 一文詳解多模態大模型發展及高頻因子計算加速GPU算力 | 英偉達顯卡被限,華為如何力挽狂瀾?
一文詳解多模態大模型發展及高頻因子計算加速GPU算力 | 英偉達顯卡被限,華為如何力挽狂瀾?
★深度學習、機器學習、多模態大模型、深度神經網絡、高頻因子計算、GPT-4、預訓練語言模型、Transformer、ChatGPT、GenAI、L40S、A100、H100、A800、H800、華為、GPU、CPU、英偉達、NVIDIA、卷積神經網絡、Stable Diffusion、Midjourney、Faster R-CNN、CNN
隨著人工智能技術的快速發展,多模態大模型在各個領域中的應用越來越廣泛。多模態大模型是指能夠處理多種不同類型的數據,如文本、圖像、音頻和視頻等大型神經網絡模型。隨著互聯網和物聯網的普及,多模態大模型在許多領域中都得到了廣泛的應用。例如,在醫療領域中,可以通過分析醫學圖像和病歷等數據,輔助醫生進行疾病診斷和治療方案制定;在智能交通領域中,可以通過分析交通圖像和交通流量等數據,輔助交通管理部門進行交通規劃和調度。
在大規模計算中,高頻因子計算是一個非常耗時的過程。GPU作為一種專門用于大規模并行計算的芯片,具有高效的計算能力和高速的內存帶寬,因此被廣泛應用于高頻因子計算中。通過將計算任務分配給多個GPU,可以顯著提高計算速度和效率。
近年來,全球范圍內的芯片禁令不斷升級,給許多企業和科研機構帶來了很大的困擾,需要在技術層面進行創新和突破。一方面,可以探索使用***和其他不受限制的芯片來替代被禁用的芯片;另一方面,可以通過優化算法和架構等方法來降低對特定芯片的依賴程度。
為了更好地推進多模態大模型的研究和應用,藍海大腦大模型訓練平臺基于自主研發的分布式計算框架和算法庫,可以高效地進行大規模訓練和推斷。同時,該平臺還提供了豐富的數據處理、模型調試和可視化工具,可以幫助用戶快速構建、訓練和部署多模態大模型。
本文將介紹多模態大模型的綜述,并探討高頻因子計算的GPU加速方法,以及探討在當前芯片禁令升級的情況下,如何繼續推進大模型訓練平臺的發展。
多模態大模型綜述
一、多模態模型重塑 AI 技術范式
多模態模型融合了語言和圖像模態,將文本理解和思維鏈能力投射到圖像模態上,賦予模型圖像理解和生成功能。通過預訓練和調參的方式,顛覆了傳統機器視覺小模型的定制化業務模式,大幅提高了模型的泛用性。多模態模型旨在模擬人類大腦處理信息的方式,從大語言模型到圖像-文本模型,再泛化到其他模態的細分場景模型。與大語言模型相比,多模態模型擴大了信息輸入規模,提高了信息流密度,突破了語言模態的限制;與傳統機器學習模型相比,多模態模型具有更高的可遷移性,并能進行內容生成和邏輯推理。
1、多模態模型通過高技術供給重塑 AI 技術范式
多模態模型目前主要是文本-圖像模型。模態是指表達或感知事物的方式,每一種信息的來源或形式都可以稱為一種模態。例如,人類有觸覺、聽覺和視覺等感官,信息的媒介有語音、視頻、文字等,每一種都可以稱為一種模態。目前已經推出幾十種基礎模型,如Clip、ViT和GPT-4等,并且已經出現諸如Stable Diffusion和Midjourney這樣的應用。因此,多模態大模型領域目前以文本-圖像大模型為主,未來隨著AI技術的發展,包含更多模態的模型有望陸續推出。
多模態模型融合語言和圖像模態,將文本理解和思維鏈能力應用于圖像模態,為模型賦予圖像理解和生成功能。多模態技術通過預訓練和調參顛覆了傳統機器視覺小模型的定制化業務模式,大幅提高了模型的泛用性。從商業模式來看,產業話語權逐漸從應用端轉向研發端,改變了由客戶主導市場的項目制,轉向由技術定義市場。
多模態模型有望顛覆 AI 視覺的商業模式
多模態模型的核心目標是以人類大腦處理信息的方式進行模擬。語言和圖像模態本質上是信息的載體,可類比為接受不同傳感器的感知方式。人類通過整合來自不同感官的信息從而理解世界,同樣,多模態模型將各種感知模態結合,以更全面、綜合的方式理解和生成信息,并實現更豐富的任務和應用。

當前圖像-語言多模態模型的典型任務
多模態模型的技術路徑是從圖像-語言模態融合擴展到三種以上模態的融合。
