 Cache工作原理講解 Cache寫入方式原理簡介
Cache工作原理講解 Cache寫入方式原理簡介
前言
Cache是位于CPU與主存儲器即DRAM(Dynamic RAM,動態存儲器)之間的少量超高速靜態存儲器SRAM(Static RAM),它是為了解決CPU與主存之間速度匹配問題而設置的,不能由用戶直接尋址訪問。
隨著科技的發展和生產工藝水平的提高,高性能處理器中Cache的容量將越來越大,而且級數將越來越多,從而大大提高系統的性能。
1 Cache和Write Buffer一般性介紹
1.1 Cache工作原理
具有Cache的計算機,當CPU需要進行存儲器存取時,首先檢查所需數據是否在Cache中。如果存在,則可以直接存取其中的數據而不必插入任何等待狀態,這是最佳情況,稱為高速命中;
當CPU所需信息不在Cache中時,則需切換存取主儲器,由于速度較慢,需要插入等待,這種情況稱高速未命中;
在CPU存取主存儲器的時候,按照最優化原則將存儲信息同時寫入到Cache中以保證下次可能的高速緩存命中。
因此,同一數據可能同時存儲在主存儲器和Cache中。同樣,按照優化算法,可以淘汰Cache中一些不常使用的數據。
傳統的Socket架構通常采用兩級緩沖結構,即在CPU中集成了一級緩存(L1Cache),在主板上裝二級緩存(L2 Cache),而SlotⅠ架構下的L2 Cache則與CPU做在同一塊電路板上,以內核速度或者內核速度的一半運行,速度比Socket下的以系統外頻運行的L2 Cache更快,能夠更大限度發揮高主頻的優勢,當然對Cache工藝要求也更高。
?CPU首先在L1 Cache中查找數據,如找不到,則在L2Cache中尋找。?若數據在L2 Cache中,控制器在傳輸數據的同時,修改L1Cache;?若數據既不在L1 Cache中,又不在L2 Cache中,Cache控制器則從主存中獲取數據,將數據提供給CPU的同時修改兩級Cache。?K6-Ⅲ則比較特殊,64KB L1 Cache,256KB Full Core Speed L2 Cache,原先主板上的緩存實際上就成了L3 Cache。
根據有關測試表明:
當512K2MB的三級緩存發揮作用時,系統性能還可以有2%10%的提高;
Tri-level成為PC系統出現以來提出的解決高速CPU與低速內存之間瓶頸最為細致復雜的方案;而且,今后Cache的發展方向也是大容。
在主存-Cache存儲體系中,所有的指令和數據都存在主存中,Cache只是存放主存中的一部分程序塊和數據塊的副本,只是一種以塊為單位的存儲方式。
Cache和主存被分為塊,每塊由多個字節組成。
由上述的程序局部性原理可知,Cache中的程序塊和數據塊會使CPU要訪問的內容在大多數情況下已經在Cache中,CPU的讀寫操作主要在CPU和Cache之間進行。
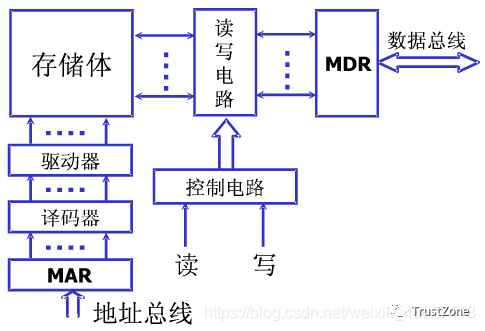
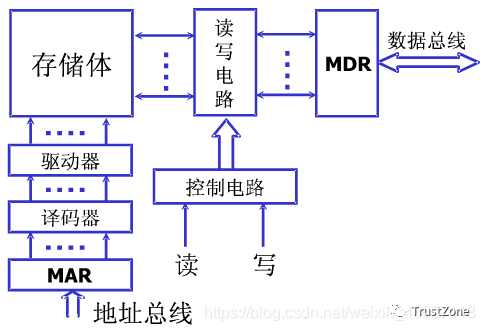
CPU訪問存儲器時,送出訪問單元的地址,由地址總線傳送到Cache控制器中的主存地址寄存器MAR,主存-Cache地址轉換機構從MA獲取地址并判斷該單元內容是否已在Cache中存有副本,如果副本已存在于Cache中,即命中。當命中時,立即把訪問地址變換成它在Cache中的地址,然后訪問Cache。
