 圖解Spring Bean生成流程,非常詳盡
圖解Spring Bean生成流程,非常詳盡
很多人把spring的相關內容當作背八股文,認為只在面試時能用上,實際開發根本用不到。實際上早期的我也是這么想的,但隨著開發年限的增長,解決了越來越多的難題后,不得不承認,這些基礎知識的學習有著無法替代的作用。
就拿我實際遇到的一個例子來說:
有一個大型項目因為安全漏洞的原因要進行升級,需要從springboot1.0升級至springboot2.0,但發現springboot2的默認動態代理方式為CGLIB,而項目上很多地方利用的jdk代理對接口做了增強,切換至CGLIB導致了大量問題。根據百度的內容,設置了proxy-target-class=“false”,然而不起作用,最后發現是某一個三方包內設置了proxy-target-class=“true”,而這個屬性只要在工程里任何地方設置過一次true,都會導致代理管理器的同名屬性為true,最終采用CGLIB代理,那么有什么簡單方式可以解決這個問題
先賣個關子,還是讓我們一起學學Bean的生成吧
1引言
作為javaboy的必修課,spring一路伴隨著開發者;同樣的,也一路伴隨著開發者面試,重要性不言而喻,我們經常遇見的問題比如:
代理對象是何時生成的?
循環依賴是怎么解決的?
能說說對Springr容器三級緩存的理解嗎?
以上問題,都離不開對bean生成流程的熟悉與理解。但是不得不談,目前網上文章魚龍混雜,一些偏頗錯誤的分析四處流傳,我們后面會提到一些常見謬傳。至于現在,現在先和我們一起,深入的看下springBean的生成邏輯吧
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://github.com/YunaiV/ruoyi-vue-pro
視頻教程:https://doc.iocoder.cn/video/
2創建Bean的極簡流程
我們開門見山,直接以單例對象為例子,說一個Bean的極簡流程以及其目的
