Continuous Batching:解鎖LLM潛力!讓LLM推斷速度飆升23倍,降低延遲!
Continuous Batching:解鎖LLM潛力!讓LLM推斷速度飆升23倍,降低延遲!
本文介紹一篇 LLM 推理加速技術相關的文章,值得讀一讀。
LLMs 在現實應用中的計算成本主要由服務成本所主導,但是傳統的批處理策略存在低效性。在這篇文章中,我們將告訴你,為什么 Continuous Batching 連續批處理成為了解決這一問題的新方法,而不再把 LLMs 視為“黑匣子”。這個技術如何利用內存,而不是計算能力,來實現 10 倍以上的性能提升,將改變AI領域的游戲規則。文章標題:
How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
文章鏈接:https://www.anyscale.com/blog/continuous-batching-llm-inference

Section 1
為了更好地理解這篇文章,讓我們先了解一下大型語言模型(LLM)的推斷過程以及傳統批處理策略中存在的低效性。
Q1. 你能解釋一下什么是大型語言模型(LLM)的推斷過程嗎?以及在傳統批處理策略中存在的哪些低效性?
當我們談論大型語言模型(LLM)的推斷過程時,我們指的是使用已經訓練好的模型來對輸入文本進行處理,從而生成相應的輸出。推斷過程涉及將一個或多個文本片段傳遞給模型,并從模型中獲取相應的預測或生成的文本。 在傳統的批處理策略中,文本通常會被分成小批次(batch)進行處理,以便在 GPU 或其他硬件上進行并行計算。然而,由于 LLMs 通常需要大量的內存和計算資源,傳統的批處理策略可能會導致一些低效性:
- 內存消耗高:傳統批處理策略可能會導致大量的 GPU 內存被占用,限制了可以同時處理的文本量。
- 計算資源未被充分利用:由于內存限制,傳統批處理策略可能導致 GPU 計算資源未被充分利用,從而降低了推斷效率。
- 高延遲:由于大型模型的計算需求,傳統批處理策略可能會導致高延遲,使得生成結果的響應速度變慢。
-
難以處理長文本:傳統批處理策略可能會限制模型處理長文本的能力,因為它們可能無法一次性將整個文本載入內存。
Q2. 為什么傳統的處理方法可能會導致在實際應用中服務成為大多數情況下的計算成本主導因素?
傳統的處理方法將 LLMs 視為“黑匣子”,主要通過內部更改(如量化和自定義 CUDA 內核)來進行優化。這種方法忽視了 LLMs 在推斷過程中生成輸出的迭代性質,以及 LLM 推斷通常受限于內存而不是計算資源。由于 LLMs 通常需要大量的 GPU 內存和計算成本,這導致在實際應用中,服務成為計算成本的主導因素。 因為 LLMs 在推斷過程中需要迭代生成輸出,而且通常情況下是內存受限的,所以存在著可以在系統級別進行批處理優化的機會。這意味著可以通過合理的批處理策略來最大程度地利用 GPU 資源,從而顯著提高推斷吞吐量,降低計算成本,使得服務成本不再是主導因素。
Q3. 在文章中提到了 LLMs 被視為“黑匣子”,認為只能通過內部更改(如量化和自定義 CUDA 內核)來進行優化。然而,作者認為這并不完全正確。為什么作者持這樣的看法?
作者之所以持這樣的看法,是因為他們認為 LLMs 在生成輸出時是迭代進行的,并且 LLM 推斷通常受到內存而不是計算資源的限制。這意味著存在一些出人意料的系統級批處理優化方法,可以在實際工作負載中產生顯著的性能提升。 相較于將 LLMs 視為不可調優的“黑匣子”,作者認為可以通過采用更靈活的系統級批處理策略來實現性能的大幅度提升,而不僅僅局限于內部更改如量化和自定義 CUDA 內核。這樣的優化方法可以使得在實際應用中,LLMs 的性能提升達到 10 倍甚至更多。
Q4. 文章中提到了 LLMs 通常是內存受限而不是計算受限的情況下,有一些出乎意料的系統級批處理優化方法。這些優化方法可以在實際工作負載中產生 10 倍甚至更多的差異。你能解釋一下作者指的內存受限和計算受限是什么意思嗎?
