 什么是強化學習
什么是強化學習
強化學習是機器學習的方式之一,它與監督學習、無監督學習并列,是三種機器學習訓練方法之一。

在圍棋上擊敗世界第一李世石的 AlphaGo、在《星際爭霸2》中以 10:1 擊敗了人類頂級職業玩家的AlphaStar,他們都是強化學習模型。諸如此類的模型還有 AlphaGo Zero 等。
強化學習的原理非常簡單,它非常像心理學中新行為主義派的斯金納發現的操作性條件反射。
操作性條件反射是什么?當年斯金納做了一個箱子,進行了兩次實驗。
第一次實驗,箱子里放了一只饑餓的老鼠,在箱子的一邊有一個可供按壓的杠桿,在杠桿旁邊有一個放置食物的小盒子。動物在箱內按下杠桿,食盒就會釋放食物進入箱內,動物可以取食。結果:小鼠自發學會了按按鈕。這是積極強化。
另一次實驗是,每次小白鼠不按下按鈕,則給箱子通電,小白鼠因此學會了按按鈕以防自己遭受電擊。這是消極強化(負向強化)。
這就是斯金納發現的操作性條件反射,當行為得到獎勵或懲罰時出現刺激,反過來控制這種行為。
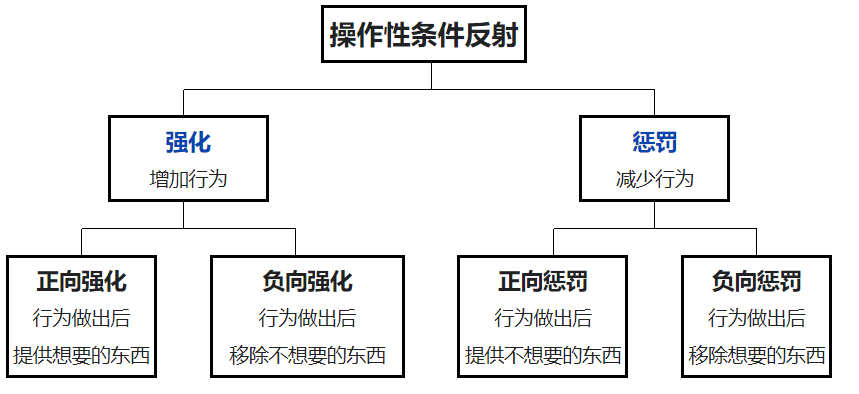
強化學習與操作性條件反射有異曲同工之妙,以人類玩游戲為例,如果在游戲中采取某種策略購買某種類型的裝備可以取得較高的得分,那么就會進一步“強化”這種策略,以期繼續取得較好的結果。
網上有不少強化學習的例子,鑒于讀者中對股票感興趣的同學比較多,我們以股票預測為例,實驗一下 wangshub 的 RL-Stock 項目。
下面就試一下這個強化學習項目,前往GitHub下載 RL-Stock:
https://github.com/wangshub/RL-Stock/
如果你無法使用GitHub,也可以在Python實用寶典公眾號后臺回復:股票強化學習1 下載全文完整代碼,這份代碼包括第三部分的多進程優化邏輯。
1.準備
開始之前,你要確保Python和pip已經成功安裝在電腦上,如果沒有,可以訪問這篇文章:超詳細Python安裝指南 進行安裝。
**(可選1) **如果你用Python的目的是數據分析,可以直接安裝Anaconda:Python數據分析與挖掘好幫手—Anaconda,它內置了Python和pip.
**(可選2) **此外,推薦大家用VSCode編輯器,它有許多的優點:Python 編程的最好搭檔—VSCode 詳細指南。
請注意,由于TensorFlow版本限制,這個強化學習項目只支持 Python3 以上,Python3.6 及以下的版本,因此我建議使用Anaconda創建一個新的虛擬環境運行這個項目:
conda create -n rlstock python=3.6
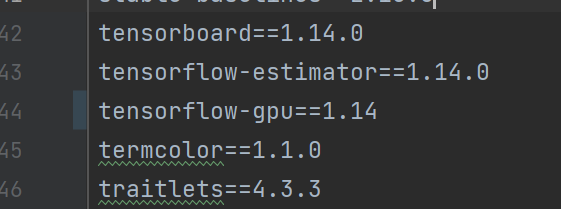
另外,實測依賴需要改動 requirements.txt 的tensorflow-gpu版本至1.14:
Windows環境下打開Cmd(開始—運行—CMD),蘋果系統環境下請打開Terminal(command+空格輸入Terminal),進入 RL-Stock 項目文件夾輸入命令安裝依賴:
pip install -r requirements.txt
2.小試強化學習
運行RL-Stock項目前,需要下載數據。進入剛創建的虛擬環境,運行get_stock_data.py代碼會自動下載數據到 stockdata 目錄中:
python get_stock_data.py
如果你使用的是在Github上下載的代碼而不是Python實用寶典后臺改好的代碼,請注意 get_stock_data.py 的第46行,必須對 row["code_name"] 去除 * 號,否則Windows系統下可能會存在問題:
df_code.to_csv(f'{self.output_dir}/{row["code"]}.{row["code_name"].strip("*")}.csv', index=False)
數據下載完成后就可以運行 main.py 執行強化學習訓練和測試,不過在訓練之前,我們先簡單了解下整個項目的輸入狀態、動作、和獎勵函數。
輸入狀態(觀測 Observation)
策略網絡觀測的就是一只股票的各類數據,比如開盤價、收盤價、成交量等,它可以由許多因子組成。為了訓練時網絡收斂,觀測狀態數據輸入時必須要進行歸一化,變換到 ** [-1, 1] ** 的區間內。RL-Stock輸入的觀測數據字段如下:
共有 買入 、賣出和**持有 **3 種動作,定義動作( ** action ** )為長度為 2 的數組
- **
action[0]**為操作類型; action[1]表示買入或賣出百分比;
動作類型action[0] | 說明 |
|---|---|
| 1 | 買入action[1] |
| 2 | 賣出action[1] |
| 3 | 持有 |
注意,當動作類型 action[0] = 3 時,表示不買也不拋售股票,此時 action[1] 的值無實際意義,網絡在訓練過程中,Agent 會慢慢學習到這一信息。Agent,實稱代理,在我們的上下文中,你可以視其為策略。
獎勵 Reward
獎勵函數的設計,對強化學習的目標至關重要。在股票交易的環境下,最應該關心的就是當前的盈利情況,故用當前的利潤作為獎勵函數。
# profits
reward = self.net_worth - INITIAL_ACCOUNT_BALANCE
reward = 1 if reward > 0 else -100
為了使網絡更快學習到盈利的策略,當利潤為負值時,給予網絡一個較大的懲罰 (-100)。
梯度策略
作者采用了基于策略梯度的PPO 算法,OpenAI 和許多文獻已把 PPO 作為強化學習研究中首選的算法。PPO 優化算法 Python 實現參考 stable-baselines。
數據集及自定義
在數據集上,作者使用了1990年至2019年11月作為訓練集,2019年12月作為測試集。
1990-01-01~2019-11-29 | 2019-12-01~2019-12-31 |
|---|---|
| 訓練集 | 測試集 |
如果你要調整這個訓練集和測試集的時間,可以更改 get_stock_data.py 的以下部分:
if __name__ == '__main__':
# 獲取全部股票的日K線數據
# 訓練集
mkdir('./stockdata/train')
downloader = Downloader('./stockdata/train', date_start='1990-01-01', date_end='2019-11-29')
downloader.run()
# 測試集
mkdir('./stockdata/test')
downloader = Downloader('./stockdata/test', date_start='2019-12-01', date_end='2019-12-31')
downloader.run()
訓練并測試
首先,我們嘗試一下單一代碼的訓練和測試,修改main.py里的股票代碼,比如我這里修改為601919中遠海控:
if __name__ == '__main__':
# multi_stock_trade()
test_a_stock_trade('sh.601919')
# ret = find_file('./stockdata/train', '601919')
# print(ret)
運行下面的命令,執行此深度學習模型的訓練和測試。
python main.py
訓練完成后,會自動進行模擬操作測試集這20個交易日,然后會輸出這20個交易日的測試結果:
------------------------------
Step: 20
Balance: 0.713083354256014
Shares held: 2060 (Total sold: 2392)
Avg cost for held shares: 5.072161917927474 (Total sales value: 12195.091008936648)
Net worth: 10930.56492977963 (Max net worth: 10930.56492977963)
Profit: 930.5649297796299
------------------------------
Step: 21
Balance: 0.713083354256014
Shares held: 2060 (Total sold: 2392)
Avg cost for held shares: 5.072161917927474 (Total sales value: 12195.091008936648)
