 Polars模塊的使用方式
Polars模塊的使用方式
它擁有以下特性:
1.多線程
2.強大的表達式API
3.查詢優化
下面給大家簡單介紹一下這個模塊的使用方式。
1.準備
開始之前,你要確保Python和pip已經成功安裝在電腦上,如果沒有,可以訪問這篇文章:超詳細Python安裝指南 進行安裝。
**(可選1) **如果你用Python的目的是數據分析,可以直接安裝Anaconda:Python數據分析與挖掘好幫手—Anaconda,它內置了Python和pip.
**(可選2) **此外,推薦大家用VSCode編輯器,它有許多的優點:Python 編程的最好搭檔—VSCode 詳細指南。
請選擇以下任一種方式輸入命令安裝依賴 :
- Windows 環境 打開 Cmd (開始-運行-CMD)。
- MacOS 環境 打開 Terminal (command+空格輸入Terminal)。
- 如果你用的是 VSCode編輯器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install polars
2.Polars 使用介紹
在初始化變量的時候,Polars用起來的方式和Pandas沒有太大區別,下面我們定義一個初始變量,后面所有示例都使用這個變量:
import polars as pl
df = pl.DataFrame(
{
"A": [1, 2, 3, 4, 5],
"fruits": ["banana", "banana", "apple", "apple", "banana"],
"B": [5, 4, 3, 2, 1],
"cars": ["beetle", "audi", "beetle", "beetle", "beetle"],
}
)
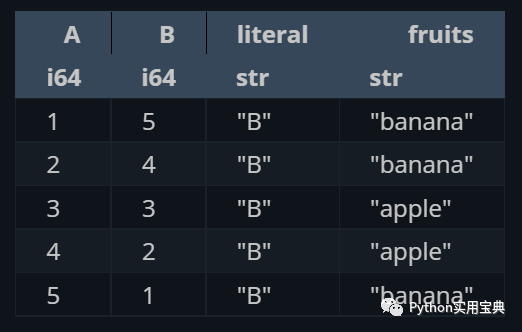
選擇需要展示的數據:
(df.select([
pl.col("A"),
"B", # the col part is inferred
pl.lit("B"), # we must tell polars we mean the literal "B"
pl.col("fruits"),
]))
效果如下:
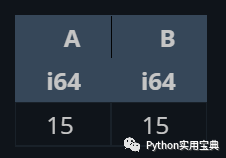
他還能使用正則表達式篩選值并進行求和等操作:
# 正則表達式
(df.select([
pl.col("^A|B$").sum()
]))
# 或者多選
(df.select([
pl.col(["A", "B"]).sum()
]))
Polars支持下面這樣復雜且高效的查詢及展示:
>> > df.sort("fruits").select(
... [
... "fruits",
... "cars",
... pl.lit("fruits").alias("literal_string_fruits"),
... pl.col("B").filter(pl.col("cars") == "beetle").sum(),
... pl.col("A").filter(pl.col("B") > 2).sum().over("cars").alias("sum_A_by_cars"),
... pl.col("A").sum().over("fruits").alias("sum_A_by_fruits"),
... pl.col("A").reverse().over("fruits").alias("rev_A_by_fruits"),
... pl.col("A").sort_by("B").over("fruits").alias("sort_A_by_B_by_fruits"),
... ]
... )
shape: (5, 8)
┌──────────┬──────────┬──────────────┬─────┬─────────────┬─────────────┬─────────────┬─────────────┐
│ fruits ┆ cars ┆ literal_stri ┆ B ┆ sum_A_by_ca ┆ sum_A_by_fr ┆ rev_A_by_fr ┆ sort_A_by_B │
