 探索SFT訓練策略對性能的影響
探索SFT訓練策略對性能的影響
SFT是目前最常見的調節模型效果的手段,然而它雖然看起來簡單(準備好數據->啟動),真正優化起效果來卻困難重重,尤其是當我們有一堆能力項要優化時(推理能力、閑聊能力等),事情往往不會像我們預想的那樣發展,單獨調節能力和混合調節能力完全是兩個難度。
今天就和大家分享我們在近期的一篇工作,探索混合數據后的模型優化姿勢:

什么是SFT階段的數據組成(Data Composition)問題?
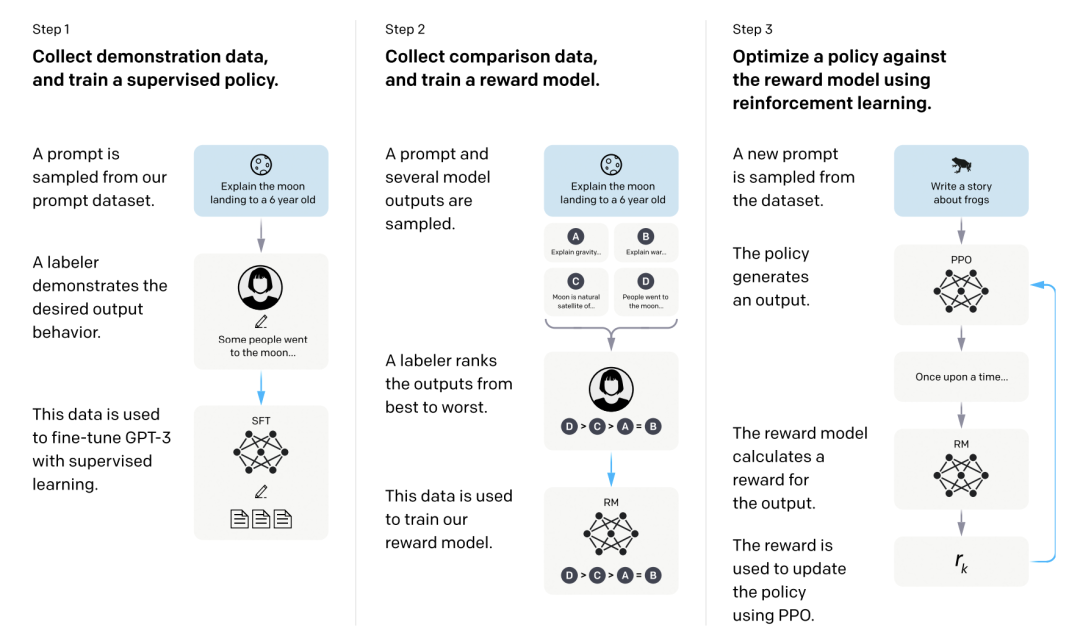
在大語言模型的監督微調階段(Superviesd Finetuning, SFT),我們通過混合注入不同能力項的數據(數學推理,翻譯,代碼,通用能力等),來解鎖大模型多樣化的能力。然而由于不同能力項的數據的來源、領域、分布,以及數據規模的不同,這些因素都將對模型性能產生劇烈的影響。因此,SFT的數據組成問題旨在探究模型能力與各種能力項數據之間的關系,包括不同能力項的數據量、數據配比、模型參數量和微調訓練策略等,這對未來全面提升大模型的奠定了堅實的基礎。
本文聚焦于SFT階段的數學推理能力,代碼生成能力,以及通用指令遵循能力,這三個能力的數據集及評測指標的介紹如下:
? GSM8K RFT [1] 是一個增強的數學推理數據集,它基于GSM8K數據集[4]并結合RFT策略整合了多條推理路徑。訓練集中包含7.5K個問題和110K個回答,我們所有實驗數學的評測指標為GSM8k測試集分數。
? Code Alpaca [2] 旨在構建一個遵循指令,生成代碼的LLaMA模型,構建方式完全基于Stanford Alpaca,包含20K對的代碼數據,我們代碼生成的評測指標為HumanEval。
? ShareGPT [3] 使用多輪對話歷史記錄,包括約9w條來自人類的提問和來自ChatGPT和其他聊天機器人的回復。我們通用能力的評測指標為MT-Bench。
本文旨在從Data Scaling的視角,全面性地研究模型性能與不同因素之間的關系,包括數據量,數據配比,模型參數量和SFT訓練策略。我們的文章以4個研究問題(RQ)為主線進行探究。
RQ1: 隨著數據量的增加,數學推理、代碼生成和通用能力的性能變化趨勢如何?
