") 幻覺降低30%!首個多模態(tài)大模型幻覺修正工作Woodpecker
幻覺降低30%!首個多模態(tài)大模型幻覺修正工作Woodpecker

圖中體現(xiàn)了兩種幻覺,紅色部分錯誤地描述了狗的顏色(屬性幻覺),藍色部分描述了圖中實際不存在的事物(目標幻覺)。幻覺對模型的可靠性產(chǎn)生了顯著的負面影響,因此引起了許多研究者的重視。
以往的方法主要集中在 MLLM 本身,通過在訓練數(shù)據(jù)以及架構上進行改進,以重新微調(diào)的方式訓練一個新的 MLLM。這種方式會造成較大的數(shù)據(jù)構建和訓練開銷,且較難推廣到各種已有的 MLLMs。
近日,來自中科大等機構的研究者們提出了一種免訓練的即插即用的通用架構“啄木鳥(Woodpecker)”,通過修正的方式解決 MLLM 輸出幻覺的問題。

論文鏈接:
https://arxiv.org/pdf/2310.16045.pdf
代碼鏈接:
https://github.com/BradyFU/Woodpecker
Woodpecker 可以修正各種場景下模型輸出的幻覺,并輸出檢測框作為引證,表明相應的目標確實存在。例如,面對描述任務,Woodpecker 可以修正其中帶有幻覺的部分。

對于 MLLM 難以檢測到的小對象,Woodpecker 也可以精準修正:

面對 MLLM 難以解決的復雜的計數(shù)場景,Woodpecker 同樣可以進行解決:

對于目標屬性類的幻覺問題,Woopecker 處理地也很好:

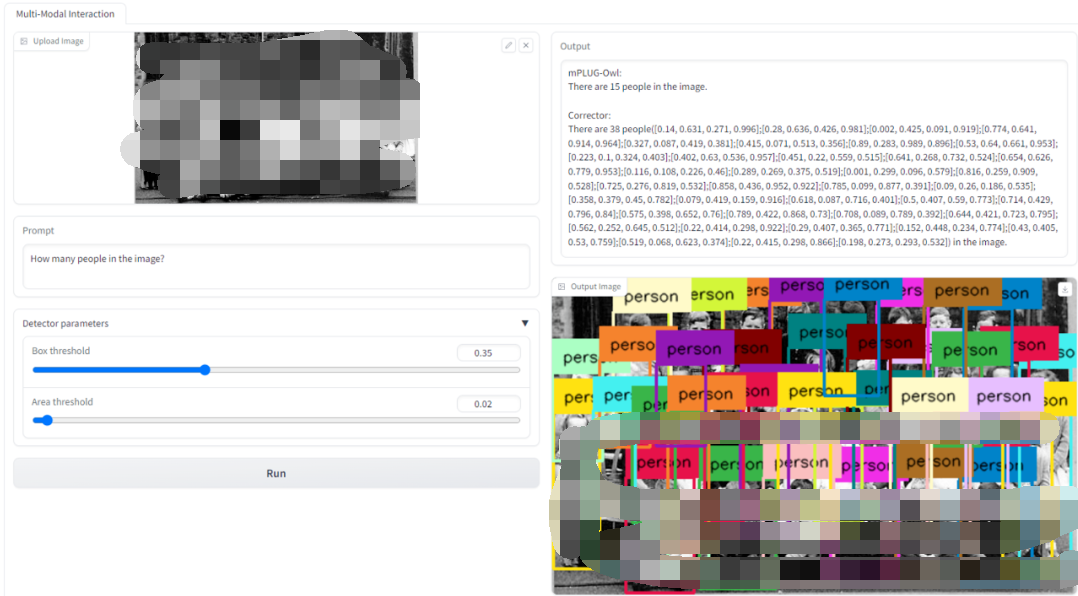
我們還提供了 Demo 供讀者測試使用,如下圖所示,上傳圖片并輸入請求,就可以得到修正前以及修正后的模型答復,以及供參考驗證的新圖片。

