 時間序列分析的四個基本Python庫介紹
時間序列分析的四個基本Python庫介紹
在本文中,我們將介紹四個主要的Python庫——statmodels、tslearn、tssearch、 tsfresh ——每個庫都針對時間序列分析的不同方面進行了定制。這些庫為從預測到模式識別的任務提供了強大的工具,使它們成為各種應用程序的寶貴資源。
我們使用來自Kaggle的數據集,通過加速度計數為各種身體活動進行分析。這些活動被分為12個不同的類別,每個類別對應一個特定的身體動作,如站立、坐著、行走,或從事更有活力的活動,如慢跑和騎自行車。每個活動都記錄了一分鐘的持續時間,提供了豐富的時間序列數據源。
用于此分析的庫有:
# statsmodels
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf
#tslearn
from tslearn.barycenters import dtw_barycenter_averaging
# tssearch
from tssearch import get_distance_dict, time_series_segmentation, time_series_search, plot_search_distance_result
# tsfresh
from tsfresh import extract_features
from tsfresh.feature_selection.relevance import calculate_relevance_table
from tsfresh.feature_extraction import EfficientFCParameters
from tsfresh.utilities.dataframe_functions import impute
Statsmodels
從statmodels庫中,兩個基本函數在理解從x, y和z方向收集的加速度數據的特征方面起著關鍵作用。
adfuller函數是確定時間序列信號平穩性的有力工具。通過對我們的數據進行Augmented Dickey-Fuller檢驗,可以確定加速度信號是否表現出平穩的行為,這是許多時間序列分析技術的基本要求。這個測試幫助我們評估數據是否隨時間而變化。
def activity_stationary_test(dataframe, sensor, activity):
dataframe.reset_index(drop=True)
adft = adfuller(dataframe[(dataframe['Activity'] == activity)][sensor], autolag='AIC')
output_df = pd.DataFrame({'Values':[adft[0], adft[1], adft[4]['1%']], 'Metric':['Test Statistics', 'p-value', 'critical value (1%)']})
