 RDMA(遠程直接內存訪問)傳輸協議概述和應用案例
RDMA(遠程直接內存訪問)傳輸協議概述和應用案例
人工智能 (AI) 的興起極大地提高了對強大、高效和可擴展的網絡傳輸協議的需求。本文深入探討了 RDMA(遠程直接內存訪問)傳輸協議,并重點討論 ROCEv2 協議,目前基于 ROCEv2 的 RDMA已經在一些超大規模數據中心中取代了 TCP。
在最近的NDSI-23-Talk中,微軟強調,70% 的 Azure 云網絡流量(主要是存儲網絡流量)在基于以太網的 ROCEv2 RDMA 上運行,只有一小部分依賴基于 TCP/IP 的網絡,這一轉變在 Oracle、阿里巴巴和 Meta 等其他超大規模提供商中也很明顯。這一趨勢表明,隨著云計算、人工智能/機器學習工作負載的持續增長,整個行業正朝著采用RDMA技術來優化網絡性能的方向發展。
01RDMA概述
RDMA 通過直接將“內存映射”數據傳輸到遠程內存位置來運行,具有兩個關鍵優勢:
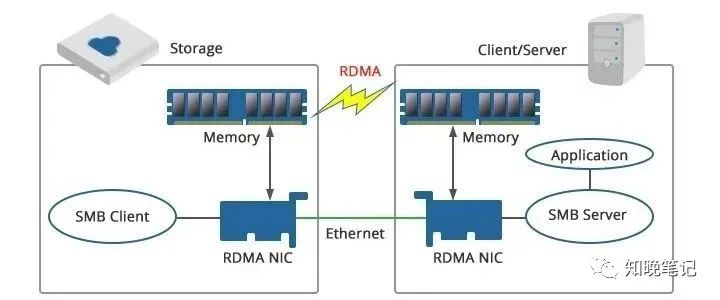
CPU 效率:與消耗多個 CPU 核心的 TCP/IP 不同,RDMA在內存注冊后將數據傳輸委托給 RDMA 網絡適配器來執行,這樣的方式釋放了CPU資源,對于云服務提供商來說,這可以更有效地利用這些新可用的CPU核心,實現更高的資源利用率。
低延遲和內存效率:RDMA 繞過 Linux 內核,直接將數據傳輸到應用程序緩沖區,這一功能稱為零復制。這消除了在發送和接收端點節點處進行內存復制的需要。內核旁路和零拷貝功能可最大限度地減少延遲和抖動。
RoCEv2 RDMA 起源于高性能計算 (HPC),并結合了 IB 傳輸協議。
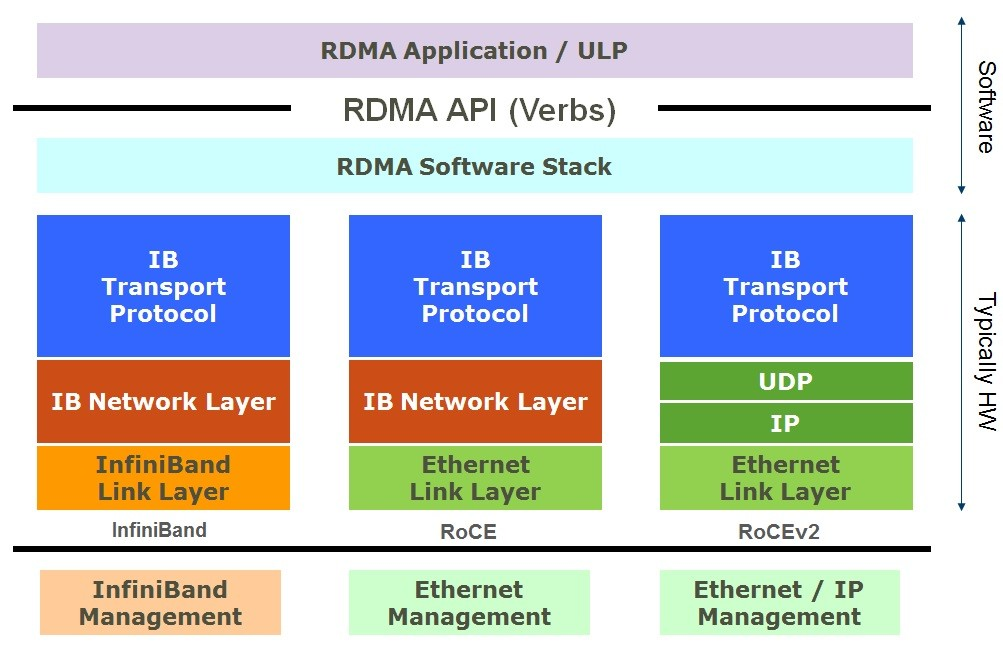
| InfiniBand 和 ROCEv2 協議棧
RoCEv2 保留了 InfiniBand 語義及其傳輸和網絡協議,并將InfiniBand鏈路層和物理層替換為以太網。
因此,ROCEv2 RDMA 已成為數據中心后端網絡的標準,可提供高吞吐量、微秒范圍的低延遲和完整的 CPU 卸載。
注意:前端網絡通常運行 TCP/IP 或 QUIC 等其他協議。RDMA、InfiniBand 等協議作為后端網絡,通常被稱為東西向流量,占現代數據中心流量的 70-80%。
02以太網 ROCEv2 挑戰
InfiniBand架構
InfiniBand架構是無損網絡,重點關注服務質量 (QoS) 和傳輸層端到端信用。IB 協議棧非常適合 HPC 和 AI/ML 網絡。然而,InfiniBand 網絡通常比以太網更昂貴,可擴展性也更差。
注意:無損意味著底層網絡被配置為避免因網絡擁塞而導致數據包的丟失。盡管如此,偶爾仍可能會由于錯誤情況導致數據包損壞或丟失。在這種情況下,傳輸協議包括一種端到端的交付機制,其中內置了數據包重傳邏輯,通常由硬件實現,以此在不需要軟件干預的情況下觸發,以恢復丟失的數據包。這確保了在網絡出現問題時可以自動糾正數據包的丟失,無需人工介入。
ROCEv2架構
RoCEv2 在以太網鏈路上通過 UDP/IP 上運行。UDP 是一種不可靠的數據報服務,而以太網的架構并非無損。由于 ROCEv2 期望底層網絡是無損的,因此在將以太網配置為無損網絡時面臨著多項挑戰,如下所述。

