 什么是pyquery?如何使用pyquery
什么是pyquery?如何使用pyquery
什么是pyquery
pyquery是類似于jquery的網頁解析工具,讓你使用jquery的風格來遍歷xml文檔,它使用lxml操作html的xml文檔,它的語法與jquery很像,和我們之前所講的解析庫xpath與Beautiful Soup比起來更加靈活與簡便,并且增加了添加類和移除節點的操作,這些操作有時會為提取信息時帶來極大的便利。
使用pyquery
如果你對web有所了解,并且比較喜歡使用CSS選擇器,那么這里有一款更適合你的解析庫——jquery。
準備工作
在使用之前,請確保已經安裝好qyquery庫。安裝教程如下所示:
pip install pyquery
初始化
和Beautiul Soup一樣,在初始化pyquery的時候,也需要傳入html文本來初始化一個pyquery對象。
初始化的時候一般有三種傳入方式:傳入字符串、傳入URL、傳入html文件。
- 字符串初始化
html = '''
< div >
< ul >
< li class="item-0" >first-item< /li >
< li class="item-1" >< a href="link2.html" >second item< /a >< /li >
< li class="item=-0 active" >< a href="link3.html" >< span class=""bold >third item< /span >< /a >< /li >
< li class="item-1 active" >< a href="link4.html" >fourth item< /a >< /li >
< li class="item-0" >< a href="link5.html" >fifth item< /a >< /li >
< /ul >
< /div >
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc)
print(type(doc))
print(doc('li'))
先對上面的代碼做簡單的描述:
首先引入PyQuery對象,取名為pq。然后聲明一個長HTML字符串,并將其當作參數傳給PyQuery類,這樣就成功的進行了初始化。
接下來將css選擇器作為參數傳入初始化對象,在這個示例中我們傳入li節點,這樣就可以選擇所有的li節點.。
- URL初始化
初始化對象的參數不僅可以是字符串,還可以是網頁的URL,這時可以將URL作為參數傳入初始化對象。
具體代碼如下所示:
from pyquery import PyQuery as pq
doc = pq('https://www.baidu.com', encoding='utf-8')
print(doc)
print(type(doc))
print(doc('title'))
試著運行上面的代碼你會發現,我們成功的獲取到了百度的title節點和網頁信息。
PyQuery對象會先請求這個URL,然后用得到的HTML內容完成初始化,這其實就相當于網頁源代碼以字符串的形式傳遞給初始化對象。
因此,還可以這樣寫代碼:
from pyquery import PyQuery as pq
import requests
url = 'https://www.baidu.com'
doc = pq(requests.get(url).content.decode('utf-8'))
print(doc)
print(type(doc))
print(doc('title'))
運行結果與上面那段代碼的運行結果是一致的。
- 文件初始化
除了傳遞URL以外還可以傳遞本地的文件名,此時只要傳遞本地文件名,此時將參數指定為filename即可。
具體代碼如下所示:
from pyquery import PyQuery as pq
doc = pq(filename='baidu.html')
print(doc)
print(type(doc))
print(doc('title'))
以上三種初始化的方式都是可以的,當然最常用的初始化方式還是以字符串的形式傳遞。
基本CSS選擇器
html = '''
< div id="container" >
< ul class="list" >
< li class="item-0" >first-item< /li >
< li class="item-1" >< a href="link2.html" >second item< /a >< /li >
< li class="item=-0 active" >< a href="link3.html" >< span class=""bold >third item< /span >< /a >< /li >
< li class="item-1 active" >< a href="link4.html" >fourth item< /a >< /li >
< li class="item-0" >< a href="link5.html" >fifth item< /a >< /li >
< /ul >
< /div >
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('#container .list li'))
print(type(doc('#container .list li')))