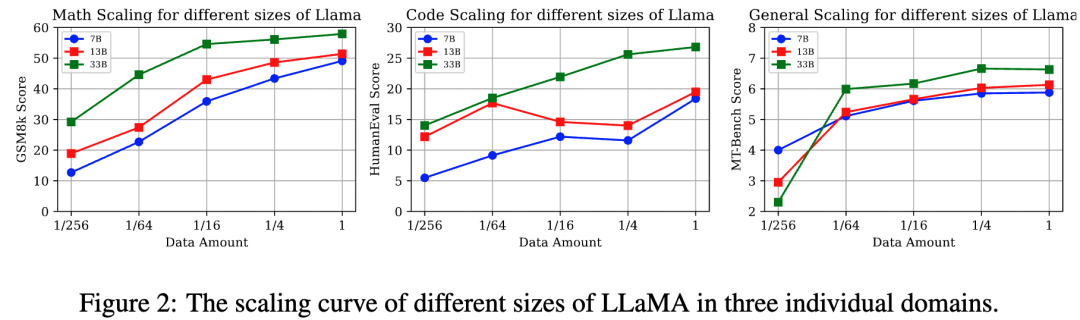
實驗設置:
我們使用來自數學,代碼,通用能力的訓練集按比例{1, 1/4, 1/16, 1/64, 1/256}對不同參數量的LLaMA進行監督微調。來評估每種單獨能力項在不同數據量/模型參數量下的表現。
核心結論(圖2):
? 不同能力項有不同的Data Scaling曲線:數學推理能力,通用能力與數據量呈正相關模型的性能縮放曲線。值得注意的是通用能力只需要大約 1k數據樣本便會產生性能激增(數據量從1/256 到 1/64),并在達到一定閾值提高緩慢(1/64),這契合于LIMA[5]文中所提到的“Less is more”。然而代碼能力在7B,13B則呈現不規則的性能曲線,33B呈現log-linear的趨勢。
? 數據充足的情況下,更大參數量的模型往往有更強大的性能
RQ2: 在SFT階段中,將三種能力項數據直接混合是否會產生性能沖突?
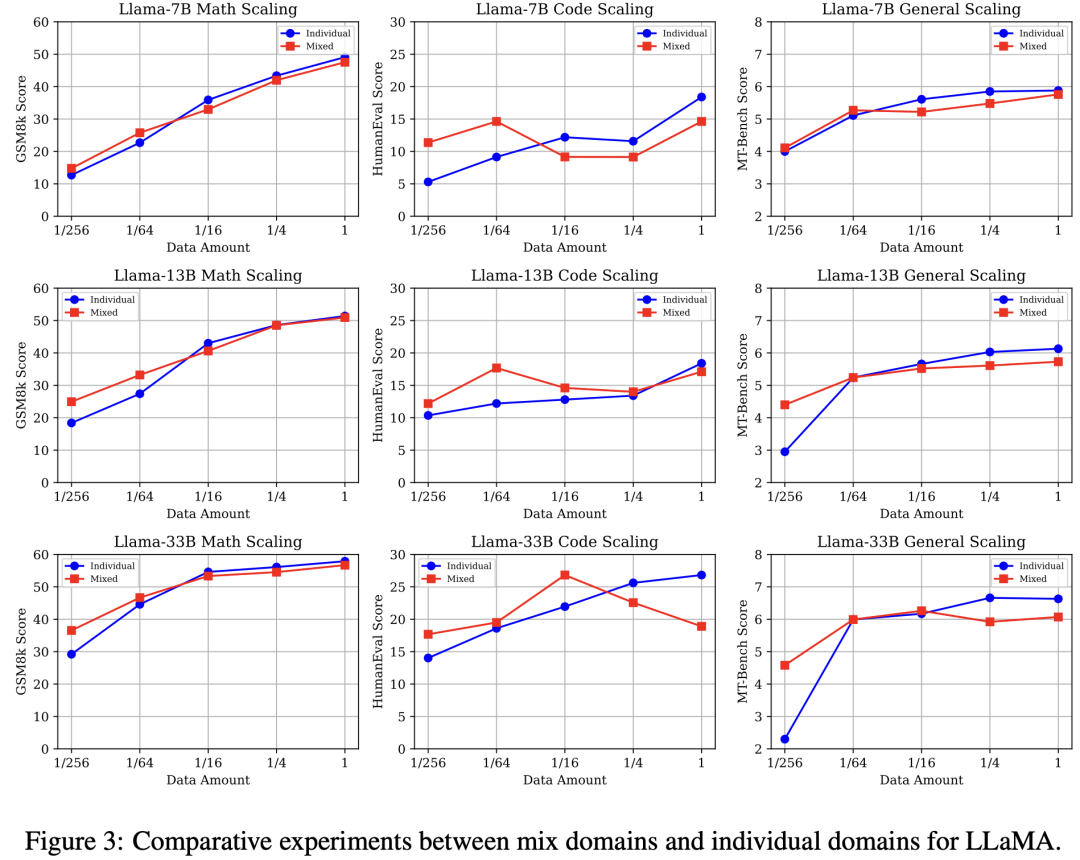
實驗設置:
單數據源:分別使用{1, 1/4, 1/16, 1/64, 1/256}數量的數學,代碼,通用能力數據對LLaMA模型微調。
混合數據源:分別使用{1, 1/4, 1/16, 1/64, 1/256}數量的三種能力項數據,三種數據按照同等的數據比例直接混合,來對LLaMA模型微調。
核心結論(圖3):
