") CPU后端和CUDA后端的執(zhí)行代碼和效果
CPU后端和CUDA后端的執(zhí)行代碼和效果
0x0. 前言
RWKV社區(qū)在Huggingface上放了rwkv-4-world和rwkv-5-world相關(guān)的一系列模型,見(jiàn):https://huggingface.co/BlinkDL/rwkv-4-world & https://huggingface.co/BlinkDL/rwkv-5-world ,然而這些模型的格式是以PyTorch的格式進(jìn)行保存的即*.pt文件,并沒(méi)有將其轉(zhuǎn)換為標(biāo)準(zhǔn)的Huggingface模型。后來(lái)了解到這里還有一個(gè)問(wèn)題是RWKV的世界模型系列的tokenizer是自定義的,在Huggingface里面并沒(méi)有與之對(duì)應(yīng)的Tokenizer。沒(méi)有標(biāo)準(zhǔn)的Huggingface模型就沒(méi)辦法使用TGI進(jìn)行部署,也不利于模型的傳播以及和其它模型一起做評(píng)測(cè)等等。
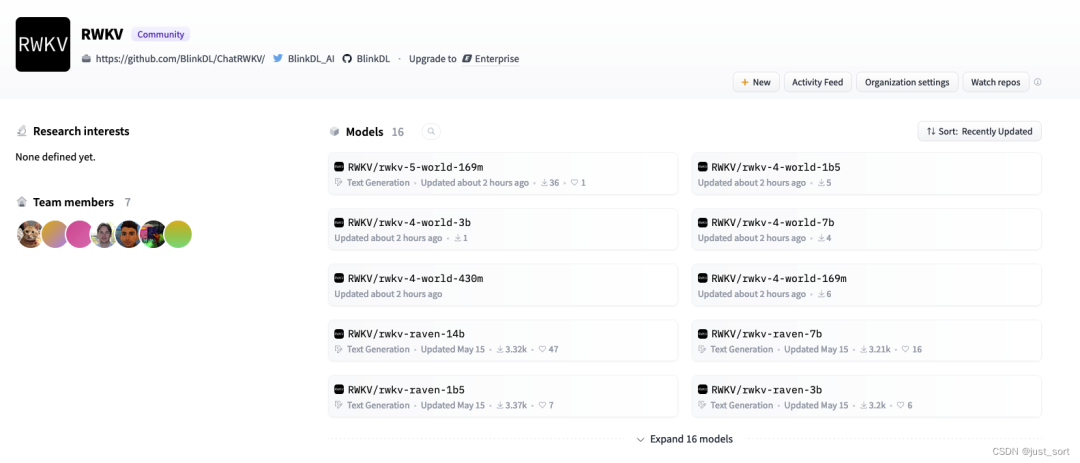
讓RWKV world系列模型登陸Huggingface社區(qū)是必要的,這篇文章介紹了筆者為了達(dá)成這個(gè)目標(biāo)所做的一些努力,最后成功讓rwkv-4-world和rwkv-5-world系列模型登陸Huggingface。大家可以在 https://huggingface.co/RWKV 這個(gè)空間找到目前所有登陸的RWKV模型:
 在這里插入圖片描述
在這里插入圖片描述本系列的工作都整理開(kāi)源在 https://github.com/BBuf/RWKV-World-HF-Tokenizer ,包含將 RWKV world tokenizer 實(shí)現(xiàn)為 Huggingface 版本,實(shí)現(xiàn) RWKV 5.0 的模型,提供模型轉(zhuǎn)換腳本,Lambda數(shù)據(jù)集ppl正確性檢查工具 等等。
0x1. 效果
以 RWKV/rwkv-4-world-3b 為例,下面分別展示一下CPU后端和CUDA后端的執(zhí)行代碼和效果。
CPU
fromtransformersimportAutoModelForCausalLM,AutoTokenizer
model=AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-world-3b")
tokenizer=AutoTokenizer.from_pretrained("RWKV/rwkv-4-world-3b",trust_remote_code=True)
text="
Inashockingfinding,scientistdiscoveredaherdofdragonslivinginaremote,previouslyunexploredvalley,inTibet.EvenmoresurprisingtotheresearcherswasthefactthatthedragonsspokeperfectChinese."
prompt=f'Question:{text.strip()}
Answer:'
inputs=tokenizer(prompt,return_tensors="pt")
output=model.generate(inputs["input_ids"],max_new_tokens=256)
print(tokenizer.decode(output[0].tolist(),skip_special_tokens=True))
輸出:
Question: In a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese.