在這里插入圖片描述
?存儲體由若跟個存儲單元組成,存儲單元由多個存儲元件組成
?存儲體----存儲單元(存儲一串二進制串)----存儲元件(存儲一個0/1)
?存儲單元:存放一串二進制代碼。
?存儲字:存儲單元中的二進制代碼
?存儲字長:存儲單元中二進制代碼位數。
?存儲單元按照地址進行尋址
?MAR:存儲器地址寄存器,反應存儲單元個數。保存了存儲體的地址(存儲單元的編號),反應了存儲單元的個數。所以MAR的位數和存儲單元的個數有關。
?MDR:存儲器數據寄存器,反應存儲字長(存儲單元長度)。保存了要送入CPU中的數據或要保存到存儲體中的數據或者剛剛從存儲體中取出來來的數據。這個寄存器的長度和存儲單元的長度相同。
如果CPU要訪問的內容不在Cache中,即不命中,則CPU轉去直接訪問主存,并將包含此存儲單元的整個數據塊(包括該塊數據的地址信息)傳到Cache中,使得以后的若干次對內存的訪問可轉化為對Cache的訪問。
若Cache存儲器已滿,則需在替換控制部件的控制下,根據某種替換算法/策略,用此塊信息替換掉Cache中原來的某塊信息。
之前記得當時面試的時候讓我用golang手寫緩存管理算法,哈哈哈。
所以,要想提高系統效率,必須提高Cache命中率,而Cache命中率的提高則取決于Cache的映像方式和Cache刷新算法等一系列因素,同時Cache中內容應與主存中的部分保持一致,也就是說,如果主存中的內容在調入Cache之后發生了變化,那么它在Cache中的映像也應該隨之發生相應改變,反之,當CPU修改了Cache中的內容后,主存中的相應內容也應作修改。
1.2 地址映像方式
所謂地址映像方式是指如何確定Cache中的內容是主存中的哪一部分的副本,即必須應用某種函數把主存地址映像到Cache中定位。
信息按某種方式裝入Cache中后,執行程序時,應將主存地址變換為Cache地址,這個變換過程叫作地址變換。
地址映像方式通常采用直接映像、全相聯映像、組相聯映像三種:
1-直接映像
每個主存地址映像到Cache中的一個指定地址的方式,稱為直接映像方式。在直接映像方式下,主存中存儲單元的數據只可調入Cache中的一個位置,如果主存中另一個存儲單元的數據也要調入該位置則將發生沖突。
地址映像的方法一般是將主存空間按Cache的尺寸分區,每區內相同的塊號映像到Cache中相同的塊位置。一般地,Cache被分為2N塊,主存被分為大小為2MB的塊,主存與Cache中塊的對應關系可用如下映像函數表示:j = i mod 2N。式中,j是Cache中的塊號;i是主存中的塊號。
直接映像是一種最簡單的地址映像方式,它的地址變換速度快,而且不涉及其他兩種映像方式中的替換策略問題。但是這種方式的塊沖突概率較高,當程序往返訪問兩個相互沖突的塊中的數據時,Cache的命中率將急劇下降,因為這時即使Cache中有其他空閑塊,也因為固定的地址映像關系而無法應用。
2-全相聯映像
主存中的每一個字塊可映像到Cache任何一個字塊位置上,這種方式稱為全相聯映像。這種方式只有當Cache中的塊全部裝滿后才會出現塊沖突,所以塊沖突的概率低,可達到很高的Cache命中率,但它實現很復雜。
當訪問一個塊中的數據時,塊地址要與Cache塊表中的所有地址標記進行比較已確定是否命中。在數據塊調入時存在著一個比較復雜的替換問題,即決定將數據塊調入Cache中什么位置,將Cache中哪一塊數據調出主存。為了達到較高的速度,全部比較和替換都要用硬件實現。