語言模態訓練為模型提供邏輯思維能力與信息生成能力,這兩種能力是處理信息的基礎。視覺模態具有高信息流密度且更貼近現實世界,因此成為多模態技術的首選信息載體。具備視覺能力的模型具有更高的實用性,可廣泛應用于現實世界的各個方面。在此基礎上,模型可以繼續發展動作、聲音、觸覺等不同模態,以應對更為復雜的場景。

多模態模型技術發展路徑
2、與大語言模型對比:抬升模型能力天花板
多模態大模型通過預訓練+調參,大幅提升信息輸入規模和信息流密度,打破語言模態的限制。大模型能力的提升得益于對信息的壓縮與二次處理,多模態模型在處理圖片和文本數據時,能夠提高模型能力的上限。視覺模態是直接從現實世界獲取的初級模態,數據源豐富且成本低廉,相比語言模態更直觀易于理解。多模態模型不僅提高信息流密度,還突破語言模態不同語種的限制。在數據資源方面,國外科技巨頭具有優勢,如ChatGPT等大模型的數據訓練集以英文語料為主,英文文本在互聯網和自然科學論文索引中的數量具有優勢。相比之下,圖像模態是可以直接獲取的一級模態,因此多模態的數據突破了語言種類限制。

圖像模態是初級模態,可以直接從現實世界獲得
多模態模型提高信息交互效率,降低應用門檻。大語言模型需要輸入文本Prompt來觸發模型文本回答,但編寫準確的Prompt需要一定技能和思考。純文本交互方式有時受限于文本表達能力,難以傳達復雜概念或需求。相比之下,多模態模型圖像交互方式使用門檻更低,更加直觀。用戶可直接提供圖像或視覺信息,提高信息交互效率。多模態模型不同模態信息可以相互印證,從而提高模型推理過程的魯棒性。
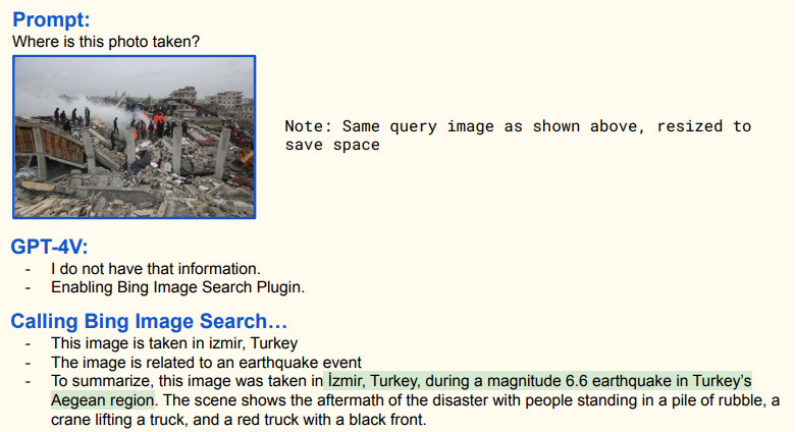
直接上傳圖片至 GPT-4 比文字描述簡單快捷
3、與傳統機器視覺模型對比:拓寬應用邊界,提升價值量
在預訓練大模型出現之前,機器視覺技術(CV)是深度學習領域的一個重要分支,深度學習算法以卷積神經網絡(CNN)為主。CNN 在圖像上應用卷積操作,從局部區域提取特征。具體而言,CNN 算法會把一張圖像切割成若干個小方塊(如 3X3),將每一個小方塊轉化成單獨的向量,先對全圖像在 3X3 的 9 個方塊范圍計算卷積得到特征值(CNN 算法),這些特征映射捕捉不同的局部信息。然后對全圖像在 2X2 的 4 個小方塊范圍內取最大值或平均值(池化算法)。最后經過多輪特征值提取與池化后,會將矩陣投喂給神經網絡,用于最終的物體識別、圖像分割等任務。

CNN 算法提取圖像的特征值
傳統機器視覺模型只能處理圖像數據,無法處理文本信息,也不具備邏輯推理能力。由于這些模型僅對圖像數據進行表征編碼,通過提取視覺特征如顏色、紋理和形狀等來識別圖像,沒有涉及語言模態。
多模態模型具有更高的可遷移性和更廣泛的應用范圍。盡管CNN在機器視覺領域被廣泛使用,但它們大多是針對特定任務設計的,因此在處理不同任務或數據集時,其可遷移性受到限制。多模態大模型通過聯合訓練各種感知模態如圖像、文本和聲音等,能夠學習到更通用和抽象的特征表示。這種預訓練使得多模態模型在各種應用中都具備強大的基礎性能,因此具有更高的泛化能力。
多模態模型還具有圖像生成和邏輯推理的能力,進一步提高了應用的價值。傳統的CNN模型只能對圖像內容進行識別和分類,無法實現圖像層面的生成與邏輯推理。而多模態模型由于采用自編碼的訓練模式,可以通過給定文字生成圖片或根據圖片生成描述。文本模態賦予了模型邏輯推理能力,與圖像模態實現思維鏈的共振。
二、多模態模型技術綜述
圖像-語言多模態模型有六大任務:表征、對齊、推理、生成、遷移和量化。其中,對齊最為關鍵,也是當前多模態模型訓練的主要難點。
表征研究如何表示和總結多模態數據,反映各模態元素之間的異質性和相互聯系;對齊旨在識別所有元素之間的連接和交互;
推理從多模態證據中合成知識,通常涉及多個推理步驟;
生成涵蓋學習生成過程,以生成反映跨模態交互的結構;
遷移旨在將具有高泛化性的模型通過調參適應各種垂直領域;
量化則通過研究模型的結構和工程化落地方式,更好地理解異質性、模態互聯和多模態學習過程。
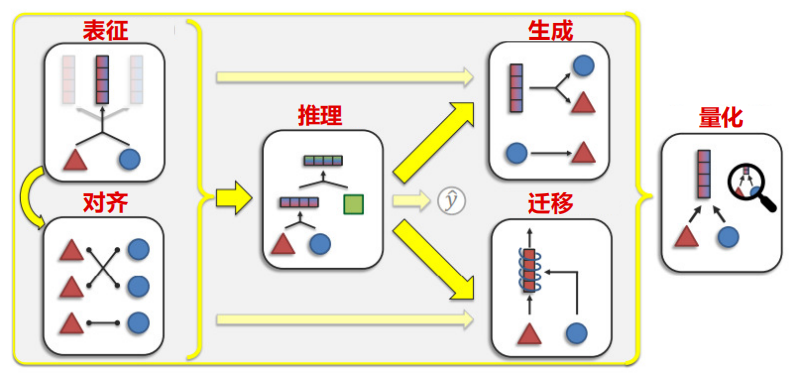
多模態模型的 6 大任務
1、表征:當前已有成熟方案
