 GPT-4就是AGI!谷歌斯坦福科學家揭秘大模型如何超智能
GPT-4就是AGI!谷歌斯坦福科學家揭秘大模型如何超智能
來源:新智元
導讀
谷歌研究院和斯坦福HAI的兩位專家發文稱,現在最前沿的AI模型,未來將會被認為是第一代AGI。最前沿的LLM已經用強大的能力證明,AGI即將到來!
通用人工智能(AGI),其實已經實現了?
最近,來自谷歌研究院和斯坦福HAI的大佬發文稱,現在的大預言模型就是通向AGI的正確方向,而且現在最前沿的模型,已經擁有AGI的能力了!
這兩位作者都是AI業界大佬,Blaise Agüera y Arcas現在是Google Research副總裁兼研究員,曾經也在微軟任職。主要研究領域是人工智能基礎研究。
Peter Norvig是一位美國計算機科學家,是斯坦福AI研究所研究員,也是Google Research的工程總監。
不同的人眼里的通用人工智能(AGI)的含義,是完全不一樣的。
當前最先進的AI大型語言模型幾乎已經實現了大部分對于AGI的暢想。
雖然這些「前沿模型」有許多缺陷:它們會編造學術引用和法庭案例,從訓練數據中擴展人類的偏見,而且簡單的數學也算不對。
盡管如此,今天的前沿模型甚至能勝任它們沒有訓練過的新任務,跨越了前幾代人工智能和有監督深度學習系統從未達到的門檻。
幾十年后,它們將被公認為第一批達到AGI能力的范例,就像現在回頭看1945年的ENIAC一樣,它就是第一臺真正的通用電子計算機。
即使今天的計算機在速度、內存、可靠性和易用性方面都遠遠超過了ENIAC。但是ENIAC可以使用順序指令、循環指令和條件指令進行編程,這賦予了它前輩(如差分分析儀)所不具備的通用性。
同樣,未來的前沿人工智能也會在今天的基礎上不斷進步。
但通用性的關鍵屬性呢?
它已經在現實的大語言模型上實現了。
什么是通用人工智能?
早期的AI系統雖然在執行任務的能力上,可以接近或超過人類的水平,但通常只能專注于單一任務。比如,斯坦福大學Ted Shortliffe在20世紀70年代開發的MYCIN,只能診斷細菌感染并提出治療建議;SYSTRAN只能進行機器翻譯;而IBM的「深藍」也只會下國際象棋。后來,經過監督學習訓練的深度神經網絡模型,如AlexNet和AlphaGo,成功完成了很多早期啟發式、基于規則或基于知識的系統,長期無法解決的機器感知和判斷任務。
最近,我們看到了一些前沿模型,它們無需進行針對性的訓練,就能完成各種各樣的任務。可以說,這些模型在五個重要方面實現了通用人工智能的能力:- 話題(Topic)前沿模型是通過數百千兆字節的文本訓練而成,這些文本涵蓋了互聯網上幾乎所有討論過的話題。其中,一些模型還會在大量多樣化的音頻、視頻和其他媒體上進行訓練。
- 任務(Task)
這些模型可以執行各種任務,包括回答問題、生成故事、總結、轉錄語音、翻譯語言、解釋、決策、提供客戶支持、調用其他服務執行操作,以及組合文字和圖像。
- 模態(Modalities)
最受歡迎的模型主要處理圖像和文本,但有些系統也能處理音頻和視頻,并且有些與機器人傳感器和執行器相連。通過使用特定模態的分詞器或處理原始數據流,前沿模型原則上可以處理任何已知的感官或運動模態。
- 語言(Language)
在大多數系統的訓練數據中英語所占的比例最高,但大模型卻能使用數十種語言進行對話和翻譯,即便在訓練數據中沒有示例的語言對之間也可以實現。如果訓練數據中包含了代碼,模型甚至可以支持自然語言和計算機語言之間的「翻譯」(即通用編程和逆向工程)。- 可指導性(Instructability)這些模型能夠進行「上下文學習」,也就是根據提示而不是訓練數據來進行學習。在「少樣本學習」中,一個新任務會配有幾個輸入/輸出示例,然后系統會基于此給出新的輸入對應的輸出。在「零樣本學習」中,會描述一項新任務,但不會給出任何示例(例如,「以海明威的風格寫一首關于貓的詩」)。