Answer: The dragons in the valley spoke perfect Chinese, according to the scientist who discovered them.
GPU
importtorch
fromtransformersimportAutoModelForCausalLM,AutoTokenizer
model=AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-world-3b",torch_dtype=torch.float16).to(0)
tokenizer=AutoTokenizer.from_pretrained("RWKV/rwkv-4-world-3b",trust_remote_code=True)
text="你叫什么名字?"
prompt=f'Question:{text.strip()}
Answer:'
inputs=tokenizer(prompt,return_tensors="pt").to(0)
output=model.generate(inputs["input_ids"],max_new_tokens=40)
print(tokenizer.decode(output[0].tolist(),skip_special_tokens=True))
輸出:
Question: 你叫什么名字?
Answer: 我是一個(gè)人工智能語(yǔ)言模型,沒(méi)有名字。
我們可以在本地通過(guò)上述代碼分別運(yùn)行CPU/GPU上的wkv-4-world-3b模型,當(dāng)然這需要安裝transformers和torch庫(kù)。
0x2. 教程
下面展示一下在 https://github.com/BBuf/RWKV-World-HF-Tokenizer 做的自定義實(shí)現(xiàn)的RWKV world tokenizer的測(cè)試,RWKV world模型轉(zhuǎn)換,檢查lambda數(shù)據(jù)集正確性等的教程。
使用此倉(cāng)庫(kù)(https://github.com/BBuf/RWKV-World-HF-Tokenizer)的Huggingface項(xiàng)目
上傳轉(zhuǎn)換后的模型到Huggingface上時(shí),如果bin文件太大需要使用這個(gè)指令
transformers-cli lfs-enable-largefiles解除大小限制.
- RWKV/rwkv-5-world-169m
- RWKV/rwkv-4-world-169m
- RWKV/rwkv-4-world-430m
- RWKV/rwkv-4-world-1b5
- RWKV/rwkv-4-world-3b
- RWKV/rwkv-4-world-7b
RWKV World模型的HuggingFace版本的Tokenizer
下面的參考程序比較了原始tokenizer和HuggingFace版本的tokenizer對(duì)不同句子的編碼和解碼結(jié)果。
fromtransformersimportAutoModelForCausalLM,AutoTokenizer
fromrwkv_tokenizerimportTRIE_TOKENIZER
token_path="/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer"
origin_tokenizer=TRIE_TOKENIZER('/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_vocab_v20230424.txt')
fromtransformersimportAutoTokenizer
hf_tokenizer=AutoTokenizer.from_pretrained(token_path,trust_remote_code=True)
#測(cè)試編碼器
asserthf_tokenizer("Hello")['input_ids']==origin_tokenizer.encode('Hello')
asserthf_tokenizer("S:2")['input_ids']==origin_tokenizer.encode('S:2')
asserthf_tokenizer("MadeinChina")['input_ids']==origin_tokenizer.encode('MadeinChina')
asserthf_tokenizer("今天天氣不錯(cuò)")['input_ids']==origin_tokenizer.encode('今天天氣不錯(cuò)')
asserthf_tokenizer("男:聽(tīng)說(shuō)你們公司要派你去南方工作?")['input_ids']==origin_tokenizer.encode('男:聽(tīng)說(shuō)你們公司要派你去南方工作?')
#測(cè)試解碼器
asserthf_tokenizer.decode(hf_tokenizer("Hello")['input_ids'])=='Hello'
asserthf_tokenizer.decode(hf_tokenizer("S:2")['input_ids'])=='S:2'
asserthf_tokenizer.decode(hf_tokenizer("MadeinChina")['input_ids'])=='MadeinChina'
asserthf_tokenizer.decode(hf_tokenizer("今天天氣不錯(cuò)")['input_ids'])=='今天天氣不錯(cuò)'
asserthf_tokenizer.decode(hf_tokenizer("男:聽(tīng)說(shuō)你們公司要派你去南方工作?")['input_ids'])=='男:聽(tīng)說(shuō)你們公司要派你去南方工作?'