? 與單數據源相比,混合數據源設置呈現低資源性能增益,而高資源性能沖突: 三種能力的性能放縮曲線一致呈現高資源下(1/1)混合數據源設置弱于單數據源,然而隨著數據量下降二者產生性能轉折,最終低資源(1/256)下混合數據源產生明顯性能增益。
? 隨著模型參數量的提高,數學推理與通用能力在低資源下的性能增益更加顯著
RQ3: 什么是產生性能沖突的關鍵因素:
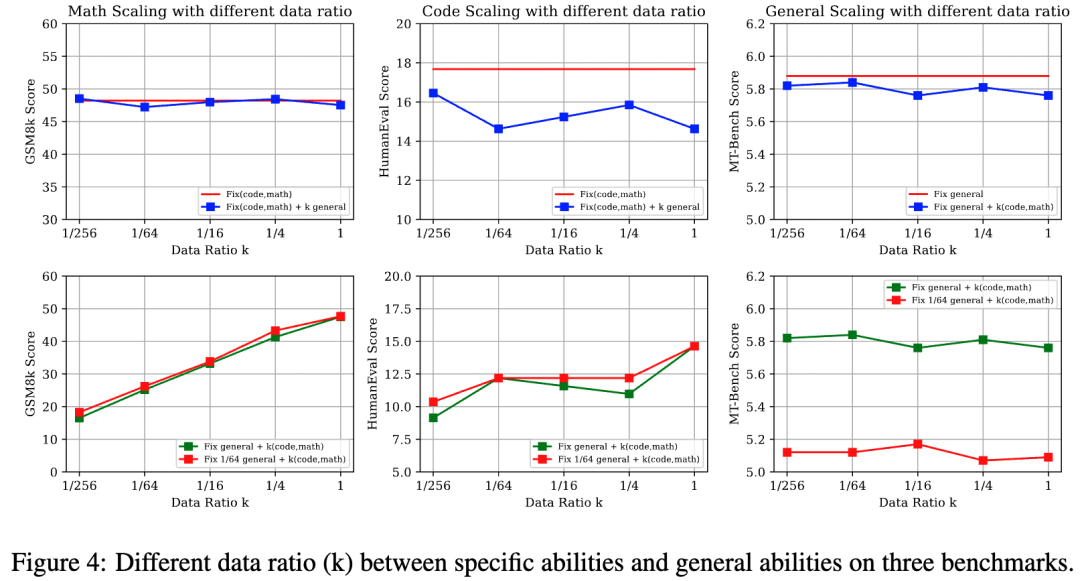
實驗設置:
我們將代碼生成與數學推理數據視為特定能力數據源,而ShareGPT則為通用能力數據源。我們設計了以下三種設置來探究通用數據和特定能力數據之間的比例變化:
固定通用數據,放縮特定能力數據:Fix general + k (code, math)
固定特定能力數據,放縮通用數據:Fix (code, math)l + k general
固定1/64通用數據,放縮特定能力數據:Fix 1/64 general+ k (code, math)
核心結論(圖4):
? 當不同的SFT能力之間存在顯著的任務格式和數據分布差異時(數學和通用數據之間),數據比例的影響較小。然而,當存在一定程度的相似性時(代碼和通用數據之間),數據比例可能會導致明顯的性能波動。(數據分布的討論見D1)
? 即便在通用數據資源非常有限的情況下,特定能力的數據比例的放縮也沒有對通用能力造成明顯影響。
RQ4: 不同的SFT訓練策略對數據組成的影響是什么?