│ --- ┆ --- ┆ ng_fruits ┆ --- ┆ rs ┆ uits ┆ uits ┆ _by_fruits │
│ str ┆ str ┆ --- ┆ i64 ┆ --- ┆ --- ┆ --- ┆ --- │
│ ┆ ┆ str ┆ ┆ i64 ┆ i64 ┆ i64 ┆ i64 │
╞══════════╪══════════╪══════════════╪═════╪═════════════╪═════════════╪═════════════╪═════════════╡
│ "apple" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 7 ┆ 4 ┆ 4 │
│ "apple" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 7 ┆ 3 ┆ 3 │
│ "banana" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 8 ┆ 5 ┆ 5 │
│ "banana" ┆ "audi" ┆ "fruits" ┆ 11 ┆ 2 ┆ 8 ┆ 2 ┆ 2 │
│ "banana" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 8 ┆ 1 ┆ 1 │
└──────────┴──────────┴──────────────┴─────┴─────────────┴─────────────┴─────────────┴─────────────┘
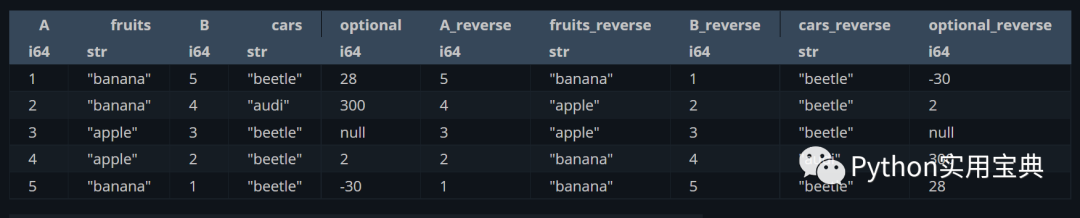
3.Polars 高級使用
倒序操作,將值倒序后重新放回變量中,起名為xxx_reverse:
(df.select([
pl.all(),
pl.all().reverse().suffix("_reverse")
]))
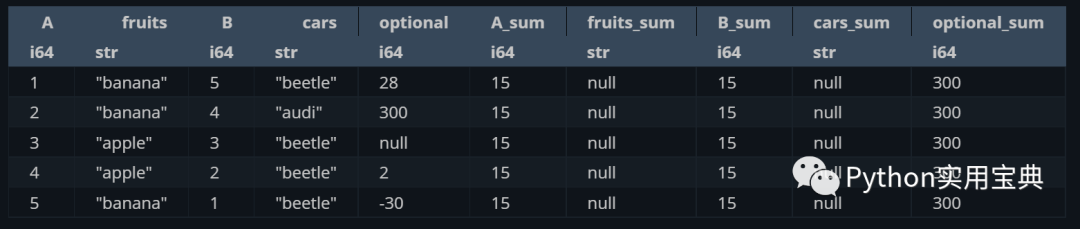
對所有列求和,并放回變量中,起名為 xxx_sum:
(df.select([
pl.all(),
pl.all().sum().suffix("_sum")
]))
正則也能用于篩選:
predicate = pl.col("fruits").str.contains("^b.*")
(df.select([
predicate
]))
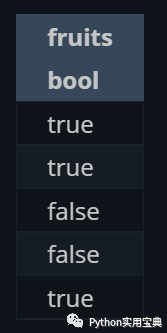
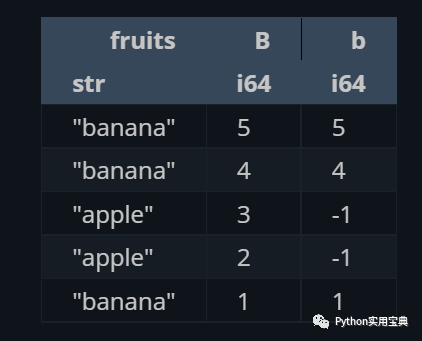
在設定一個新列的時候,甚至可以根據條件來給不同的行設定值:
(df.select([
"fruits",
"B",
pl.when(pl.col("fruits") == "banana").then(pl.col("B")).otherwise(-1).alias("b")
]))
fold 函數很強大,它能在列上執行操作,獲得最快的速度,也就是矢量化執行:
df = pl.DataFrame({
"a": [1, 2, 3],
"b": [10, 20, 30],
}
)
out = df.select(
pl.fold(acc=pl.lit(0), f=lambda acc, x: acc + x, exprs=pl.col("*")).alias("sum"),
)
print(out)
# shape: (3, 1)
# ┌─────┐
# │ sum │
# │ --- │
# │ i64 │
# ╞═════╡
# │ 11 │
# ├?????┤
# │ 22 │
# ├?????┤
# │ 33 │
# └─────┘
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
模塊
+關注
關注
7文章
2674瀏覽量
47350 -
多線程
+關注
關注
0文章
277瀏覽量
19923 -
數據分析
+關注
關注
2文章
1429瀏覽量
34025
發布評論請先 登錄
相關推薦
Wifi模塊的工作方式功能是什么?