Huggingface RWKV World模型轉(zhuǎn)換
使用腳本scripts/convert_rwkv_world_model_to_hf.sh,將huggingface的BlinkDL/rwkv-4-world項(xiàng)目中的PyTorch格式模型轉(zhuǎn)換為Huggingface格式。這里,我們以0.1B為例。
#!/bin/bash
set-x
cdscripts
pythonconvert_rwkv_checkpoint_to_hf.py--repo_idBlinkDL/rwkv-4-world
--checkpoint_fileRWKV-4-World-0.1B-v1-20230520-ctx4096.pth
--output_dir../rwkv4-world4-0.1b-model/
--tokenizer_file/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer
--size169M
--is_world_tokenizerTrue
cp/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/rwkv_vocab_v20230424.json../rwkv4-world4-0.1b-model/
cp/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/tokenization_rwkv_world.py../rwkv4-world4-0.1b-model/
cp/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/tokenizer_config.json../rwkv4-world4-0.1b-model/
使用腳本 scripts/convert_rwkv5_world_model_to_hf.sh,將來(lái)自 huggingface BlinkDL/rwkv-5-world 項(xiàng)目的 PyTorch 格式模型轉(zhuǎn)換為 Huggingface 格式。在這里,我們以 0.1B 為例。
#!/bin/bash
set-x
cdscripts
pythonconvert_rwkv5_checkpoint_to_hf.py--repo_idBlinkDL/rwkv-5-world
--checkpoint_fileRWKV-5-World-0.1B-v1-20230803-ctx4096.pth
--output_dir../rwkv5-world-169m-model/
--tokenizer_file/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer
--size169M
--is_world_tokenizerTrue
cp/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_v5.0_model/configuration_rwkv5.py../rwkv5-world-169m-model/
cp/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_v5.0_model/modeling_rwkv5.py../rwkv5-world-169m-model/
cp/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/rwkv_vocab_v20230424.json../rwkv5-world-169m-model/
cp/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/tokenization_rwkv_world.py../rwkv5-world-169m-model/
cp/Users/bbuf/工作目錄/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/tokenizer_config.json../rwkv5-world-169m-model/
另外,您需要在生成文件夾中的 config.json 文件開(kāi)頭添加以下幾行:
"architectures":[
"RwkvForCausalLM"
],
"auto_map":{
"AutoConfig":"configuration_rwkv5.Rwkv5Config",
"AutoModelForCausalLM":"modeling_rwkv5.RwkvForCausalLM"
},
運(yùn)行Huggingface的RWKV World模型
run_hf_world_model_xxx.py演示了如何使用Huggingface的AutoModelForCausalLM加載轉(zhuǎn)換后的模型,以及如何使用通過(guò)AutoTokenizer加載的自定義RWKV World模型的HuggingFace版本的Tokenizer進(jìn)行模型推斷。請(qǐng)看0x1節(jié),這里就不贅述了。
檢查L(zhǎng)ambda
如果你想運(yùn)行這兩個(gè)腳本,首先需要下載一下 https://github.com/BlinkDL/ChatRWKV ,然后cd到rwkv_pip_package 目錄做pip install -e . ,然后再回到ChatRWKV的v2目錄下面,運(yùn)行這里提供的lambda_pt.py和lambda_hf.py。
check_lambda文件夾下的lambda_pt.py和lambda_hf.py文件分別使用RWKV4 World 169M的原始PyTorch模型和HuggingFace模型對(duì)lambda數(shù)據(jù)集進(jìn)行評(píng)估。從日志中可以看出,他們得到的評(píng)估結(jié)果基本上是一樣的。
lambda_pt.py lambda評(píng)估日志
#CheckLAMBADA...
#100ppl42.41acc34.0
#200ppl29.33acc37.0
#300ppl25.95acc39.0
#400ppl27.29acc36.75
#500ppl28.3acc35.4
#600ppl27.04acc35.83
...
#5000ppl26.19acc35.84
#5100ppl26.17acc35.88
#5153ppl26.16acc35.88
lambda_hf.py lambda評(píng)估日志
#CheckLAMBADA...
#100ppl42.4acc34.0
#200ppl29.3acc37.0
#300ppl25.94acc39.0
#400ppl27.27acc36.75
#500ppl28.28acc35.4
#600ppl27.02acc35.83
...