當作者提到 LLMs 通常是內存受限而不是計算受限時,他指的是在 LLM 推斷過程中,通常更多地受到可用內存的限制,而不是計算能力的限制。 內存受限意味著在處理大型語言模型時,系統的內存資源是一個相對稀缺的資源。這意味著模型在推斷時需要將許多數據存儲在內存中,例如輸入文本、中間計算結果等。如果內存不足以容納所需的數據,可能會導致內存溢出或性能下降。 相比之下,計算受限指的是在進行模型推斷時,計算資源(例如 CPU 或 GPU 的處理能力)是主要的瓶頸。這種情況下,系統的處理能力會成為推斷性能的主要限制因素,而內存資源可能并不是主要的瓶頸。 因此,在 LLM 推斷中,作者指出通常更關鍵的是如何有效地利用有限的內存資源,而不是解決計算資源瓶頸。通過優化內存的使用方式,可以使得在實際工作負載中推斷性能提升 10 倍甚至更多。這意味著通過合理地調度和利用內存,可以顯著地提高 LLM 模型在實際應用中的性能表現。
Q5. 作者提到了一種最近提出的優化方法,即連續批處理,也稱為動態批處理或迭代級別調度批處理。你能介紹一下這種優化方法的工作原理嗎?
連續批處理是一種最近提出的優化方法,也稱為動態批處理或迭代級別調度批處理。它旨在解決傳統批處理策略中的一些低效性問題。 傳統批處理策略通常是基于請求的動態批處理,即一次性處理一批請求。這可能會導致一些請求在推斷過程中花費的時間較長,因為某些請求可能會比其他請求更加復雜或耗時。 相比之下,連續批處理采用了一種更為靈活的方法。它允許在推斷過程中動態地調整批次的大小,以適應不同請求的復雜程度。具體來說,連續批處理會在模型推斷的過程中不斷地將新的請求添加到當前的批次中,同時保持一定的效率。 這意味著,如果某些請求需要更多時間來完成推斷,它們可以在當前批次中等待,而不會等待整個批次處理完畢。這樣可以顯著降低高復雜度請求的等待時間,提高了推斷的效率。
Section2 - The basics of LLM inference
Q1. 在 LLM 推斷中,對于每一個請求,我們是如何開始的?可以描述一下“前綴”或“提示”是什么嗎?
當進行 LLM 推斷時,對于每一個請求,我們會首先提供一個稱為“前綴”或“提示”的 token 序列作為輸入。這個前綴通常包含了一個或多個起始 token,用于引導模型生成接下來的文本。例如,在文章中的例子中,前綴是句子:“What is the capital of California:”。 這個前綴的目的是為了提供模型一個起點,使其能夠理解用戶的請求并生成相應的響應。在這個例子中,前綴引導模型去回答加利福尼亞的首府是什么。 一旦提供了前綴,LLM 會開始生成一個完整的響應序列,它會在產生一個終止 token 或達到最大序列長度時停止。這是一個迭代的過程,每一次前向傳遞模型都會產生一個額外的完成 token,逐步構建出完整的響應序列。
Q2. LLM 在產生完整的響應之前會產生一個什么樣的 token 序列?什么情況下會停止生成?
LLM 在產生完整的響應之前會產生一個包含多個 token 的序列,這個序列通常被稱為 “completion tokens”。生成過程會一直進行,直到滿足以下兩種情況之一:- 生成了一個特定的“停止”標記,表明生成過程應該終止。
-
達到了設定的最大序列長度,這時也會停止生成。
Q3. 作者提到了這是一個迭代的過程,可以舉一個例子來說明嗎?如果我們以句子“加利福尼亞的首府是什么:”作為提示,需要多少次前向傳遞才能得到完整的響應?