獲取Bean定義
掃描工程內所有被標記的Bean,獲取其類型,名稱,屬性,構造方法等信息,存在一個Map里
生成實例
這一步也很簡單,遍歷上述Map,利用Bean定義里的無參構造方法創建對象,和new 對象同理
屬性裝填
剛創建的對象所有屬性都是默認值,需要我們給它裝填上需要的內容
初始化
如果這個Bean實現了InitializingBean接口,則會調用你寫在afterPropertiesSet方法里的內容。
到此,一個Bean就創建完畢了,是不是很簡單?是的,很簡單,邏輯也很清晰。
當然,上面四步是核心功能,Spring為了增強對這些Bean的修改能力,在2-生成實例 3-屬性裝填 4-初始化的前后都預留了處理點,Spring自己或用戶都可以通過編寫==Bean后置處理器(BeanPostProcessor)==來實現自己的目的,這些處理器會在對應的處理點被執行,從而完成對Bean的修改,下面會詳細講一下
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://github.com/YunaiV/yudao-cloud
視頻教程:https://doc.iocoder.cn/video/
3后置處理器(PostProcessor)
Spring中的后置處理器分為兩大類:
一類是針對Bean工廠的BeanFactoryPostProcessor
一類是針對Bean的BeanPostProcessor
以上兩者都是接口,Spring已經給定了一些實現類,用戶也可以自己寫一些實現類來實現全局的Bean相關的操作;顧名思義,BeanFactoryPostProcessor針對Bean工廠(它還有個子接口BeanDefinitionRegistryPostProcessor),調整Bean工廠的屬性、影響Bean定義,注意此時還沒有Bean進行實例化。BeanPostProcessor則更直接的作用于Bean實例生成過程中的修改。
BeanFactoryPostProcessor
