") 如何利用CLIP 的2D 圖像-文本預(yù)習(xí)知識(shí)進(jìn)行3D場(chǎng)景理解
如何利用CLIP 的2D 圖像-文本預(yù)習(xí)知識(shí)進(jìn)行3D場(chǎng)景理解
前言:
3D場(chǎng)景理解是自動(dòng)駕駛、機(jī)器人導(dǎo)航等領(lǐng)域的基礎(chǔ)。當(dāng)前基于深度學(xué)習(xí)的方法在3D點(diǎn)云數(shù)據(jù)上表現(xiàn)出了十分出色的性能。然而,一些缺點(diǎn)阻礙了它們?cè)诂F(xiàn)實(shí)世界中的應(yīng)用。第一個(gè)原因是他們嚴(yán)重依賴(lài)大量的帶注釋點(diǎn)云,尤其是當(dāng)高質(zhì)量的3D注釋獲取成本高昂時(shí)。此外,他們通常不能識(shí)別訓(xùn)練數(shù)據(jù)中從未見(jiàn)過(guò)的新物體。因此,可能需要額外的注釋工作來(lái)訓(xùn)練模型識(shí)別這些新的對(duì)象,這既繁瑣又費(fèi)時(shí)。
OpenAI的CLIP為緩解2D視覺(jué)中的上述問(wèn)題提供了一個(gè)新的視角。該方法利用網(wǎng)站上大規(guī)模免費(fèi)提供的圖文對(duì)進(jìn)行訓(xùn)練,建立視覺(jué)語(yǔ)言關(guān)聯(lián),以實(shí)現(xiàn)有前景的開(kāi)放詞匯識(shí)別。基于此,MaskCLIP做了基于CLIP的2D圖像語(yǔ)義分割的擴(kuò)展工作。在對(duì)CLIP預(yù)訓(xùn)練網(wǎng)絡(luò)進(jìn)行最小修改的情況下,MaskCLIP可以直接用于新對(duì)象的語(yǔ)義分割,而無(wú)需額外的訓(xùn)練工作。PointCLIP將CLIP的樣本分類(lèi)問(wèn)題從2D圖像推廣到3D點(diǎn)云。它將點(diǎn)云框架透視投影到2D深度圖的不同視圖中,以彌合圖像和點(diǎn)云之間的模態(tài)間隙。上述研究表明了CLIP在2D分割和3D分類(lèi)性能方面的潛力。然而,CLIP是否可以及如何有利于3D場(chǎng)景理解仍有待探索。
本文探討了如何利用 CLIP 的2D 圖像-文本預(yù)習(xí)知識(shí)進(jìn)行3D 場(chǎng)景理解。作者提出了一個(gè)新的語(yǔ)義驅(qū)動(dòng)的跨模態(tài)對(duì)比學(xué)習(xí)框架,它充分利用 CLIP 的語(yǔ)義和視覺(jué)信息來(lái)規(guī)范3D 網(wǎng)絡(luò)。
作者主要的貢獻(xiàn)如下:
1、作者是第一個(gè)將CLIP知識(shí)提煉到3D網(wǎng)絡(luò)中用于3D場(chǎng)景理解的。
2、作者提出了一種新的語(yǔ)義驅(qū)動(dòng)的跨模態(tài)對(duì)比學(xué)習(xí)框架,該框架通過(guò)時(shí)空和語(yǔ)義一致性正則化來(lái)預(yù)訓(xùn)練3D網(wǎng)絡(luò)。
3、作者提出了提出了一種新的語(yǔ)義引導(dǎo)的時(shí)空一致性正則化,該正則化強(qiáng)制時(shí)間相干點(diǎn)云特征與其對(duì)應(yīng)的圖像特征之間的一致性。
4、該方法首次在無(wú)注釋的三維場(chǎng)景分割中取得了良好的效果。當(dāng)使用標(biāo)記數(shù)據(jù)進(jìn)行微調(diào)時(shí),本文的方法顯著優(yōu)于最先進(jìn)的自監(jiān)督方法。這里也推薦「3D視覺(jué)工坊」新課程《徹底搞懂視覺(jué)-慣性SLAM:VINS-Fusion原理精講與源碼剖析》