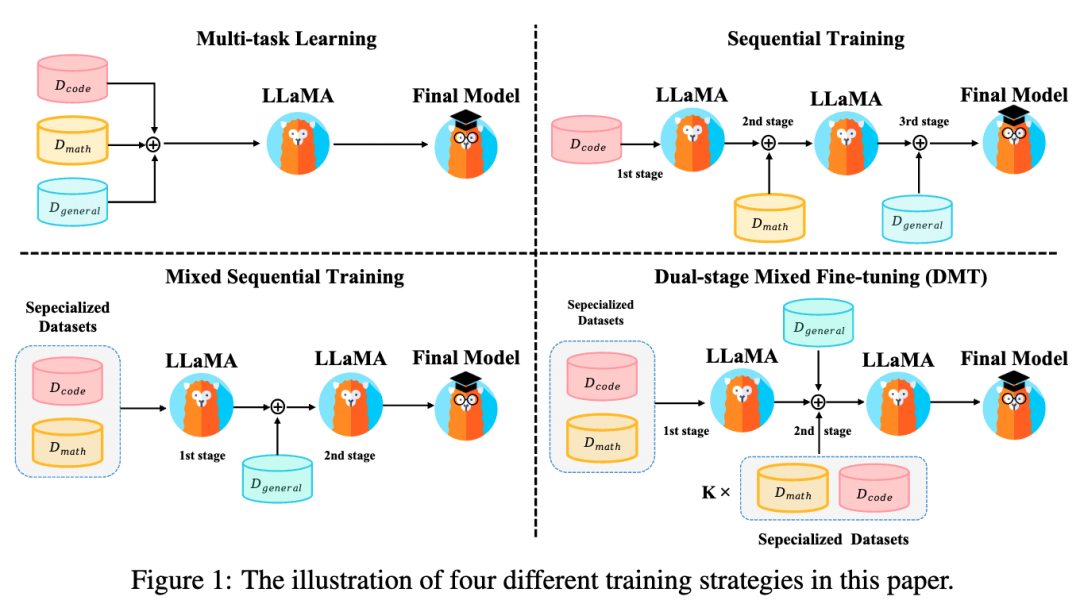
實驗設置:
如圖1所示,我們探究以上SFT訓練策略對性能的影響:
多任務學習:直接混合不同的SFT能力項數據進行SFT。若將每個數據源視為不同任務,則可視為多任務學習。
順序訓練:按順序依次在各能力項數據集上微調。由于通用能力是人類對齊的核心能力,我們將通用能力數據放在最后階段微調。
混合順序訓練:首先在特定能力數據集(代碼、數學)上進行多任務學習,然后在通用能力數據集上進行SFT。
兩階段混合微調(DMT):我們綜合RQ1-3的結論與上述訓練策略的優缺點,提出DMT策略。在第一階段我們首先在特定能力數據集(代碼、數學)上進行多任務學習。在第二階段我們使用混合數據源進行SFT,其中包括通用數據和一定比例k的特定能力數據(k = 1, 1/2, 1/4, 1/8, 1/16, 1/32),這有助于緩解模型對特定能力的災難性遺忘。
核心結論(表1):
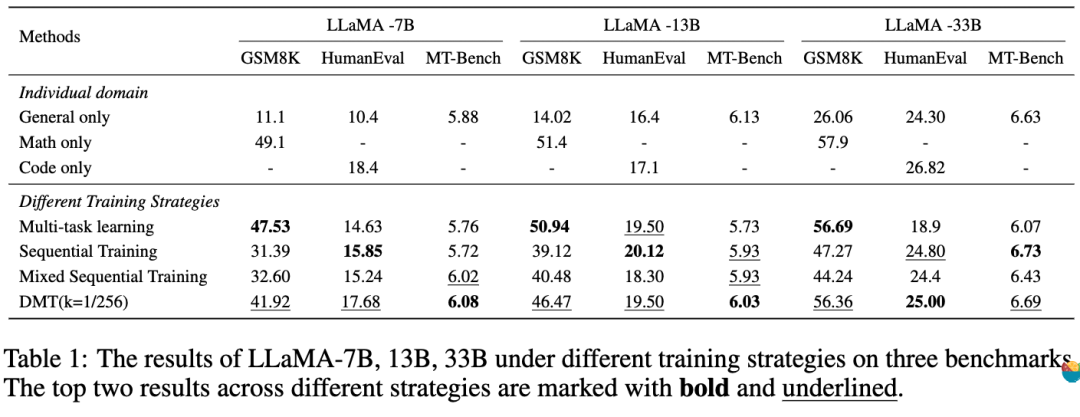
? 多任務學習在盡可能保留了特有能力,但是通用能力性能下降顯著。
? 兩種順序訓練保留了通用能力能力,但是由于多階段的微調產生災難性遺忘,使得他失去了太多的特定能力(尤其是數學)。
? 在不同的模型參數量下(7B,13B,33B),DMT (k = 1/256)策略在特定能力方面(數學,代碼)均有顯著改善,甚至對于通用能力也有一定程度的優化。
Discussion
D1:不同能力的語義表示的可視化
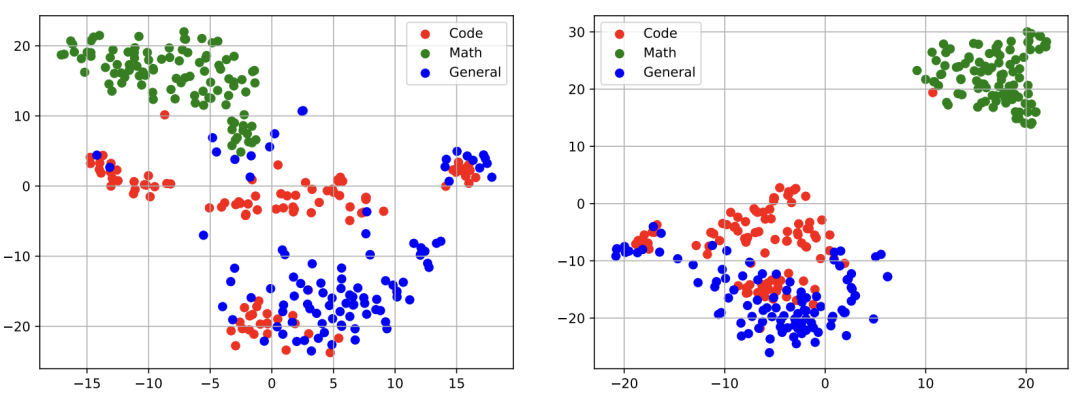