#5000ppl26.17acc35.82
#5100ppl26.15acc35.86
#5153ppl26.14acc35.86
從lambda的輸出結(jié)果可以驗(yàn)證原始基于ChatRWKV系統(tǒng)運(yùn)行的模型和轉(zhuǎn)換后的Huggingface模型是否精度是等價(jià)的。
0x3. 實(shí)現(xiàn)
Tokenizer的實(shí)現(xiàn)
Tokenizer的實(shí)現(xiàn)分為兩步。
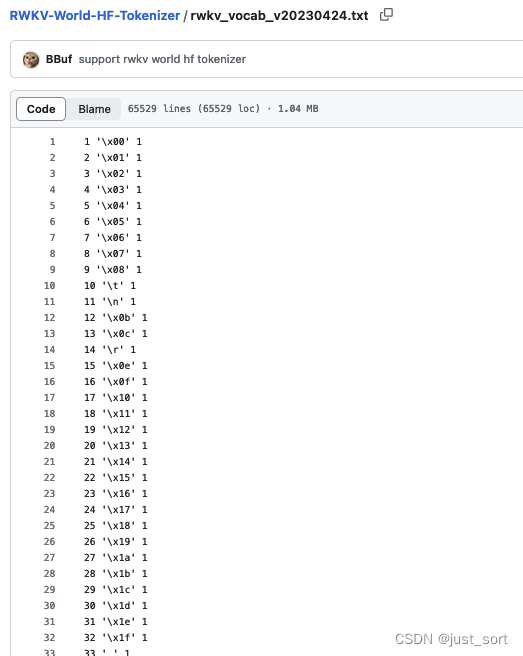
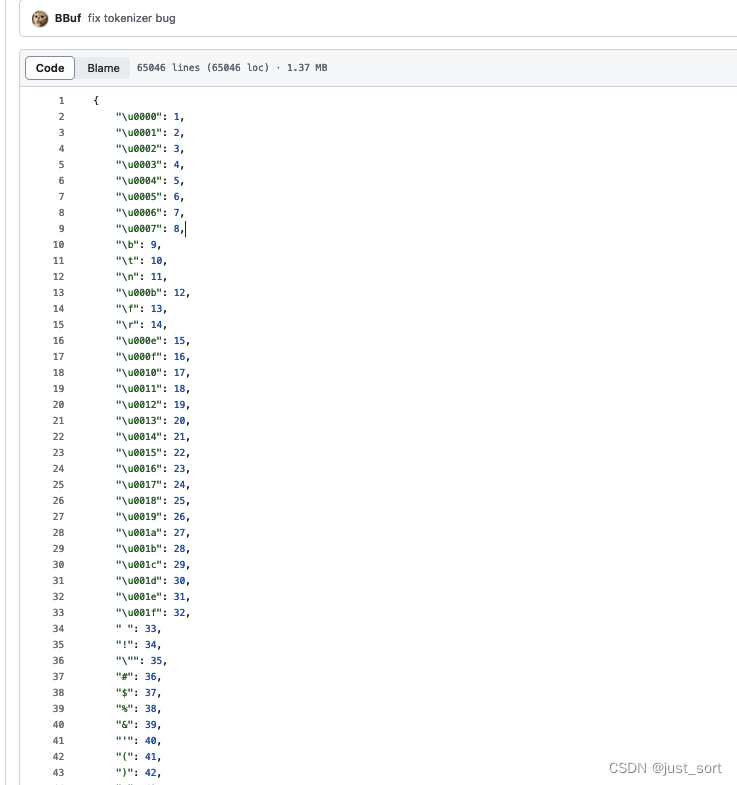
因?yàn)槟壳吧鐓^(qū)的RWKV world模型tokenizer文件是一個(gè)txt文件:https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/rwkv_vocab_v20230424.txt 。我們需要將其轉(zhuǎn)換為Huggingface的AutoTokenizer可以讀取的json文件。這一步是通過(guò) https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/scripts/convert_vocab_json.py 這個(gè)腳本實(shí)現(xiàn)的,我們對(duì)比一下執(zhí)行前后的效果。
 在這里插入圖片描述
在這里插入圖片描述轉(zhuǎn)換為json文件后:
 在這里插入圖片描述
在這里插入圖片描述這里存在一個(gè)轉(zhuǎn)義的關(guān)系,讓gpt4解釋一下u0000和x00的關(guān)系:
 在這里插入圖片描述
在這里插入圖片描述有了這個(gè)json文件之后,我們就可以寫(xiě)一個(gè)繼承PreTrainedTokenizer類(lèi)的RWKVWorldTokenizer了,由于RWKV world tokenzier的原始實(shí)現(xiàn)是基于Trie樹(shù)(https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/rwkv_tokenizer.py#L5),所以我們實(shí)現(xiàn) RWKVWorldTokenizer 的時(shí)候也要使用 Trie 樹(shù)這個(gè)數(shù)據(jù)結(jié)構(gòu)。具體的代碼實(shí)現(xiàn)在 https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/rwkv_world_tokenizer/tokenization_rwkv_world.py 這個(gè)文件。