初始化PyQuery對象之后,傳入CSS選擇器#container .list li將所有符合條件的節點輸出,并且運行上面的代碼之后你會發現它的類型依然還是PyQuery類型。
查找節點
下面介紹一些常用的查詢函數,這些函數與jQuery函數的用法是完全相同的。
- 子節點
查找子節點時需要用到find()方法,并傳入的參數是CSS選擇器,以前面的html為例子。
from pyquery import PyQuery as pq
doc = pq(html)
print(doc.find('li'))
print(type(doc.find('li')))
調用find()方法,將節點名稱li傳入該方法,獲取所有符合條件的內容。類型依然還是PyQuery。
當然我們還可以這樣寫:
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
print(type(items))
lis = items.find('li')
print(type(lis))
print(lis)
首先先選取class為list的節點,然后調用find()方法,傳入CSS選擇器,選取內部的``li`節點,最后打印輸出。
其實find()方法是查找所有的子孫節點,要獲取所有的子節點可以調用chirdren()方法。具體代碼如下所示:
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
lis = items.children()
print(lis)
print(type(lis))
如果想要篩選子節點中符合條件的節點,可以向chirdren()方法傳入CSS選擇器。具體代碼如下所示:
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
lis = items.children('.active')
print(lis)
print(type(lis))
試著運行上面的代碼你會發現,這里已經成功獲取到了class為active的節點。
- 父節點
我們可以調用parent()方法來獲取某個節點的父節點。
html = '''
< div id="container" >
< ul class="list" >
< li class="item-0" >first-item< /li >
< li class="item-1" >< a href="link2.html" >second item< /a >< /li >
< li class="item=-0 active" >< a href="link3.html" >< span class=""bold >third item< /span >< /a >< /li >
< li class="item-1 active" >< a href="link4.html" >fourth item< /a >< /li >
< li class="item-0" >< a href="link5.html" >fifth item< /a >< /li >
< /ul >
< /div >
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()
print(container)
print(type(container))
先對上面的代碼做簡要的說明:
首先選取class為list的節點,然后再調用parent()方法得到其父節點,其類型依然還是PyQuery類型。
這里的父節點是直接父節點,但是如果要獲取祖父節點,可以調用parents()方法。
html = '''
< div class="wrap" >
< div id="container" >
< ul class="list" >
< li class="item-0" >first-item< /li >
< li class="item-1" >< a href="link2.html" >second item< /a >< /li >
< li class="item=-0 active" >< a href="link3.html" >< span class=""bold >third item< /span >< /a >< /li >
< li class="item-1 active" >< a href="link4.html" >fourth item< /a >< /li >
< li class="item-0" >< a href="link5.html" >fifth item< /a >< /li >
< /ul >
< /div >
< /div >
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parents()
print(container)
print(type(container))
運行上面的代應為碼之后,你會發現這里輸出的內容有四個,因為class為list節點的祖父節點有四個,分別是:container、wrap、body、html。在初始化對象的時候已經添加上了body和html節點。
- 兄弟節點
除了可以獲取到父節點和子節點之外,還可以獲取到兄弟節點。如果需要獲取兄弟節點,可以調用siblings()方法。
具體代碼如下所示:
html = '''
< div class="wrap" >
< div id="container" >
< ul class="list" >
< li class="item-0" >first-item< /li >