當以句子“加利福尼亞的首府是什么:”作為提示時,LLM 會逐步生成完整的響應。這是一個迭代的過程,每次迭代都會產生一個新的完成 token。 示例迭代過程:
- 第一次迭代:LLM 生成第一個 token "S",此時我們有 ["S"]。
- 第二次迭代:LLM 生成第二個 token "a",此時我們有 ["S", "a"]。
- 第三次迭代:LLM 生成第三個 token "c",此時我們有 ["S", "a", "c"]。
- ...
-
第十次迭代:LLM 生成第十個 token "o",此時我們有完整的響應:["S", "a", "c", "r", “a”, "m", "e", "n", "t", "o"]。
Q4. 作者在例子中提到了一種簡化情況,實際上 token 與 ASCII 字符并不是一一映射的,采用了一種流行的 token 編碼技術,叫做 Byte-Pair Encoding。請簡要解釋一下這種編碼技術的作用。
當作者提到了 Byte-Pair Encoding(字節對編碼)時,實際上指的是一種流行的文本壓縮和編碼技術。它的主要作用是將文本中的字符或字節序列進行編碼,以便更有效地表示和傳輸文本數據。 具體來說,Byte-Pair Encoding 通過識別和合并在文本中頻繁出現的字符對(字節對),來構建一個更緊湊的編碼表。這使得一些常用的字符或詞組可以用更短的編碼表示,從而減小了文本的總體大小。 在大型語言模型(LLM)的上下文中,使用 Byte-Pair Encoding 可以幫助將原始文本轉化為模型可以更有效地處理的編碼形式。這也是為什么在實際情況中,token 與 ASCII 字符并不是一一映射的原因之一。
Q5. 這里展示了一個玩具示例,用于說明 LLM 推斷的簡化過程。你能解釋一下圖中的元素代表了什么嗎?
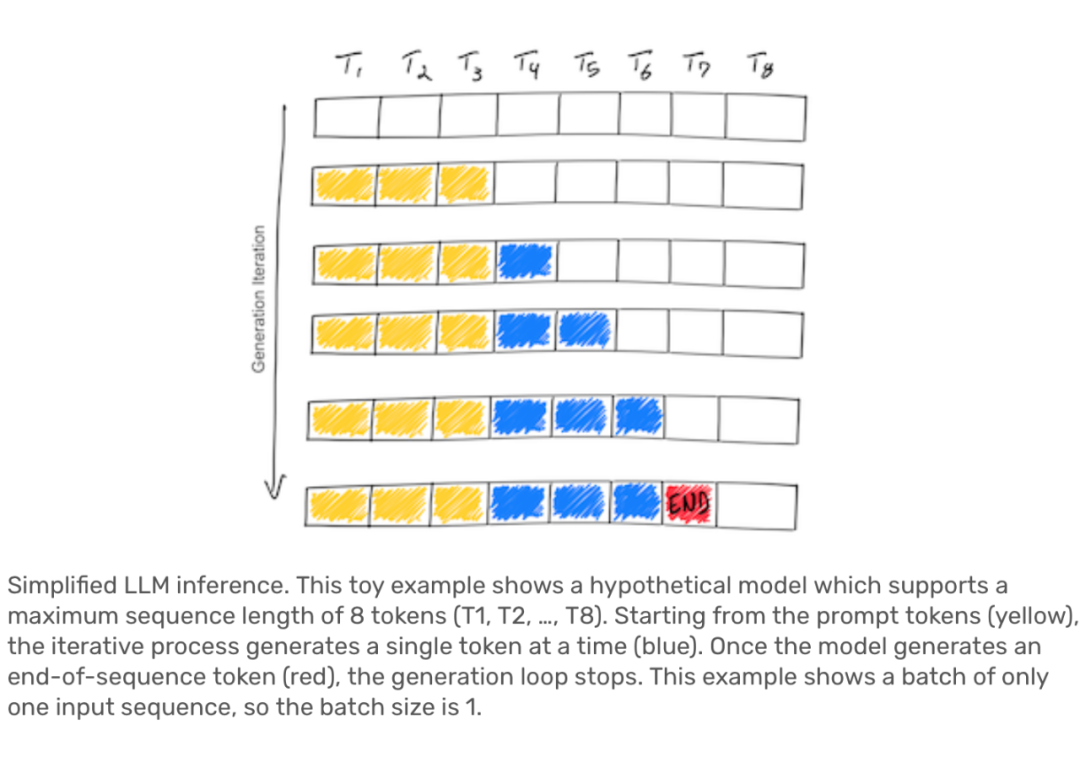
- 黃色方框中的 T1, T2, ..., T8:這些代表了一個假設模型,它支持最大長度為 8 個 token 的序列。這里的 T1, T2, ..., T8 是不同的 token。
- 藍色的箭頭:表示推斷過程的迭代。從開始的“前綴”或“提示”(黃色方框中的內容)開始,模型逐步生成一個 token。
- 紅色的方框中的 “end-of-sequence” 標志:這表示了當模型生成了一個特殊的 token,通知推斷過程結束。
-
批處理大小(Batch Size):這里展示的示例只包含一個輸入序列,因此批處理大小為1。
