 智能離線語音識別全屋智能語音控制方案
智能離線語音識別全屋智能語音控制方案
概述
方便用戶控制智能設備、電器,用戶只須說一下口令就實現制智能設備、電器。
特性
電氣特性
2、功耗:
待機-----0.1mA
工作-----300mA
Zigbee相關參數(了解Zigbee,請參閱:介紹一款高性比的Zigbee無線模塊,我們燒錄好程序的,開箱即用)
通訊頻率:2.4G
接收靈敏度:-95dBM
通信協議:ZigBee3.0協議
發射功率:20.5dB
語音相關參數
支持語種: 默認普通話+自學習語言及其他語種
揚聲器: 4歐姆2.5W
識別距離:遠場離線語音識別15米內
系統框架
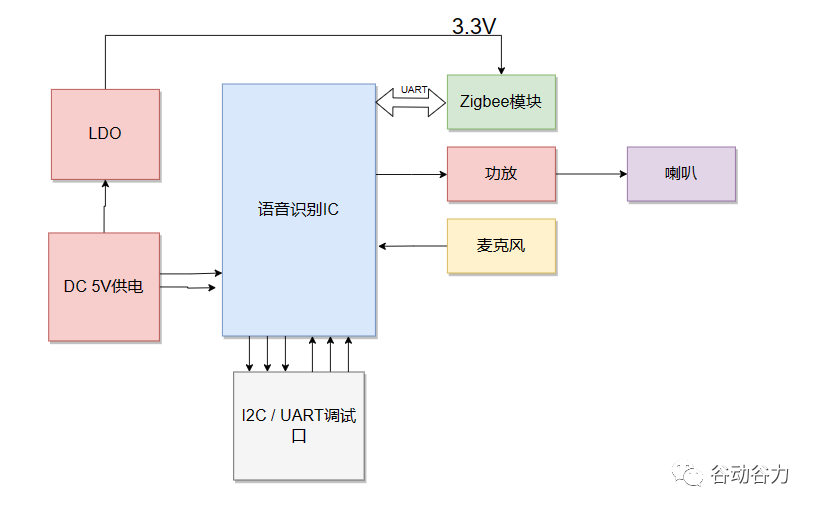
語音識別原理
語音識別的本質就是將語音序列轉換為文本序列,其常用的系統框架如下:
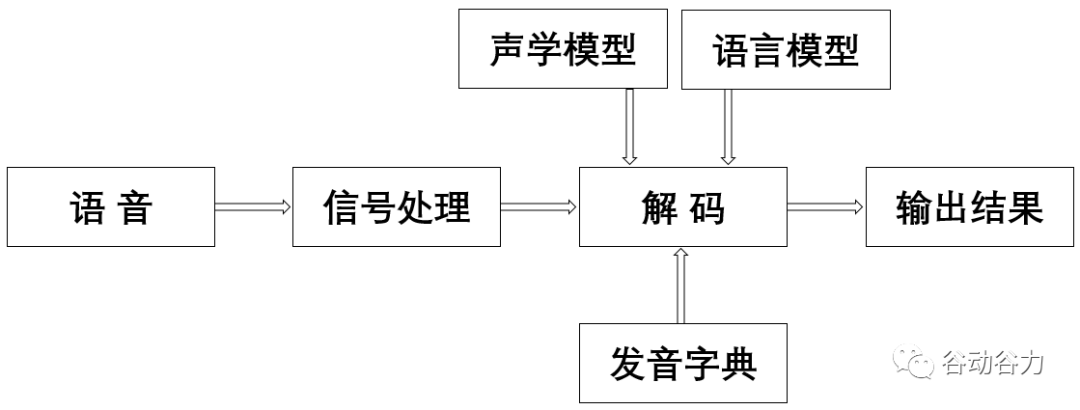
接下來對語音識別相關技術進行介紹,為了便于整體理解,首先,介紹語音前端信號處理的相關技術,然后,解釋語音識別基本原理,并展開到聲學模型和語言模型的敘述。
一、語音前處理
前端的信號處理是對原始語音信號進行的相關處理,使得處理后的信號更能代表語音的本質特征,相關技術點如下表所述:
1、語音端點檢測
語音端點檢測(VAD)用于檢測出語音信號的起始位置,分離出語音段和非語音(靜音或噪聲)段。VAD算法大致分為三類:基于閾值的VAD、基于分類器的VAD和基于模型的VAD。
基于閾值的VAD是通過提取時域(短時能量、短時過零率等)或頻域(MFCC、譜熵等)特征,通過合理的設置門限,達到區分語音和非語音的目的;
基于分類的VAD是將語音活動檢測作為(語音和非語音)二分類,可以通過機器學習的方法訓練分類器,達到語音活動檢測的目的;
基于模型的VAD是構建一套完整的語音識別模型用于區分語音段和非語音段,考慮到實時性的要求,并未得到實際的應用。
2、降噪