「通用智能」必須通過多個維度來考慮,而不是從單一的「是/否」命題。此前,弱人工智能系統通常只執行單一或預定的任務,并為此接受明確的訓練。即使是多任務學習,也只能產生弱智能,因為模型仍在工程師設想的任務范圍內運行。事實上,開發弱人工智能所涉及的大部分艱巨工作,都是關于特定任務數據集的整理和標注。相比之下,前沿語言模型可以勝任幾乎所有人類可以完成的任務,這些任務可以用自然語言提出和回答,并且具有可量化的性能。對于通用人工智能來說,上下文學習能力是一項意義重大的任務。上下文學習將任務范圍從訓練語料中觀察到的事物,擴展到了所有可以被描述的事物。因此,通用人工智能模型可以執行設計者從未設想過的任務。
根據「通用」和「智能」這兩個詞的日常含義,前沿模型實際上在這方面已經達到了相當高的水平。那么,為什么有人不愿意承認AGI的存在呢?其原因主要有以下四點:1. 對于AGI的度量標準持懷疑態度2. 堅信其他的人工智能理論或技術3. 執著于人類(或生物)的特殊性4. 對人工智能經濟影響的擔憂
如何設定AGI的評價指標
對于通用人工智能(AGI)的門檻到底在哪里,其實存在很大分歧。業界很多專家們都曾試圖完全避諱使用這個詞。比如DeepMind的聯合創始人Mustafa Suleyman建議使用「人工能力智能(Artificial Capable Intelligence)」來描述這種系統。他建議通過「現代圖靈測試」來衡量這種AI系統——能否在10萬美元的啟動資金基礎上,快速在網上賺取100萬美元的能力。盡管將「有能力」直接等同于「能賺錢」似乎還是一件值得商榷的事情,但是能夠直接產生財富的AI系統肯定會在更加深遠的層面上影響世界。當然,大眾有充分的理由對某些指標表示懷疑。比如當一個人通過了復雜的法律、商業或醫學考試時,大眾就會假設這個人不僅能夠準確回答考試中的問題,而且能夠解決一系列相關的問題和復雜任務。自然更不會懷疑這個人會具備普通人類所具有的一般能力了。
LLM能考試,卻不能當醫生
但是,當訓練前沿的大語言模型以通過這些考試時,訓練過程通常會針對測試中的確切問題類型進行調整。盡管模型可以通過這些資格考試,但是目前的前沿模型當然不可能勝任律師或者醫生的工作。正如古德哈特定律所說的,「當一項措施成為目標時,它就不再是一個好的措施。」整個AI行業都需要更好的測試來評估模型的能力,而且已經取得了不錯的進展,例如斯坦福大學的模型評估系統——HELM。
說話流暢=智能高?
另一個非常重要的問題是,不要將語言的流暢性與智能的高低混為一談。前幾代的聊天機器人,例如Mitsuku(現在稱為Kuki),偶爾會通過突然改變主題并重復連貫的文本段落來蒙騙人類開發人員。而當前最先進的,模型可以即時生成響應,而不需要依賴預設文本,并且它們更擅長把握海量文字的主題。但這些模型仍然受益于人類的自然假設。也就是說,他們流利、符合語法的回答依然還是來自像人類這樣的智能實體。我們將其稱為「昌西·加德納效應」,以「Being There」(一部后來被改編為電影的諷刺小說)中的角色命名——昌西受到了世人的尊敬甚至是崇拜,僅僅是因為他「看起來像」一個應該受到尊敬和崇拜的人。
忽然涌現的LLM能力
研究人員Rylan Schaeffer、Brando Miranda和Sanmi Koyejo在論文中指出了常見人工智能能力指標的另一個問題:測評指標的難度不是線性的。
比如,對于一個由一系列五位數算術問題組成的測試。小模型幾乎都不可能回答對,但隨著模型規模的不斷擴大,將會出現一個臨界閾值,在此閾值之后模型將正確回答大部分問題。這個現象會讓人覺得,計算能力是從規模足夠大的模型中突然涌現出來的。但是,如果測試集中也包括一到四位數的算術題,并且如果評分標準改為只要能算對一些數字就能得分,不一定非要像人類一樣算對所有數字才能得分的話。我們會發現:隨著模型大小的增加,模型的性能是逐漸提高的,并不會突然出現一個閾值。這個觀點對超級智能能力或者屬性(可能包括意識)可能突然神秘地「涌現」的觀點提出了質疑。而「涌現論」確實讓大眾甚至是政策的制定者產生了某種程度的恐慌。類似的論點也被用來「解釋」為什么人類擁有智能,而其他類人猿就沒有智能。
實際上,這種智能的不連續性可能同樣是虛幻的。只要衡量智能的標準足夠精確,基本上都能看到智力是連續的——「越多就越好」而不是「越多就越不同」。
為什么計算機編程+語言學≠AGI?
