 Python 如何獲取旅游景點信息
Python 如何獲取旅游景點信息
今天將手把手教你使用線程池爬取同程旅行的景點信息及評論數據并做詞云、數據可視化!!!帶你了解各個城市的游玩景點信息。
在開始爬取數據之前,我們首先來了解一下線程。
線程
進程 :進程是代碼在數據集合上的一次運行活動,是系統進行資源分配和調度的基本單位。
線程 :是輕量級的進程,是程序執行的最小單元,是進程的一個執行路徑。
一個進程中至少有一個線程,進程中的多個線程共享進程的資源。
線程生命周期
在創建多線程之前,我們先來學習一下線程生命周期,如下圖所示:
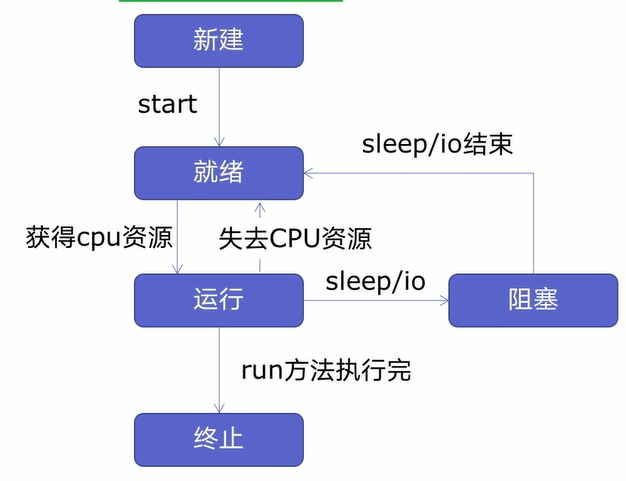
由圖可知,線程可以分為五個狀態——新建、就緒、運行、阻塞、終止。
首先新建一個線程并開啟線程后線程進入就緒狀態,就緒狀態的線程不會馬上運行,要獲得CPU資源才會進入運行狀態,在進入運行狀態后,線程有可能會失去CPU資源或者遇到休眠、io操作(讀寫等操作)線程進入就緒狀態或者阻塞狀態,要等休眠、io操作結束或者重新獲得CPU資源后,才會進入運行狀態,等到運行完后進入終止狀態。
注意:新建線程系統是需要分配資源的,終止線程系統是需要回收資源的,那么如何減去新建/終止線程的系統開銷呢,這時我們可以創建線程池來重用線程,這樣就可以減少系統的開銷了。
在創建線程池之前,我們先來學習如何創建多線程。
創建多線程
創建多線程可以分為四步:
- 創建函數;
- 創建線程;
- 啟動線程;
- 等待結束;
創建函數
為了方便演示,我們拿博客園的網頁做爬蟲函數,具體代碼如下所示:
import requests
urls=[
f'https://www.cnblogs.com/#p{page}'
for page in range(1,50)
]
def get_parse(url):
response=requests.get(url)
print(url,len(response.text))
首先導入requests網絡請求庫,把我們所有的要爬取的URL保存在列表中,然后自定義函數get_parse來發送網絡請求、打印請求的URL和響應的字符長度。
創建線程
在上一步我們創建了爬蟲函數,接下來將創建線程了,具體代碼如下所示:
import threading
#多線程
def multi_thread():
threads=[]
for url in urls:
threads.append(
threading.Thread(target=get_parse,args=(url,))
)
首先我們導入threading模塊,自定義multi_thread函數,再創建一個空列表threads來存放線程任務,通過threading.Thread()方法來創建線程。其中:
- target為運行函數;
- args為運行函數所需的參數。
注意args中的參數要以元組的方式傳入,然后通過.append()方法把線程添加到threads空列表中。