3-組相聯映像
組相聯映像方式是直接映像和全相聯映像的一種折中方案。這種方法將存儲空間分為若干組,各組之間是直接映像,而組內各塊之間則是全相聯映像。
它是上述兩種映像方式的一般形式,如果組的大小為1,即Cache空間分為2N組,就變為直接映像;如果組的大小為Cache整個的尺寸,就變為全相聯映像。組相聯方式在判斷塊命中及替換算法上都要比全相聯方式簡單,塊沖突的概率比直接映像低,其命中率也介于直接映像和全相聯映像方式之間。
1.3 Cache寫入方式原理簡介
提高高速緩存命中率的最好方法是盡量使Cache存放CPU最近一直在使用的指令與數據,當Cache裝滿后,可將相對長期不用的數據刪除,提高Cache的使用效率。
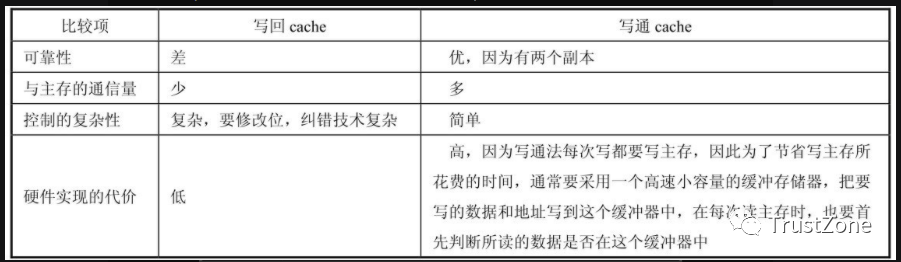
為保持Cache中數據與主存儲器中數據的一致性,避免CPU在讀寫過程中將Cache中的新數據遺失,造成錯誤地讀數據,確保Cache中更新過程的數據不會因覆蓋而消失,必須將Cache中的數據更新及時準確地反映到主存儲器中,這是一個Cache寫入過程,Cache寫入的方式通常采用直寫式、緩沖直寫式與回寫式三種,下面比較介紹這三種Cache寫入方式。
1- 直寫式(Write Through)系統
CPU對Cache寫入時,將數據同時寫入到主存儲器中,這樣可保證Cache中的內容與主存儲器的內容完全一致。這種方式比較直觀,而且簡單、可靠,但由于每次對Cache更新時都要對主存儲器進行寫操作,而這必須通過系統總線來完成,因此總線工作頻繁,系統運行速度就會受到影響。
2-緩沖直寫式(Post Wirte)系統
為解決直寫式系統對總線速度的影響問題,在主存儲器的數據寫入時增加緩沖器區。當要寫入主存儲器的數據被緩沖器鎖存后,CPU便可執行下一個周期的操作,不必等待數據寫入主存儲器。這相對于給主存儲器增加了一個單向單次高速緩存。
比如,在寫入周期之后可以緊接著一個數據已存在于Cache中的讀取周期,這樣就可避免直寫式系統造成的操作延時,但這個緩沖器只能存儲一次寫入的數據,當連續兩次寫操作發生時,CPU仍需等待。
3-回寫式(Write Back)系統
前面兩種寫入方式系統,都是在寫Cache的同時對主存儲器進行寫操作。實際上這不僅是對總線帶寬的占用,浪費了寶貴的執行時間,而且在有些情況下是不必要的,可以通過增加額外的標準來判斷是否有必要更新數據。回寫式系統就是通過在Cache中的每一數據塊的標志字段中加入一更新位,解決主存儲器不必要的寫操作。
比如,若Cache中的數據曾被CPU更新過但還未更新主存儲器,則該更新位被置1。每次CPU將一塊新內容寫入Cache時,首先檢查Cache中該數據塊的更新位,若更新位為0,則將數據直接寫入Cache;反之,若更新位為1,則先將Cache中的該項內容寫入到主存儲器中相應的位置,再將新數據寫回Cache中。
與直寫式系統相比,回寫式系統可省下一些不必要的立即回寫操作,而在許多情況下這是很頻繁出現的。即使一個Cache被更新,若未被新的數據所取代,則沒有必要立刻進行主存儲器的寫操作。也就是說,實際寫入主存儲器的次數,可能少于CPU實際所執行寫入周期的次數,但回寫式系統的結構較復雜,Cache也必須用額外的容量來存儲標志。由于回寫系統的高效率,現代的Cache大多采取這種方式進行操作。