Q6. 作者提到了初始攝入(“預填充”)階段,即提示“加利福尼亞的首府是什么:”的處理,它與生成后續 token 一樣需要一定的時間。這是因為預填充階段預先計算了某些關于注意力機制的輸入,這些輸入在生成的整個生命周期內保持不變。你能解釋一下預填充階段的具體作用和原理嗎?
當處理一個請求時,預填充階段扮演著關鍵的角色。這個階段起初可能會花費一些時間,但它在整個生成過程中扮演著非常重要的作用。 在預填充階段,模型會提前計算一些關于注意力機制的輸入信息。這些輸入信息是在生成過程中保持不變的,因為它們與前綴(或提示)無關。這樣做的好處是,在每次進行后續的生成時,不需要重新計算這些輸入信息,從而節省了計算資源和時間。 具體來說,這些提前計算的輸入信息可以幫助模型在生成后續 token 時更高效地利用 GPU 的并行計算能力。這是因為這些輸入信息可以獨立計算,而不受后續生成過程的影響。 總的來說,預填充階段的作用是優化模型的生成過程,通過提前計算一些與前綴無關的輸入信息,從而在后續的生成過程中節省計算資源和時間。 這個階段的存在是為了使整個生成過程更加高效和快速,尤其是對于需要生成大量 token 的情況下,可以明顯地提升性能。
Q7. 作者指出了 LLM 推斷是內存 - IO 受限的,而不是計算受限的。這意味著加載 1MB 的數據到GPU的計算核心所需的時間比在 1MB 的數據上執行 LLM 計算所需的時間更長。這一點對于 LLM 推斷的吞吐量有著怎樣的影響?可以解釋一下 GPU 內存的作用和影響嗎?
當作者提到 LLM 推斷是內存 - IO 受限而不是計算受限時,意味著在 LLM 推斷過程中,主要的瓶頸并不在于計算速度,而在于數據的傳輸速度,特別是從主內存加載數據到 GPU 內存的過程。 這對 LLM 推斷的吞吐量有著重要的影響。具體來說,由于數據傳輸速度相對較慢,如果我們可以減少需要從主內存加載到 GPU 內存的次數,就能提高推斷的效率,從而提高吞吐量。 GPU 內存在這里起到了關鍵的作用。它是臨時存儲模型參數、輸入數據和計算結果的地方。在 LLM 推斷過程中,模型參數需要在 GPU 內存中保留,同時輸入數據也需要被加載到 GPU 內存中才能進行計算。因此,GPU 內存的大小限制了我們可以處理的數據量以及批次的大小。 總的來說,GPU 內存的充足與否直接影響了 LLM 推斷的性能和吞吐量。如果我們能夠優化內存的使用,比如通過模型量化策略或其他方法減少內存占用,就能提升推斷效率,從而實現更高的吞吐量。
Q8. GPU 內存的消耗量是如何隨著基本模型大小和 token 序列長度的增加而變化的?你能簡要說明一下這方面的估算和計算方法嗎?