< li class="item-1" >< a href="link2.html" >second item< /a >< /li >
< li class="item-0 active" >< a href="link3.html" >< span class=""bold >third item< /span >< /a >< /li >
< li class="item-1 active" >< a href="link4.html" >fourth item< /a >< /li >
< li class="item-0" >< a href="link5.html" >fifth item< /a >< /li >
< /ul >
< /div >
< /div >
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list .item-0.active')
print(items.siblings())
這里首先選取類為.item-0.active的節點,再調用siblings()方法獲取到該節點的兄弟節點。
試著運行上面的代碼,你會發現獲取到其他四個兄弟節點。
遍歷
通過上面的代碼可以觀察到,pyquery的選擇結果可能是多個節點,也可能是單個節點,類型都是PyQuery類型,并沒有向Beautiful Soup那樣的列表。
對于單個節點來說,可以直接打印輸出,也可以直接轉成字符串。
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list .item-0.active')
print(items)
print(str(items))
print(type(items))
對于多個節點,可以通過調用item()方法,將獲取的內容轉換成生成器類型,在通過遍歷的方式輸出。
具體代碼如下所示:
from pyquery import PyQuery as pq
doc = pq(html)
lis = doc('li').items()
print(lis)
for li in lis:
print(li, type(li))
運行上面的代碼,你會發現輸出變量lis的結果是生成器,因此可以遍歷輸出。
獲取信息
一般來說,在網頁里面我們需要獲取的信息有兩類:一類是文本內容,另一類是節點屬性值。
- 獲取屬性
獲取到某個PyQuery類型的節點之后,就可以通過attr()方法來獲取屬性。
具體代碼如下所示:
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.list .item-0.active a')
print(a.attr('href'))
先獲取class為list下面的class為item-0 active的節點下的a節點,這時變量a是PyQuery類型,再調用attr()方法并傳入屬性值href。
當然也可以通過調用attr屬性來獲取屬性。
print(a.attr.href)
你會發現輸出結果與上面的代碼是一樣的。
當然,我們也可以獲取到所有a節點的屬性,具體代碼如下所示:
html = '''
< div class="wrap" >
< div id="container" >
< ul class="list" >
< li class="item-0" >first-item< /li >
< li class="item-1" >< a href="link2.html" >second item< /a >< /li >
< li class="item-0 active" >< a href="link3.html" >< span class=""bold >third item< /span >< /a >< /li >
< li class="item-1 active" >< a href="link4.html" >fourth item< /a >< /li >
< li class="item-0" >< a href="link5.html" >fifth item< /a >< /li >
< /ul >
< /div >
< /div >
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('a').items()
for item in a:
print(item.attr('href'))
但是如果代碼這樣寫:
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('a')
print(a.attr('href'))
運行上面的代碼之后,你會發現只獲取到第一個a節點的href屬性。
所有這個是需要注意的地方!!
- 提取文本
提取文本與提取屬性的邏輯是一樣的,首先獲取到class為PyQuery的節點,再調用text()方法獲取文本。
首先來獲取一個節點的文本內容。具體代碼如下所示:
html = '''
< div class="wrap" >
< div id="container" >
< ul class="list" >
< li class="item-0" >first-item< /li >
< li class="item-1" >< a href="link2.html" >second item< /a >< /li >
< li class="item-0 active" >< a href="link3.html" >< span class=""bold >third item< /span >< /a >< /li >