1.4 關于Write-through和Write-back
1-對于磁盤操作來說
write-through的意思是寫操作根本不使用緩存,數據總是直接寫入磁盤,關閉寫緩存,可釋放緩存用于讀操作(緩存被讀寫操作共用)。
write-back的意思是數據不直接被寫入磁盤,而是先寫入緩存,再由控制器將緩存內未寫入磁盤的數據寫入磁盤,從應用程序的角度看,比等待完成磁盤寫入操作要快得多,因此可以提高寫性能。
但是write-back(write cache)方式通常在磁盤負荷較輕時速度更快。負荷重時,每當數據被寫入緩存后,就要馬上再寫入磁盤以釋放緩存來保存將要寫入的新數據,這時如果數據直接寫入磁盤,控制器會以更快的速度運行。因此,負荷重時,將數據先寫入緩存反而會降低吞吐量。
2-對于CPU內部的cache緩沖模式來說
Write-Through和Write-Back,前者是按順序來一個寫一個,而后者則是先將資料按一定數量保存在緩沖區中,然后將相同位置的數據一次性寫出。舉例說明:有一部電梯,如果按先入先出的原則,即write through模式,第一個人去3樓,第二個去2樓,第三個也去3樓,那么這電梯就得先到3樓,然后到2樓,再去3樓。
但如果在write back模式下,電梯先到2樓把第二個人送出去,然后再到3樓把第一個人和第三個人送出去,效率顯然高多了。早期的cache只有write through模式,但現在的cache都使用write back模式了。
3-其他的解釋
?Write-Through:在write的時候,同步更新cache和memory中的數據。
?Write-Back:在write的時候更新cache,但是memory中的數據不一定同步更新,只有當cache到一定程度才會把cache中的數據刷到memory中,或者通過cache指令刷新,不會同步自動刷新。
?cache line的意思是假設你那條指令只要從memory中讀4個字節,但是一般來說你接下來的指令很有可能要讀這4個字節后面的數據,所以一般硬件會多讀一些數據進入cache,比如64字節,那么這64字節就是一個cache line。而如果你這個cache line里的數據長時間不被CPU訪問,那么這個cache line可能會被選中換出,這時候就必須把cache里被改過的信息寫回memory了。
1.5 Cache替換策略
Cache和存儲器一樣具有兩種基本操作,即讀操作和寫操作。當CPU發出讀操作命令時,根據它產生的主存地址分為兩種情形:一種是需要的數據已在Cache中,那么只需要直接訪問Cache,從對應單元中讀取信息到數據總線即可;
另一種是需要的數據尚未裝入Cache,CPU需要從主存中讀取信息的同時,Cache替換部件把該地址所在的那塊存儲內容從主存復制到Cache中。若Cache中相應位置已被字塊占滿,就必須去掉舊的字塊。常見的替換策略有以下兩種:
1-先進先出策略(FIFO)
FIFO(First In First Out)策略總是把最先調入的Cache字塊替換出去,它不需要隨時記錄各個字塊的使用情況,較容易實現。缺點是經常使用的塊,如一個包含循環程序的塊也可能由于它是最早的塊而被替換掉。
2-最近最少使用策略(LRU)
LRU(Least Recently Used)策略是把當前近期Cache中使用次數最少的信息塊替換出去,這種替換算法需要隨時記錄Cache中字塊的使用情況。LRU的平均命中率比FIFO高,在組相聯映像方式中,當分組容量加大時,LRU的命中率也會提高。