在AGI的發展歷史上,存在許多相互競爭的智能理論,其中一些理論在一定的領域內得到了認可。計算機科學本身基于具有精確定義的形式語法的編程語言,一開始就與「Good Old-Fashioned AI」(GOFAI)密切相關。GOFAI的信條至少可以追溯到17世紀德國數學家戈特弗里德·威廉·萊布尼茨 (Gottfried Wilhelm Leibniz)。艾倫·紐厄爾(Allen Newell)和司馬賀(Herbert Simon)的「物理符號系統假說」進一步具體化這個理論。
假說認為智力可以用微積分來表述,其中符號代表思想,思維由根據邏輯規則的符號變換構成。起初,像英語這樣的自然語言似乎就是這樣的系統:用「椅子」和「紅色」這樣的符號代表「椅子」和「紅色」等概念。符號系統可以進行陳述——「椅子是紅色的」——也可以產生邏輯推論:「如果椅子是紅色的,那么椅子就不是藍色的。」
雖然這種觀點看起來很合理,但用這種方法構建的系統往往是很脆弱的,并且能夠實現的功能和通用性很有限。主要是存在兩個主要問題:首先,諸如「藍色」、「紅色」和「椅子」之類的術語僅只能被模糊地定義,并且隨著所執行的任務的復雜性增加,歧義會變得更加嚴重。其次,這樣的邏輯推論很難產生普遍有效的結果,椅子確實可能是藍色的,也可能是紅色的。更根本的是,大量的思考和認知過程不能簡化為對邏輯命題的變換。這就是為什么幾十年來,想要將計算機編程和語言學結合起來的努力都沒能產生任何類似于通用人工智能的東西的最主要原因。然而,一些特別專注于對符號系統或語言學的研究人員仍然堅持認為,他們的特定理論是通用智能前提,而神經網絡或更廣泛的機器學習在理論上無法實現通用智能——特別是如果如果模型們僅僅接受語言訓練。ChatGPT出現后,這些批評者的聲音越來越大。
例如,現代語言學之父的諾姆·喬姆斯基(Noam Chomsky)在談到大型語言模型時寫道:「我們從語言學和知識哲學中知道,它們與人類推理和使用語言的方式截然不同。這種差異極大地限制了這些程序的功能,并給它們編碼了無法根除的缺陷。」
認知科學家和當代人工智能評論家加里·馬庫斯(Gary Marcus)表示,前沿模型「正在學習如何聽起來和看起來像人類。但他們并不真正知道自己在說什么或在做什么。」馬庫斯承認神經網絡可能是通用人工智能解決方案的一部分,但他認為「為了構建一個強大的、知識驅動的人工智能方法,我們的工具包中必須有符號操作機制。」馬庫斯(和許多其他人)專注于尋找前沿模型(尤其是大型語言模型)的能力差距,并經常聲稱它們反映了該方法的根本缺陷。
這些批評者認為,如果沒有明確的符號,僅僅通過學習到的「統計」方法無法產生真正的理解。與此相關的是,他們聲稱沒有符號概念,就不可能發生邏輯推理,而「真正的」智能需要這樣的推理。撇開智能是否總是依賴于符號和邏輯的問題不談,我們有理由質疑這種關于神經網絡和機器學習不足的說法,因為神經網絡在做計算機能做的任何事情上都非常強大。例如:- 神經網絡可以輕松學習離散或符號表示,并在訓練過程中自然出現。