| ROCEv2 數據包格式
隊頭 (HOL) 阻塞:由于優先流量控制 (PFC),不同流中的數據包可能會被擁塞流阻塞,跨更大的網絡、跨多個交換機進行擴展成為一個挑戰。
擁塞管理:通常由軟件以帶外方式處理。現有技術緩慢且復雜,一些供應商借用了 InfiniBand 的硬件技術,但這些是定制的,不是以太網標準的一部分。
減少有效吞吐量:以太網不是一個無損網絡。由于擁塞下降,可能會發生數據包丟失,這種數據包丟失會導致整個數據包窗口的重傳(稱為 Go-back-to-N),從而降低網絡“goodput”。
盡管存在這些挑戰,大型 ROCEv2 網絡已經成功部署,但要求對其進行精細調優和持續監控。大多數超大規模企業都采用自定義、非標準的 ROCEv2 解決方案,并在針對不同工作負載微調RDMA堆棧方面投入了大量資金。
在某些情況下,組織甚至為 AI/ML 或存儲等特定應用程序建立了單獨的基于 ROCEv2 RDMA 的數據中心,但這也導致了運營成本的顯著增加。
接下來,我們將深入研究三個不同的案例,以便更全面地理解這一情況。
03大廠案例
微軟
十多年來,微軟一直在大型數據中心部署 RoCEv2,并發表了一篇見解深刻的Microsoft-RDMA-Challenges研究論文。微軟的部署面臨 PFC 死鎖挑戰、RDMA 傳輸活鎖挑戰以及其他網卡相關問題。
微軟認為,單靠協議理論不足以滿足現實世界的部署,嚴格的大規模測試、分階段部署和網卡供應商協作對于發現協議最初設計時隱藏的漏洞至關重要。微軟已經為ROCEv2開發了自定義協議擴展,例如基于 DSCP 的 PFC,一些網卡/交換機供應商已經支持該協議。此外,微軟還實施了用于健康跟蹤和故障排除的遙測系統,這對于識別這些隱藏的復雜性問題至關重要。
Oracle
OCI(Oracle Cloud Infrastructure,Oracle 云基礎設施)是一個公有云,可在同一 RDMA 網絡上運行 AI、HPC、數據庫和存儲等多種不同應用程序。
| Oracle RDMA 網絡結構
Oracle 通過多種方法應對 ROCEv2 挑戰:
限制優先級流控制 (PFC):僅限于 3 層 Clos 網絡中的網絡邊緣。
網絡局部性提示:Oracle 根據網絡關聯性放置工作負載,以將大部分流量保持在本地,稱為網絡局部性提示。
微調擁塞控制:利用顯式擁塞通知 (ECN) 和 DC-QCN,每個都針對特定 RDMA 工作負載進行微調,以平衡延遲和吞吐量。
Meta
Meta 專注于針對 AI/ML 工作負載的 ROCEv2 RDMA 部署,正如Meta @Scale 2023活動視頻中所討論的那樣,主要工作負載包括推薦引擎、內容理解和大語言模型(LLM),這些集群的規模從數百個 GPU 到數萬個 GPU不等。
有趣的是,Meta 并沒有面臨與微軟相同的挑戰。例如,由于骨干交換機中的深度緩沖區,PFC HOL 阻塞不再是問題。Meta 還成功地使用 DC-QCN 進行擁塞控制,并且由于現代 NIC 具有更大的 NIC 緩存,因此沒有面臨擴展問題。總的來說,由于具有先進功能的新硬件以及拓撲、工作負載和軟件策略的差異等多種原因,Meta 沒有遇到相同的問題。