很多人不知道在實際項目中這個處理器有什么用,好像我們不需要對Bean工廠或者Bean做什么改動吧?大部分項目確實不需要,但很多時候,我們需要添加一些自定義的Bean,或者出于項目需要,改動一些Spring原生Bean屬性時就用的上了。
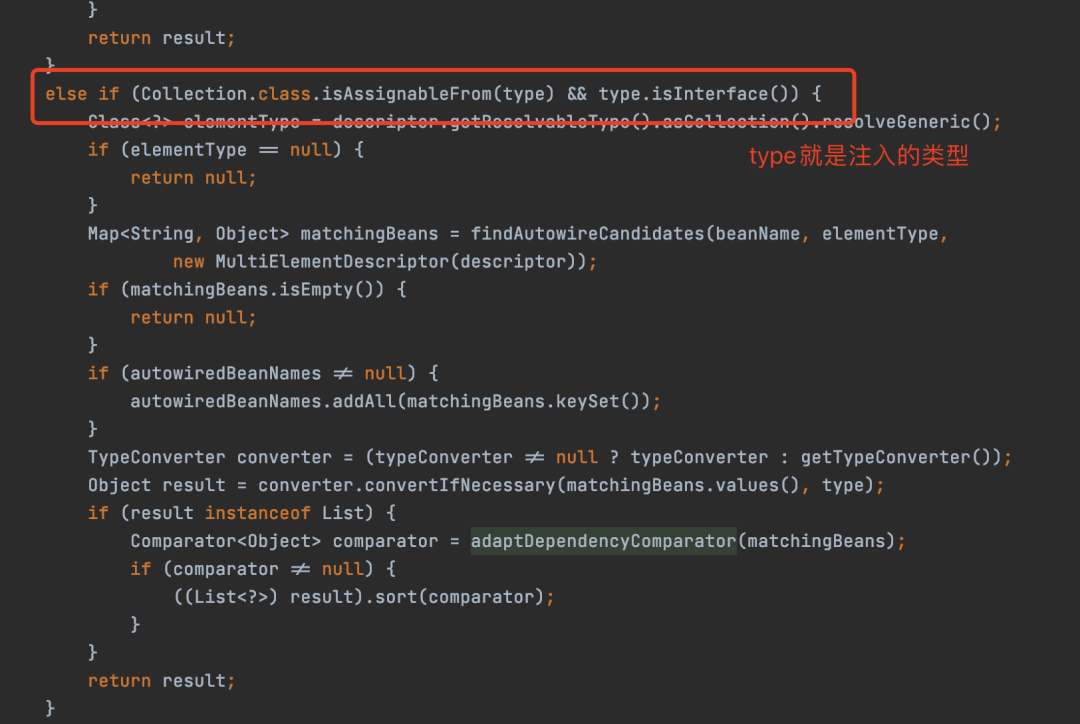
比如我們常用的myBatis組件,我們會在mapper層的接口上寫@Mapper注解,最后就會在Spring中生成對應的Bean對象,然而這里有一個問題:
@Mapper注解不是Spring規定的Bean注解,怎么被掃描進容器的?
自然是依托于BeanFactory后置處理器。mybatis中寫有工廠后置處理器的實現
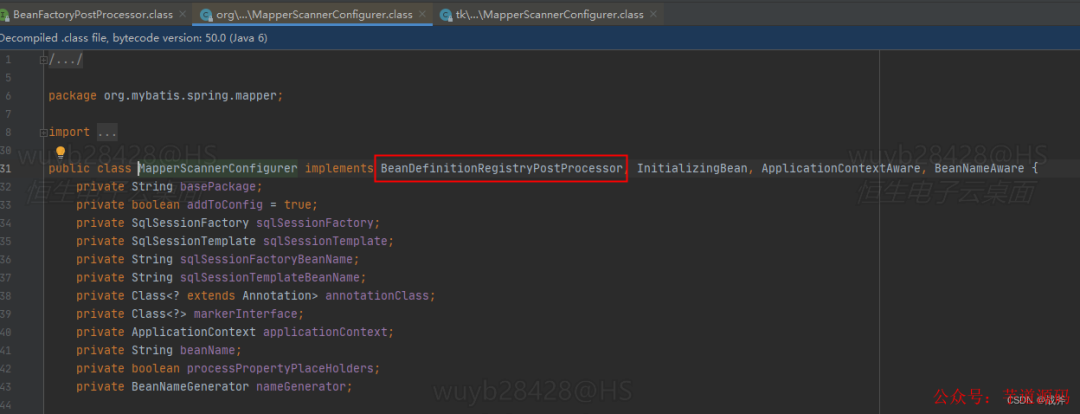
看名字也知道,這個處理器起了掃描的作用,找到了被我們標記的接口,并“捏造”一個Bean定義,并把Bean的類型設置為MapperFactoryBean.class,即工廠類,然后把它添加到Bean定義注冊器中。
而在我們需要實例化這個Bean的時候,mybatis又會從這個工廠對象中使用getObject()為我們取出一個Bean實例,這個Bean實例是使用我們寫的Mapper接口產生的代理,而后再把這個代理放入Spring容器
BeanPostProcessor
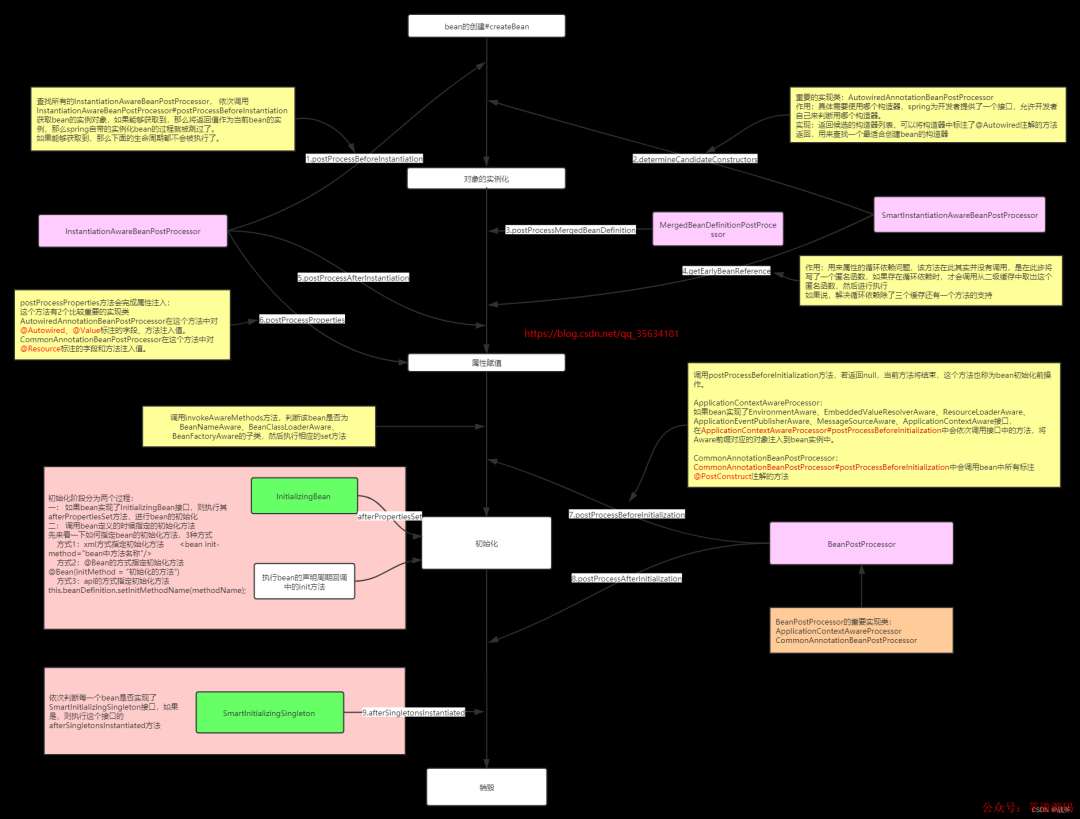
而Bean后置處理器則更加常見,種類也更豐富,他們的詳細作用和工作時機都可以在下圖中看到
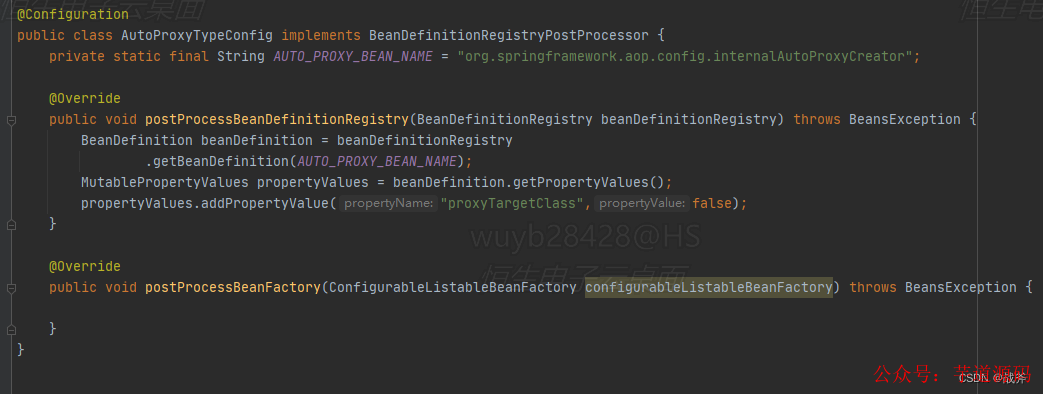
契機問題的解決
讓我們回到契機里提到的那個問題,這個問題簡化的講,其實就是有這么一個Spring內部的Bean名字為org.springframework.aop.config.internalAutoProxyCreator,它有一個屬性proxy-target-class,這個屬性決定了Spring動態代理的生成用的jdk動態代理還是CGlib,然而在很多地方(三方包)已經給他賦值。