Net worth: 10815.713083354256 (Max net worth: 10930.56492977963)
Profit: 815.713083354256
利潤圖如下:
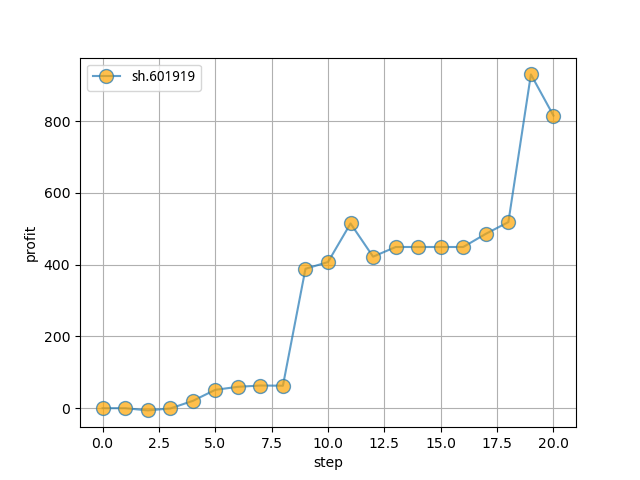
然后我們看一下中遠海控2019年12月的走勢:
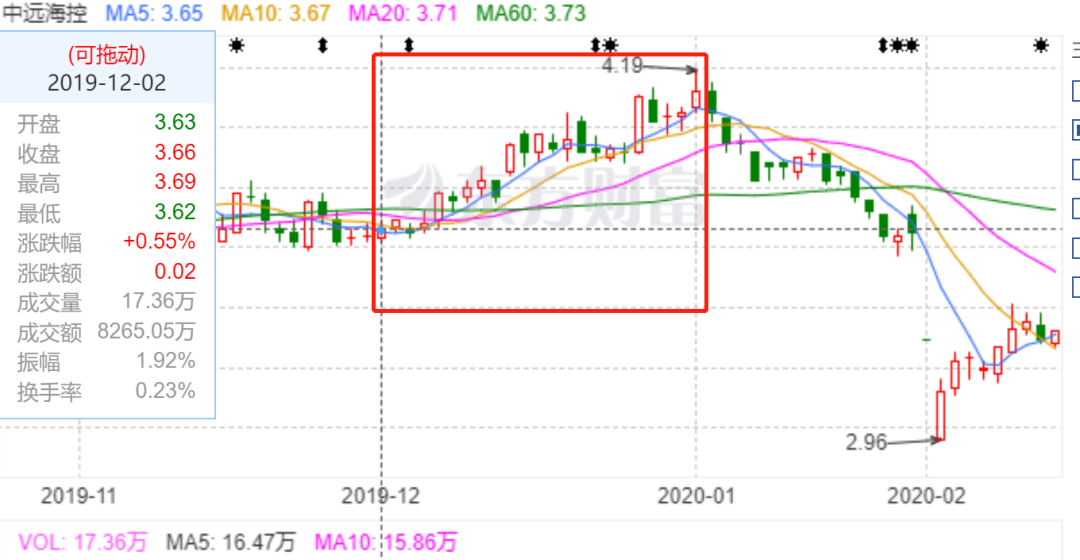
可以看到這個月的中遠海控是一個上升趨勢,一共上漲了12%,而這個模型捕捉到其中8%左右的利潤,還是相當不錯的。
當然,凡事不能只看個體,下面我們修改下作者的源代碼,試一下其在市場里的整體表現。
3.強化學習模型整體表現
由于作者原有的模型是單進程的計算,為了測試全市場的表現,我進行了多進程改造。
我將作者的訓練及測試任務集成到一個函數中,并使用celery做并行:
@app.task
def multi_stock_trade(code):
stock_file = find_file('./stockdata/train', str(code))
if stock_file:
try:
profits = stock_trade(stock_file)
with open(f'result/code-{code}.pkl', 'wb') as f:
pickle.dump(profits, f)
except Exception as err:
print(err)
將訓練集的時間范圍設置為1990年到2021年,測試集的測試周期改為最近一個月:
1990-01-01~2021-11-25 | 2021-11-26~2021-12-25 |
|---|---|
| 訓練集 | 測試集 |
開啟redis-server 及 Celery Worker:
# redis-server 獨占一個進程,所以需要另開一個窗口
celery -A tasks worker -l info
遍歷所有的股票代碼做并發測試:
files = os.listdir("stockdata/train")
files_test = os.listdir("stockdata/test")
all_files_list = list(set(files) & set(files_test))
for i in all_files_list:
# 使用celery做并發
code = ".".join(i.split(".")[:2])
# multi_stock_trade.apply_async(args=(code,))
multi_stock_trade(code)
再對生成的結果進行統計,測試結果如下:
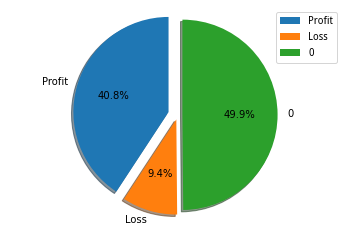
對這個模型在2021-11-26到2021-12-25的測試結果表明,有40.8%的股票進行了交易并且獲利,有49.9%的股票沒有進行操作,有9.4%的股票進行了交易并虧損。平均每次交易利潤為445元,作為一個測試策略,這個結果已經很不錯了。
由于只是一個測試策略,這里就不做詳細的風險分析了,實際上我們還需要觀察這個策略的最大回撤率、夏普率等指標才能更好地評判此策略的好壞。
我認為這個項目還有很大的改造空間,原邏輯中只觀察了OHLC等基本數據,我們還可以增加很多指標,比如基于Ta-lib,算出MACD、RSI等技術指標,再將其加入Observation中,讓模型觀察學習這些數據的特征,可能會有不錯的表現。
-
模型
+關注
關注
1文章
3171瀏覽量
48711 -
代碼
+關注
關注
30文章
4745瀏覽量
68347 -
機器學習
+關注
關注
66文章
8377瀏覽量
132406 -
強化學習
+關注
關注
4文章
266瀏覽量
11213
發布評論請先 登錄
相關推薦
什么是深度強化學習?深度強化學習算法應用分析

深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
薩頓科普了強化學習、深度強化學習,并談到了這項技術的潛力和發展方向
如何深度強化學習 人工智能和深度學習的進階
什么是強化學習?純強化學習有意義嗎?強化學習有什么的致命缺陷?







 工商網監
工商網監
評論