 預訓練擴散大模型取得點云-圖像配準SoTA!
預訓練擴散大模型取得點云-圖像配準SoTA!
介紹一下我們最新開源的工作:FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators. 給定部分重疊的圖像和點云,FreeReg能夠估計可靠的像素-三維點同名關系并解算圖像-點云相對位姿關系。值得注意的是,FreeReg不需要任何訓練/微調!
基于FreeReg估計的準確的同名關系,我們可以把圖像patch投影到點云的對應位置:


主頁:https://whu-usi3dv.github.io/FreeReg/
代碼:github.com/WHU-USI3DV/FreeReg
論文:https://arxiv.org/abs/2310.03420
太長不看(TL,DR):
區別于現有方法利用Metric Learning直接學習跨模態(圖像和點云)一直特征,FreeReg提出首先進行基于預訓練大模型的模態對齊,隨后進行同模態同名估計:
-
Diffusion大模型實現點云到圖像模態的統一并構建跨模態數據的粗粒度魯棒語義特征,
-
單目深度估計大模型實現圖像到點云模態的統一并刻畫跨模態數據的細粒度顯著幾何特征,
-
FreeReg通過融合兩種特征,無需任何針對圖像-點云配準任務的訓練,實現室內外圖像-點云配準SoTA表現。
任務概述:圖像-點云(Image-to-point cloud, I2P)配準

-
輸入:部分重疊的圖像和點云
-
輸出:圖像相機相對于點云的位置姿態
-
典型框架:
-
Step I (關鍵) : 構建圖像-點云跨模態一致特征
-
Step II: 基于特征一致性的 pixel(from 圖像)-point(from 點云) 同名估計
-
Step III: 基于所構建同名匹配的相對姿態估計 (PnP+RANSAC)
-
-
現有方法往往是:用一個2D特征提取網絡提取圖像特征;用一個3D特征提取網絡提取點云特征;然后根據pixel-to-point對應關系真值通過Metric Learning (Triplet/Batch hard/Circle loss/InfoCE...)的方式訓練網絡去提取跨模態一致的特征,這存在幾個問題:
-
圖像和點云存在故有的模態差異:圖像-紋理、點云-幾何,這給網絡可靠收斂帶來了困難,而影響特征的魯棒性(Wang et al, 2021);
-
需要長時間的訓練 (Pham,2020);
-
場景間泛化能力弱 (Li,2023)。
-
FreeReg:
-
通過預訓練大模型實現模態對齊,消除模態差異,顯著提升特征魯棒性;
-
不需要任何針對I2P配準任務的訓練/微調;
-
能夠處理室內外等多類型場景。
FreeReg pipeline:

Section I: FreeReg-D
在這一部分,我們首先利用Diffusion大模型將點云對齊到圖像模態,然后基于圖像模態下的特征進行同名估計。Naive Solution:利用現在圖像生成大殺器的ControlNet (Zhang et al, 2023; depth-to-image diffusion model)實現從點云(深度圖)中渲染出一個圖像,然后和query圖像做match不就行了?不行!如下圖,一個depth map可能對應各種各樣的RGB圖像,ControlNet基于點云渲染出來的圖像合理,但是和query input image差異忒大,match不起來。
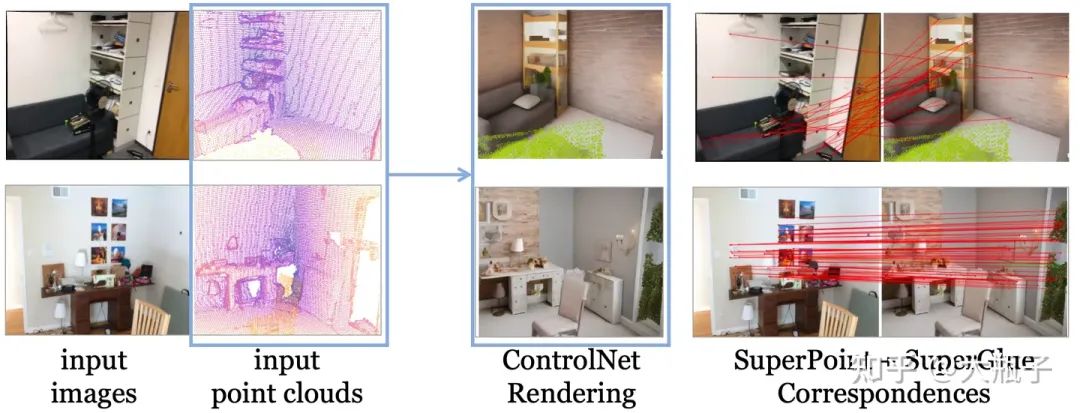
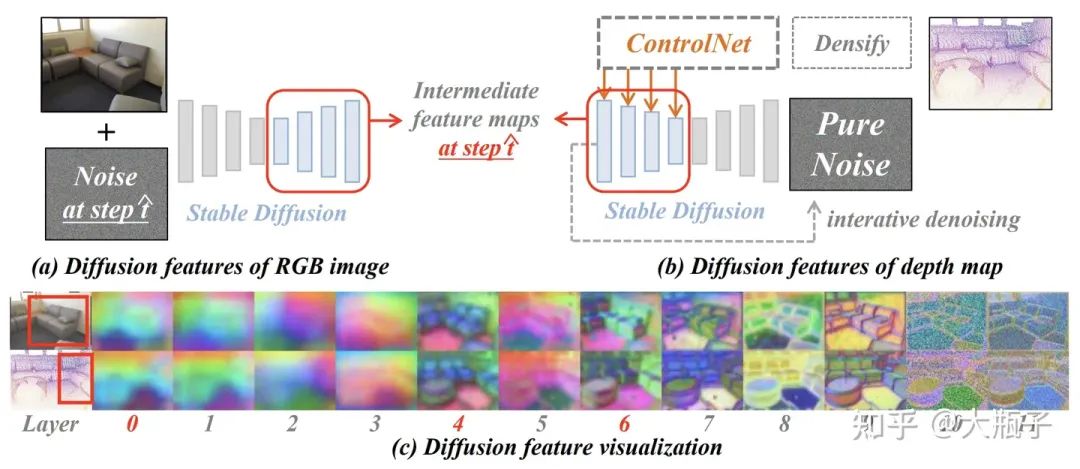
但是,我們注意到,ControlNet雖然生成的紋理和query差異很大,但是語義很正確而且和query RGB是對應的,那么我們怎么提取這種跨模態一致的語義特征呢?受到相關研究的啟發(Mingi et al, 2022)一種基于Diffusion大模型的多模特Diffusion Feature
-
RGB image diffusion feature:預訓練圖像生成大模型Stable Diffusion (SD,Dhariwal et al,2022)能夠通過迭代T步去噪的方式從純噪聲生成一張符合某種text-prompt(包含一些代表語義的名詞)的圖像,證明它能認識、區分和表征這些語義。而我們就把圖像加上一些噪聲讓SD去處理,然后看看哪些SD深層特征具有語義性。
-
Depth diffusion feature:我們用預訓練的ControlNet處理來自點云投影的深度圖,并基于其引導SD的圖像生成(迭代去噪)過程使生成的圖像符合深度圖,當去噪到某種程度時候我們把SD的中間層特征拿出來,看看哪些特征保證了生成圖像不僅符合深度圖而且語義性也是對的。
-
如上圖的c,我們發現,SD的0-6層輸出特征具有可靠的語義性和跨模態一致性!后面的特征才關注紋理。所以我們之用0-6層的特征(我們最終選擇concate0,4,6層的特征)作為我們的語義特征就好了,叫做Diffusion Feature!
Section II: FreeReg-G
在這一部分,我們利預訓練的單目深度估計網絡Zoe-Depth (Bhat et al, 2023)去恢復input RGB的深度,并將其恢復到3D點云分布,然后對RGB恢復的點云和input點云分別提取幾何特征(Geometric feature, Choy et al, 2019)用于match。此外,由于match得到的同名關系存在于點云空間,我們的變換估計可以采用Kabsch算法而非PnP方法,Kabsch利用Zoe-depth預測深度的約束可以僅使用3對同名關系就實現變換解算,更高效、更可靠,但是受到Zoe的影響不太精準(具體可以間我們的原文)。
Section III: FreeReg = FreeReg-D + FreeReg-G
在這一部分,我們融合前面在不同模態空間中提取的Diffusion Feature和Geometric Feature,作為我們最終的跨模特特征。如下圖所示:

-
Diffusion Feature具有很強的語義相關性和跨模特一致的可靠性,但是因為語義信息關聯自圖像的比較大的區域,這種大感受野使得基于特征相似性和雙向最近鄰篩選得到的pixel-to-point同名對準確但是稀疏。
-
Geometric Feature能夠關注幾何細節構建更加dense的pixel-to-point correspondences,但是很容易受到zoe-depth預測誤差和噪聲的影響,導致得到的pixel-to-point同名對存在大量的outliers。
-
通過Fuse兩種特征(L2 normalization + weighted concatenate, Zhang et al, 2023),FreeReg特征兼具語義可靠性和幾何顯著性,得到了更加可靠且dense的pixel-to-point correspondences!
實驗結果:
定性評價:得益于大模型模態對齊,FreeReg-D/G在沒有任何訓練和微調的情況下,就在室內外三個數據集上取得了SoTA表現,而FreeReg進一步提升算法表現,取得了平均20%的內點比例提升和48.6%的配準成功率提升!
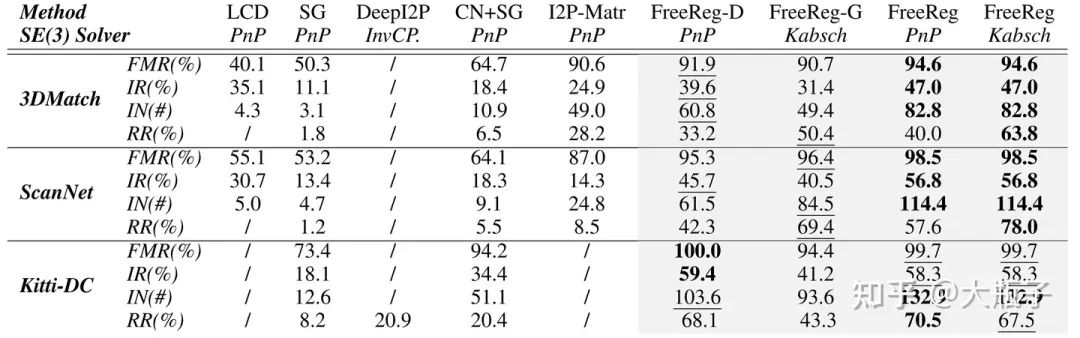
定量評價:

更多的結果:實現細節、消融實驗、精度評價、同模態配準表現(也是SoTA!)、和同期工作的比較(FreeReg更優)、尚存問題請見我們的論文!
-
圖像
+關注
關注
2文章
1075瀏覽量
40269 -
點云
+關注
關注
0文章
58瀏覽量
3763 -
大模型
+關注
關注
2文章
2135瀏覽量
1979
原文標題:武大&港大提出FreeReg:預訓練擴散大模型取得點云-圖像配準SoTA!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于擴散模型的圖像生成過程







 工商網監
工商網監
評論