表征的主要目標是把不同類型的數據轉化為模型能理解的形式。單模態的表征負責將信息表示為數值向量或更高級的特征向量,而多模態表征則是利用不同模態之間的互補性,去除冗余性,從而學習到更好的特征表示。目前,多模態模型的訓練大多采用融合表征法,整合多個模態的信息,以尋找不同模態的互補性。此外,還有協同表征和裂變表征兩種方法。協同表征將多模態中的每個模態映射到各自的表示空間,并保持映射后的向量之間具有相關性約束;裂變表征則創建一個新的不相交的表征集,輸出集通常比輸入集大,反映了同場景模態內部結構的知識,如數據聚類或因子分解。
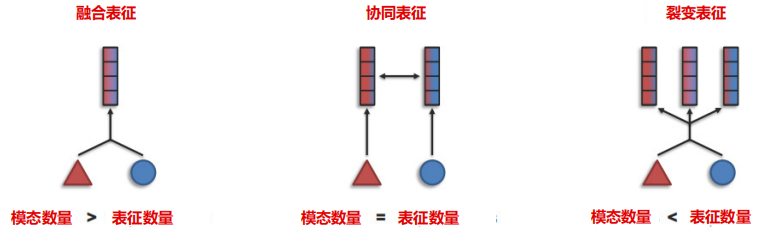
多模態表征可以分為三種類型
目前文本表征和圖像表征都有較為成熟的方案。文本表征的目的是將單詞轉化為向量 tokens,可以直接采用BERT等大語言模型成熟的方案。圖像表征則生成圖片候選區域并提取特征,將其轉化為矩陣,可沿用機器視覺的CNN、Faster R-CNN等模型方案。
2、對齊:多模態技術的最大瓶頸
對齊是多模態模型訓練最難且最重要的任務,對模型性能和顆粒度有直接決定作用。對齊的目的是識別多模態元素之間的跨模態連接和相互作用,例如將特定手勢與口語或話語對齊。模態之間的對齊具有技術挑戰性,因為不同模態之間可能存在長距離的依賴關系,涉及模糊的分割,并可能是一對一、多對多的關聯性。經過對齊的模型圖像的時間、空間邏輯更加細膩,不同模態的信息匹配度更高,信息損耗更小。
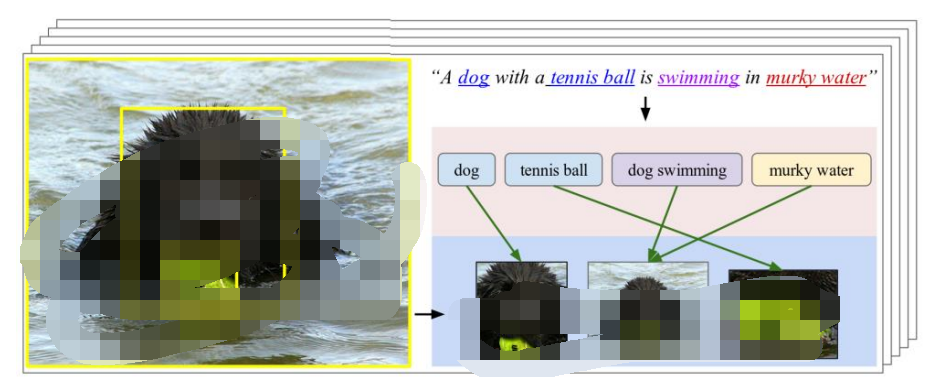
不同模態的對齊存在多對多的相互關系
數據對齊時會對文本和圖像表征進行融合處理,根據詞嵌入與信息融合方式的順序不同,可分為雙流(Cross-Stream)與單流(Single-Stream)。多模態大模型主要采用Encoder編碼方式實現文本信息與圖像信息的匹配融合。雙流模型首先使用兩個對立的單模態Encoder分別學習圖像和句子表示的高級抽象,然后通過Cross Transformer實現不同模態信息的融合,典型模型有ViLBERT、Visual Parsing等。雙流模型需要同時對兩種模態進行Encoder編碼,因此訓練時算力消耗更大,但其優點在于模態之間的相關性更簡潔明了,可解釋性更具優勢。
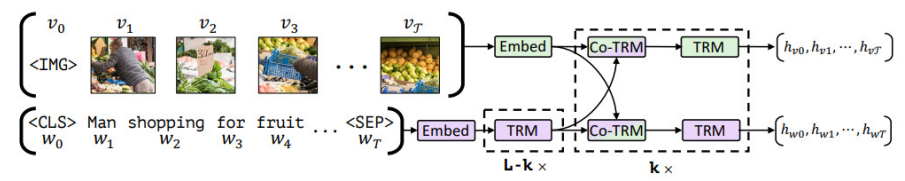
雙流方案,以 ViLBERT 模型為例
單流模型假設圖像和文本的底層語義簡單明了,因此將圖像區域特征和文本特征直接連接起來,將兩種模態一起輸入一個Encoder進行融合。采用單流形式的典型模型有VL-BERT、ViLT等。單流模型只需對混合的模態進行編碼,因此算力需求更低。但信息傳遞和融合可能會受到限制,某些信息可能會丟失。此外,過早混合兩種模態使得相關性和可解釋性較差。
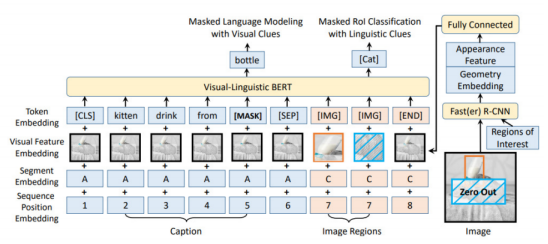
單流方案,以 VL-BERT 模型為例
3、推理與生成:沿用大語言模型方案
推理與生成是多模態模型結合知識并決策的過程。多模態中的視覺推理受到文本模態的影響,文本的時間序列為圖像推理提供更強的邏輯性。隨著訓練的推進和參數量增長,多模態模型展現出思維鏈能力,將復雜任務分解為多個簡單步驟。多模態模型的推理與生成算法搭建和大語言模型類似,可沿用其方案。模型推理與生成的速度主要由算力基礎設施決定。
多模態模型生成任務包括總結、翻譯和創建三個任務。總結是通過計算縮短一組數據以創建摘要,摘要包含原始內容中最重要或最相關的信息,信息規模下降。翻譯涉及從一種模態到另一種模態的映射,信息規模保持不變。創建旨在從小的初始示例或潛在的條件變量中生成新的高維多模態數據,信息規模上升。
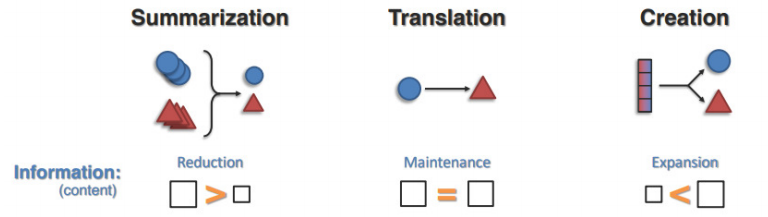
生成包含總結、翻譯與創建三個任務
4、遷移:難度與下游應用場景關聯度較大
多模態大模型的遷移是指將預訓練好的多模態模型經過調參后,用于解決不同任務或領域的過程。經過預訓練的大模型具備基本的多模態生成、圖像理解與邏輯推理能力,但由于缺少行業數據的訓練,在細分場景的適配性較低。經過調參的多模態大模型會增強圖文檢索、圖像描述、視覺回答等功能,與醫療、教育、工業場景的匹配性更高。遷移任務的難度技術上不高,主要難點在于工程化調試,且難度與下游應用場景關聯度較大。