啟動線程
線程已經創建好了,接下來將啟動線程了,啟動線程很簡單,具體代碼如下所示:
for thread in threads:
thread.start()
首先我們通過for循環把threads列表中的線程任務獲取下來,通過.start()來啟動線程。
等待結束
啟動線程后,接下來將等待線程結束,具體代碼如下所示:
for thread in threads:
thread.join()
和啟動線程一樣,先通過for循環把threads列表中的線程任務獲取下來,再使用.join()方法等待線程結束。
多線程已經創建好了,接下來將測試一下多線程的速度如何,具體代碼如下所示:
if __name__ == '__main__':
t1=time.time()
multi_thread()
t2=time.time()
print(t2-t1)
運行結果如下圖所示:
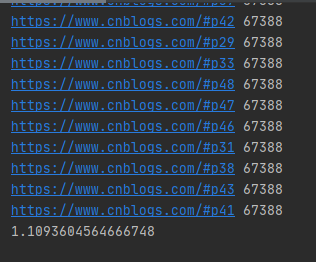
多線程爬取50個博客園網頁只要1秒多,而且多線程的發送網絡請求的URL是隨機的。
我們來測試一下單線程的運行時間,具體代碼如下所示:
if __name__ == '__main__':
t1=time.time()
for i in urls:
get_parse(i)
t2=time.time()
print(t2-t1)
運行結果如下圖所示:
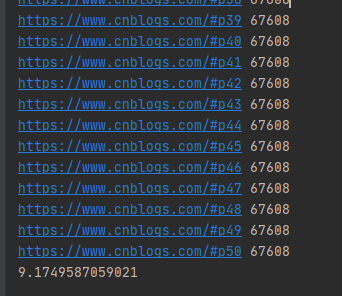
單線程爬取50個博客園網頁用了9秒多,單線程的發送網絡請求的URL是按順序的。
在上面我們說了,新建線程系統是需要分配資源的,終止線程系統是需要回收資源的,為了減少系統的開銷,我們可以創建線程池。
線程池原理
一個線程池由兩部分組成,如下圖所示:
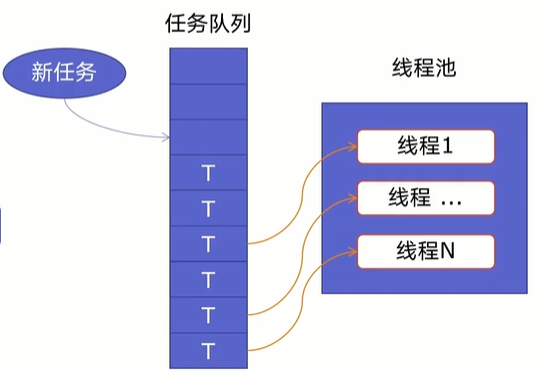
- 線程池:里面提前建好N個線程,這些都會被重復利用;
- 任務隊列:當有新任務的時候,會把任務放在任務隊列中。
當任務隊列里有任務時,線程池的線程會從任務隊列中取出任務并執行,執行完任務后,線程會執行下一個任務,直到沒有任務執行后,線程會回到線程池中等待任務。
使用線程池可以處理突發性大量請求或需要大量線程完成任務(處理時間較短的任務)。
好了,了解了線程池原理后,我們開始創建線程池。
線程池創建
Python提供了ThreadPoolExecutor類來創建線程池,其語法如下所示:
ThreadPoolExecutor(max_workers=None, thread_name_prefix='', initializer=None, initargs=())
其中:
- max_workers:最大線程數;
- thread_name_prefix:允許用戶控制由線程池創建的threading.Thread工作線程名稱以方便調試;
- initializer:是在每個工作者線程開始處調用的一個可選可調用對象;