方法
Woodpecker 的架構如下,它包括五個主要步驟:關鍵概念提取、問題構造、視覺知識檢驗、視覺斷言生成以及幻覺修正。

關鍵概念提取:關鍵概念指的是 MLLM 的輸出中最可能存在幻覺的存在性目標,例如上圖描述中的“自行車;垃圾桶;人”。我們可以 Prompt 大語言模型來提取出這些關鍵概念,這些關鍵概念是后續(xù)步驟進行的基礎;
問題構造:圍繞著前一步提取出的關鍵概念,Prompt 大語言模型來提出一些有助于檢驗圖片描述真?zhèn)蔚膯栴},如“圖中有幾輛自行車?”、“垃圾桶邊上的是什么?”等等;
視覺知識檢驗:使用視覺基礎模型對提出的問題進行檢驗,獲得與圖片以及描述文本相關的信息。例如,我們可以利用 GroundingDINO 來進行目標檢測,確定關鍵目標是否存在以及關鍵目標的數(shù)量。這里我們認為像 GroundingDINO 這類視覺基礎模型對圖片的感知能力比 MLLM 本身的感知能力更強。對于目標顏色等這類屬性問題,我們可以利用 BLIP-2 來進行回答。BLIP-2這類傳統(tǒng) VQA 模型輸出答案的長度有限,幻覺問題也更少;
視覺斷言生成:基于前兩步中獲得的問題以及對應的視覺信息,合成結(jié)構化的“視覺斷言”。這些視覺斷言可以看做與原有 MLLM 的回答以及輸入圖片相關的視覺知識庫;
幻覺修正:基于前面得到的,使用大語言模型對 MLLM 的文本輸出進行逐一修正,并提供目標對應的檢測框信息作為視覺檢驗的參照。
 ?
?實驗效果
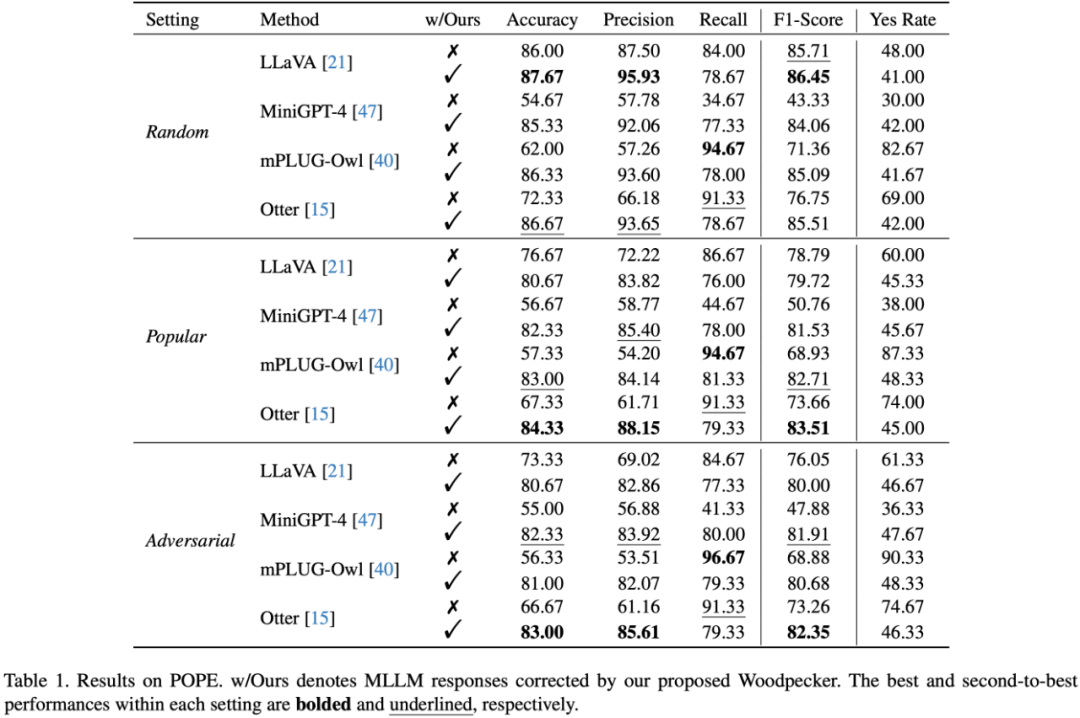