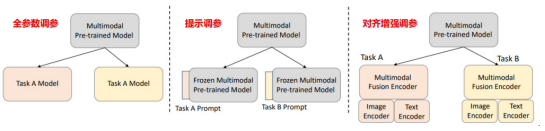
多模態模型調參的三種方法
多模態模型調參可分為三種類型:全參數調參、提示調參和對齊增強調參。全參數調參需要微調所有參數以適應下游任務;提示調參只需微調每個下游任務的少量參數;對齊增強調參在多模態預訓練模型外添加了對齊感知圖像Encoder和對齊感知文本Encoder,并一起訓練所有參數以增強對齊。
5、量化:模型的迭代與改良
量化旨在通過深入研究多模態模型以提高實際應用中的魯棒性、可解釋性和可靠性。在量化過程中,開發者會總結模型構建經驗,量化不同模態之間的關聯交互方式,尋求更好的結合方法。因此,量化會引導開發者重新審視模型對齊與訓練過程,不斷迭代優化模型,尋找最佳通用性與場景專用性的平衡點。量化是一個長期且模糊的過程,沒有標準答案,只能通過模型迭代嘗試尋找更優解法。
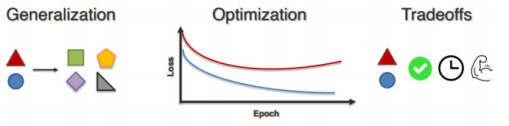
量化會協助模型迭代到通用性與場景專用型的平衡點
三、多模態模型的應用落地與產業趨勢
1、產品陸續發布,應用落地加速
9月25日,OpenAI發布GPT-4多模態能力,包括圖像理解能力,基于GPT-4 Vision模型,可以理解和解釋圖像內容,同時具備上下文回溯能力。GPT-4的多模態能力基于GPT-4V模型,經過2022年訓練后,使用RLHF完成一系列微調,從有害信息、倫理問題、隱私問題、網絡安全、防越獄能力五個角度完善模型,大幅度降低了模型安全風險。
在長期打磨后,OpenAI開放了GPT-4的多模態能力,意味著應用落地的門檻不是技術限制,而是在于模型打磨和場景挖掘。長期打磨的GPT-4多模態能力具備較高的魯棒性,安全性已達到商用標準,產品成熟度較高。因此,可以推斷GPT-4多模態模型的應用落地可能更加樂觀。同時,9月21日OpenAI發布DALL-E3文生圖模型,相比DALL-E2,DALL-E3理解圖像細微差別和細節的能力大幅度提高,生成的圖像包含更多細節,更符合prompt描述。DALLE-3深度整合ChatGPT模型,用戶可以直接通過自然語言與DALL-E3交互。文生圖應用門檻大幅度降低。
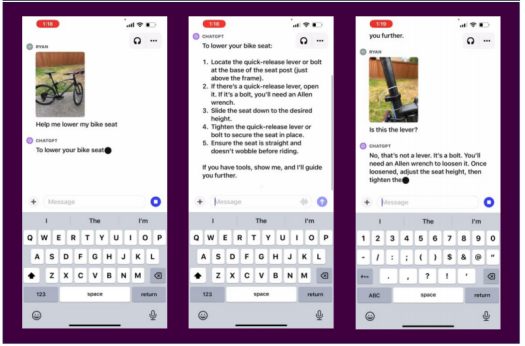
GPT-4 多模態模型有較強的邏輯思維能力
測評顯示,DALL-E3模型在相同prompt輸入下的性能已經達到Midjourney V5水平。DALL-E3已于10月首先向ChatGPT Plus和企業客戶提供。

DALL-E2(左)與 DALL-E3(右)生成圖像對比
DALL-E3 深度結合 ChatGPT,使用戶可以直接以自然語言與模型交互,降低文生圖應用的使用門檻。DALL-E3 具備上下文理解和記憶能力,可回溯上文信息,進一步簡化交互流程。相比 Midjourney,DALL-E3 用戶無需花費大量時間編寫和優化 prompt,通過 ChatGPT 打磨好 prompt 后再輸入應用即可。
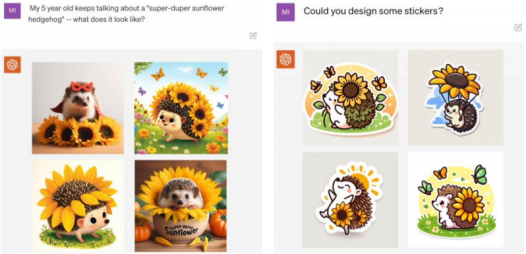
DALL-E3 整合 ChatGPT
2、場景匹配度提升,核心賽道有望快速滲透
大語言模型只能用于文本相關的場景,而多模態模型可以覆蓋所有視覺場景,因此應用范圍得到極大的提升。可以類比計算機發展早期從文本操作系統向圖形操作系統的躍升,圖像模態更貼近現實世界,信息密度更高,使用門檻更低,更適合人機交互。隨著GPT-4多模態能力的開放,多模態模型的應用有望快速實現。這將帶來新的技術發展和應用機會。
與文本操作系統(Terminal)相比,圖形操作系統(Windows 1.0x)更符合人機交流習慣
多模態模型在提高場景匹配度方面具有顯著優勢。自2023年初以來,大模型應用在落地過程中取得廣泛的關注,但其在滲透速度上的進展相對緩慢。核心原因在于大語言模型在場景匹配度方面存在不足,難以徹底改變特定細分領域的應用場景。相比之下,多模態模型能夠顯著提高應用的場景匹配度,實用性較高,預計將在醫療、教育、辦公等場景中快速滲透。這種高實用性的特點可能催生大批爆款應用,建議密切關注核心場景中多模態應用的落地節奏。