相關(guān)工作:
三維零樣本學(xué)習(xí):
零樣本學(xué)習(xí)(ZSL)的目標(biāo)是識(shí)別訓(xùn)練集中看不見(jiàn)的對(duì)象。但是目前的方法主要都是基于2D識(shí)別的任務(wù),對(duì)三維領(lǐng)域執(zhí)行ZSL的研究特別有限。本文進(jìn)一步研究了 CLIP 中豐富的語(yǔ)義和視覺(jué)知識(shí)對(duì)三維語(yǔ)義分割任務(wù)的影響。
自監(jiān)督表征學(xué)習(xí):
自我監(jiān)督學(xué)習(xí)的目的是獲得有利于下游任務(wù)的良好表現(xiàn)。主流的方法是使用對(duì)比學(xué)習(xí)來(lái)與訓(xùn)練網(wǎng)絡(luò)。受CLIP成功的啟發(fā),利用CLIP的預(yù)訓(xùn)練模型來(lái)完成下游任務(wù)引起了廣泛的關(guān)注。本文利用圖像文本預(yù)先訓(xùn)練的CLIP知識(shí)來(lái)幫助理解3D場(chǎng)景。
跨模式知識(shí)蒸餾:
近年來(lái),越來(lái)越多的研究集中于將二維圖像中的知識(shí)轉(zhuǎn)化為三維點(diǎn)云進(jìn)行自監(jiān)督表示學(xué)習(xí)。本文首先嘗試?yán)?CLIP 的知識(shí)對(duì)一個(gè)三維網(wǎng)絡(luò)進(jìn)行預(yù)訓(xùn)練。
具體方法:
本文研究了用于3D場(chǎng)景理解的CLIP的跨模態(tài)知識(shí)轉(zhuǎn)移,稱(chēng)為CLIP2Scene。本文的工作是利用CLIP知識(shí)進(jìn)行3D場(chǎng)景理解的先驅(qū)。本文的方法由三個(gè)主要組成部分組成:語(yǔ)義一致性正則化、語(yǔ)義引導(dǎo)的時(shí)空一致性規(guī)則化和可切換的自我訓(xùn)練策略。
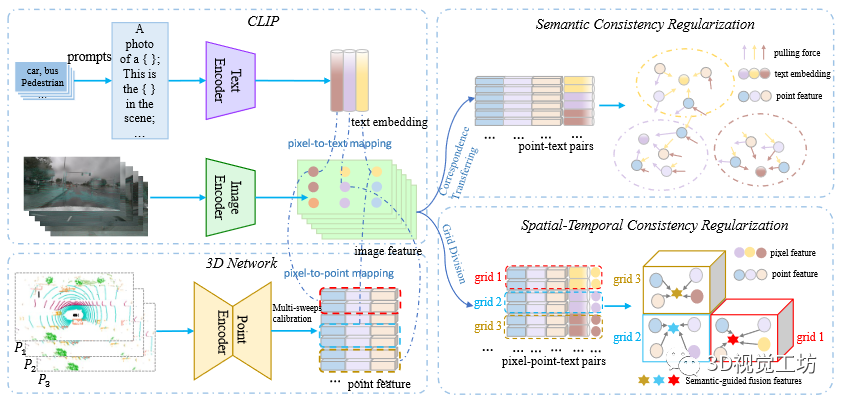
圖1 語(yǔ)義驅(qū)動(dòng)的跨模態(tài)對(duì)比學(xué)習(xí)圖解。首先,本文分別通過(guò)文本編碼器、圖像編碼器和點(diǎn)編碼器獲得文本嵌入、圖像像素特征和點(diǎn)特征。本文利用CLIP知識(shí)來(lái)構(gòu)建用于對(duì)比學(xué)習(xí)的正樣本和負(fù)樣本。這樣就得到了點(diǎn)-文本對(duì)和短時(shí)間內(nèi)的所有像素點(diǎn)文本對(duì)。因此,和分別用于語(yǔ)義一致性正則化和時(shí)空一致性規(guī)則化。最后,通過(guò)將點(diǎn)特征拉到其相應(yīng)的文本嵌入來(lái)執(zhí)行語(yǔ)義一致性正則化,并通過(guò)將時(shí)間上相干的點(diǎn)特征模仿到其對(duì)應(yīng)的像素特征來(lái)執(zhí)行時(shí)空一致性正則化。
CLIP2Scene
語(yǔ)義一致性正則化
由于CLIP是在2D圖像和文本上預(yù)先訓(xùn)練的,作者首先關(guān)注的是2D圖像和3D點(diǎn)云之間的對(duì)應(yīng)關(guān)系。具體的,使用既可以獲得圖像和點(diǎn)云的因此,可以相應(yīng)地獲得密集的像素-點(diǎn)對(duì)應(yīng),其中和表示第i個(gè)成對(duì)的圖像特征和點(diǎn)特征,它們分別由CLIP的圖像編碼器和3D網(wǎng)絡(luò)提取。M是對(duì)數(shù)。

