 ICCV 2023 | 面向視覺-語言導航的實體-標志物對齊自適應預訓練方法
ICCV 2023 | 面向視覺-語言導航的實體-標志物對齊自適應預訓練方法
本文是 ICCV 2023 入選 Oral 論文 Grounded Entity-Landmark Adaptive Pre-training for Vision-and-Language Navigation 的解讀。本論文是某智能人機交互團隊在視覺-語言導航(Vision-and-Language Navigation, VLN)領域的最新工作。該工作構建了 VLN 中首個帶有高質量實體-標志物對齊標注的數據集,并提出實體-標志物對齊的自適應預訓練方法,從而顯著提高了智能體的導航性能。
ICCV 是“計算機視覺三大頂級會議”之一,ICCV 2023 于今年 10 月 2 日至 6 日在法國巴黎舉行,本屆會議共收到全球 8260 篇論文投稿,2161 篇被接收,接收率為 26.16%,其中 152 篇論文被選為口頭報告展示(Oral Presentation),Oral 接收率僅為 1.8%。

論文題目:
Grounded Entity-Landmark Adaptive Pre-training for Vision-and-Language Navigation
論文地址:
https://arxiv.org/abs/2308.12587開源數據集:
https://pan.baidu.com/s/12WTzZ05T8Uxy85znn28dfQ?pwd=64t7代碼地址:
https://github.com/csir1996/vln-gela

引言
視覺-語言導航(Vision-and-Language Navigation, VLN)任務旨在構建一種能夠用自然語言與人類交流并在真實 3D 環境中自主導航的具身智能體。自提出以來,VLN 越來越受到計算機視覺、自然語言處理和機器人等領域的廣泛關注。 如圖 1 所示,將自然語言指令中提過的標志物(物體或者場景)對應到環境中能夠極大的幫助智能體理解環境和指令,由此跨模態對齊是 VLN 中的關鍵步驟。