- initargs:傳遞給初始化器的元組參數。
注意:在啟動 max_workers 個工作線程之前也會重用空閑的工作線程。
在ThreadPoolExecutor類中提供了map()和submit()函數來插入任務隊列。其中:
map()函數
map()語法格式為:
map(調用方法,參數隊列)
具體示例如下所示:
import requestsimport concurrent.futuresimport timeurls=[ f'https://www.cnblogs.com/#p{page}' for page in range(1,50)]def get_parse(url): response=requests.get(url) return response.textdef map_pool(): with concurrent.futures.ThreadPoolExecutor(max_workers=20) as pool: htmls=pool.map(get_parse,urls) htmls=list(zip(urls,htmls)) for url,html in htmls: print(url,len(html))if __name__ == '__main__': t1=time.time() map_pool() t2=time.time() print(t2-t1)
首先我們導入requests網絡請求庫、concurrent.futures模塊,把所有的URL放在urls列表中,然后自定義get_parse()方法來返回網絡請求返回的數據,再自定義map_pool()方法來創建代理池,其中代理池的最大max_workers為20,調用map()方法把網絡請求任務放在任務隊列中,在把返回的數據和URL合并為元組,并放在htmls列表中。
運行結果如下圖所示:
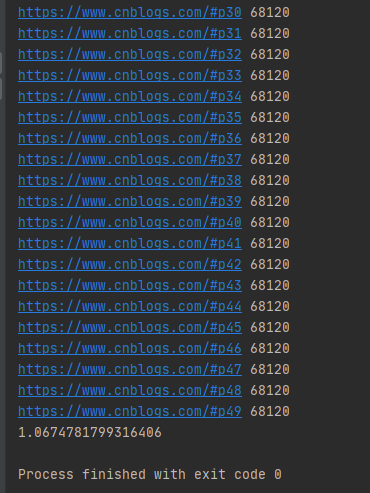
可以發現map()函數返回的結果和傳入的參數順序是對應的。
注意:當我們直接在自定義方法get_parse()中打印結果時,打印結果是亂序的。
submit()函數
submit()函數語法格式如下:
submit(調用方法,參數)
具體示例如下:
def submit_pool(): with concurrent.futures.ThreadPoolExecutor(max_workers=20)as pool: futuress=[pool.submit(get_parse,url)for url in urls] futures=zip(urls,futuress) for url,future in futures: print(url,len(future.result()))
運行結果如下圖所示:
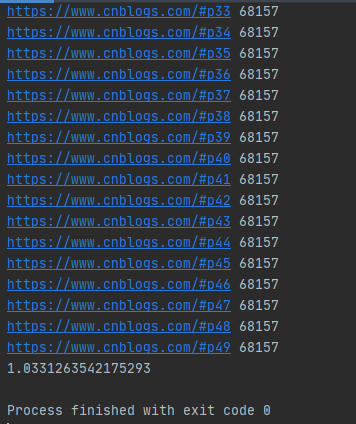
注意:submit()函數輸出結果需需要調用result()方法。