圖2 圖像像素到文本映射的圖示。密集像素-文本對(duì)應(yīng)關(guān)系是通過(guò)MaskCLIP的方法提出的。
本文提出了一種利用CLIP的語(yǔ)義信息的語(yǔ)義一致性正則化。具體而言,本文通過(guò)遵循off-the-shelf方法MaskCLIP(圖2)生成密集像素文本對(duì),其中是從CLIP的文本編碼器生成的文本嵌入。請(qǐng)注意,像素文本映射可從CLIP免費(fèi)獲得,無(wú)需任何額外的訓(xùn)練。然后,我們將像素文本對(duì)轉(zhuǎn)換為點(diǎn)文本對(duì),并利用文本語(yǔ)義來(lái)選擇正點(diǎn)樣本和負(fù)點(diǎn)樣本進(jìn)行對(duì)比學(xué)習(xí)。目標(biāo)函數(shù)如下:其中,代表由第個(gè)類(lèi)名生成,并且是類(lèi)別的數(shù)量。表示標(biāo)量積運(yùn)算,是溫度項(xiàng)()。由于文本是由放置在預(yù)定義的模板中的類(lèi)名組成,因此文本嵌入表示相應(yīng)的類(lèi)的語(yǔ)義信息。因此那些具有相同語(yǔ)義的點(diǎn)將被限制在相同的文本嵌入附近,而那些具有不同語(yǔ)義的點(diǎn)將被推開(kāi)。為此,語(yǔ)義一致性正則化會(huì)減少對(duì)比學(xué)習(xí)中的沖突。
語(yǔ)義引導(dǎo)的時(shí)空一致性正則化
除了語(yǔ)義一致性正則化之外,本文還考慮圖像像素特征如何幫助正則化3D網(wǎng)絡(luò)。自然替代直接引入點(diǎn)特征及其在嵌入空間中的對(duì)應(yīng)像素。然而,圖像像素的噪聲語(yǔ)義和不完美的像素點(diǎn)映射阻礙了下游任務(wù)的性能。為此,提出了一種新的語(yǔ)義引導(dǎo)的時(shí)空一致性正則化方法,通過(guò)對(duì)局部空間和時(shí)間內(nèi)的點(diǎn)施加軟約束來(lái)緩解這一問(wèn)題。
具體地,給定圖像和時(shí)間相干LiDAR點(diǎn)云,其中,是秒內(nèi)掃描的次數(shù)。值得注意的是圖像與像素點(diǎn)對(duì)的點(diǎn)云第一幀進(jìn)行匹配。本文通過(guò)校準(zhǔn)矩陣將點(diǎn)云的其余部分配準(zhǔn)到第一幀,并將它們映射到圖像上(圖3)。
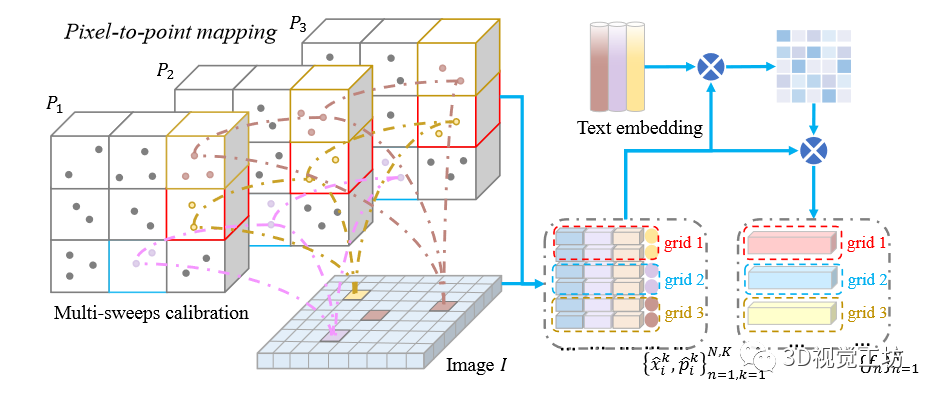
圖3 圖像像素到點(diǎn)映射(左)和語(yǔ)義引導(dǎo)的融合特征生成(右)示意圖。本文建立了在秒內(nèi)圖像和時(shí)間相干激光雷達(dá)點(diǎn)云之間的網(wǎng)格對(duì)應(yīng)關(guān)系,并且生成語(yǔ)義引到的融合特征。和用于執(zhí)行時(shí)空一致性正則化。
因此,我們?cè)诙虝r(shí)間內(nèi)獲得所有像素點(diǎn)文本對(duì)。接下來(lái),作者將整個(gè)縫合的點(diǎn)云劃分為規(guī)則網(wǎng)格,其中時(shí)間相干點(diǎn)位于同一網(wǎng)格中。本文通過(guò)以下目標(biāo)函數(shù)在各個(gè)網(wǎng)格內(nèi)施加時(shí)空一致性約束:
其中,代表像素-點(diǎn)對(duì)位于第個(gè)網(wǎng)格。是一種語(yǔ)義引導(dǎo)的跨模態(tài)融合特征,由以下公式表示:
其中和是注意力權(quán)重是由以下來(lái)計(jì)算的:
其中代表溫度項(xiàng)。實(shí)際上,局部網(wǎng)格內(nèi)的那些像素和點(diǎn)特征被限制在動(dòng)態(tài)中心附近。因此,這種軟約束減輕了噪聲預(yù)測(cè)和校準(zhǔn)誤差問(wèn)題。同時(shí),它對(duì)時(shí)間相干點(diǎn)特征進(jìn)行了時(shí)空正則化處理。
實(shí)驗(yàn)
數(shù)據(jù)集的選擇:兩個(gè)室外數(shù)據(jù)集 SemanticKITTI 和 nuScenes一個(gè)室內(nèi)數(shù)據(jù)集 ScanNet
無(wú)注釋語(yǔ)義分割