在生活環境中通常會存在例如空調、風扇等各種噪聲,降噪算法目的在于降低環境中存在的噪聲,提高信噪比,進一步提升識別效果。
常用降噪算法包括自適應LMS和維納濾波等。
3、回聲消除
回聲存在于雙工模式時,麥克風收集到揚聲器的信號,比如在設備播放音樂時,需要用語音控制該設備的場景。
回聲消除通常使用自適應濾波器實現的,即設計一個參數可調的濾波器,通過自適應算法(LMS、NLMS等)調整濾波器參數,模擬回聲產生的信道環境,進而估計回聲信號進行消除。
4、混響消除
語音信號在室內經過多次反射之后,被麥克風采集,得到的混響信號容易產生掩蔽效應,會導致識別率急劇惡化,需要在前端處理。
混響消除方法主要包括:基于逆濾波方法、基于波束形成方法和基于深度學習方法等。
5、聲源定位
麥克風陣列已經廣泛應用于語音識別領域,聲源定位是陣列信號處理的主要任務之一,使用麥克風陣列確定說話人位置,為識別階段的波束形成處理做準備。
聲源定位常用算法包括:基于高分辨率譜估計算法(如MUSIC算法),基于聲達時間差(TDOA)算法,基于波束形成的最小方差無失真響應(MVDR)算法等。
6、波束形成
波束形成是指將一定幾何結構排列的麥克風陣列的各個麥克風輸出信號,經過處理(如加權、時延、求和等)形成空間指向性的方法,可用于聲源定位和混響消除等。
波束形成主要分為:固定波束形成、自適應波束形成和后置濾波波束形成等。
二、語音識別的基本原理
所謂語音識別,就是將一段語音信號轉換成相對應的文本信息,系統主要包含特征提取、聲學模型、語言模型以及字典與解碼四大部分,其中為了更有效地提取特征往往還需要對所采集到的聲音信號進行濾波、分幀等預處理工作,把要分析的信號從原始信號中提取出來;之后,特征提取工作將聲音信號從時域轉換到頻域,為聲學模型提供合適的特征向量;聲學模型中再根據聲學特征性計算每一個特征向量在聲學特征上的得分;而語言模型則根據語言學相關的理論,計算該聲音信號對應可能詞組序列的概率;最后根據已有的字典,對詞組序列進行解碼,得到最后可能的文本表示。其中聲學模型與語言模型的關系,將通過貝葉斯公式表示為:
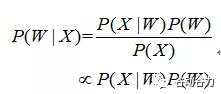
其中,P(X|W)稱之為聲學模型,P(W)稱之為語言模型。大多數的研究將聲學模型和語言模型分開處理,并且,不同廠家的語音識別系統主要體現在聲學模型的差異性上面。此外,基于大數據和深度學習的端到端(Seq-to-Seq)方法也在不斷發展,它直接計算P(X|W),即將聲學模型和語言模型作為整體處理。
三、傳統HMM聲學模型
聲學模型是將語音信號的觀測特征與句子的語音建模單元聯系起來,即計算P(X|W)。我們通常使用隱馬爾科夫模型(Hidden Markov Model,HMM)解決語音與文本的不定長關系,比如下圖的隱馬爾科夫模型中。
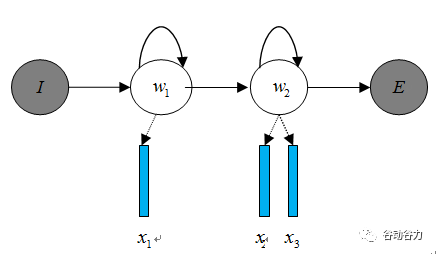
將聲學模型表示為:
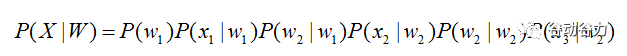
其中,初始狀態概率P(w1)和狀態轉移概率(P(w2|w1)、P(w2|w2))可用通過常規統計的方法計算得出,發射概率(P(x1|w1)、P(wx2|w2)、P(x3|w2))可以通過混合高斯模型GMM或深度神經網絡DNN求解。
傳統的語音識別系統普遍采用基于GMM-HMM的聲學模型,示意圖如下:
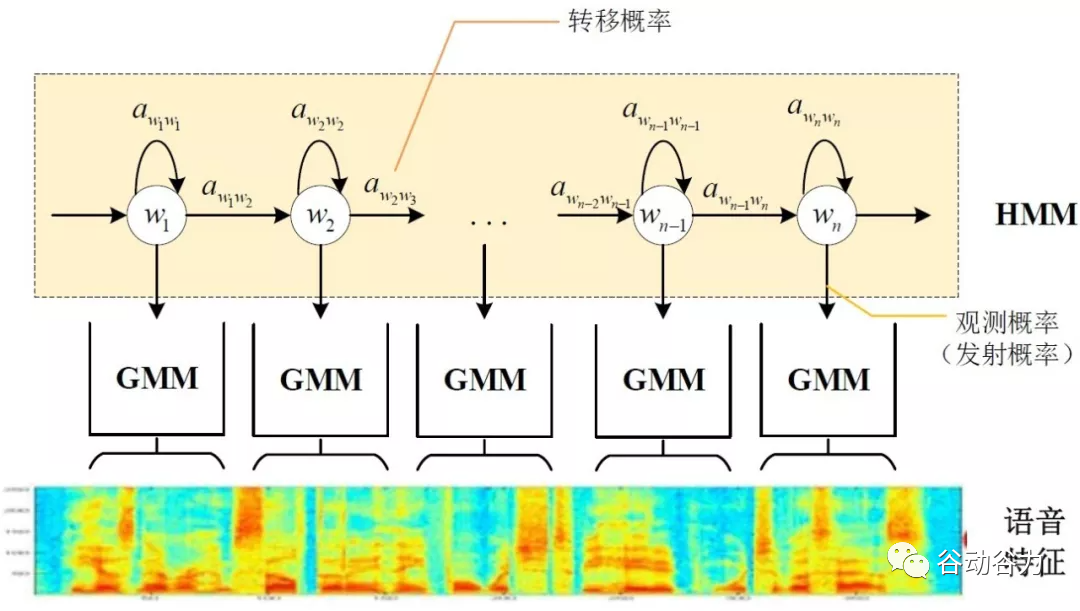
其中,awiwj表示狀態轉移概率P(wj|wi),語音特征表示X=[x1,x2,x3,…],通過混合高斯模型GMM建立特征與狀態之間的聯系,從而得到發射概率P(xj|wi),并且,不同的wi狀態對應的混合高斯模型參數不同。
基于GMM-HMM的語音識別只能學習到語音的淺層特征,不能獲取到數據特征間的高階相關性,DNN-HMM利用DNN較強的學習能力,能夠提升識別性能,其聲學模型示意圖如下:
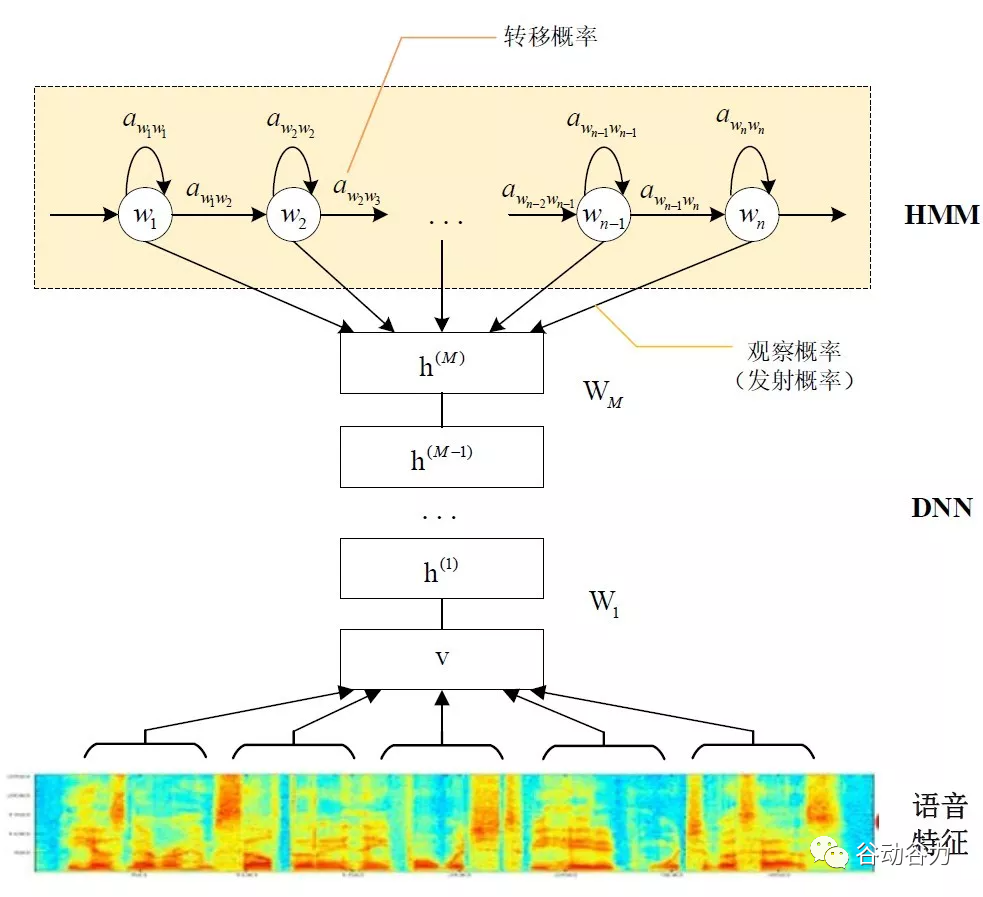