我們必須在它被其他三方包賦值后 ,把它的屬性值改為false。這個問題最終怎么做到的呢?就是利用了后置處理器,此處使用工廠后置處理器找到該Bean定義,修改其Bean屬性
4引用與緩存
從上面看,似乎創建一個Bean只需要四步(忽略后置處理器的步驟),十分簡單。確實,如果我們的項目只需生成一個Bean,那只要按序完成這四步就可以了。
但實際上,Spring本身和我們的項目要生成的Bean數量遠不止一個,復雜的項目一般會達到上千個Bean,Bean之間還有復雜的引用關系。我們不僅要存儲這些Bean,還必須考慮到這些引用情形,從而引入緩存的機制。
引用已有的Bean
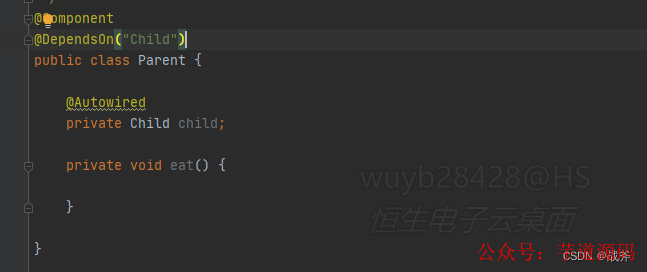
如圖,上述是一種最簡單的引用,Parent 里面引用了 Child ,。理想的情況下,我們先創建了Child并保存起來,那么在創建Parent的時候,直接引用現成的Child就好(此處用@DependsOn保證這種順序)。那么這時我們可以說,容器只需要使用一級緩存,就像養雞場里飼養著許多雞,這個緩存里存的就是各個現成的Bean,直接取用即可。
引用未創建的Bean
上述的Parent 里面引用了 Child案例,只是一種理想情況,實際上,大部分的Bean之間加載順序并不會特意指定,創建的先后順序自然沒了保障(spring會執行默認的加載順序,如字母排序)。
比如這個案例,如果先創建的是Parent,那么當我們做到屬性裝填這一步的時候,就會發現Parent的屬性里,引用了一個未知的Bean —— Child。
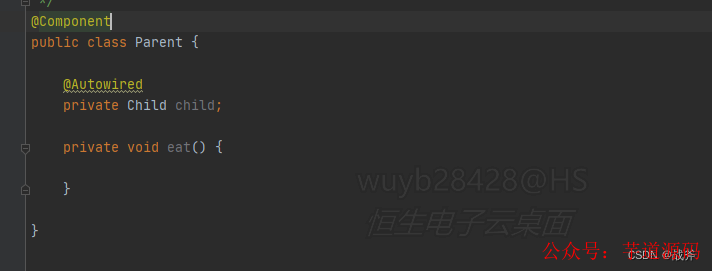
這個時候Spring就會去搜尋并創建Child,此時Parent的創建就停滯了。那么這個創建未半而中道崩殂的Parent也需要有一個地方存起來啊。你或許會說,還是存在上面的一級緩存里面不行嗎?