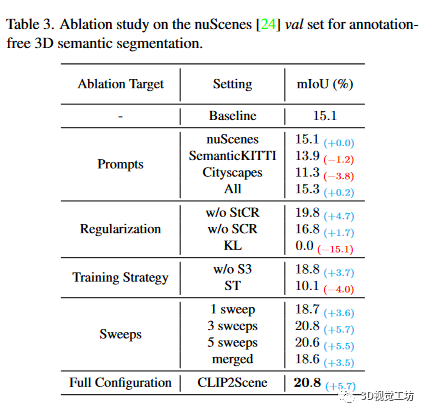
表2 是針對(duì)不同數(shù)據(jù)集的無(wú)注釋的3D語(yǔ)義分割的性能表3 是無(wú)注釋三維語(yǔ)義分割的nuScenes數(shù)據(jù)集消融研究。這里也推薦「3D視覺(jué)工坊」新課程《徹底搞懂視覺(jué)-慣性SLAM:VINS-Fusion原理精講與源碼剖析》
高效注釋的語(yǔ)義分割
如表1所示,當(dāng)對(duì)1%和100%nuScenes數(shù)據(jù)集進(jìn)行微調(diào)時(shí),該方法顯著優(yōu)于最先進(jìn)的方法,分別提高了8.1%和1.1%。與隨機(jī)初始化相比,改進(jìn)幅度分別為14.1%和2.4%,表明了本文的語(yǔ)義驅(qū)動(dòng)跨模態(tài)對(duì)比學(xué)習(xí)框架的有效性。定性結(jié)果如圖4所示。此外,本文還驗(yàn)證了該方法的跨域泛化能力。
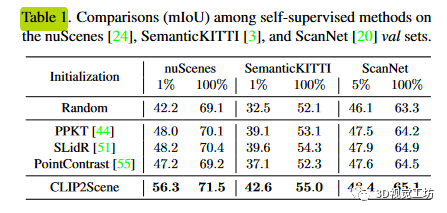
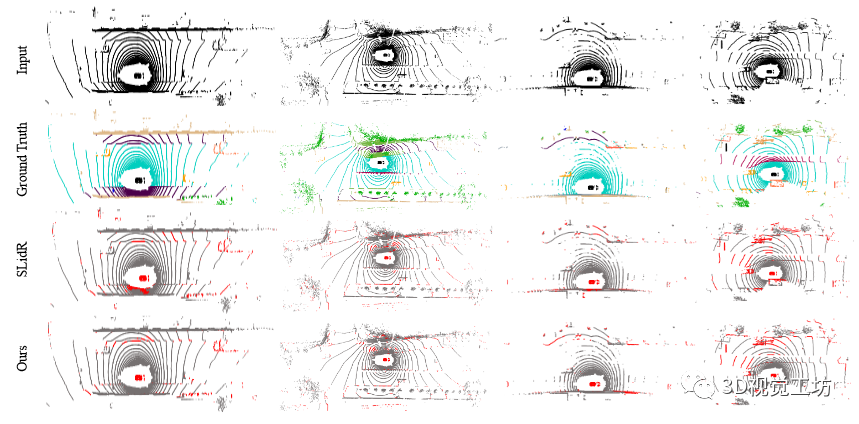
圖4 對(duì)1%nuScenes數(shù)據(jù)集進(jìn)行微調(diào)的定性結(jié)果。從第一行到最后一行分別是輸入激光雷達(dá)掃描、真值、SLidR預(yù)測(cè)和我們的預(yù)測(cè)。請(qǐng)注意,我們通過(guò)誤差圖顯示結(jié)果,其中紅點(diǎn)表示錯(cuò)誤的預(yù)測(cè)。顯然,本文的方法取得了不錯(cuò)的性能。
結(jié)論
在這項(xiàng)名為CLIP2Scene的工作中,作者探討了CLIP知識(shí)如何有助于3D場(chǎng)景理解。為了有效地將CLIP的圖像和文本特征轉(zhuǎn)移到3D網(wǎng)絡(luò)中,作者提出了一種新的語(yǔ)義驅(qū)動(dòng)的跨模態(tài)對(duì)比學(xué)習(xí)框架,包括語(yǔ)義正則化和時(shí)空正則化。作者的預(yù)訓(xùn)練3D網(wǎng)絡(luò)首次以良好的性能實(shí)現(xiàn)了無(wú)注釋的3D語(yǔ)義分割。此外,當(dāng)使用標(biāo)記數(shù)據(jù)進(jìn)行微調(diào)時(shí),我們的方法顯著優(yōu)于最先進(jìn)的自監(jiān)督方法。