Meta的關鍵挑戰主要圍繞負載均衡,這通過依靠 SDN 控制器對路由進行編程來解決。在網絡事件發生之前,這些路由不會更新。ECMP 哈希方案僅在網絡事件發生后生效。跨多個隊列對 (QP) 的元多路復用流和定制的 ECMP 哈希方案以增加熵。
Meta 使用 PCIe 點對點 (P2P) DMA 技術,通過支持跨 GPU 的直接數據傳輸來提高應用程序性能。
Meta 還超額訂閱了主干層,因為 AI/ML 流量模式不需要完整的非阻塞主干連接。這降低了數據中心成本。
與許多其他公司一樣,Meta 正在探索數據包噴射、基于分解 VOQ 的交換機以及可以容忍亂序交付的自定義傳輸協議。
一篇MIT + Meta 研究論文《針對 LLM 的優化網絡架構》提出了一種針對 LLM 流量模式的新網絡架構,可以將網絡成本削減 37% - 75%。該架構為具有高通信需求的 GPU 定義了高帶寬或 HB 域。在 HB 內,GPU 通過任意對任意互連進行互連。在Meta部署中,跨HB網絡流量稀疏,可以消除跨HB域的連接和交換機,從而降低網絡成本。
04RDMA 的未來
超大規模廠商和供應商都以自定義的方式解決了 ROCEv2 的潛在問題。ROCEv2 網絡仍然需要針對每個工作負載進行定制和微調。
1RMA 擴展框架
具有多個租戶的公共云需要大規模擴展,達到數百萬個節點和數十億個流。由于 ROCEv2 面向連接的特性,工作隊列條目 (WQE) 通常在硬件中實現,這限制了流量擴展。跨多個租戶的安全性和線速加密給 RoCEv2 帶來了額外的挑戰。
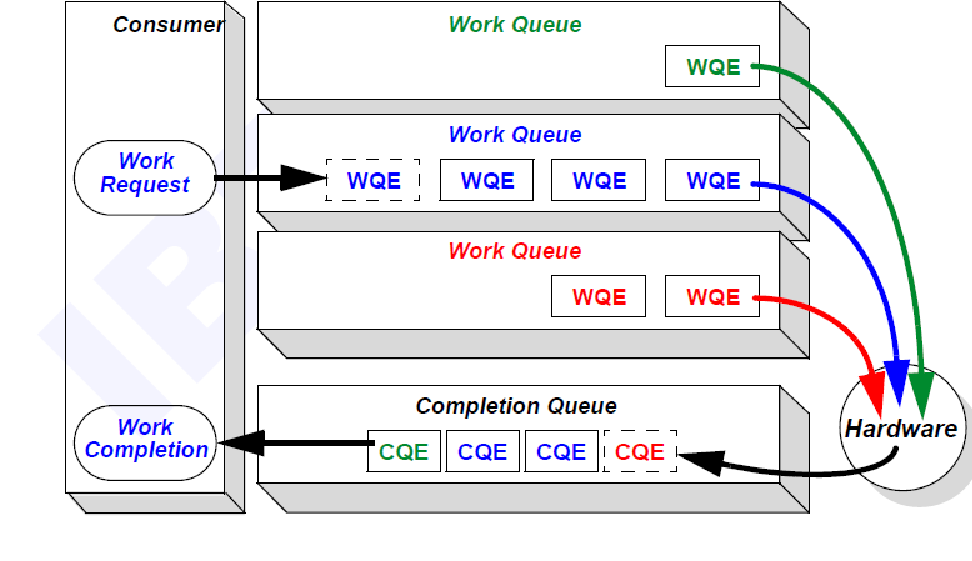
| 消費者排隊模型
云數據中心的一個替代方案是1RMA 論文中記錄的 1-Shot 遠程內存訪問 (1RMA) 方法,該方法建議以軟件為中心的重新架構。由于片上系統 (SoC)處理器內核現在可在基于 DPU/IPU 的網絡適配器上運行軟件,因此這種以軟件為中心的方法變得更加可行。主要思想是:
軟件重點:將一些傳統的網卡硬件數據結構(例如排隊、數據包排序、數據包調步和擁塞控制)轉移到軟件中。
硬件重點:將網卡硬件重點放在主數據路徑、DMA 傳輸、incast 邊界、身份驗證和加密上。硬件無需連接,并向軟件提供細粒度的延遲測量和故障通知。
1RMA 方法主張將連接和大部分狀態轉移到軟件中,以獲得更好的可擴展性。這簡化了硬件并支持公共云所需的大規模擴展。
請注意,采用 1RMA 方法可能需要從頭開始重新架構,涉及新協議和 NIC 硬件。此外,1RMA 的研究重點是云數據中心的需求;AI/ML 和 HPC 網絡可能需要不同的權衡。
UEC聯盟
UEC聯盟提議用基于UDP/IP的新開放協議取代ROCEv2。UEC 的重點是 AI/ML 和 HPC 網絡。
# ROCEv2 替代協議的關鍵屬性
多路徑和數據包噴射
靈活的交付順序和選擇性重傳
響應式擁塞控制機制
規模更大、穩定可靠
堆棧的所有層可能都需要進行更改。
UEC聯盟白皮書中的一些主題確實與1RMA Paper和EDQS Paper(由Correct Networks撰寫,被Broadcom收購)產生了共鳴。