GMM-HMM和DNN-HMM的區別在于用DNN替換GMM來求解發射概率P(xj|wi),GMM-HMM模型優勢在于計算量較小且效果不俗。DNN-HMM模型提升了識別率,但對于硬件的計算能力要求較高。因此,模型的選擇可以結合實際的應用調整。
四、Seq-to-Seq模型
語音識別實際上可以看成兩個序列之間轉換的問題。語音識別實際上的目標就是把輸入的音頻序列轉錄為對應的文本序列,音頻序列可以描述為 O=o1,o2,o3,…,ot 其中oi表示每一幀語音特征,t表示音頻序列的時間步(通常情況下,每秒語音會被分為100幀,每幀可以提取39維或者120維的特征),同樣的,文本序列可以描述為 W=w1,w2,w3,…,wt 其中n表示語音中對應的詞數(不一定是詞,也可能是音素等其他建模單元)。由此可見,語音識別問題可以用序列到序列的模型建模。傳統的語音識別問題是DNN-HMM的混合結構,并且還需要語言模型、發音詞典和解碼器等多個部件共同建模。其中發音詞典的構建需要大量的專家知識,多個模型組件之間也需要單獨訓練不能進行聯合優化。Seq2Seq模型給語音識別建模提供了一種新的解決思路。將Seq2Seq模型應用于語音識別問題有很多明顯的優勢:可以進行端到端聯合優化,徹底擺脫了馬爾科夫假設,不需要發音詞典。
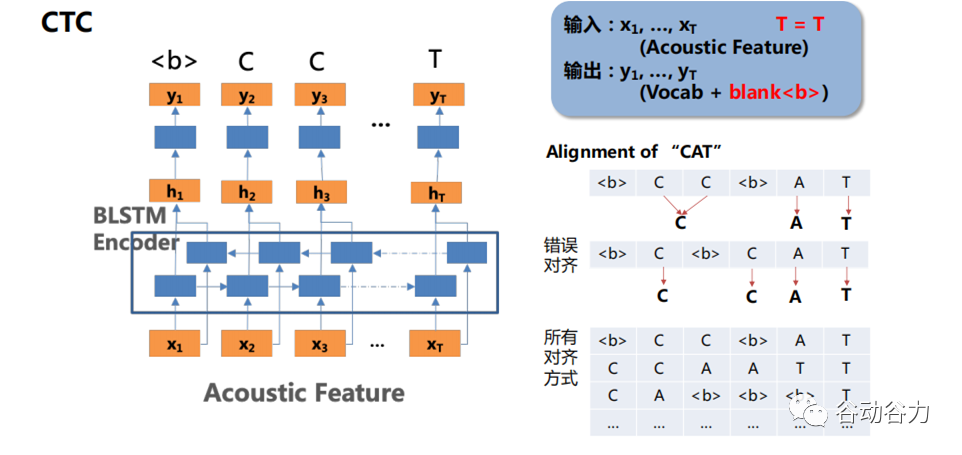
CTC
語音識別中,一般包含語音段和對應的文本標簽,但是卻并不知道具體的對齊關系,即字符和語音幀之間對齊,這就給語音識別訓練任務帶來困難;而CTC在訓練時不關心具體的唯一的對齊關系,而是考慮所有可能對應為標簽的序列概率和,所以比較適合這種類型的識別任務。CTC是和聲學特征序列同步進行解碼,就是每輸入一個特征,就輸出一個label,所以它的輸入和輸出序列長度是相同的。但是我們前面說輸入輸出的長度明顯差別是很大的,所以在CTC里面引入了一個blank的符號,帶有blank的文本序列稱為CTC的一個對齊結果。拿到對齊之后,首先對進行符號去重,再刪掉blank,就恢復到標注的文本了。
RNN Transducer