print('Statistics of {} sensor:n'.format(sensor), output_df)
print()
if (adft[1] < 0.05) & (adft[0] < adft[4]['1%']):
print('The signal is stationary')
else:
print('The signal is non-stationary')
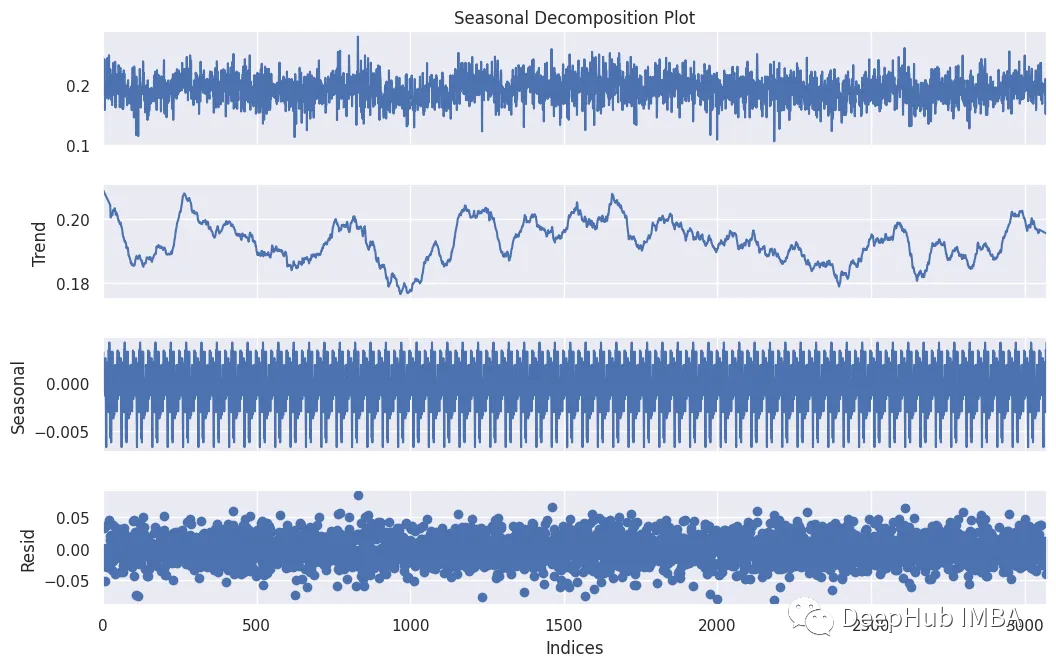
seasonal_decomposition函數提供了對時間序列數據結構的寶貴見解。它將時間序列分解為三個不同的組成部分:趨勢、季節性和殘差。這種分解使我們能夠可視化和理解加速度數據中的潛在模式和異常。
def activity_decomposition(dataframe, sensor, activity):
dataframe.reset_index(drop=True)
data = dataframe[(dataframe['Activity'] == activity)][sensor]
decompose = seasonal_decompose(data, model='additive', extrapolate_trend='freq', period=50)
fig = decompose.plot()
fig.set_size_inches((12, 7))
fig.axes[0].set_title('Seasonal Decomposition Plot')
fig.axes[3].set_xlabel('Indices')
plt.show()
Tslearn
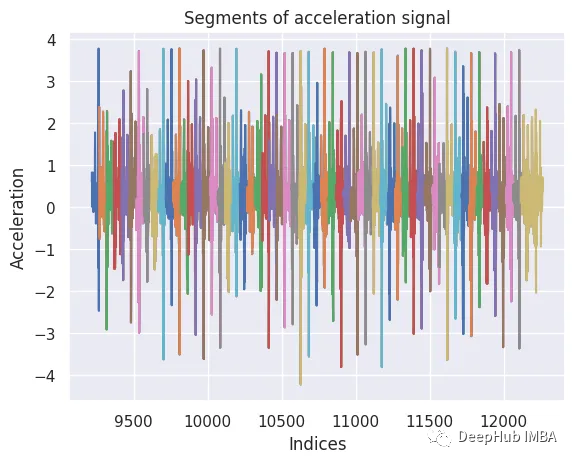
如果使用tslearn庫進行時間序列分析。可以采用分割方法,將連續的加速信號分解成特定長度的離散段或窗口(例如,150個數據點)。這些片段提供了行走過程中運動的顆粒視圖,并成為進一步分析的基礎。重要的是,我們在相鄰部分之間使用了50個數據點的重疊,從而可以更全面地覆蓋潛在的動態。
template_length = 150
overlap = 50 # Adjust the overlap value as needed
segments = [signal[i:i + template_length] for i in range(0, len(signal) - template_length + 1, overlap)]
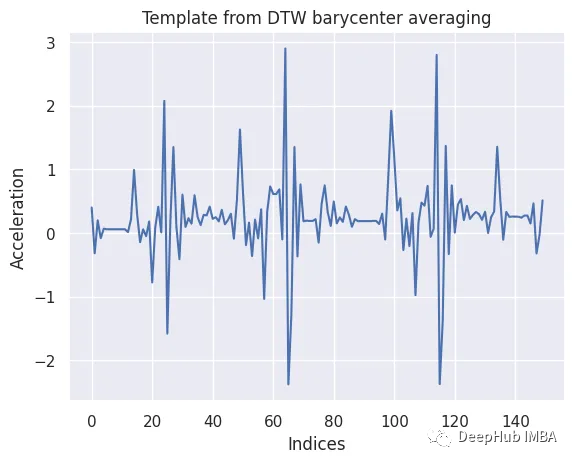
為了從這些片段中獲得一個封裝行走典型特征的代表性模板,我們使用了dtw_barycenter_averaging函數。該方法采用動態時間規整(Dynamic Time Warping, DTW)對分割的時間序列進行對齊和平均,有效地創建了一個捕捉步行運動中心趨勢的模板。