當然可以!但本著人以類聚物以群分的觀念,對于這些創建了一半就中斷的Bean,我們還是專門引入了三級緩存供其棲息。我們知道,此時Parent已經實例化了,但屬性裝填沒完成,像個未孵化的蛋,而三級緩存就是個保溫箱,是存放這些“蛋”的地方。實際上三級緩存里存的全是Bean工廠,可以通過Bean工廠的getEarlyBeanReference獲取到這個未完成的Bean(蛋)。
循環引用(循環依賴)
如果不僅Parent里面引用了Child,Child里面也引用了Parent,那么顯然,這就構成了循環引用。
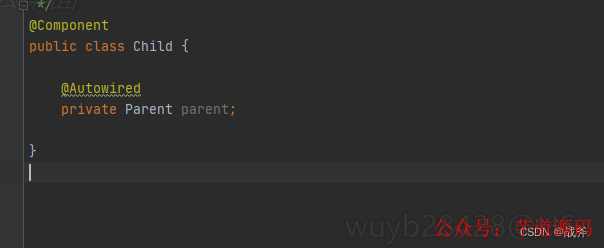
我們假定Spring先加載了Parent,后發現需要注入Child,又去加載Child,過程中又發現需要注入Parent,那么又去加載Parent…… 那Spring會這么無限的加載下去嗎?
答案我們都知道,自然是不會的。實際上,每開始加載一個Bean,Spring都會把Bean名稱記錄在一個叫SingletonCurrentlyInCreation的Set集合里。
顧名思義,這個集合里都是正在創建中的Bean,這個集合在其他的文檔中很少提及,但顯然他的作用十分巨大。因為第二次加載Parent時,Spring就發現Parent已經在這個集合中了,才意識到進入循環引用了。
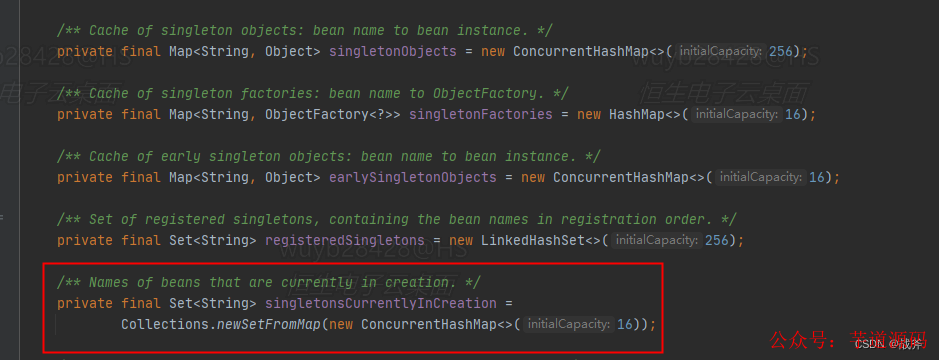
當發現進入循環引用后,自然Spring不會再傻乎乎的走再走一遍Parent的加載邏輯,而是從三級緩存中取出未完成的Bean,做一些處理后,然后將其放入二級緩存。
這一過程相當于從保溫箱取出來未孵化的雞蛋,孵化出小雞后,放到專門的小雞培養室中。而此時,只需要返回這只小雞(Parent)就可以了,你或許會說,我要的是成品雞,你給我小雞有什么用,功能什么的能有保障嗎?別急,我下面就為你解釋這樣的可行性。
循環引用中的代理
我們都知道Parent是創建了一半被放入緩存中的,此時它已經完成的步驟是生成實例正在卡著的步驟是屬性裝填和初始化,被從緩存中取出后,這兩個步驟仍然是未完成的,但我們無需擔心,因為此刻我們僅需完成引用,即我要引用Parent(成雞),你現在給我返回半成品(小雞)也沒關系,因為我現在也不是要立刻就用你,只要你保證小雞 成雞在內存中的地址一樣即可,即小雞和成雞是同一個對象。