先進的神經網絡模型可以將復雜的統計技術應用于數據,使它們能夠根據給定的數據做出近乎最佳的預測。模型學習如何應用這些技術并為給定問題選擇最佳技術,而無需明確告知。 以正確的方式將多個神經網絡堆疊在一起會產生一個模型,該模型可以執行與任何給定計算機程序相同的計算。提供任意由計算機算出的函數的輸入和輸出示例,神經網絡都可以學會如何逼近這個函數。(比如99.9%的正確率。)
對于批評的聲音,都應該區別它是原教旨主義型批評還是積極討論型的批評。原教旨主義型批評會說:「為了被認為是通用人工智能,一個系統不僅必須通過這個測試,而且還必須以這種方式構建。」我們不認同這樣的批評,理由是測試本身應該足夠——如果不夠,測試應該被修改。另一方面,積極討論型的批評則認為:「我認為你不能讓人工智能以這種方式工作——我認為用另一種方式來做會更好。」這樣的批評可以幫助確定研究方向。如果某個系統能夠通過精心設計的測試,這些批評就會消失了。
近年來,人們設計了大量針對與「智能」、「知識」、「常識」和「推理」相關的認知任務的測試。其中包括無法通過記憶訓練數據來回答但需要概括的新問題——當我們使用測試對象在學習期間沒有遇到過的問題來測試他們的理解或推理時,我們要求測試對象提供同樣的理解證明。復雜的測試可以引入新的概念或任務,探索考生的認知靈活性:即時學習和應用新想法的能力。(這就是情境學習的本質。)當AI批評者努力設計新的測試來測試當前模型仍然表現不佳時,他們正在做有用的工作——盡管考慮到更新、更大的模型克服這些障礙的速度越來越快,推遲幾周可能是明智的選擇(再次)急于聲稱人工智能是「炒作」。
人類憑什么是「獨一無二」的?
只要懷疑論者仍然對指標不為所動,他們可能不愿意接受AGI的任何事實性的證據。這種不情愿可能是由于想要保持人類精神的特殊性的愿望所驅動的,就像人類一直不愿意接受地球不是宇宙的中心以及智人不是「生物偉大進化」的頂峰一樣。確實,人類有一些特別之處,我們應該保持他們,但我們不應該將其與通用智能混為一談。有些聲音認為,任何可以算作通用人工智能的東西都必須是有意識的、具有代理性、能夠體驗主觀感知或感受感情。但是簡單推理一下就會變成這樣:一個簡單的工具,比如螺絲刀,顯然有一個目的(擰螺絲),但不能說它是自己的代理;相反,任何代理顯然屬于工具制造者或工具使用者。螺絲刀本身「只是一個工具」。同樣的推理也適用于經過訓練來執行特定任務的人工智能系統,例如光學字符識別或語音合成。然而,具有通用人工智能的系統很難被歸類為純粹的工具。前沿模型的技能超出了程序員或用戶的想象。此外,由于LLM可以被語言提示執行任意任務,可以用語言生成新的提示,并且確實可以自我提示(「思維鏈提示」),所以前沿模型是否以及何時具有「代理」的問題需要更仔細的考慮。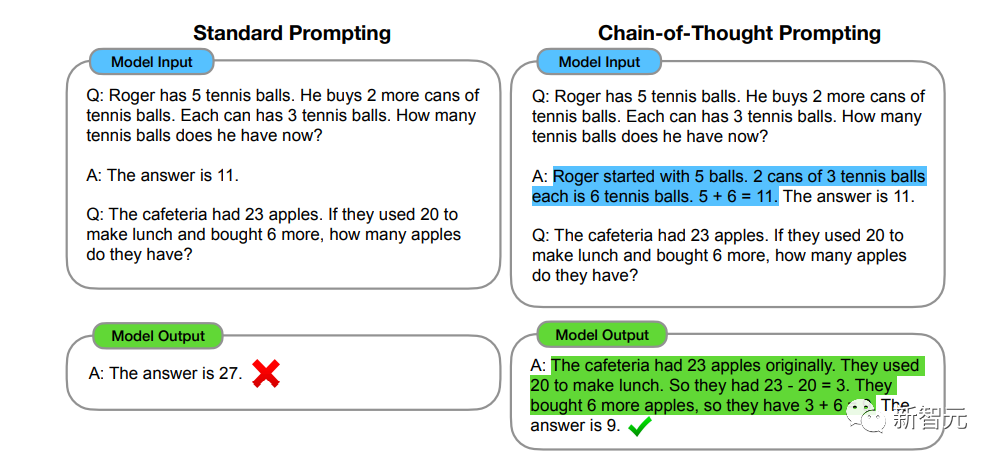 假設一下,Suleyman的「人工能力智能」為了在網上賺一百萬美元可能采取的許多行動:它可能會研究網絡,看看最近什么東西最火,找到亞馬遜商店里的爆款,然后生成一系列類似的產品的圖像和制作圖,發送給在阿里巴巴上找到的代發貨制造商,然后通過電子郵件來完善要求并就合同達成一致。