Wifi模塊的工作方式是什么呢,Wifi模塊的主要功能又有哪些呢?本文主要介紹了有關Wifi模塊的基礎知識即:Wifi模塊的工作
發表于 06-12 14:22
?5871次閱讀

【技術分享】WiFi模塊常見的配網方式簡介
配網方式。WiFi模塊常見的WiFi模塊配網方式,一般可以歸類為直接配網、智能配網、WEB配網、WPS配網。其中最為常見的就是前三種,用戶可以根據具體的使用場合選擇各種最適合的配網
485無線通信模塊與4-20mA采集模塊傳輸方式的區別
若將485無線通信模塊與4-20mA采集模塊進行比較,則兩者在傳輸方式上的差別仍較大。與普通儀表一樣,信號電流都是4-20mA,即最小電流是4mA,最大電流是20mA。在傳送信號時,要考慮到導線還有
發表于 03-03 14:50
?1.2w次閱讀
光模塊的分類方式及類型詳解
不同的應用需求,不同參數和功能的光模塊應運而生。光模塊的分類方式及類型詳見如下: 1、按封裝分類 光模塊按照封裝形式來分有以下幾種常見類型:SFP、SFP+、SFP28、QSFP+、Q
發表于 06-08 15:14
?7521次閱讀
Polars是一個使用Apache Arrow列格式作為內存模型
需要注意的是,Python實現的Rust crate被稱為py-polars,以區別于Rust crate包polars本身。然而,Python包和Python模塊都被命名為polars
發表于 07-07 16:21
?1305次閱讀
DC電源模塊具有不同的安裝方式和安全規范
BOSHIDA DC電源模塊具有不同的安裝方式和安全規范 DC電源模塊是將低壓直流電轉換為需要的輸出電壓的裝置。它們廣泛應用于各種領域和行業,如通信、醫療、工業、家用電器等。安裝DC電源模塊

verilog調用模塊端口對應方式
Verilog是一種硬件描述語言(HDL),廣泛應用于數字電路設計和硬件驗證。在Verilog中,模塊是構建電路的基本單元,而模塊端口對應方式則用于描述模塊之間信號傳遞的
DC電源模塊的原理及工作方式
BOSHIDA ?DC電源模塊的原理及工作方式 DC電源模塊是一種將交流電轉換為直流電的設備,它將交流電輸入端轉換為穩定的直流電輸出,以供電子設備使用。DC電源模塊的工作原理及工作

開關量模塊接線方式有哪些
開關量模塊接線方式是自動化控制系統中的重要組成部分,它負責接收和處理開關信號,實現對設備的控制。 一、開關量模塊概述 1.1 開關量模塊定義 開關量
將NVIDIA加速計算引入Polars
Polars 近日發布了一款由 RAPIDS cuDF 驅動的全新 GPU 引擎,該引擎可將 NVIDIA GPU 上的 Polars 工作流速度最高提速 13 倍,使數據科學家僅在一臺機器上就能實現在數秒內處理數億行數據。






 工商網監
工商網監
評論