當基本模型大小和 token 序列長度增加時,GPU 內存的消耗量也會相應增加。這是因為更大的模型和更長的序列需要更多的內存來存儲它們的參數和生成的中間結果。 具體地說,一般可以使用以下方法來估算 GPU 內存消耗:
-
基本模型大小(模型參數):隨著模型大小的增加,需要更多的內存來存儲模型的權重、偏差等參數。一般來說,模型越大,所需內存就越多。
-
Token 序列長度:每個 token 都需要一定的內存來存儲其編碼和相關信息。因此,當序列長度增加時,內存消耗也會隨之增加。
-
模型架構:不同的模型架構可能會對內存消耗產生不同的影響。一些模型可能會有特定的內存優化策略或特性,可以影響其在 GPU 上的內存占用。
-
GPU 類型和內存容量:不同類型和容量的 GPU 具有不同的內存限制。較大內存的 GPU 可以容納更大的模型和序列。
-
其他輔助數據和計算:除了模型參數和 token 序列之外,還可能存在其他計算所需的內存,比如中間結果的存儲等。
Q9. 文章中提到了一些策略和方法可以優化內存的使用,可以舉一些例子說明嗎?
當涉及到優化內存使用時,文章中提到了以下一些策略和方法:- 模型量化策略:例如 AutoGPTQ,它可以通過將模型權重從 16 位減少到 8 位表示,從而減少內存使用,為更大批處理提供了更多空間。
- FlashAttention 技術:該技術通過重新組織注意力計算,以減少內存 - IO,從而實現了顯著的吞吐量提升。
- 優化模型實現:例如 NVIDIA 的 FasterTransformer,通過優化模型實現可以提高吞吐量。
-
連續批處理:這是一種內存優化技術,不需要對模型進行修改。它可以提高 LLM 生成的內存效率。
Q10. 連續批處理是另一種不需要修改模型的內存優化技術,它是如何工作的?可以解釋一下它相對于樸素批處理的優勢嗎?
當使用連續批處理時,它允許將多個請求的前綴(prompt)合并成一個批次一起發送到模型進行推斷。相比之下,樸素批處理會單獨處理每個請求,即使它們之間可能存在共享的計算資源。 具體來說,連續批處理的工作方式如下:-
合并前綴:對于多個請求,將它們的前綴合并成一個批次。這樣做的好處是可以利用 GPU 的并行計算能力,因為可以一次性地計算多個請求的前綴。
- 共享計算資源:通過將多個請求的前綴合并成一個批次,模型的計算可以在這些前綴之間共享,從而減少了冗余的計算工作。這使得整體推斷的效率得到了提升。
- 減少前綴處理時間:樸素批處理會為每個請求單獨處理前綴,而連續批處理可以一次性地處理多個請求的前綴,從而減少了前綴處理的總時間。
- 提高內存利用率:連續批處理可以在同樣的內存限制下處理更多的請求,因為它將多個請求的前綴合并成一個批次,從而減少了內存的浪費。
-
提升模型推斷效率:通過共享計算資源,連續批處理可以更高效地利用 GPU 的計算能力,從而提升了模型推斷的速度。

Section3 - LLM batching explained
Q1. 文章提到 LLMs 盡管具有大量的計算能力,但由于內存帶寬主要用于加載模型參數,LLMs 很難實現計算飽和度。請解釋一下為什么模型參數的加載對計算飽和度有如此大的影響。
模型參數的加載對 LLMs 的計算飽和度有很大影響是因為在 GPU 架構中,內存和計算是兩個相對獨立但又相互關聯的方面。
- GPU 的計算能力:GPUs 是高度并行化的計算架構,可以以每秒數萬億次(teraflop)甚至百萬億次(petaflop)的浮點運算速度執行計算任務。這意味著它們可以在短時間內完成大量的計算工作。
-
內存帶寬的限制:然而,GPU 的內存帶寬相對有限。內存帶寬是指 GPU 用于在內存和處理器之間傳輸數據的速度。加載模型參數意味著將模型的權重和其他相關數據從存儲介質(如硬盤或內存)傳輸到 GPU 的內存中。
Q2. 什么是批處理,以及它如何有助于提高LLM推斷的效率?與每次處理一個輸入序列加載新模型參數相比,批處理有什么優勢?