最后設計賣家列表,并根據買家反饋不斷更新營銷材料和產品設計。正如Suleyman指出的那樣,最新的模型理論上已經能夠完成所有這些事情,并且能夠可靠地規劃和執行整個操作的模型可能也要即將出現。這樣的AI看起來也不再像一把螺絲刀。既然已經有了可以執行任意一般智能任務的系統,那么表現出代理性相當于有意識的說法似乎是有問題的——這意味著要么前沿模型是有意識的,要么代理不一定需要意識。
假設一下,Suleyman的「人工能力智能」為了在網上賺一百萬美元可能采取的許多行動:它可能會研究網絡,看看最近什么東西最火,找到亞馬遜商店里的爆款,然后生成一系列類似的產品的圖像和制作圖,發送給在阿里巴巴上找到的代發貨制造商,然后通過電子郵件來完善要求并就合同達成一致。最后設計賣家列表,并根據買家反饋不斷更新營銷材料和產品設計。正如Suleyman指出的那樣,最新的模型理論上已經能夠完成所有這些事情,并且能夠可靠地規劃和執行整個操作的模型可能也要即將出現。這樣的AI看起來也不再像一把螺絲刀。既然已經有了可以執行任意一般智能任務的系統,那么表現出代理性相當于有意識的說法似乎是有問題的——這意味著要么前沿模型是有意識的,要么代理不一定需要意識。
雖然我們不知道如何測量、驗證或偽造智能系統中意識的存在。我們可以直接問它,但我們可能相信也可能不相信它的回答。事實上,「只是問」似乎有點像羅夏墨跡測試:AI感知力的信徒會接受積極的回應,而不相信的人會聲稱任何肯定的回應要么只是「鸚鵡學舌」。要么當前的人工智能系統是「哲學僵尸 」,能夠像人類一樣行事,但「內部」缺乏任何意識或經驗。更糟糕的是,羅夏墨跡測試適用于LLM本身:他們可能會根據調整或提示的方式回答自己是否有意識。(ChatGPT和Bard都接受過訓練,能夠回答自己確實沒有意識。)由于依賴于無法驗證的某種「信仰」(人類和人工智能),意識或感知的爭論目前無法解決。一些研究人員提出了意識的測量方法,但這些方法要么基于不可證偽的理論,要么依賴于我們自己大腦特有的相關性。因此這些標準要么是武斷的,要么無法評估,不具有我們生物遺傳特征的系統中的意識。聲稱非生物系統根本不可能具有智能或意識(例如,因為它們「只是算法」)似乎是武斷的,植根于無法檢驗的精神信仰。類似地,比如說感覺疼痛需要傷害感受器的想法,可能會讓我們對熟悉的疼痛體驗到底是什么進行一些有根據的猜測,但目前尚不清楚如何將這種想法應用于其他神經結構或智力類型。「當一只蝙蝠是什么感覺?」,這是托馬斯·內格爾(Thomas Nagel)在1974 年提出了一個著名的問題。我們不知道,也不知道我們是否能夠知道,蝙蝠是什么樣子,或者人工智能是什么樣子。但我們確實有越來越多的測試來評估智力的各種維度。雖然尋求對意識或感知更普遍、更嚴格的表征可能是值得的,但任何這樣的表征都不會改變任何任務的測量能力。那么,目前尚不清楚這些擔憂如何能夠有意義地納入通用人工智能的定義中。
將「智能」與「意識」和「感知」分開來看會是更加理智的選擇。
AGI會對人類社會造成什么樣的影響?