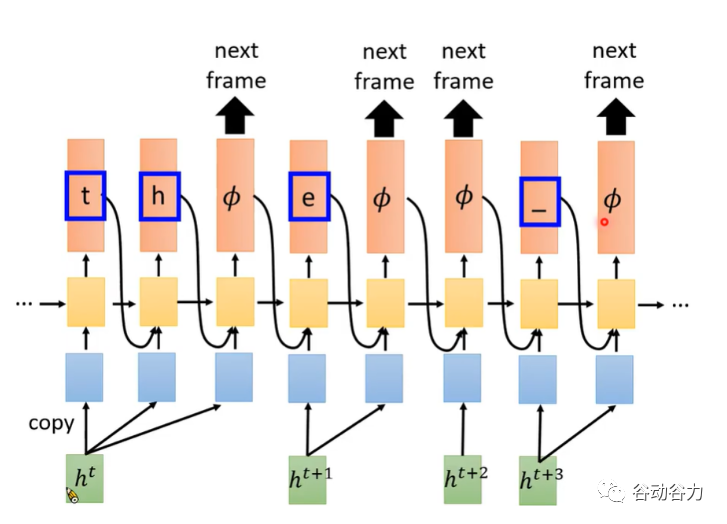
CTC對于語音識別的聲學建模帶來了極大的好處,但是CTC模型仍然存在著很多的問題,其中最顯著的就是CTC假設模型的輸出之間是條件獨立的。這個基本假設與語音識別任務之前存在著一定程度的背離。此外,CTC模型并不具有語言建模能力,同時也并沒有真正的實現端到端的聯合優化。RNN-T不再是一個輸入對應一個輸出的結構,而是使其給一個輸入能夠產生多個token輸出,直到輸出1個空字符?表示需要下一個輸入,也就是說最后的?數量一定是和輸入的長度相同,因為每一幀輸入一定會產生一個?。
五、語言模型
語言模型與文本處理相關,比如我們使用的智能輸入法,當我們輸入“nihao”,輸入法候選詞會出現“你好”而不是“尼毫”,候選詞的排列參照語言模型得分的高低順序。
語音識別中的語言模型也用于處理文字序列,它是結合聲學模型的輸出,給出概率最大的文字序列作為語音識別結果。由于語言模型是表示某一文字序列發生的概率,一般采用鏈式法則表示,如W是由w1,w2,…wn組成,則P(W)可由條件概率相關公式表示為:
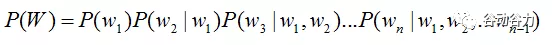
由于條件太長,使得概率的估計變得困難,常見的做法是認為每個詞的概率分布只依賴于前幾個出現的詞語,這樣的語言模型成為n-gram模型。在n-gram模型中,每個詞的概率分布只依賴于前面n-1個詞。例如在trigram(n取值為3)模型,可將上式化簡:
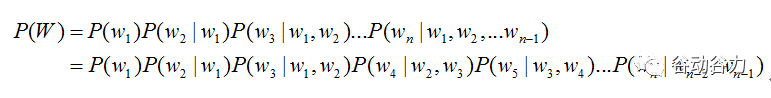
操作說明
此產品必須與我司生產的Zigbee智能網關一起使用,開機后, 聽到“歡迎使用使用小谷離線語音”,則系統啟動成功。
說“小谷同學”喚醒后,說出控制口令即可控制控制智能設備、電器。
Zigbee入網
操作前確保家中入網歐米家智能超級網關, 小歐智能離線語音在無zgibee網絡狀態(LED閃)。
首先,在移動終端打開“歐米家智能”APP;