批處理是一種將多個數據樣本一起傳遞給模型進行處理的技術。相比于逐個處理單個樣本,批處理允許在一次計算中同時處理多個樣本。這樣可以更有效地利用計算資源,提高計算速度。 在 LLM 推斷中,批處理的優勢主要體現在以下幾個方面:- 減少模型參數加載次數:在不使用批處理的情況下,每次處理一個輸入序列都需要加載一次模型參數。而批處理可以在一次加載后多次使用這些參數,從而減少了加載的次數。
-
提高內存帶寬的利用率:GPU 的內存帶寬是有限的資源,而加載模型參數通常會消耗大量的內存帶寬。通過批處理,可以更有效地利用這些內存帶寬,使其在計算過程中得到更充分的利用。
-
提高計算資源的利用率:LLM 推斷通常是內存 - IO 受限的,而不是計算受限的,意味著加載數據到 GPU 的計算核心比在計算核心上執行 LLM 計算花費的時間更多。通過批處理,可以更有效地利用計算資源,提高計算速度。
Q3. 傳統的批處理方法被稱為靜態批處理,為什么它被稱為靜態批處理?它與 LLM 推斷中的迭代性質有什么關系?
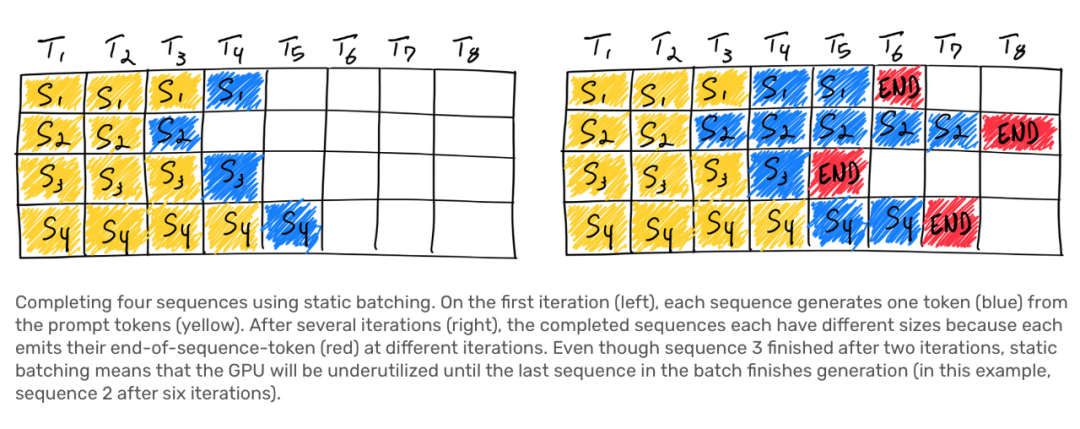
Q4. 在文章中提到靜態批處理的問題在于 GPU 會被低效利用,尤其是當批處理中的不同序列的生成長度不同時。請解釋一下為什么這會導致 GPU 低效利用,以及在靜態批處理中,如何處理不同生成長度的序列?