-
3D
+關(guān)注
關(guān)注
9文章
2863瀏覽量
107324 -
模型
+關(guān)注
關(guān)注
1文章
3172瀏覽量
48711 -
Clip
+關(guān)注
關(guān)注
0文章
31瀏覽量
6649 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120976
原文標(biāo)題:結(jié)論
文章出處:【微信號(hào):3D視覺(jué)工坊,微信公眾號(hào):3D視覺(jué)工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
UV光固化技術(shù)在3D打印中的應(yīng)用
3D封裝熱設(shè)計(jì):挑戰(zhàn)與機(jī)遇并存

蘇州吳中區(qū)多色PCB板元器件3D視覺(jué)檢測(cè)技術(shù)

NVIDIA Instant NeRF將多組靜態(tài)圖像變?yōu)?b class='flag-5'>3D數(shù)字場(chǎng)景
通過(guò)2D/3D異質(zhì)結(jié)構(gòu)精確控制鐵電材料弛豫時(shí)間

有了2D NAND,為什么要升級(jí)到3D呢?

高分工作!Uni3D:3D基礎(chǔ)大模型,刷新多個(gè)SOTA!

介紹一種使用2D材料進(jìn)行3D集成的新方法
如何搞定自動(dòng)駕駛3D目標(biāo)檢測(cè)!

一種用于2D/3D圖像處理算法的指令集架構(gòu)以及對(duì)應(yīng)的算法部署方法
一文了解3D視覺(jué)和2D視覺(jué)的區(qū)別
2D圖像和LiDAR的3D點(diǎn)云之間的配準(zhǔn)方法

2D與3D視覺(jué)技術(shù)的比較
3D人體生成模型HumanGaussian實(shí)現(xiàn)原理
使用Python從2D圖像進(jìn)行3D重建過(guò)程詳解






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論