然后,添加zigbee設備,APP會啟動Zigbee掃描, 當掃描設備時APP會提示找到設備(小歐智能離線語音會熄滅),保存返回即可。
Zigbee退網
方法一:點擊小谷智能離線語音圖標,點刪除圖標即可,退網成功后,燃氣閥門控制器在無zgibee網絡狀態(LED閃)。
方法二:說“小谷同學”喚醒后,說“清除網絡設置”,聽回復后“是”
學習控制指令
說“小谷同學”喚醒后,說“開始語音學習”,聽回復后,說出口令(命令詞),然后在APP上對應操作,則學習完成一條指令錄入,依次重復上述操作,學習完成后,說“結束語音學習”,則退出學習口令模式,切換到語音控制模式。
更改喚醒詞或命令詞
用戶可免代碼開發,會excel表格,就能替換喚醒詞、命令詞,當然可找我們定制開發。
離線語音控制+SOS模塊喚醒詞和命令詞學習與刪除方法
1、學習喚醒詞
喚醒后,說學習喚醒詞,根據語音提示,說喚醒詞3遍
注:只能學習喚醒詞
2、學習命令詞
喚醒后,說"學習命令詞",根據語音提示,說命令詞2遍
注:此更改數量、命令,要改代碼
3、學習結束或中斷學習
學習完全后,說“退出學習"
4、重新學習
學習完全后,說“重新注冊"
5、刪除學習內容
喚醒后,說"我要刪除",根據語音提示,
刪除喚醒詞--說“刪除喚醒詞”
刪除命令詞--說“刪除命令詞”
喚醒詞和命令詞都刪除--說“全部刪除”
刪除結束--說“退出刪除”
審核編輯:湯梓紅
-
ZigBee
+關注
關注
158文章
2269瀏覽量
242552 -
無線模塊
+關注
關注
12文章
622瀏覽量
48454 -
智能語音
+關注
關注
10文章
781瀏覽量
48714 -
語音控制
+關注
關注
5文章
481瀏覽量
28233
原文標題:智能離線語音識別全屋智能語音控制方案
文章出處:【微信號:嵌入式加油站,微信公眾號:嵌入式加油站】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦








 工商網監
工商網監
評論