實驗發現:如上圖所示,通過對 LLaMA-13b [左]和 DMT-13b (k=1/256) [右]策略下 LLaMA-13b 的第15層的語義表示進行可視化,我們發現雖然這兩個模型可以分離開數學能力的語義表示,但是在代碼數據與通用能力數據的語義表示間,仍存在一定程度的坍縮重疊現象。
D2: 消融通用能力數據中的代碼和數學樣本
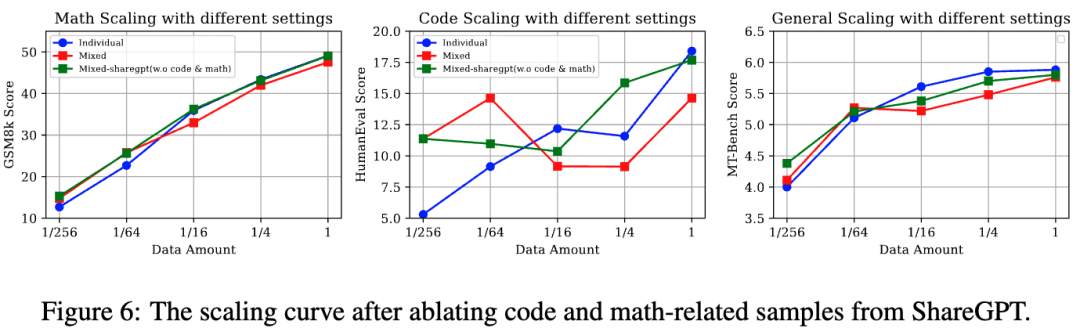
實驗設計:為了消融通用能力數據中的特定能力數據,我們使用InsTag[1]工具對通用能力數據中的樣本標注標簽。并通過正則匹配過濾掉“數學”,“代碼”相關數據(從90K減少到63K)。與RQ2中的設置對齊,我們從數學,代碼,與過濾后的通用能力數據集中抽樣不同比例的訓練數據(1, 1/4, 1/16, 1/64, 1/256),并按照相應的比例直接混合后來微調LLaMA。
實驗結論:如圖6所示,移除通用能力數據中的代碼和數學后,低資源設置下依舊保持了穩定的增益。這個消融實驗也表明通用能力中的代碼和數學樣本不是導致低資源性能增益的關鍵因素,而是數據的多樣性和可變性。
D3:雙階段混合微調(DMT)中第二階段特定能力數據的比例K
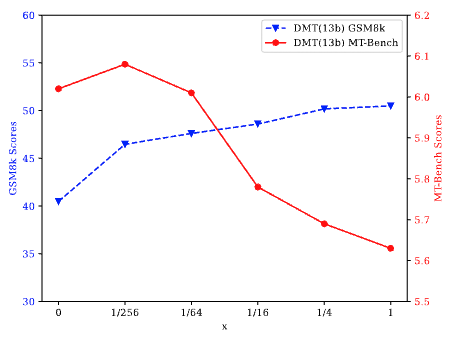
實驗發現:如上圖所示,當我們將k從0調整到1/256(k = 0等于混合順序訓練)時,發現模型在特定能力和通用能力方面都表現出顯著的提升。相反,當k從1/4增加到1時,模型的通用能力出現下降。我們認為這與RQ2的發現一致,即高資源環境會導致沖突,而低資源環境會導致混合來源的增益。此外,當k從1/256增加到1/4時,特定能力與通用能力呈現此消彼長的趨勢。這表明需要根據具體大模型SFT需求調整k值,以在多種能力之間實現平衡。