GPT-4 Vision 在工業界的應用
多模態模型將引發新的算力競賽。由于圖像數據規模龐大,多模態模型對算力的需求更高。當前,算力仍是AI模型訓練和推理的主要瓶頸。隨著多模態模型的普及,AI公司將開啟新一輪的算力競賽。因此,建議關注英偉達、華為、藍海大腦等算力產業鏈上的廠商。
此外,多模態大模型有望實現人形機器人的“端到端”方案。傳統的機器人算法系統由感知、決策規劃和控制三個模塊組成,需要兩個接口進行信息傳遞。而多模態模型將感知和決策合并為一個模塊,只需一個接口,減少了信息傳遞的環節,提高系統的性能和魯棒性。
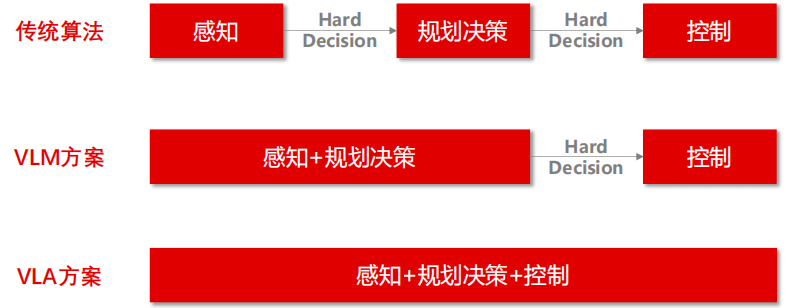
多模態模型將感知與決策模塊合并
高頻因子計算的GPU加速
近年來,AI技術顯著提高因子挖掘和合成效率,但因子計算環節尚未充分受益于技術進步。傳統因子計算通常使用CPU,但高頻數據的普及,CPU性能面臨限制。隨著NVIDIA引領GPU軟硬件生態日益成熟,使得高頻因子計算的GPU加速成為可能。
RAPIDS是NVIDIA為數據科學與機器學習推出的GPU加速平臺。以CUDA-X AI為基礎,由一系列開源軟件庫和API組成,支持完全在GPU上執行從數據加載和預處理到機器學習、圖形分析和可視化的端到端數據科學工作流程。據NVIDIA官網,RAPIDS能夠將數據科學領域效率提升50倍。
在量化投資的因子計算場景下,RAPIDS使用CuPy、cuDF庫替代NumPy、Pandas庫,實現高頻因子計算的GPU加速。在NVIDIA GeForce RTX 3090和Intel Core i9-10980XE測試環境下,使用CuPy和cuDF替換庫函數的GPU提速效果約為6倍,如果同時將for循環替換為矩陣運算,最終提速超過100倍。
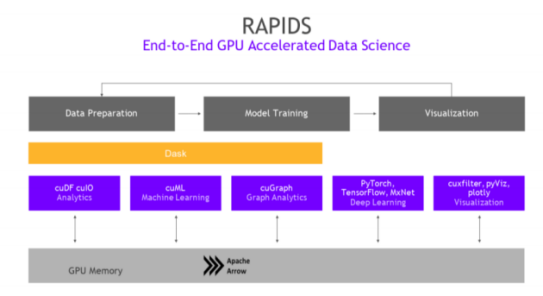
RAPIDS:數據科學的 GPU 加速
一、NVIDIA RAPIDS 實踐
1、RAPIDS 安裝
RAPIDS 官網提供詳細的安裝方法,可參考:https://docs.rapids.ai/install。在安裝過程中可能會遇到一些問題,參考以下經驗。
1)RAPIDS 安裝
推薦操作系統Ubuntu 20.04 和 CentOS 7。如果使用的是 Windows 系統,需要通過 Windows 子系統 Linux 2(WSL2)來安裝。具體的安裝方法可以在微軟官網找到:https://learn.microsoft.com/en-us/windows/wsl/install。
在安裝 WSL 時,可能會遇到一些問題。需要注意的是:
- 推薦使用 Windows 11 系統
- 在任務管理器中確認 CPU 虛擬化已啟用
- 在 Windows 功能中勾選“適用于 Linux 的 Windows 系統”和“虛擬機平臺”
- 以管理員身份運行 Power Shell,執行 bcdedit /set hypervisorlaunchtype auto
- 設置網絡和 Internet 屬性中的 DNS 服務器分配為手動,并設置 IPv4 DNS 服務器為首選,DNS 設為 114.114.114.114,備用 DNS 設為 8.8.8.8。不執行此步驟可能會導致安裝 WSL 時報錯
- 以管理員身份運行 CMD,執行 wsl –update 來更新 WSL。不執行此步驟可能會導致啟動 Ubuntu 時報錯
- 繼續執行 wsl --install -d Ubuntu 來安裝 Ubuntu 子系統
- 啟動“適用于 Linux 的 Window 子系統”(WSL),設置賬戶和密碼,完成 WSL 安裝
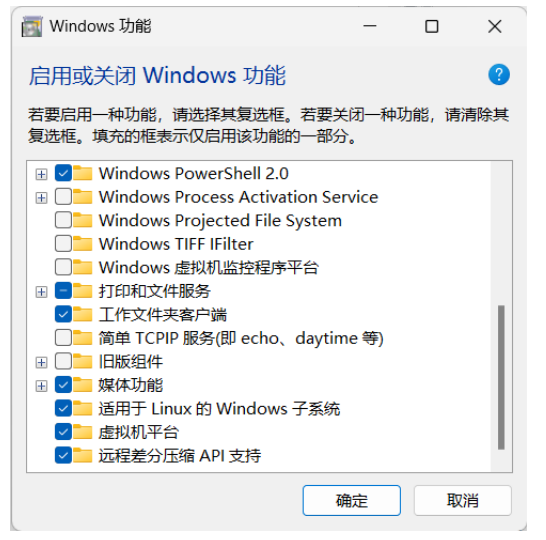
WSL 安裝:啟動或關閉 Windows 功能
2)WSL Conda 和 RAPIDS 安裝
RAPIDS 官網提供在 WSL 中安裝 Conda 和 RAPIDS 的方法,參考文檔:https://docs.rapids.ai/install#wsl2。
以下是在 WSL 中安裝 Conda 和 RAPIDS 的要點:
- 啟動 WSL,登錄 Ubuntu 系統
- 運行指令下載并安裝 Miniconda:wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh bash Miniconda3-latest-Linux-x86_64.sh
- 運行 export PATH=/home/username/miniconda3/bin:$PATH,設置環境變量
- 在 RAPIDS 官網(https://docs.rapids.ai/install)選擇需要安裝的版本、方式、CUDA版本、Python 版本、RAPIDS 庫種類、附加擴展庫,生成相應代碼,在 WSL 中運行
以僅安裝 cuDF 和 cuML 為例,運行代碼 conda create --solver=libmamba -n rapids-23.08 -c rapidsai -c conda-forge -c nvidia cudf=23.08 cuml=23.08 python=3.10 cuda-version=11.2。該指令將自動創建名為 rapids-23.08 的 conda 環境。
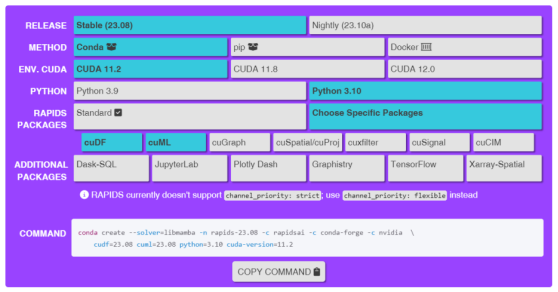
RAPIDS 安裝:選擇版本
- 激活名為 rapids-23.08 的 Conda 環境
- 進入 Python 環境,運行以下代碼以驗證安裝是否成功:import cudf print(cudf.Series([1, 2, 3]))
- Miniconda 環境僅提供了少數庫,可以通過 Conda install 命令來安裝 Pandas 等常用庫
- 在代碼中調用 Windows 系統文件時,請使用路徑“/mnt/盤符/路徑”,例如“/mnt/d/data”
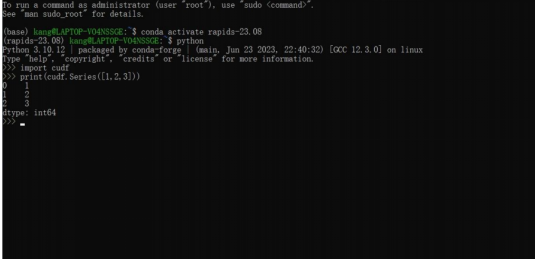
RAPIDS 安裝:在 WSL 中運行
2、高頻因子代碼優化
測試環境:CPU - Intel Core i9-10980XE,GPU - NVIDIA GeForce RTX 3090。以2023年4月24日單日全A股分鐘線數據為例,測試時間開銷。在將CPU計算代碼改造為GPU版本時,有兩種優化方式:使用CuPy和cuDF替換NumPy和Pandas函數(針對全部50個因子);使用矩陣運算替換for循環(針對50個因子中的22個因子)。
結果表明:
- 單獨使用第一種優化方式反而增加時間開銷
- 同時使用兩種優化方式,時間開銷總體縮短約117倍,其中第一種優化方式貢獻約18.4倍,第二種優化方式貢獻約6.4倍
- GPU性能表現主要取決于數據量,單次運算涉及的數據量越大,GPU加速效果越顯著。如果數據量過小,反而不如CPU計算效率
1)簡單替換庫函數
RAPIDS的CuPy和cuDF與原始CPU代碼的NumPy和Pandas具有相似的接口,因此可以通過簡單地替換庫名稱來簡化工作量。以計算下行收益率方差return_downward_var的代碼為例,只需將numpy.var替換為cupy.var即可。cuDF的具體指令集可參考官方文檔:https://docs.rapids.ai/api/cudf/stable/

計算下行收益率方差 return_downward_var 代碼:for 循環+CPU
實證發現,CPU版代碼的單日高頻因子計算時間開銷為12.34秒,但簡單替換為GPU版代碼后,時間開銷反而超過100秒。問題在于,代碼在因子計算中大量使用for循環,而RAPIDS的接口只實現接口內部的并行計算,并未對for循環進行優化。此外,由于數據需要在CPU和GPU之間進行拷貝傳遞,這也帶來額外耗時。GPU更適合進行批量運算,如果只是簡單替換庫函數,而for循環逐輪調用GPU處理小數據量,反而會拖累性能。因此,在進行GPU加速時,需要考慮代碼的整體結構和優化方法。
2)矩陣運算代替 for 循環,同時替換庫函數
下面將重新調整for循環的邏輯,將其改為矩陣運算,并使用CuPy接口進行批量處理。以下是一個計算下行收益率方差return_downward_var的代碼示例。