< li class="item-1 active" >< a href="link4.html" >fourth item< /a >< /li >
< li class="item-0" >< a href="link5.html" >fifth item< /a >< /li >
< /ul >
< /div >
< /div >
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.list .item-0.active a')
print(a.text())
試著運行上面的代碼你會發現成功獲取a節點的文本內容。
接下來我們就來獲取多個li節點的文本內容。
具體代碼如下所示:
html = '''
< div class="wrap" >
< div id="container" >
< ul class="list" >
< li class="item-0" >first-item< /li >
< li class="item-1" >< a href="link2.html" >second item< /a >< /li >
< li class="item-0 active" >< a href="link3.html" >< span class=""bold >third item< /span >< /a >< /li >
< li class="item-1 active" >< a href="link4.html" >fourth item< /a >< /li >
< li class="item-0" >< a href="link5.html" >fifth item< /a >< /li >
< /ul >
< /div >
< /div >
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('li')
print(items.text())
運行上面的代碼,你會發現該代碼成功獲取到了所有節點名稱為li的文本內容,中間用空格隔開。
如果你想要一個一個獲取,那還是少不了生成器,具體代碼如下所示:
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('li').items()
for item in items:
print(item.text())
節點操作
pyquery提供了一系列方法對節點進行動態修改,比如為某個節點添加一個class,移除某個節點,這些操作有時會為提取信息帶來便利。
- add_class和remove_class
html = '''
class="wrap">
"container">
< ul class="list" >
< li class="item-0" >first-item< /li >
< li class="item-1" >< a href="link2.html" >second item< /a >< /li >
< li class="item-0 active" >< a href="link3.html" >class=""bold >third item< /a >< /li >
< li class="item-1 active" >< a href="link4.html" >fourth item< /a >< /li >
< li class="item-0" >< a href="link5.html" >fifth item< /a >< /li >
< /ul >
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li)
li.remove_class('active')
print(li)
li.add_class('active')
print(li)
運行結果如下所示:
< li class="item-0 active" >< a href="link3.html" >< span class="" bold="" >third item< /span >< /a >< /li >
< li class="item-0" >< a href="link3.html" >< span class="" bold="" >third item< /span >< /a >< /li >
< li class="item-0 active" >< a href="link3.html" >< span class="" bold="" >third item< /span >< /a >< /li >
上面有三段輸出內容,首先先獲取一個li節點,然后再刪除active類屬性,第三段代碼是添加active類屬性。
偽類選擇器
CSS選擇器之所以強大,還有一個很重要的原因,那就是它可以支持多種多樣的偽類選擇器,例如選擇第一個節點、最后一個節點、奇偶數節點、包含某一文本的節點。
html = '''
class="wrap">
"container">
< ul class="list" >
< li class="item-0" >first-item< /li >
< li class="item-1" >< a href="link2.html" >second item< /a >< /li >
< li class="item-0 active" >< a href="link3.html" >class=""bold >third item< /a >< /li >