實驗選取了幾個典型的 MLLM 作為基線,包括:LLaVA,mPLUG-Owl,Otter,MiniGPT-4 論文中首先測試了 Woodpecker 在面對目標幻覺時的修正能力,在 POPE 驗證集的實驗結(jié)果如下表所示:
此外,研究者還應用更全面的驗證集 MME,進一步測試 Woodpecker 在面對屬性幻覺時的修正能力,結(jié)果如下表所示:
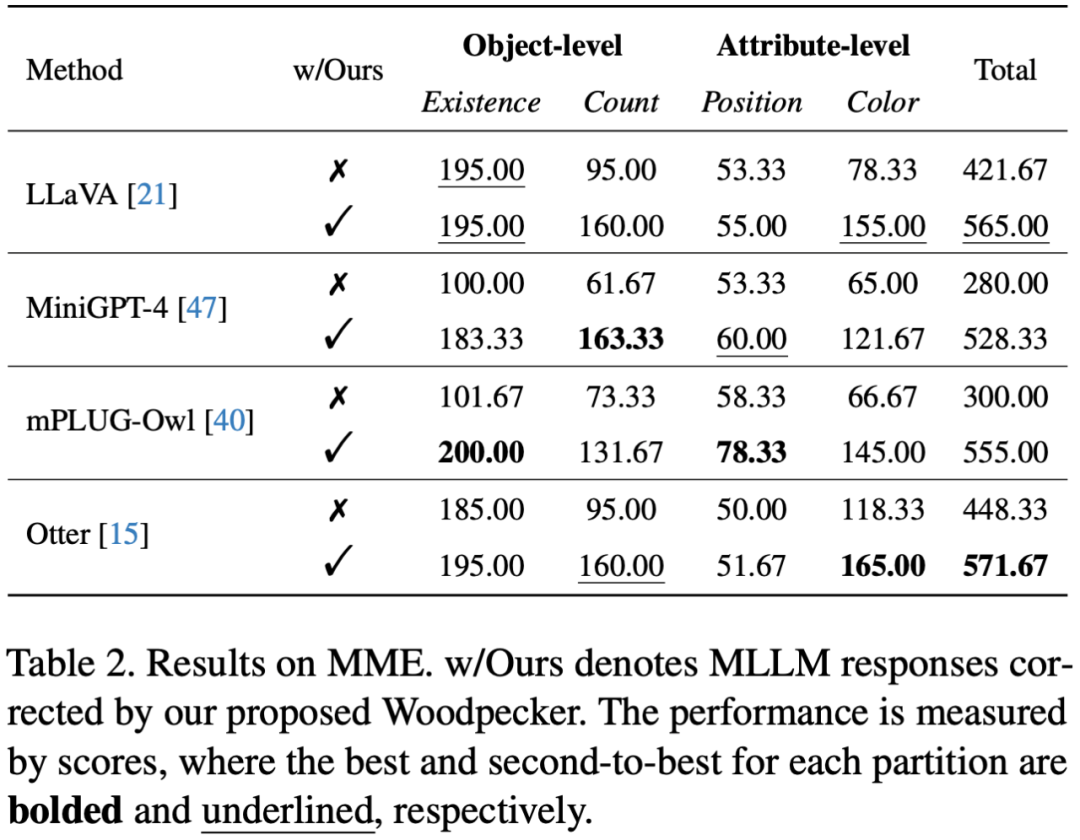
從表中可見 Woodpecker 不僅在應對目標幻覺時有效,在修正顏色等屬性幻覺時也具有出色的表現(xiàn)。LLaVA 的顏色得分從 78.33 分大幅提升到 155 分!經(jīng)過 Woodpecker 修正后,四個基線模型在四個測試子集上的總分均超過 500 分,在總體感知能力上獲得了顯著提升。
為了更直接地衡量修正表現(xiàn),更直接的方式是使用開放評測。不同于以往將圖片轉(zhuǎn)譯后送入純文本 GPT-4 的做法,文章利用 OpenAI 最近開放的視覺接口,提出使用 GPT-4 (Vision) 對修正前后的圖片描述直接對下列兩個維度進行打分:- 準確度:模型的答復相對于圖片內(nèi)容是否準確
-
詳細程度:模型答復的細節(jié)豐富度
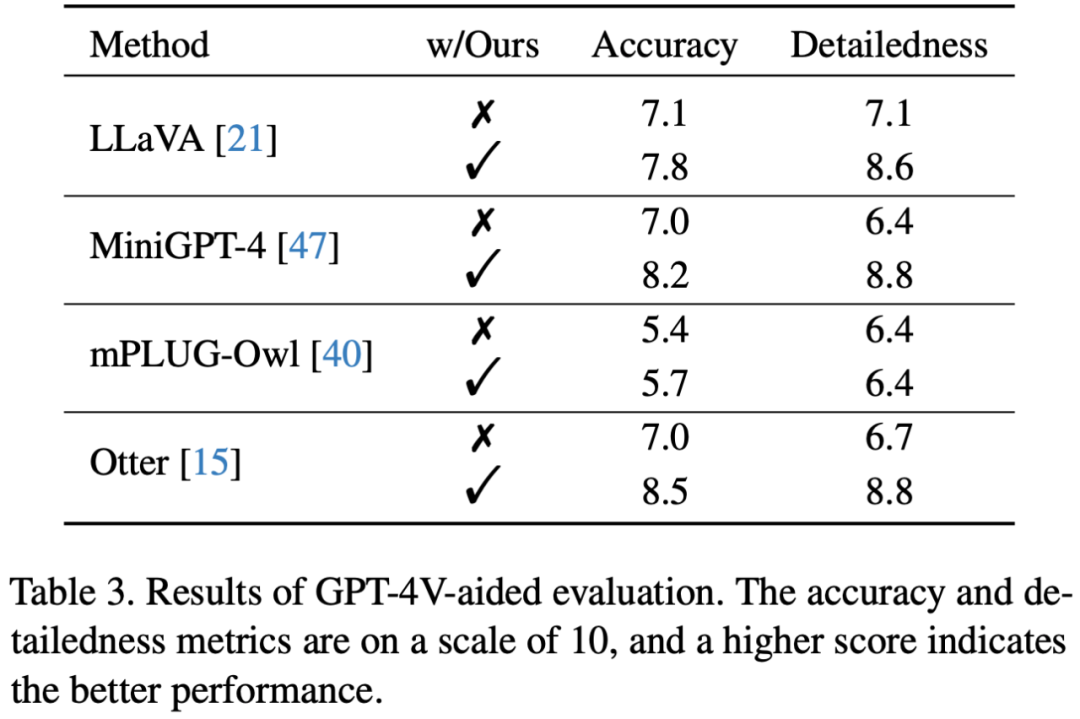
結(jié)果表明經(jīng)過 Woodpecker 修正后圖片描述的準確性有一定的提升,這說明該框架可以有效修正描述中幻視的部分。另一方面,Woodpecker 修正后引入的定位信息豐富了文本描述,提供了進一步的位置信息,從而提升了細節(jié)豐富度。GPT-4V 輔助的評測樣例如下圖所示:

·
原文標題:幻覺降低30%!首個多模態(tài)大模型幻覺修正工作Woodpecker
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術研究所】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
-
物聯(lián)網(wǎng)
+關注
關注
2903文章
44262瀏覽量
371213
原文標題:幻覺降低30%!首個多模態(tài)大模型幻覺修正工作Woodpecker
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術研究所】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
李彥宏:大模型行業(yè)消除幻覺,iRAG技術引領文生圖新紀元
利用OpenVINO部署Qwen2多模態(tài)模型
TaD+RAG-緩解大模型“幻覺”的組合新療法
阿里達摩院提出“知識鏈”框架,降低大模型幻覺
商湯科技與海通證券攜手發(fā)布金融行業(yè)首個多模態(tài)全棧式大模型
人大系初創(chuàng)公司智子引擎發(fā)布全新多模態(tài)大模型Awaker 1.0
商湯科技聯(lián)合海通證券發(fā)布業(yè)內(nèi)首個面向金融行業(yè)的多模態(tài)全棧式大模型

商湯科技發(fā)布5.0多模態(tài)大模型,綜合能力全面對標GPT-4 Turbo
微軟下架最新大語言模型WizardLM-2,緣因“幻覺測試疏忽”
利用知識圖譜與Llama-Index技術構建大模型驅(qū)動的RAG系統(tǒng)(下)

機器人基于開源的多模態(tài)語言視覺大模型

什么是多模態(tài)?多模態(tài)的難題是什么?

從Google多模態(tài)大模型看后續(xù)大模型應該具備哪些能力
大模型+多模態(tài)的3種實現(xiàn)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論