靜態批處理之所以會導致 GPU 低效利用,主要是因為它難以有效地處理不同生成長度的序列,這些序列可能在同一批次中同時存在。這導致了以下問題:- 等待最長序列完成:在靜態批處理中,所有序列都必須等待批處理中生成時間最長的序列完成,然后才能進行下一批次的處理。這意味著一旦有一個生成時間較長的序列存在,其他生成時間較短的序列將被迫等待,導致 GPU 的計算資源無法充分利用。這會浪費 GPU 的計算能力,尤其是當一些序列的生成非常快時。
- 難以釋放資源和添加新請求:由于 LLM 推斷是一個迭代過程,一些序列可能會在批次中的不同時間點完成生成。這使得難以及時釋放已完成生成的序列所占用的資源,并添加新的請求到批次中。如果沒有有效的機制來管理這些生成中和已完成的序列,將導致 GPU 資源的浪費和低效利用。
-
Variance in Generation Output:在靜態批處理中,如果不同序列的生成長度差異較大,那么某些序列可能會迅速完成,而其他序列則需要更長的時間。這種差異性會導致 GPU 的部分計算資源一直處于閑置狀態,因為它們無法立即用于生成更多的序列。
Q5. 靜態批處理何時會低效利用 GPU?請舉一個例子來說明,特別是當輸入和輸出序列的長度不相等時,靜態批處理可能會導致什么情況。
靜態批處理在輸入和輸出序列長度不相等的情況下會低效利用 GPU。舉例來說,假設我們有一個 LLM 模型,可以接受最多 512 個 token 的輸入序列,但其生成的輸出序列可能長度不一。如果我們采用靜態批處理,即將一批輸入序列一次性加載到 GPU 中進行推斷,那么如果批中的不同序列生成長度不同,就會導致以下情況:
假設我們有一個批次,其中包含了以下兩個輸入序列:
- 輸入序列 1(長度為 512)生成的輸出序列長度為 20。
-
輸入序列 2(長度為 512)生成的輸出序列長度為 30。
- 輸入序列 1 生成的輸出序列長度只有 20,但 GPU 在等待序列 2 完成生成之前無法開始下一個批次的處理。這意味著 GPU 會在這段時間內處于空閑狀態,無法充分利用其計算資源。
-
輸入序列 2 生成的輸出序列長度為 30,但在整個批次處理期間,GPU 只能等待最長的生成過程完成。這導致 GPU 的計算資源被浪費了 10 個 token 的長度。
Q6. 作者提到了連續批處理是一種更高效的方法,相對于靜態批處理。請解釋一下連續批處理是如何工作的,以及它是如何提高 GPU 利用率的?
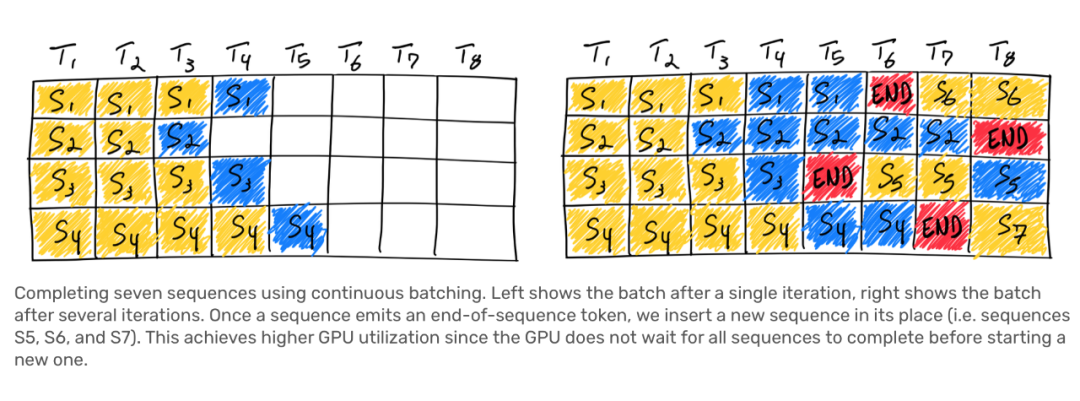
- 動態確定批次大小:與靜態批處理不同,連續批處理采用了迭代級別的調度。它并不等待每個序列在批次中完成生成后再進行下一個序列的處理。相反,它在每個迭代中根據需要確定批次的大小。這意味著一旦某個序列在批次中完成生成,就可以立即將一個新的序列插入到相同位置。
-
提高 GPU 利用率:連續批處理通過更靈活地利用 GPU 的計算資源來提高 GPU 的利用率。在靜態批處理中,如果批次中的不同序列的生成長度不同,GPU 會被低效利用,因為它必須等待批次中的所有序列完成生成才能開始下一個批次。而在連續批處理中,一旦一個序列完成生成,就可以立即開始處理下一個序列,從而最大程度地減少了 GPU 的閑置時間。
Q7. 文章中提到了 Orca 是一個首次解決這一問題的論文,它采用了迭代級別的調度。請解釋一下迭代級別調度是如何工作的,以及它相對于靜態批處理的優勢是什么?