< li class="item-1 active" >< a href="link4.html" >fourth item< /a >< /li >
< li class="item-0" >< a href="link5.html" >fifth item< /a >< /li >
< /ul >
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('li:first-child') # 第一個li節點
print(li)
li = doc('li:last-child') # 最后一個li節點
print(li)
li = doc('li:nth-child(2)') # 第二個位置的li節點
print(li)
li = doc('li:gt(2)') # 第三個之后的li節點
print(li)
li = doc('li:nth-child(2n)') # 偶數位置的li節點
print(li)
li = doc('li:contains(second)') # 包含second文本的li節點
print(li)
至此,關于pyquery的所有內容都講完了,接下來就進入實戰了,光說不練肯定是不行的,只有通過實戰才能正真學會剛剛所學會的知識。
實戰
本次我帶來的實戰內容是爬取貓眼電影的TOP100的排行榜及評分情況。
準備
工欲善其事,必先利其器 。首先,我們要準備幾個庫:pyquery、requests。
安裝過程如下:
pip install pyquery
pip install requests
前言
寒假又到來了,小伙伴們準備怎么過呢?
在大冬天里,躲在被窩刷劇是最舒服的,好懷念當年的生活啊~
所以今天就來爬取貓眼電影的TOP100排行榜,為冬眠做好準備。
網站鏈接:
https://maoyan.com/board/4
需求分析與功能實現
獲取電影名稱
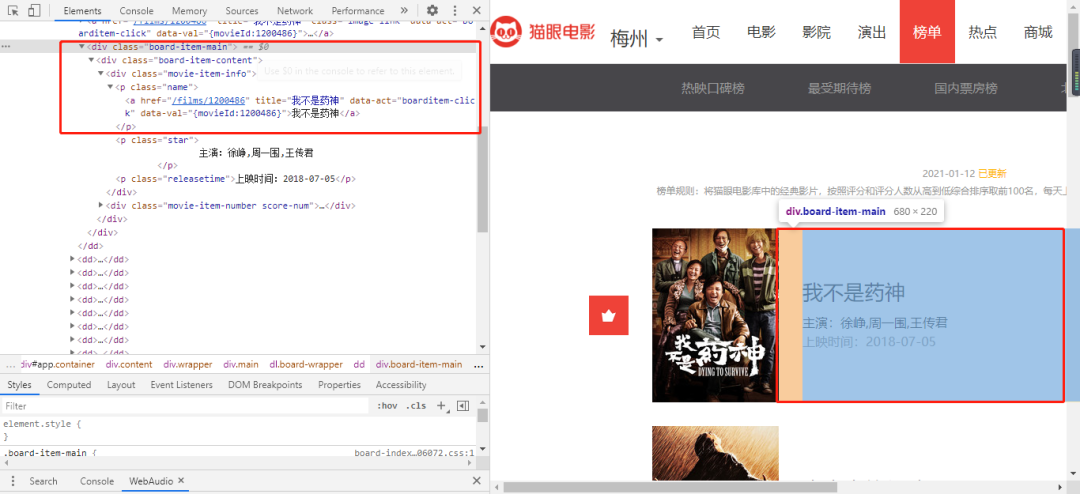
從上圖可以看到我們需要的信息藏在class為board-item-main的div標簽下的a標簽內,因此我們需要獲取其文本信息。
核心代碼如下所示:
movie_name = doc('.board-item-main .board-item-content .movie-item-info p a').text()
獲取主演信息
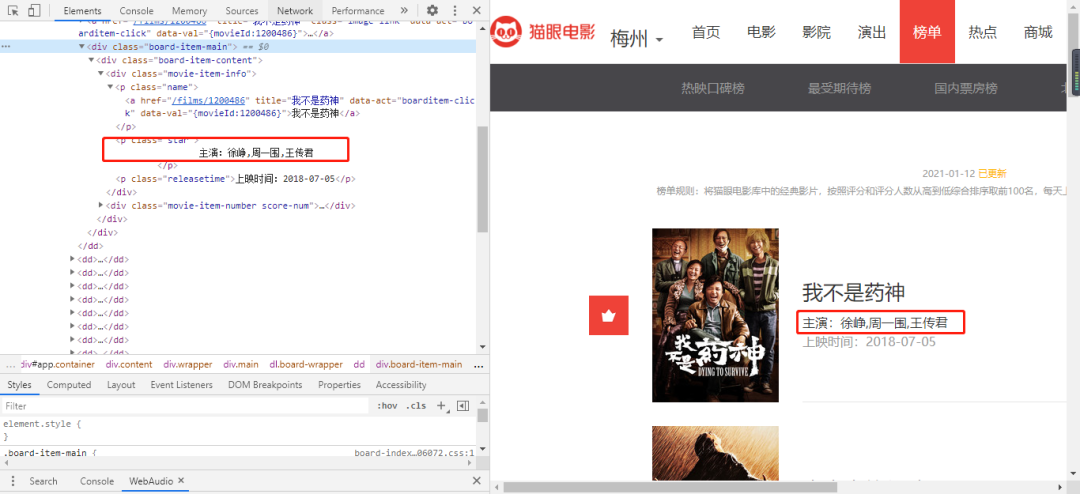
從上圖可以看到,主演的信息位于board-item-main的子節點p標簽內,因此我們可以這樣獲取主演信息。
核心代碼如下所示:
p = doc('.board-item-main .board-item-content .movie-item-info')
star = p.children('.star').text()
獲取上映時間
從前面的圖片也可以看到,上映時間的信息與主演信息的節點是兄弟節點,所以我們可以這樣寫代碼。
p = doc('.board-item-main .board-item-content .movie-item-info')
time = p.children('.releasetime').text()
從上面的圖片可以看到,整數部分與小數部分被分割了成了兩部分。因此需要分別獲取兩部分的數據,在進行拼接即可。
核心代碼如下所示:
score1 = doc('.board-item-main .movie-item-number.score-num .integer').text().split()
score2 = doc('.board-item-main .movie-item-number.score-num .fraction').text().split()
score = [score1[i]+score2[i] for i in range(0, len(score1))]
關于翻頁
打開網頁的時候,你會發現榜單一共有10頁,每一頁的URL都不相同,那該怎么辦呢?總不能每一次都手動更換URL地址吧。
先來觀察前四頁的URL地址吧。
https://maoyan.com/board/4 # 第一頁
https://maoyan.com/board/4?offset=10 # 第二頁
https://maoyan.com/board/4?offset=20 # 第三頁
https://maoyan.com/board/4?offset=30 # 第四頁
觀察完之后,我想不需要我過多敘述它的特點了吧。
接下來我們就可以構建每一頁的URL地址了,具體代碼如下所示:
def get_url(self, page):
url = f'https://maoyan.com/board/4?offset={page}'
return url
if __name__ == '__main__':
maoyan = MaoYan()
for page in range(10):
url = maoyan.get_url(page*10)
結果展示

最后
本次分享到就此結束,如果你從開頭讀到這里,想必文章對你是有所幫助的,這也是我分享知識的初衷。
-
字符串
+關注
關注
1文章
577瀏覽量
20488 -
網頁
+關注
關注
0文章
72瀏覽量
19299 -
選擇器
+關注
關注
0文章
106瀏覽量
14523
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論