1.6 使用Cache的必要性
所謂Cache即高速緩沖存儲器,它位于CPU與主存即DRAM之間,是通常由SRAM構成的規模較小但存取速度很快的存儲器。
目前計算機主要使用的內存為DRAM,它具有價格低、容量大等特點,但由于使用電容存儲信息,存取速度難以提高,而CPU每執行一條指令都要訪問一次或多次主存,DRAM的讀寫速度遠低于CPU速度,因此為了實現速度上的匹配,只能在CPU指令周期中插入wait狀態,高速CPU處于等待狀態將大大降低系統的執行效率。
由于SRAM采用了與CPU相同的制作工藝,因此與DRAM相比,它的存取速度快,但體積大、功耗大、價格高,不可能也不必要將所有的內存都采用SRAM。
因此為了解決速度與成本的矛盾就產生了一種分級處理的方法,即在主存和CPU之間加裝一個容量相對較小的SRAM作為高速緩沖存儲器。
當采用Cache后,在Cache中保存著主存中部分內容的副本(稱為存儲器映像),CPU在讀寫數據時,首先訪問Cache(由于Cache的速度與CPU相當,所以CPU可以在零等待狀態下完成指令的執行),只有當Cache中無CPU所需的數據時(這稱之“未命中”,否則稱為“命中”),CPU才去訪問主存。
而目前大容量Cache能使CPU訪問Cache命中率高達90%~98%,從而大大提高了CPU訪問數據的速度,提高了系統的性能。
1.7 使用Cache的可行性
對大量的典型程序的運行情況分析結果表明,在一個較短的時間內,由程序產生的地址往往集中在存儲器邏輯地址空間的很小范圍內。
在多數情況下,指令是順序執行的,因此指令地址的分布就是連續的,再加上循環程序段和子程序段要重復執行多次,因此對這些地址的訪問就自然具有時間上集中分布的趨向。
數據的這種集中傾向不如指令明顯,但對數組的訪問以及工作單元的選擇都可以使存儲器地址相對集中。這種對局部范圍的存儲器地址的頻繁訪問,而對此范圍以外的地址則訪問甚少的現象稱為程序訪問的局部性。
根據程序的局部性原理,在主存和CPU之間設置Cache,把正在執行的指令地址附近的一部分指令或數據從主存裝入Cache中,供CPU在一段時間內使用,是完全可行的。
審核編輯:湯梓紅
-
處理器
+關注
關注
68文章
19165瀏覽量
229128 -
存儲器
+關注
關注
38文章
7452瀏覽量
163606 -
cpu
+關注
關注
68文章
10825瀏覽量
211150 -
計算機
+關注
關注
19文章
7421瀏覽量
87716 -
Cache
+關注
關注
0文章
129瀏覽量
28298
原文標題:參考資料
文章出處:【微信號:IP與SoC設計,微信公眾號:IP與SoC設計】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Cache的工作原理
高速緩存(Cache),高速緩存(Cache)原理是什么?

cache結構與工作原理
Buffer和Cache的定義
什么是 Cache? Cache讀寫原理
深入理解Cache工作原理
深入理解CACHE VIPT與PIPT的工作原理
Cache的原理和地址映射
Cache分類與替換算法
Cache內容鎖定是什么
Cache工作原理是什么





 工商網監
工商網監
評論