template_signal = dtw_barycenter_averaging(segments)
template_signal = template_signal.flatten()
生成的模板為后續的分類和比較任務提供了有價值的參考,有助于基于x軸加速度的步行活動識別和分析。
Tssearch
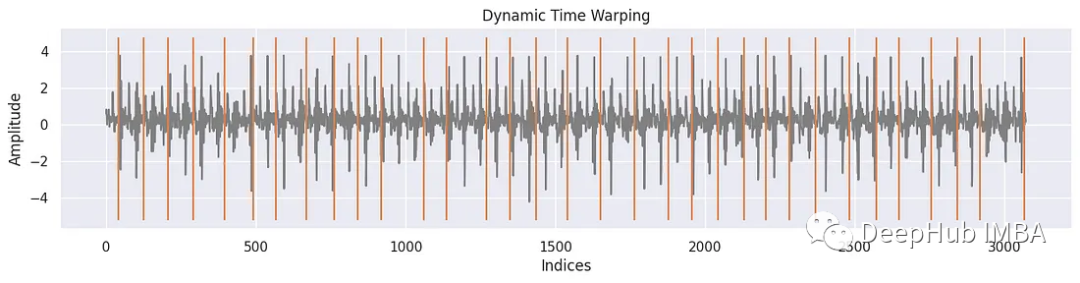
對于tssearch庫使用time_series_segmentation函數,通過動態時間規整(DTW)或其他相似性度量來識別輸入時間序列中與所提供的模板信號最相似的片段。
該函數的主要目標是定位和提取與模板信號密切匹配的輸入時間序列片段。通過將模板信號與輸入時間序列進行比較,可以找到這些片段,該函數返回輸入時間序列中這些片段開始的位置或索引。
segment_distance = get_distance_dict(["Dynamic Time Warping"])
segment_results = time_series_segmentation(segment_distance, template_signal, signal_np)
for k in segment_results:
plt.figure(figsize=(15, 3))
plt.plot(signal_np, color='gray')
plt.vlines(segment_results[k], np.min(signal_np)-1, np.max(signal_np) + 1, 'C1')
plt.xlabel('Indices')
plt.ylabel('Amplitude')
plt.title(k)
tssearch庫中還有另一個用于發現時間序列數據中的相似性和差異性的方法。首先,我們配置了一個字典dict_distances來指定搜索的距離度量。定義了兩種不同的方法。第一個,標記為“elastic”,采用動態時間規整(DTW)作為相似性度量。使用特定的參數定制DTW,例如dtw_type設置為“sub-dtw”,alpha設置為0.5,允許靈活的時間序列對齊和比較。然后是“lockstep”,它利用歐幾里得距離以一種更嚴格的方式來衡量相似性。有了這些距離配置,就可以使用time_series_search函數執行時間序列搜索,將模板信號與目標信號(signal_np)進行比較,并指定前30個匹配項的輸出。
dict_distances = {
"elastic": {
"Dynamic Time Warping": {
"function": "dtw",
"parameters": {"dtw_type": "sub-dtw", "alpha": 0.5},
}
},
"lockstep": {
"Euclidean Distance": {
"function": "euclidean_distance",
"parameters": "",
}
}
}