你或許會問,小雞長著長著,還能變了人不成?怎么可能小雞和成雞就不是同一個對象了呢?這就不得不談代理模式了
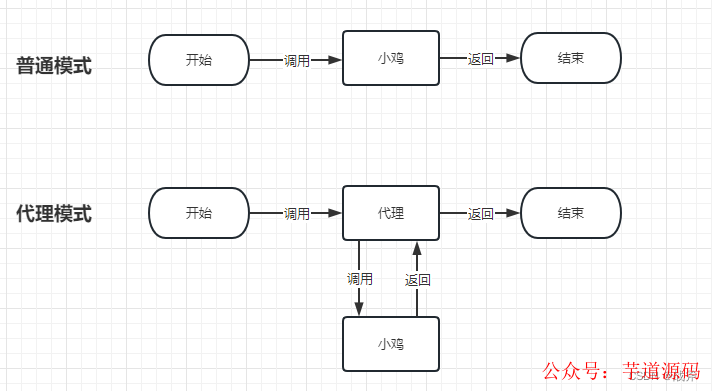
我們這里不去細談代理流程,你只需要知道代理模式會產生一個新的對象,相當于一個霸道中介,原本你可以直接聯系小雞,現在小雞的聯系被中介切斷了,你需要找小雞就只能聯系中介。所以,一旦成雞后續需要代理,我們需要聯系的就是成雞的代理了,此時你給我小雞的聯系方式不頂用。
為避免這種情況,我們只能給小雞生成中介。是的,原來中介是只給成雞用的,但現在不得不提前到小雞階段了,生成中介后,返回給我們小雞的-中介的-聯系方式(即半成品Bean的-代理的-引用),事實上如果你看源碼,對成品和半成品Bean生成代理用的是同一個方法wrapIfNecessary,因此生成代理的效果是一樣的。當然你也許仍然有顧慮,對成品和半成品生成代理真的沒差別嗎?
的確,這里就不得不提Spring的代理的特殊點了,代理的基礎就是大名鼎鼎的AOP 或者說 切面增強,然而Spring的增強僅針對方法。而半成品和成品,最大的差異是屬性值,方法卻是一樣的,因此增強的效果肯定是一樣的。如果哪天Spring的代理生成時會用到當前屬性值,那不同階段的代理功能才會有差異。
5三級緩存的解讀
關于三級緩存,市面上有太多的解讀文章,也是面試時經常問到的點,我們不妨解讀一下三級緩存。
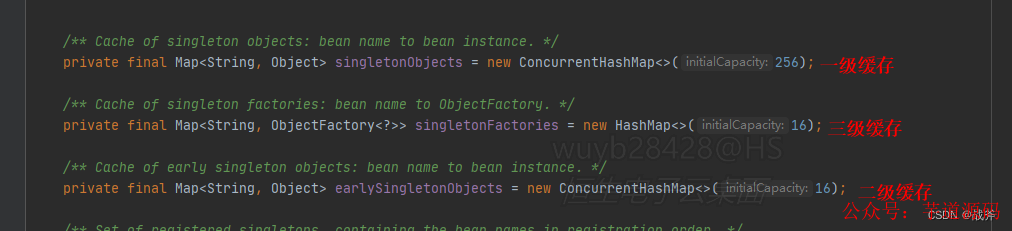
我們平常說的三級緩存,大多數人會想到CPU的三級緩存,硬件上之所以緩存分級,是對于成本與性能的考量,一級緩存最快,所以CPU優先從一級緩存取東西,但同樣一級緩存最貴,存不了太多數據,所以需要二級緩存。
而這里,三級緩存并沒有性能上的區別,所以劃分三級緩存并非必須。實際上一個Bean,在同一時間只會出現在某一級緩存中,因此我們可以直接產出一個暴論:Spring可以不用所謂三級緩存,甚至說只需要一個集合就能存下全部