在10 月 17 日的OCP峰會上,OCP與 UEC 達成合作,利用兩家組織的專業技能來提高AI工作負載的以太網性能。已確定初步探索潛在合作的領域包括 OCP交換機抽象接口(SAI)、OCP Caliptra Workstream、OCP網絡項目、OCP網卡Workstream、OCP Time Appliance項目和OCP未來技術倡議。
未來的開放標準
到目前為止,還沒有 ROCEv3 標準。針對這些挑戰的可擴展、通用和開放的解決方案仍然難以實現。
AI/ML、HPC 和云數據中心工作負載的需求可能差異很大,以至于我們需要多種解決方案。例如,
# UEC聯盟
UltraEthernet 聯盟僅專注于大規模人工智能和高性能計算。
# 工作負載特征
HPC 要求超低延遲,而 AI/ML 訓練優先考慮高吞吐量和低尾延遲。
# 多種拓撲
公共云通常使用 2 層或 3 層 Clos 網絡,而 AI/HPC 網絡可能采用蜻蜓、3D 環面或超立方體拓撲,這些仍在不斷發展。
# 不斷變化的需求
AI/ML 算法不斷發展,云數據中心工作負載也在不斷發展,這可能會導致未來進一步分化。
# 開放與封閉
云數據中心可以繼續使用定制解決方案或在 OCP 等論壇中協作來定義開放標準。
如果出現多種開放解決方案,協作可以幫助建立統一的基礎架構。這將防止解決方案出現分歧以及相關的成本問題。雖然具有挑戰性,但重要性不言而喻。
新標準需要時間才能成熟。定義后,硬件開發可能需要長達兩年的時間,然后是規模測試和錯誤修復,這讓時間線又增加了幾年。短期內,預計主要參與者將繼續進行定制創新。
05結 論
雖然有多種定制和復雜的方法可以解決 ROCEv2 的挑戰,但業界正在積極探索基于開放標準的 ROCEv2 RDMA 替代方案。未來的 RDMA 協議必須發展成為適用于廣泛工作負載的“即插即用”解決方案,就像今天的 TCP 一樣。
最后,DPU/IPU與內置SOC正在徹底改變我們對網絡的看法,它們使我們能夠重新定義硬件-軟件邊界,直接在網絡硬件上運行關鍵軟件,使我們的系統變得靈活且面向未來。
審核編輯:湯梓紅
-
AI
+關注
關注
87文章
30106瀏覽量
268400 -
TCP
+關注
關注
8文章
1349瀏覽量
78985 -
人工智能
+關注
關注
1791文章
46845瀏覽量
237535 -
傳輸協議
+關注
關注
0文章
78瀏覽量
11435 -
RDMA
+關注
關注
0文章
76瀏覽量
8925
原文標題:ROCEv2 RDMA:TCP的變革者還是取而代之者?
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
RDMA RNIC虛擬化方案
CW32L052 DMA直接內存訪問

PMC與Mellanox聯合展示 NVMe over RDMA 以及P2P的高速傳輸
RDMA技術有助于實現網絡和設備的性能提升
InfiniBand和遠程直接訪問是什么,如何進行配置
RDMA技術簡介 RDMA的控制通路和數據通路方案
什么是RoCE?如何實現RoCE?
數據中心以太網和RDMA:超大規模環境下的問題






 工商網監
工商網監
評論