計算下行收益率方差 return_downward_var 代碼:矩陣運算+CPU
- 對于50個替換庫函數的因子,GPU相比CPU總時間開銷從0.91秒縮短至0.16秒,性能提升約5.9倍
- 對于22個使用矩陣運算代替for循環的因子,CPU總時間開銷從12.34秒縮短至0.67秒,性能提升約18倍。GPU相比CPU總時間開銷從0.67秒縮短至0.11秒,性能提升約6.4倍。兩項改進總時間開銷從12.34秒縮短至0.11秒,性能提升約117倍
總的來說,使用GPU(NVIDIA 3090)相比使用CPU(Intel i9-10980XE)計算因子帶來的性能提升在5.9~6.4倍之間。這個約6倍的加速效果并不是上限,實際加速效果受到顯卡性能和數據量等多種因素的影響。根據NVIDIA官網的數據,RAPIDS的提速可達50倍。(https://www.nvidia.cn/deep-learning-ai/software/rapids/)
同時觀察到一些沒有GPU加速效果的因子,例如return_intraday、return_improved、return_last_30min等,這些因子僅使用日內兩個時間點的數據,因此數據量過少。另外,對于intraday_maxdrawdown這個因子,CuPy尚未實現numpy.minimum.accumulate接口,導致調用GPU反而耗時增加。

因子計算環節 CPU、GPU 性能對比(匯總)
除了因子計算,還使用cudf庫替換pandas庫,對數據讀取和預處理環節進行優化。然而,測試發現數據讀取和預處理部分性能不佳的主要原因是數據量不足。單日分鐘K線數據的維度約為5000×242×11(全A股分鐘字段)。嘗試構建虛擬數據集,發現當數據量擴大4倍后,GPU性能超過CPU。此外,發現cudf庫僅有數據導出環節的to_csv函數性能更優(約5倍加速)。

數據讀取、預處理及導出環節 CPU、GPU 性能對比
芯片禁令升級后
我們該何去何從?
前幾天,美國正式發布“新規”,全面收緊尖端AI芯片對華出口,禁令將在30天內生效。
一、新一輪禁令有哪些新變化?
只要滿足以下任一條件,GPU芯片就會受到出口限制:總算力低于300 TFLOPS,或每平方毫米的算力低于370 GFLOPS。此次新規的主要變化在于降低門檻,并取消“帶寬參數”,轉而采用“性能密度”作為衡量標準。此舉旨在堵住一個漏洞,即通過Chiplet技術將多個小芯片組裝成一個大芯片。
根據這一新規,英偉達的A100、A800、H100、H800、L40和L40S等產品將無法向中國出售。甚至定位于發燒級游戲顯卡的RTX 4090也需要報批,因為在老美的邏輯中,RTX 4090也可以用于AI訓練,盡管其優勢并不在此。
二、當前AI大模型一般用什么卡在訓練?
自年初以來,業界各家都在積極開發自家的大模型,這些模型通常都以GPT-4模型為標桿,GPT-4的參數量高達1.76萬億,已經達到現有算力的極限。實際上,OpenAI需要使用約2.5萬個A100 GPU訓練GPT-4,耗時約100天。而對于下一代大模型GPT-5,根據馬斯克的說法,可能需要3-5萬塊H100 GPU進行訓練,但具體的訓練時間并未提及。
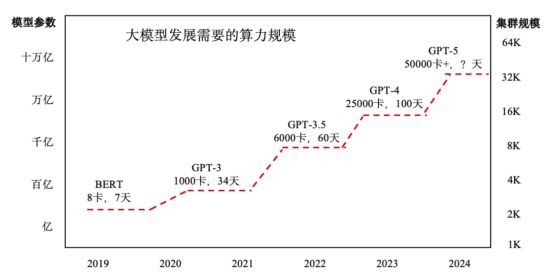
目前,國內第一批大模型廠商主要使用英偉達芯片,今年的主力芯片預計仍是A100、A800。而H800近期才逐漸在國內交付。英偉達構建完備的CUDA生態,使得用戶在更換生態時面臨較高的學習成本、試錯成本和調試成本。一位客戶表示:“如果不是情非得已,絕大部分用戶不敢貿然更換生態,因為那意味著學習、試錯和調試成本都會增加。”這表明,采用國產GPU可能會導致用戶在某些方面落后于同行,盡管金錢成本可能不是主要考慮因素,但速度和效率卻是關鍵。
根據華為公布的數據,昇騰910B基本上可以與英偉達的A800相媲美。然而,由于高端顯存方面的不足,其實際性能可能會打些折扣,約為A800的90%。如果采用大型服務集群,折扣可能會更大。當然,真正的難點并不在于技術參數,而在于應用生態和AI模型底層算法的差距。CUDA的優勢恰恰在于此,這也是最難以突破的地方。
三、面對新一輪禁令,該何去何從?