關于智能和代理的爭論很容易演變為關于權利、地位、權力和階級關系的擔憂。自工業革命以來,被認為「死記硬背」或「重復性」的任務往往由低薪工人來完成,而編程——一開始被認為是「女性的工作」——只有當它在工業革命中成為男性主導時,其智力和經濟地位才會上升。20世紀70年代。然而諷刺的是,即使對于GOFAI來說,下棋和解決積分問題也很容易,但即使對于當今最復雜的人工智能來說,體力勞動仍然是一項重大的挑戰。1956年夏天,一群研究人員在達特茅斯召開會議,研究「如何讓機器使用語言、形成抽象和概念、解決各種問題,如果AGI以某種方式「按期」實現,公眾會有何反應?現在保留給人類,并提高自己」?當時,大多數美國人對技術進步持樂觀態度。在那個時代,快速發展的技術所取得的經濟收益被廣泛地重新分配(盡管肯定不公平,特別是在種族和性別方面)。盡管冷戰的威脅迫在眉睫,但對大多數人來說,未來看起來比過去更加光明。如今,這種再分配方式已經發生了逆轉:窮人越來越窮,富人越來越富。當人工智能被描述為「既不是人工的,也不是智能的」,而僅僅是人類智能的重新包裝時,很難不從經濟威脅和不安全的角度來解讀這種批評。
在將關于AGI應該是什么和它是什么的爭論混為一談時,人類似乎違反了大衛·休謨的禁令,應該盡最大努力將「是」與「應該」問題分開。但這是行不通的,因為什么是「應該」的辯論必須要誠實地進行。AGI有望在未來幾年創造巨大價值,但它也將帶來重大風險。到2023年,我們應該問的問題包括——「誰受益?」 「誰受到傷害?」 「我們如何才能最大化利益并最小化傷害?」以及「我們怎樣才能公平公正地做到這一點?」這些都是緊迫的問題,應該直接討論,而不是否認通用人工智能的現實。
-
AI
+關注
關注
87文章
30239瀏覽量
268484 -
Agi
+關注
關注
0文章
77瀏覽量
10194 -
大模型
+關注
關注
2文章
2339瀏覽量
2501
發布評論請先 登錄
相關推薦
Llama 3 與 GPT-4 比較
OpenAI推出新模型CriticGPT,用GPT-4自我糾錯
斯坦福團隊抄襲國產大模型,主要責任人失聯
阿里云發布通義千問2.5大模型,多項能力超越GPT-4
商湯科技發布5.0多模態大模型,綜合能力全面對標GPT-4 Turbo
OpenAI推出Vision模型版GPT-4 Turbo,融合文本與圖像理解
微軟Copilot全面更新為OpenAI的GPT-4 Turbo模型
全球最強大模型易主,GPT-4被超越
全球最強大模型易主:GPT-4被超越,Claude 3系列嶄露頭角
NVIDIA首席科學家Bill Dally:深度學習硬件趨勢

谷歌DeepMind科學家欲建AI初創公司
ChatGPT plus有什么功能?OpenAI 發布 GPT-4 Turbo 目前我們所知道的功能

周鴻祎:長期看谷歌趕上GPT-4綽綽有余

OpenAI發布的GPT-4 Turbo版本ChatGPT plus有什么功能?





 工商網監
工商網監
評論