然而,大多數可用的數據集只能提供粗粒度的文本-圖像對齊信號,比如整條指令與整條軌跡的對應或者子指令與子路徑之間的對應,而跨模態對齊監督也都停留在句子級別(sentence-level)。因此,VLN 需要更細粒度(entity-level)的跨模態對齊數據和監督方法以促進智能體更準確地導航。
為解決以上問題,我們提出了一種面向 VLN 的實體-標志物自適應預訓練方法,主要工作與貢獻如下:
1. 我們基于 Room-to-Room(R2R)數據集 [1] 標注實體-標志物對齊,構建了第一個帶有高質量實體-標志物對齊標注的 VLN 數據集,命名為 GEL-R2R;
2. 我們提出一種實體-標志物自適應預訓練 (Grounded Entity-Landmark Adaptive,GELA) 方法,利用 GEL-R2R 數據集顯式監督 VLN 模型學習實體名詞和環境標志物之間的細粒度跨模態對齊;
3. 我們構建的 GELA 模型在兩個 VLN 下游任務上取得了最佳的導航性能,證明了我們數據集和方法的有效性和泛化性。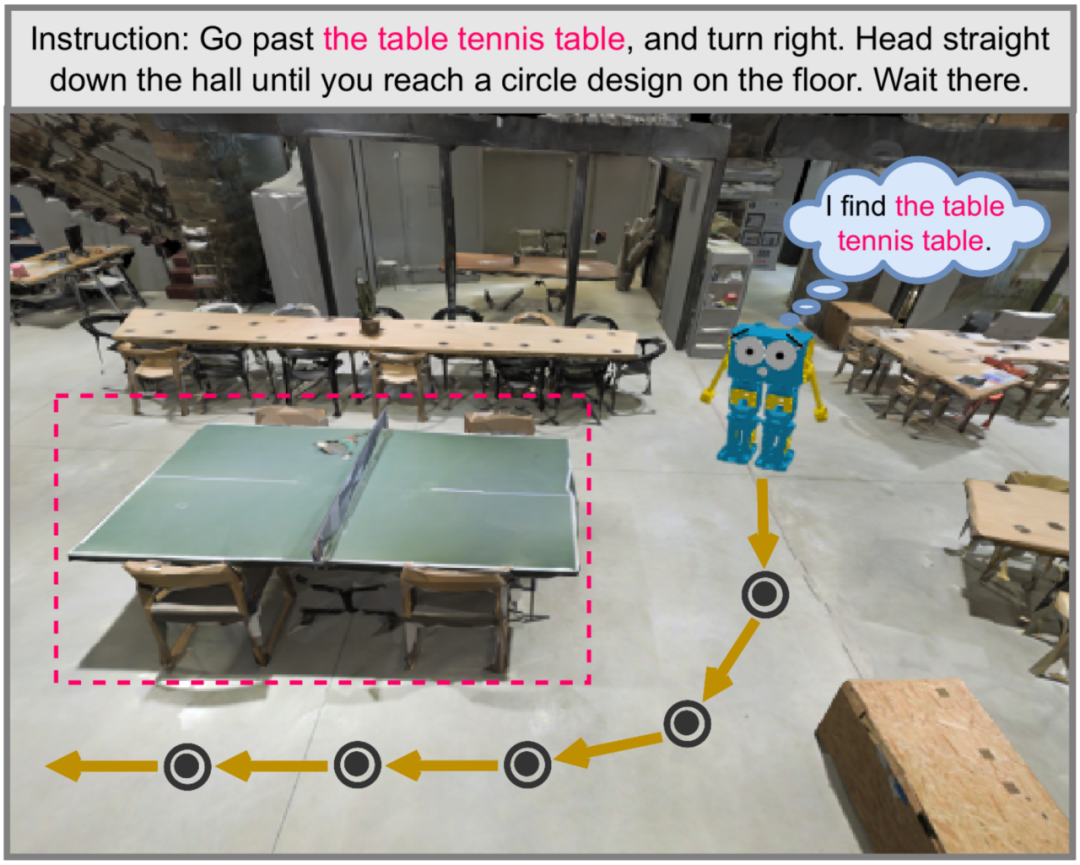 ▲圖1. 具身智能體在3D真實環境中的導航示例
▲圖1. 具身智能體在3D真實環境中的導航示例

GEL-R2R數據集
為了建立指令中實體短語與其周圍環境中相應標志物之間的對齊,我們在 R2R 數據集的基礎上進行了實體-標志物對齊的人工標注,整個流程包括五個階段:
1. 原始數據準備。我們從 Matterport3D 模擬器中采集每個可導航點的全景圖。為了提高標注的效率和準確性,我們在全景圖中標注下一個動作方向,并根據 FG-R2R 數據集 [2] 將每個全景圖與相應的子指令進行對應;
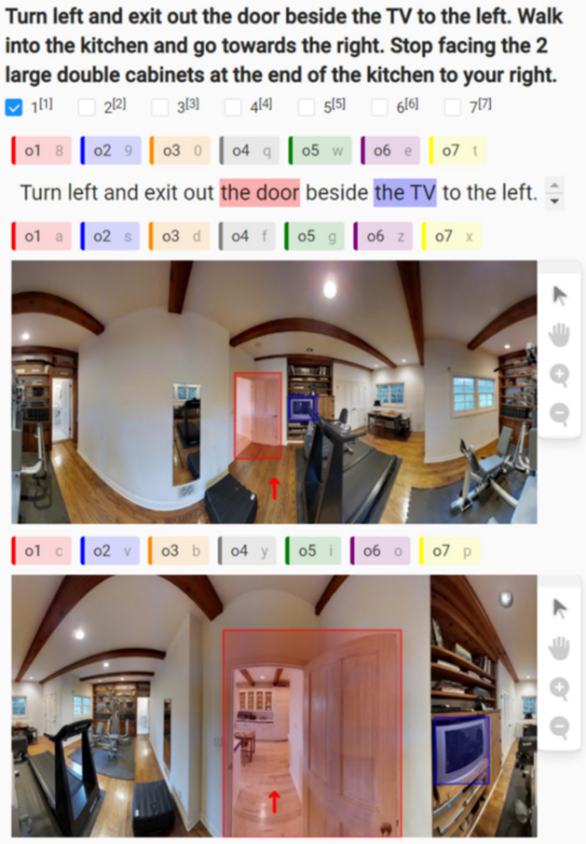
2. 標注工具開發。我們基于 Label-Studio 開發了一個跨模態標注平臺,如圖 2 所示;
3. 標注指南建立。為確保標注的一致性,我們經過預標注之后建立了四個準則來標準化標注指南:
-