關于CUDA生態的解決方案,可以從鴻蒙操作系統得到啟示。雖然鴻蒙生態短期內還無法與iOS和安卓系統抗衡,但其中包含兼容Google生態的代碼,使得能夠兼容基于安卓開發的APP。這是短期內的解決方案,但長遠來看,建立自己的軟件生態是擺脫制約的關鍵。至于何時能夠實現這一“脫鉤”,華為官方表示,下一個鴻蒙版本可能會是一個轉折點。
在GPU領域,也可以采取類似的策略。首先,可以為國產GPU增加一個虛擬化層,實現與基于CUDA開發的應用軟件的兼容。這可以作為過渡期的解決方案。然而,長遠來看,國產GPU必須構建自己的軟件生態。例如,華為的CANN被視為對標CUDA的解決方案,兼容PyTorch、TensorFlow等主流AI框架。最近有消息稱,華為成為了PyTorch基金會的最高級別會員,這是中國首個加入該基金會的會員,也是全球第10個。這意味著CANN將能夠跟上PyTorch的發展。
在大模型時代,頭部客戶的需求逐漸收斂,使用的算子庫也相應減少。據報道,目前主流AI框架的兼容性已經超過50%。同時,華為也在推廣自己的AI框架MindSpore(昇思),據稱在國內已經與百度的PaddlePaddle(飛槳)并列第三,市場份額達到11%。一些基于華為原生態體系孵化的大模型已經在使用“昇騰GPU+CANN+MindSpore”整套國產體系,例如“訊飛星火認知”、盤古NLP、鵬城盤古、盤古CV等。而通過“昇騰GPU+CANN”適配的大模型則更多,包括GPT、ChatGLM、LLaMA、BLOOM等主流基礎大模型。
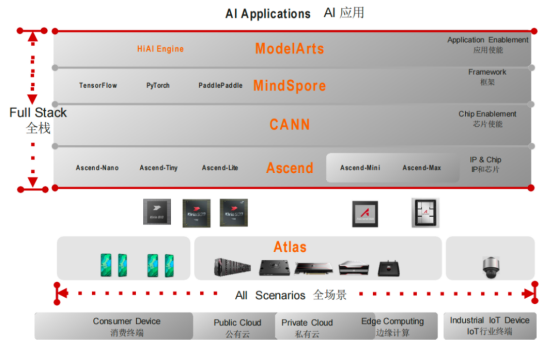
藍海大腦大模型訓練平臺
藍海大腦大模型訓練平臺提供強大的算力支持,包括基于開放加速模組高速互聯的AI加速器。配置高速內存且支持全互聯拓撲,滿足大模型訓練中張量并行的通信需求。支持高性能I/O擴展,同時可以擴展至萬卡AI集群,滿足大模型流水線和數據并行的通信需求。強大的液冷系統熱插拔及智能電源管理技術,當BMC收到PSU故障或錯誤警告(如斷電、電涌,過熱),自動強制系統的CPU進入ULFM(超低頻模式,以實現最低功耗)。致力于通過“低碳節能”為客戶提供環保綠色的高性能計算解決方案。主要應用于深度學習、學術教育、生物醫藥、地球勘探、氣象海洋、超算中心、AI及大數據等領域。
在最底層,構建基于英偉達GPU的全場景AI基礎設施方案,適用于“端、邊、云”等各種應用環境。幫助開發者更快速、更高效地構建和部署AI應用。


一、為什么需要大模型?
1、模型效果更優
大模型在各場景上的效果均優于普通模型。
2、創造能力更強
大模型能夠進行內容生成(AIGC),助力內容規模化生產。
3、靈活定制場景
通過舉例子的方式,定制大模型海量的應用場景。
4、標注數據更少
通過學習少量行業數據,大模型就能夠應對特定業務場景的需求。
二、平臺特點
1、異構計算資源調度
一種基于通用服務器和專用硬件的綜合解決方案,用于調度和管理多種異構計算資源,包括CPU、GPU等。通過強大的虛擬化管理功能,能夠輕松部署底層計算資源,并高效運行各種模型。同時充分發揮不同異構資源的硬件加速能力,以加快模型的運行速度和生成速度。
2、穩定可靠的數據存儲
支持多存儲類型協議,包括塊、文件和對象存儲服務。將存儲資源池化實現模型和生成數據的自由流通,提高數據的利用率。同時采用多副本、多級故障域和故障自恢復等數據保護機制,確保模型和數據的安全穩定運行。
3、高性能分布式網絡
提供算力資源的網絡和存儲,并通過分布式網絡機制進行轉發,透傳物理網絡性能,顯著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用嚴格的權限管理機制,確保模型倉庫的安全性。在數據存儲方面,提供私有化部署和數據磁盤加密等措施,保證數據的安全可控性。同時,在模型分發和運行過程中,提供全面的賬號認證和日志審計功能,全方位保障模型和數據的安全性。
三、常用配置
1、CPU:
Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
AMD EPYC? 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
AMD EPYC? 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
2、GPU:
NVIDIA L40S GPU 48GB
NVIDIA NVLink-A100-SXM640GB
NVIDIA HGX A800 80GB
NVIDIA Tesla H800 80GB HBM2
NVIDIA A800-80GB-400Wx8-NvlinkSW×8
審核編輯 黃宇
-
gpu
+關注
關注
28文章
4702瀏覽量
128710 -
AI
+關注
關注
87文章
30178瀏覽量
268441 -
算力
+關注
關注
1文章
931瀏覽量
14747 -
大模型
+關注
關注
2文章
2335瀏覽量
2491
發布評論請先 登錄
相關推薦
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
英偉達發布新一代 GPU 架構圖靈和 GPU 系列 Quadro RTX
英偉達GPU慘遭專業礦機碾壓,黃仁勛宣布砍掉加密貨幣業務!
rx580算力,rx580顯卡算力,rx588算力,rx588顯卡算力 精選資料分享
瑞芯微和英偉達的邊緣計算盒子方案,你會選哪一家的?
英偉達加速部署下一代GPU,7納米GPU性能有希望提升100%
英偉達的算力霸主之路 “卷王”英偉達的真面目
火種初現的國產GPU,誰能突破算力封鎖?
大模型訓練,英偉達Turing、Ampere和Hopper算力分析







 工商網監
工商網監
評論