但為什么這里要這么做,因為這是邏輯分層而非必要分層,三級緩存存著不同狀態的Bean罷了:一級緩存存成品雞,二級緩存存小雞,三級緩存存雞蛋 一級比一級原始,你要非把成品雞、小雞、雞蛋擱一個房子里也不是不行,所以這種分層是基于邏輯清晰而非邏輯必需。
這里還有個誤區,很多人說是因為代理的存在,導致需要三級緩存,如果沒有代理,兩級就夠了。實際上三級緩存并不是因為代理導致的,不管有沒有代理,都是三級緩存。
就像我說的一級緩存存成品雞,二級緩存存小雞,三級緩存存雞蛋 ,這里面并不區分代理,成品雞或者成品雞的代理都在一級緩存;小雞或者小雞的代理都在二級緩存。
實際上我們看代碼,只要發生了循環引用,都會導致Bean從三級緩存取出,并放入二級緩存。這個過程中執行wrapIfNecessary,不管生不生成代理都是一樣的,只不過如果需要代理,放入二級緩存的是小雞的代理;如果不需要代理,放入二級緩存的就是小雞本雞,因此我們可以說 不管有沒有代理,三級緩存的模式都沒有變化。
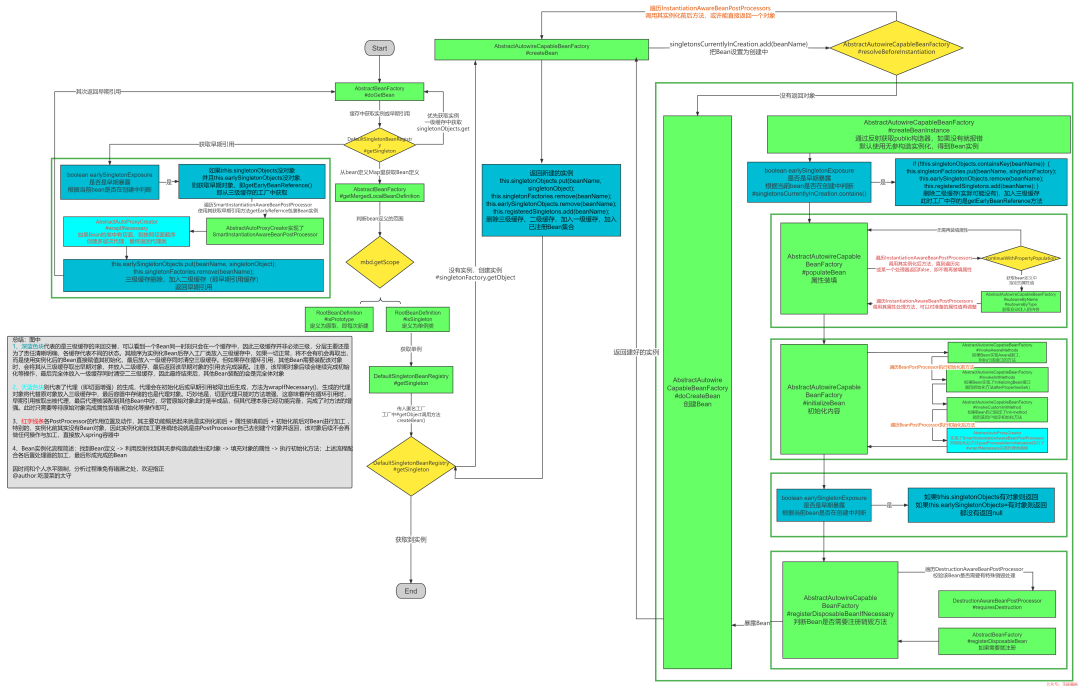
6創建Bean的極詳細流程
多說無益,我根據Spring4的源碼整理了一份詳細的生成流程,這圖說是全網最細也不為過,歡迎大家補充和指正
-
處理器
+關注
關注
68文章
19165瀏覽量
229138 -
spring
+關注
關注
0文章
338瀏覽量
14311 -
安全漏洞
+關注
關注
0文章
150瀏覽量
16706
原文標題:圖解 Spring Bean 生成流程,非常詳盡
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
java spring教程
spring實例
Spring工作原理
「Spring認證」Spring Hello World 項目示例
Spring Boot嵌入式Web容器原理是什么
Spring應用 1 springXML配置說明
解析加載及實例化Bean的順序(零配置)
「Spring認證」Spring IoC 容器

Spring中Bean的生命周期是怎樣的?
Spring Dependency Inject與Bean Scops注解
Spring依賴注入Bean類型的8種情況
Spring容器原始Bean是如何創建的?Spring源碼中方法的執行順序






 工商網監
工商網監
評論