對齊準則:指令中的實體短語應與全景圖中的標志物準確匹配
-
自由文本準則:標注自由文本而不是類別
-
文本共指準則:指代相同標志物的實體短語用相同的標簽標注
-
唯一標志物準則:對于一個實體短語,在全景圖中只應標注一個對應的標志物
4. 數據標注與修訂;
5. 數據整合與處理。
 ▲圖3. GEL-R2R數據集統計分析
▲圖3. GEL-R2R數據集統計分析

GELA方法
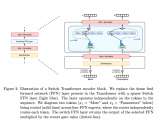
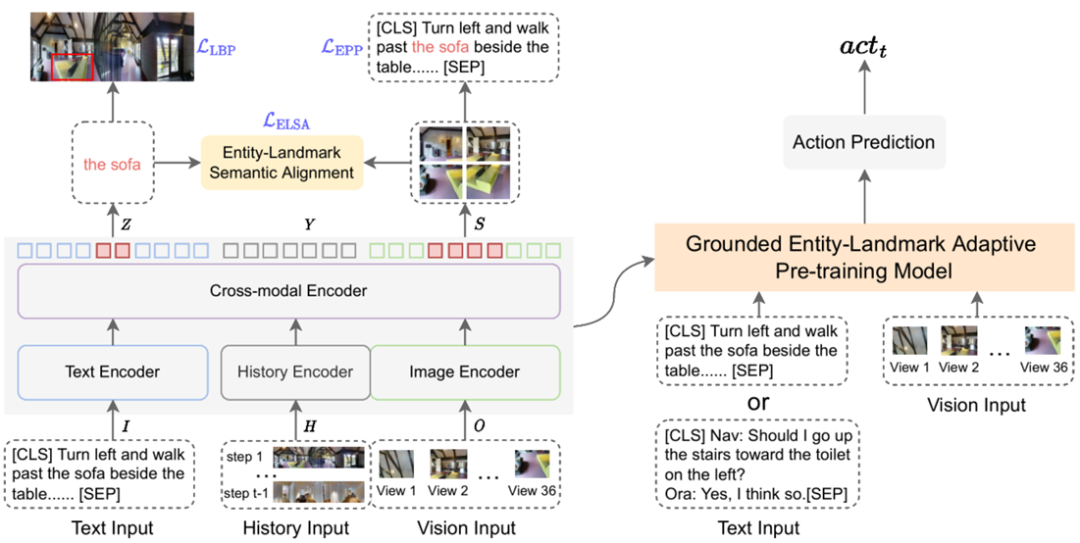 ▲圖4. GELA方法概覽
▲圖4. GELA方法概覽
如圖 4 所示,方法流程分為三個階段:預訓練(pre-training)、自適應預訓練(adaptive pre-training)和微調(fine-tuning)。我們直接在預訓練模型 HAMT [3] 的基礎上進行自適應預訓練,HAMT 模型由文本編碼器、圖像編碼器、歷史編碼器和跨模態編碼器構成。我們將跨模態編碼器輸出的文本向量、歷史向量和圖像向量分別記為 Z、Y 和 S。我們設計了三種自適應預訓練任務:
1. 實體短語預測。在這個任務中,我們通過標注的環境標志物預測其對應的實體短語在指令中的位置。首先將人工標注的實體位置轉化為 L+1 維的掩碼向量 (與 維度相同),并將人工標注的標志物邊界框轉化為 37 維的掩碼向量 (與 維度相同)。然后,我們將標志物圖像 patch 的特征平均化,并將其輸入一個兩層前饋網絡(Feedforward Network, FFN)中,預測指令序列中 token 位置的概率分布,用掩碼向量 作監督,具體損失函數為:
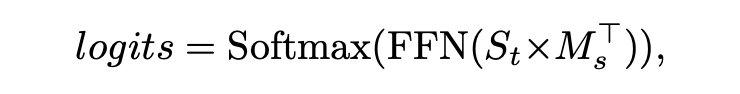

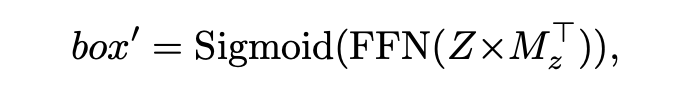
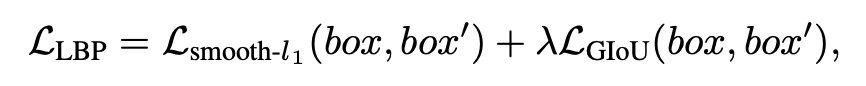
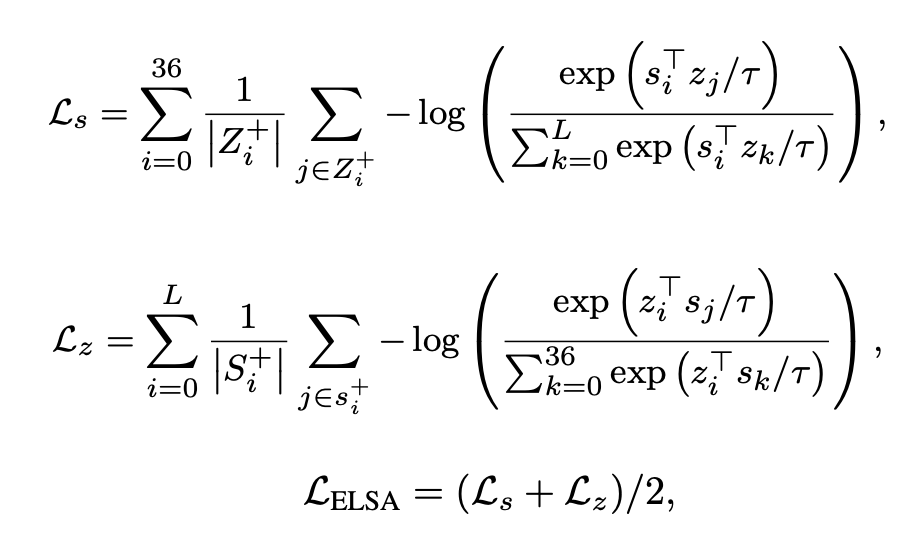 自適應預訓練最終的損失函數為:
自適應預訓練最終的損失函數為:
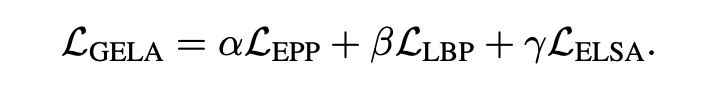
 ?
?實驗結果
如圖 5 所示,GELA 模型在 R2R 數據集上與先前 SOTA 模型的性能進行比較。GELA 模型在所有子集上的主要指標(SR 和 SPL)均優于所有其他模型。具體地,在已知驗證集上,GELA 的性能與 HAMT 模型相當,而在未知驗證集和測試集上,GELA 模型分別取得了 5% 、2% (SR) 和 4% 、2% (SPL) 的提高。因此,GELA 模型具有更好的未知環境泛化能力,這主要是由于 GELA 模型在學習實體-標志物對齊后,具有較強的語義特征捕捉能力。
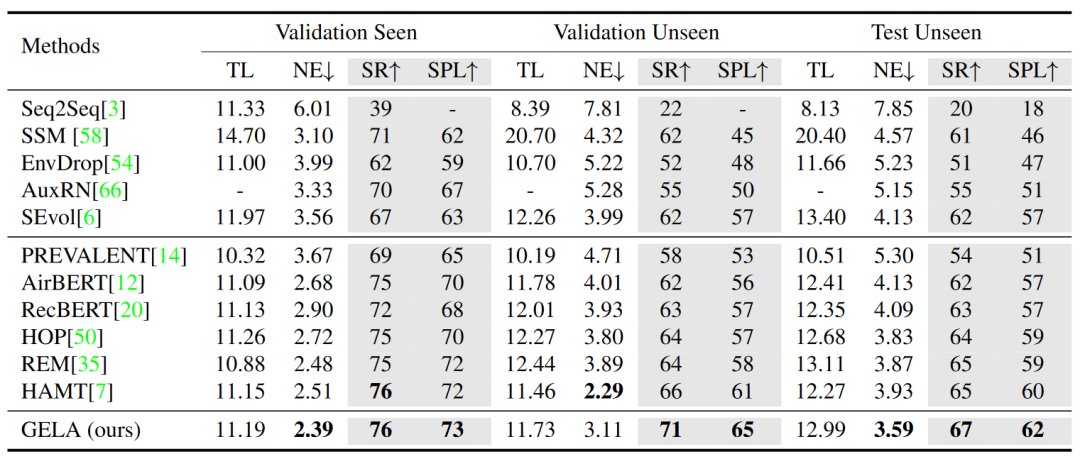 ▲ 圖5. R2R數據集上的性能對比
我們同樣在 CVDN 數據集上對比了 GELA 模型與先前 SOTA 模型的性能,如圖 6 所示,該數據集使用以米為單位的目標進度 (Goal Progress,GP) 作為關鍵性能指標。結果表明,GELA 模型在驗證集和測試集上的性能都明顯優于其他模型。因此,GELA 模型對不同的 VLN 下游任務具有良好的泛化能力。
▲ 圖5. R2R數據集上的性能對比
我們同樣在 CVDN 數據集上對比了 GELA 模型與先前 SOTA 模型的性能,如圖 6 所示,該數據集使用以米為單位的目標進度 (Goal Progress,GP) 作為關鍵性能指標。結果表明,GELA 模型在驗證集和測試集上的性能都明顯優于其他模型。因此,GELA 模型對不同的 VLN 下游任務具有良好的泛化能力。
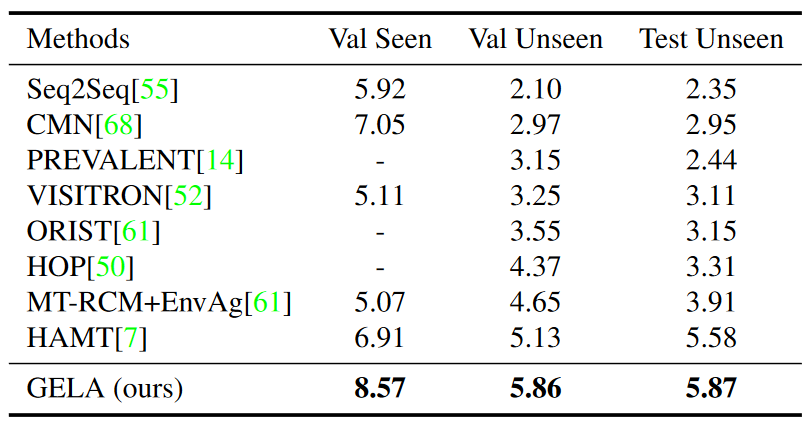 ▲圖6. CVDN數據集上的性能對比
▲圖6. CVDN數據集上的性能對比

參考文獻
?[1] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko S ? underhauf, Ian D. Reid, Stephen Gould, and Anton van den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In CVPR, pages 3674–3683, 2018.