好了,線程知識就學到這里了,接下來開始我們的爬蟲。
爬前分析
首先我們進入同程旅行的景點網頁并打開開發者工具,如下圖所示:
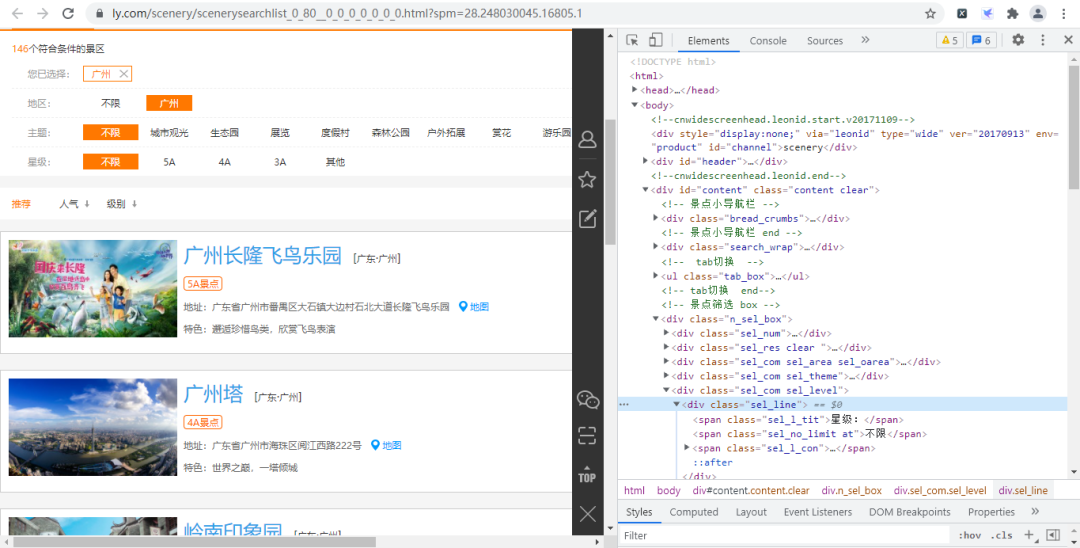
經過尋找,我們發現各個景點的基礎信息(詳情頁URL、景點id等)都存放在下圖的URL鏈接中,
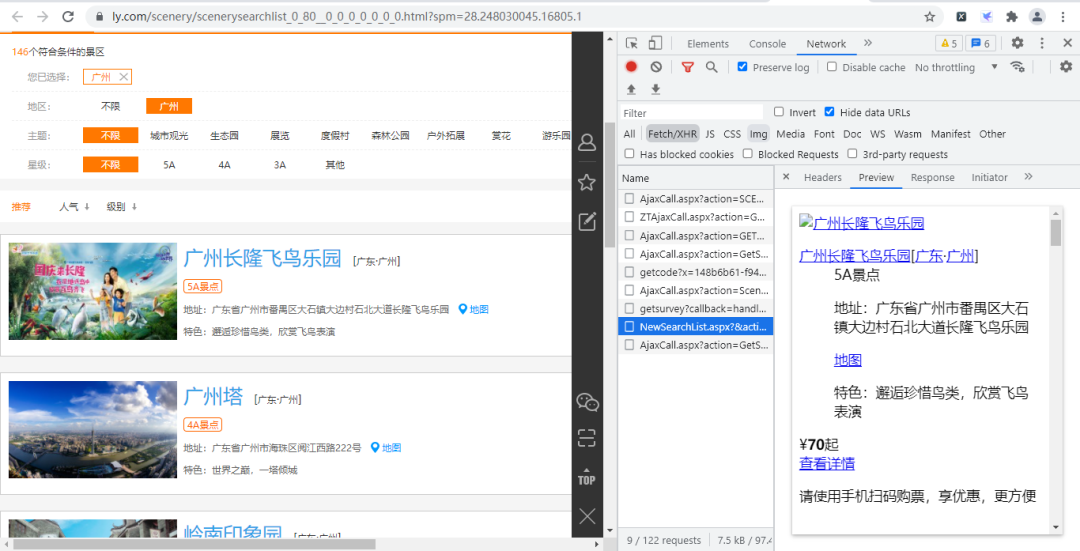
其URL鏈接為:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=2&kw=&pid=6&cid=80&cyid=0&sort=&isnow=0&spType=&lbtypes=&IsNJL=0&classify=0&grade=&dctrack=1%CB%871629537670551030%CB%8720%CB%873%CB%872557287248299209%CB%870&iid=0.6901326566387387
經過增刪改查操作,我們可以把該URL簡化為:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=1&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0
其中page為我們翻頁的重要參數。
打開該URL鏈接,如下圖所示:
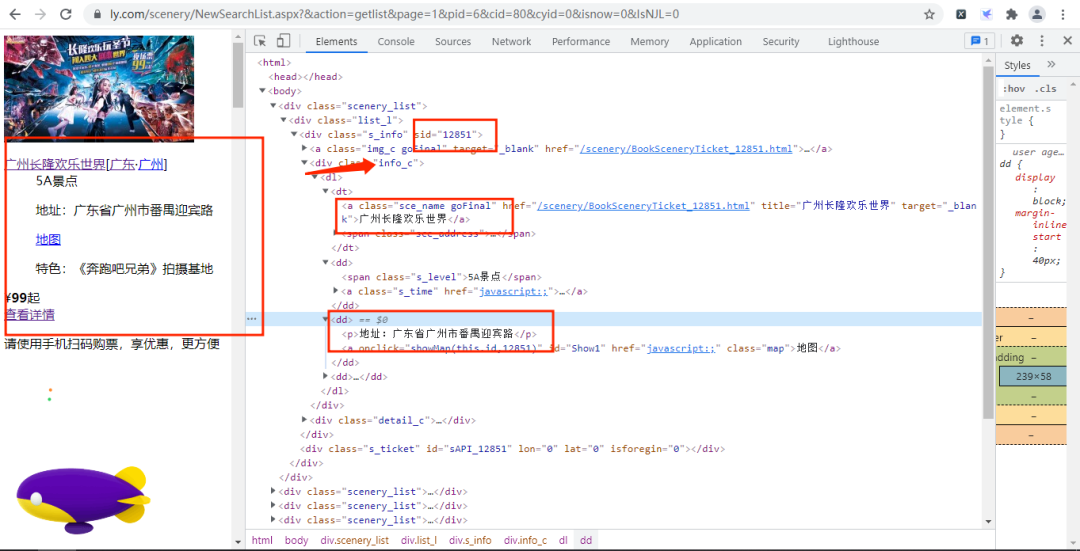
通過上面的URL鏈接,我們可以獲取到很多景點的基礎信息,隨機打開一個景點的詳情網頁并打開開發者模式,經過查找,評論數據存放在如下圖的URL鏈接中,
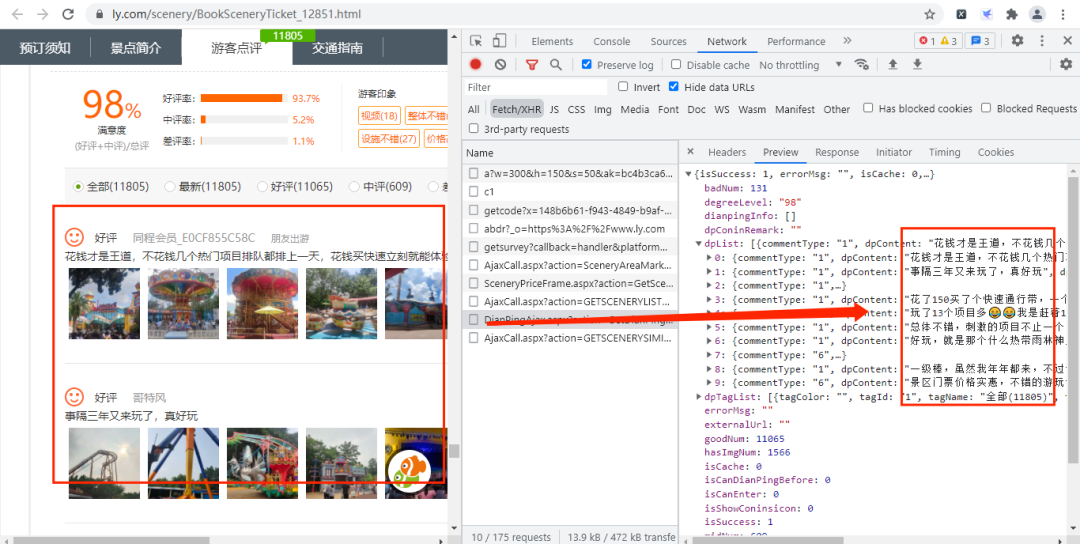
其URL鏈接如下所示:
https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid=12851&page=1&pageSize=10&labId=1&sort=0&iid=0.48901069375088
其中:action、labId、iid、sort為常量,sid是景點的id,page控制翻頁,pageSize是每頁獲取的數據量。
在上上步中,我們知道景點id的存放位置,那么構造評論數據的URL就很簡單了。
實戰演練
這次我們爬蟲步驟是:
- 獲取景點基本信息
- 獲取評論數據
- 創建MySQL數據庫
- 保存數據
- 創建線程池
- 數據分析
獲取景點基本信息
首先我們先獲取景點的名字、id、價格、特色、地點和等級,主要代碼如下所示:
def get_parse(url): response=requests.get(url,headers=headers) Xpath=parsel.Selector(response.text) data=Xpath.xpath('/html/body/div') for i in data: Scenery_data={ 'title':i.xpath('./div/div[1]/div[1]/dl/dt/a/text()').extract_first(), 'sid':i.xpath('//div[@class="list_l"]/div/@sid').extract_first(), 'Grade':i.xpath('./div/div[1]/div[1]/dl/dd[1]/span/text()').extract_first(), 'Detailed_address':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:',''), 'characteristic':i.xpath('./div/div[1]/div[1]/dl/dd[3]/p/text()').extract_first(), 'price':i.xpath('./div/div[1]/div[2]/div[1]/span/b/text()').extract_first(), 'place':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:','')[6:8] }
首先自定義方法get_parse()來發送網絡請求后使用parsel.Selector()方法來解析響應的文本數據,然后通過xpath來獲取數據。
獲取評論數據
獲取景點基本信息后,接下來通過景點基本信息中的sid來構造評論信息的URL鏈接,主要代碼如下所示:
def get_data(Scenery_data): for i in range(1,3): link = f'https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid={Scenery_data["sid"]}&page={i}&pageSize=100&labId=1&sort=0&iid=0.20105777381446832' response=requests.get(link,headers=headers) Json=response.json() commtent_detailed=Json.get('dpList') # 有評論數據 if commtent_detailed!=None: for i in commtent_detailed: Comment_information={ 'dptitle':Scenery_data['title'], 'dpContent':i.get('dpContent'), 'dpDate':i.get('dpDate')[5:7], 'lineAccess':i.get('lineAccess') } #沒有評論數據 elif commtent_detailed==None: Comment_information={ 'dptitle':Scenery_data['title'], 'dpContent':'沒有評論', 'dpDate':'沒有評論', 'lineAccess':'沒有評論' }