總結
大模型混合多種能力項數據進行微調時,會呈現高資源沖突,低資源增益的現象。我們提出的DMT策略通過在第一階段微調特定能力數據,在第二階段微調通用數據+少量的特定能力數據,可以在保留通用能力的同時,極大程度地挽救大模型對特定能力的災難性遺忘,這為SFT的數據組成問題提供了一個簡單易行的訓練策略。值得注意的是,第二階段微調時混合的特定能力數據量需要根據需求而定。
一句話概括:訓通用大模型就少混點,訓特定能力就著重多混合點!
編輯:黃飛
-
數據
+關注
關注
8文章
6909瀏覽量
88850 -
語言模型
+關注
關注
0文章
508瀏覽量
10247 -
SFT
+關注
關注
0文章
9瀏覽量
6807 -
大模型
+關注
關注
2文章
2339瀏覽量
2501
原文標題:總結
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Waiting for SFT on the OMAP-L138... 問題?
停留在Waiting for SFT on the OMAP-L138
如何進行高效的時序圖神經網絡的訓練
探索一種降低ViT模型訓練成本的方法
FSB50760SFT Motion SPM
FSB50660SFT Motion SPM
CAT-D48-SFT273 DEUTSCH 沖壓成型端子
小米在預訓練模型的探索與優化

面向K近鄰分類性能的遺傳訓練集優化算法
設計模式最佳實踐探索—策略模式
微軟開源“傻瓜式”類ChatGPT模型訓練工具
YOLOv5網絡結構訓練策略詳解





 工商網監
工商網監
評論