[2] Yicong Hong, Cristian Rodriguez Opazo, Qi Wu, and Stephen Gould. Sub-instruction aware vision-and-language navigation. In EMNLP, pages 3360–3376, 2020.
[3] Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision-and-language navigation. In NeurIPS, pages 58345847, 2021.
·
原文標題:ICCV 2023 | 面向視覺-語言導航的實體-標志物對齊自適應預訓練方法
文章出處:【微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
-
物聯網
+關注
關注
2903文章
44262瀏覽量
371221
原文標題:ICCV 2023 | 面向視覺-語言導航的實體-標志物對齊自適應預訓練方法
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于視覺語言模型的導航框架VLMnav
ai大模型訓練方法有哪些?
大語言模型的預訓練
LLM預訓練的基本概念、基本原理和主要優勢
預訓練模型的基本原理和應用
【大語言模型:原理與工程實踐】大語言模型的預訓練
利用液滴納米孔傳感平臺,實現單分子水平上皮克級生物標志物的靈敏檢測
基于DNA樹突狀探針的微流控免疫傳感平臺,用于過敏原標志物的高靈敏檢測
什么是自適應光學?自適應光學原理與方法的發展
谷歌模型訓練軟件有哪些功能和作用
混合專家模型 (MoE)核心組件和訓練方法介紹

無監督域自適應場景:基于檢索增強的情境學習實現知識遷移






 工商網監
工商網監
評論