當使用迭代級別調度時,相較于靜態批處理,批次的大小是在每個迭代中動態確定的,而不是在推斷過程的開始時就固定下來。這意味著一旦批次中的某個序列完成生成,就可以立即插入一個新的序列以繼續利用 GPU 進行計算。 相對于靜態批處理,迭代級別調度具有以下優勢:
- 更高的 GPU 利用率:在迭代級別調度中,一旦一個序列完成生成,就可以立即開始處理下一個序列。這意味著 GPU 的計算資源得到更高效的利用,不會因為等待批次中的所有序列完成生成而被浪費。
-
更高的推斷吞吐量:由于 GPU 的計算資源得到更充分的利用,相對于靜態批處理,迭代級別調度可以實現更高的推斷吞吐量,從而加快了整個推斷過程的速度。
Q8. 作者提到 Hugging Face 在他們的文本生成推斷 LLM 推斷服務器中實現了連續批處理。這個實現是如何管理預填充階段和生成階段的?有沒有提到的超參數 “waiting_served_ratio”?
在 Hugging Face 的文本生成推斷 LLM 推斷服務器中,連續批處理的實現是通過一個名為 “waiting_served_ratio” 的超參數來管理預填充階段和生成階段的。 “waiting_served_ratio” 指的是等待預填充和等待生成結束的請求數之間的比率。這個超參數的設置影響著連續批處理的表現,它可以用來調整在生成階段與預填充階段之間的權衡。文章沒有詳細說明如何設置這個超參數,但可以推測它可能是根據具體情況和需求進行調整的關鍵參數之一。 這個超參數的存在表明,Hugging Face 在他們的實現中考慮了如何在預填充階段和生成階段之間平衡處理請求,以最大化 GPU 的利用率。Q9. 文章中提到了連續批處理、動態批處理和迭代級別調度這些術語都可以用來描述批處理算法,但選擇使用了連續批處理。為什么選擇了這個術語,以及它與動態批處理和迭代級別調度有什么區別?
選擇使用連續批處理這個術語是因為它最準確地描述了優化方法的本質。下面是連續批處理與動態批處理以及迭代級別調度之間的區別:
- 連續批處理:連續批處理是一種優化技術,它允許在生成過程中動態地調整批處理的大小。具體來說,一旦一個序列在批處理中完成生成,就可以立即用新的序列替代它,從而提高了 GPU 的利用率。這種方法的關鍵在于實時地適應當前的生成狀態,而不是等待整個批次的序列都完成。
- 動態批處理:動態批處理也是一種批處理策略,但它通常指的是在訓練過程中動態調整批處理的大小,以便更好地利用硬件資源。在推斷過程中,動態批處理的意義可能會略有不同,可能是根據當前生成狀態來動態調整批處理的大小。
-
迭代級別調度:迭代級別調度與連續批處理類似,它也是在生成過程中動態調整批處理的大小。但它強調的是調度是以迭代為單位的,也就是說,在每個迭代中決定批處理的大小,而不是隨時隨地都可以進行調整

參考文獻
?https://mp.weixin.qq.com/s/bs3puOXFZYg5K-zfyDfpOw
-
物聯網
+關注
關注
2904文章
44296瀏覽量
371400
原文標題:Continuous Batching:解鎖LLM潛力!讓LLM推斷速度飆升23倍,降低延遲!
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是LLM?LLM在自然語言處理中的應用
如何訓練自己的LLM模型
LLM技術對人工智能發展的影響
LLM和傳統機器學習的區別
LLM大模型推理加速的關鍵技術
大模型LLM與ChatGPT的技術原理
llm模型有哪些格式
LLM模型和LMM模型的區別
llm模型和chatGPT的區別
LLM模型的應用領域
什么是LLM?LLM的工作原理和結構
解鎖LLM新高度—OpenVINO? 2024.1賦能生成式AI高效運行
100%在樹莓派上執行的LLM項目

優于10倍參數模型!微軟發布Orca 2 LLM
GPT推斷中的批處理(Batching)效應簡析





 工商網監
工商網監
評論