首先自定義方法get_data()并傳入剛才獲取的景點基礎信息數據,然后通過景點基礎信息的sid來構造評論數據的URL鏈接,當在構造評論數據的URL時,需要設置pageSize和page這兩個變量來獲取多條評論和進行翻頁,構造URL鏈接后就發送網絡請求。
這里需要注意的是:有些景點是沒有評論,所以我們需要通過if語句來進行設置。
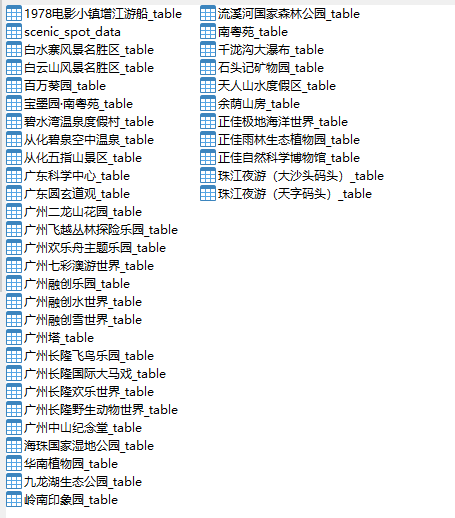
創建MySQL數據庫
這次我們把數據存放在MySQL數據庫中,由于數據比較多,所以我們把數據分為兩種數據表,一種是景點基礎信息表,一種是景點評論數據表,主要代碼如下所示:
#創建數據庫def create_db(): db=pymysql.connect(host=host,user=user,passwd=passwd,port=port) cursor=db.cursor() sql='create database if not exists commtent default character set utf8' cursor.execute(sql) db.close() create_table()#創建景點信息數據表def create_table(): db=pymysql.connect(host=host,user=user,passwd=passwd,port=port,db='commtent') cursor=db.cursor() sql = 'create table if not exists Scenic_spot_data (title varchar(255) not null, link varchar(255) not null,Grade varchar(255) not null, Detailed_address varchar(255) not null, characteristic varchar(255)not null, price int not null, place varchar(255) not null)' cursor.execute(sql) db.close()
首先我們調用pymysql.connect()方法來連接數據庫,通過.cursor()獲取游標,再通過.execute()方法執行單條的sql語句,執行成功后返回受影響的行數,然后關閉數據庫連接,最后調用自定義方法create_table()來創建景點信息數據表。
這里我們只給出了創建景點信息數據表的代碼,因為創建數據表只是sql這條語句稍微有點不同,其他都一樣,大家可以參考這代碼來創建各個景點評論數據表。
保存數據
創建好數據庫和數據表后,接下來就要保存數據了,主要代碼如下所示:
#保存景點數據到景點數據表中def saving_scenery_data(srr): db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='commtent') cursor = db.cursor() sql = 'insert into Scenic_spot_data(title, link, Grade, Detailed_address, characteristic,price,place) values(%s,%s,%s,%s,%s,%s,%s)' try: cursor.execute(sql, srr) db.commit() except: db.rollback() db.close()
首先我們調用pymysql.connect()方法來連接數據庫,通過.cursor()獲取游標,再通過.execute()方法執行單條的sql語句,執行成功后返回受影響的行數,使用了try-except語句,當保存的數據不成功,就調用rollback()方法,撤消當前事務中所做的所有更改,并釋放此連接對象當前使用的任何數據庫鎖。
注意:srr是傳入的景點信息數據。
創建線程池
好了,單線程爬蟲已經寫好了,接下來將創建一個函數來創建我們的線程池,使單線程爬蟲變為多線程,主要代碼如下所示:
urls = [ f'https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page={i}&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0' for i in range(1, 6)]def multi_thread(): with concurrent.futures.ThreadPoolExecutor(max_workers=8)as pool: h=pool.map(get_parse,urls)if __name__ == '__main__': create_db() multi_thread()
創建線程池的代碼很簡單就一個with語句和調用map()方法
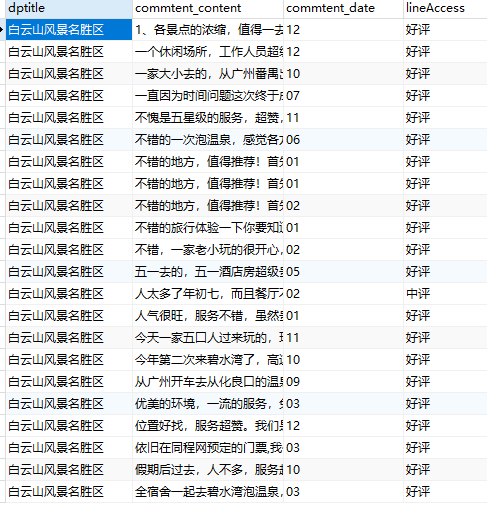
運行結果如下圖所示:
-
cpu
+關注
關注
68文章
10702瀏覽量
209371 -
數據
+關注
關注
8文章
6715瀏覽量
88311 -
線程池
+關注
關注
0文章
55瀏覽量
6810 -
python
+關注
關注
53文章
4753瀏覽量
84078
發布評論請先 登錄
相關推薦
手機導游冬日暖游Android版評測
旅游景點無線覆蓋方案
使用旅游機器人需要注意哪些問題?
旅游景點使用自助售票機的好處有哪些呢?
HarmonyOS原子化服務(五)策劃文案初稿案例參考
HarmonyOS原子化服務案例分享-廈門旅游攻略
Google Earth在旅游景點展示中的應用
廣西巴馬長壽旅游信息系統的開發研究
基于互聯網信息的多約束多目標旅游路線推薦






 工商網監
工商網監
評論