需要注意 https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/rwkv_world_tokenizer/tokenization_rwkv_world.py#L211 這一行,當(dāng)解碼的token id是0時(shí)表示句子的結(jié)束(eos),這個(gè)時(shí)候就停止解碼。
RWKV World 5.0模型實(shí)現(xiàn)
實(shí)現(xiàn)了rwkv world tokenizer之后就可以完成所有rwkv4 world模型轉(zhuǎn)換到HuggingFace模型格式了,因?yàn)閞wkv4 world模型的模型結(jié)構(gòu)和目前transformers里面支持的rwkv模型的代碼完全一樣,只是tokenzier有區(qū)別而已。
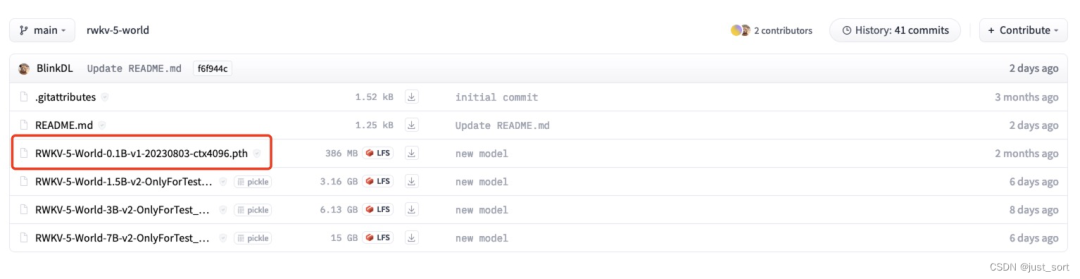
但是如果想把 https://huggingface.co/BlinkDL/rwkv-5-world 這里的模型也轉(zhuǎn)換成 HuggingFace模型格式,那么我們就需要重新實(shí)現(xiàn)一下模型了。下面紅色部分的這個(gè)模型就是rwkv5.0版本的模型,剩下的都是5.2版本的模型。
 在這里插入圖片描述
在這里插入圖片描述我對(duì)照著ChatRWKV里面rwkv world 5.0的模型實(shí)現(xiàn)完成了HuggingFace版本的rwkv world 5.0版本模型代碼實(shí)現(xiàn),具體見(jiàn):https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/rwkv_world_v5.0_model/modeling_rwkv5.py ,是在transformers官方提供的實(shí)現(xiàn)上進(jìn)一步修改得來(lái)。
實(shí)現(xiàn)了這個(gè)模型之后就可以完成rwkv world 5.0的模型轉(zhuǎn)換為HuggingFace結(jié)果了,教程請(qǐng)看上一節(jié)或者github倉(cāng)庫(kù)。成品:https://huggingface.co/RWKV/rwkv-5-world-169m
0x4. 踩坑
在實(shí)現(xiàn)tokenizer的時(shí)候,由于RWKV world tokenzier的eos是0,我們沒(méi)辦法常規(guī)的去插入eos token,所以直接在Tokenzier的解碼位置特判0。
RWKVWorldTokenizer的初始化函數(shù)在 super().__init__ 的時(shí)機(jī)應(yīng)該是在構(gòu)造self.encoder之后,即:
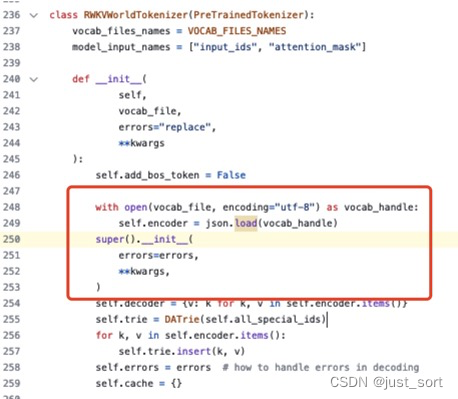 在這里插入圖片描述
在這里插入圖片描述否則會(huì)在當(dāng)前最新的transformers==4.34版本中造成下面的錯(cuò)誤:
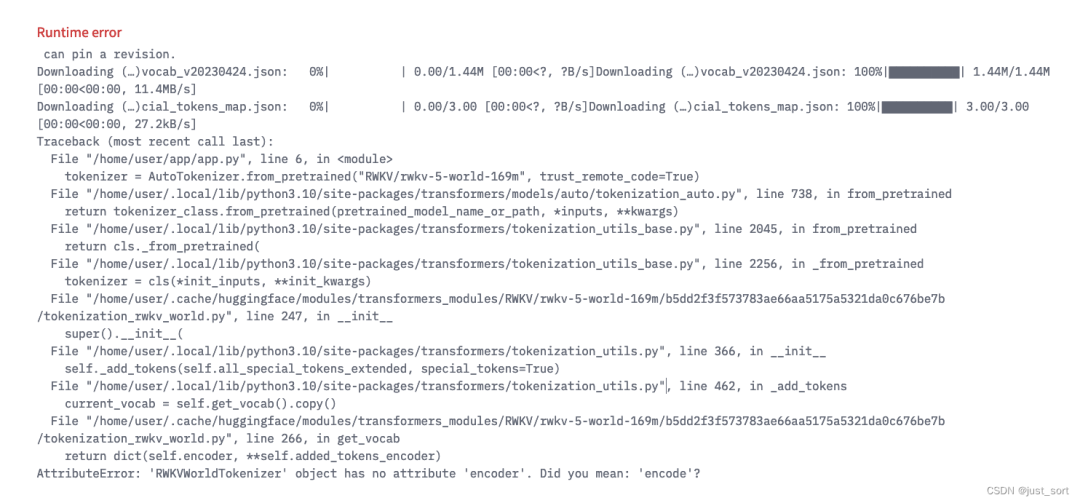 在這里插入圖片描述
在這里插入圖片描述在模型實(shí)現(xiàn)部分踩了一個(gè)坑,在embedding的時(shí)候第一次需要需要對(duì)embedding權(quán)重做一個(gè)pre layernorm的操作:
 在這里插入圖片描述
在這里插入圖片描述這個(gè)操作只能在第一次輸入的時(shí)候做一般就是prefill,我沒(méi)注意到這一點(diǎn)導(dǎo)致后面decoding的時(shí)候也錯(cuò)誤做了這個(gè)操作導(dǎo)致解碼的時(shí)候亂碼,后面排查了不少時(shí)間才定位到這個(gè)問(wèn)題。
另外,在做check lambda的時(shí)候,如果不開(kāi)啟torch.no_grad上下文管理器禁用梯度計(jì)算,顯存會(huì)一直漲直到oom:https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/check_lambda/lambda_hf.py#L48 。
0x5. 總結(jié)
這件事情大概花了國(guó)慶的一半時(shí)間加一個(gè)完整的周六才搞定,所以這篇文章記錄一下也可以幫助有相關(guān)需求的小伙伴們少踩點(diǎn)坑。
-
人工智能
+關(guān)注
關(guān)注
1791文章
46888瀏覽量
237644 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
508瀏覽量
10246 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24648
原文標(biāo)題:0x5. 總結(jié)
文章出處:【微信號(hào):GiantPandaCV,微信公眾號(hào):GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于Serverless的前后端一體化框架
IC后端概述(下)
IC前端和后端設(shè)計(jì)的區(qū)別
數(shù)字IC后端設(shè)計(jì)介紹,寫(xiě)給哪些想轉(zhuǎn)IC后端的人!
什么是后端?
后端系統(tǒng),后端系統(tǒng)是什么意思
后端時(shí)序修正基本思路






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論