result = time_series_search(dict_distances, template_signal, signal_np, output=("number", 30))
plot_search_distance_result(result, signal_np)
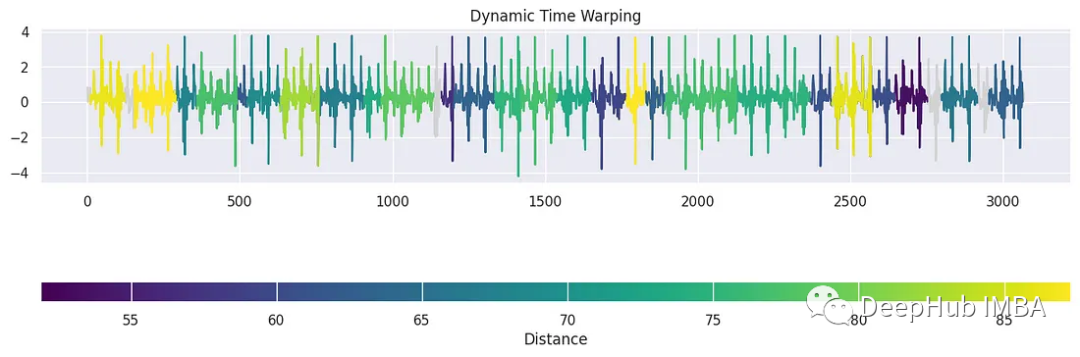
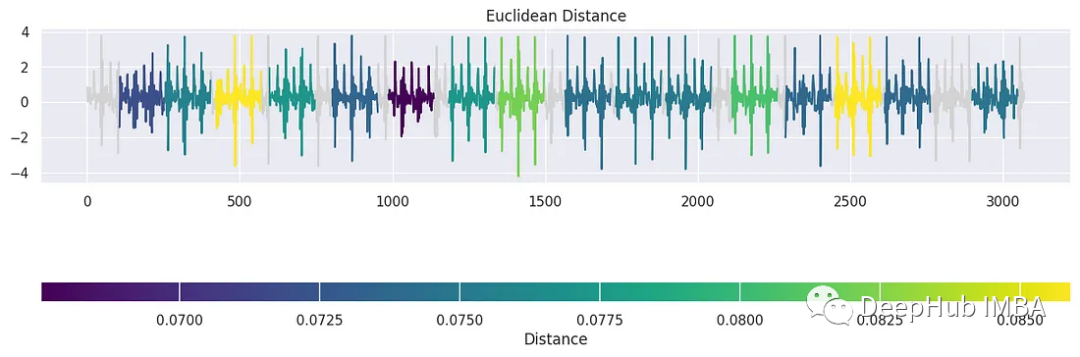
這是一種時間序列聚類的簡單的方法,并且可解釋性很強。
Tsfresh
tsfresh庫則是一個很好的自動化特征提取過程的工具。effentfcparameters()定義了一組提取設置,它指定了特征提取參數和配置。這些設置可以控制在提取過程中計算哪些特征。然后就可以使用extract_features函數應用進行特征的提取。這里應該將“Activity”列作為標識符列,并提供了特征提取參數。重要的是,該庫可以對缺失值(NaN)的特征進行自動刪除,結果保存在x_extract中,是從時間序列數據中提取的大量特征集合。Tsfresh簡化了通常復雜且耗時的特征工程過程,為時間序列分析提供了寶貴的資源。
extraction_settings = EfficientFCParameters()
X_extracted = extract_features(final_df, column_id='Activity',
default_fc_parameters=extraction_settings,
# we impute = remove all NaN features automatically
impute_function=impute, show_warnings=False)
X_extracted= pd.DataFrame(X_extracted, index=X_extracted.index, columns=X_extracted.columns)
values = list(range(1, 13))
y = pd.Series(values, index=range(1, 13))
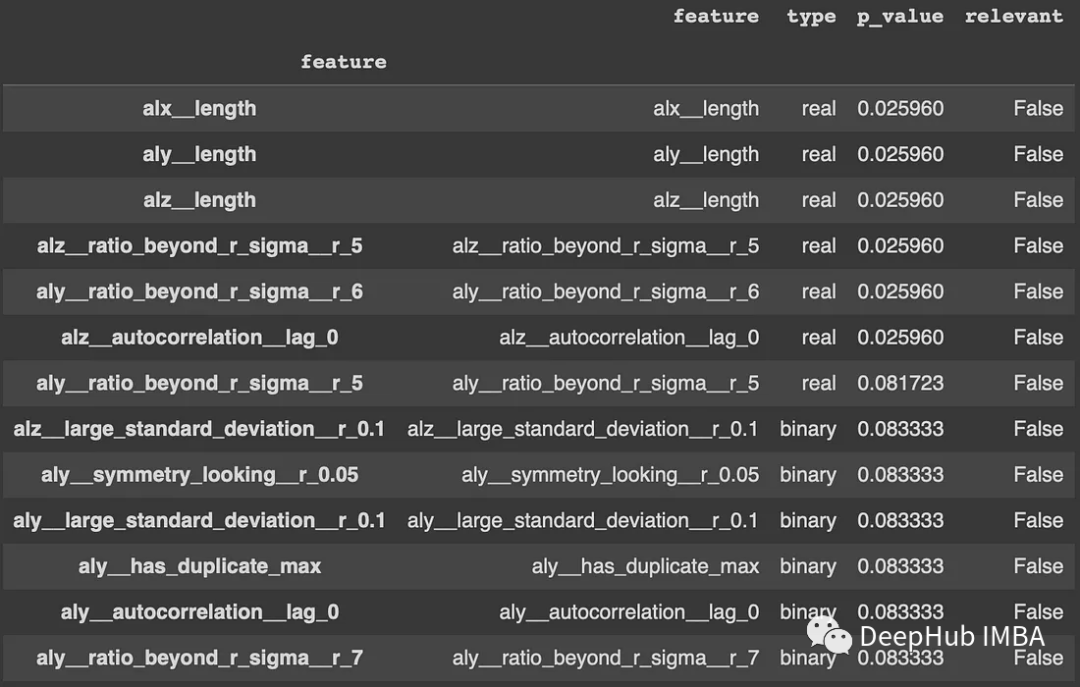
relevance_table_clf = calculate_relevance_table(X_extracted, y)
relevance_table_clf.sort_values("p_value", inplace=True)
relevance_table_clf.head(10)
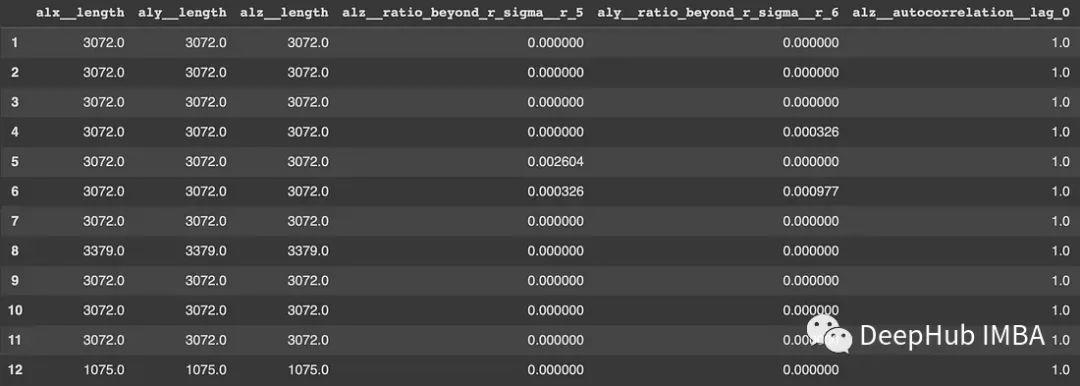
top_features = relevance_table_clf["feature"].head(10)
x_features = X_extracted[top_features]
總結
本文向您介紹了時間序列分析的四個基本Python庫:statmodels、tslearn、tssearch和tsfresh。時間序列分析是金融和醫療保健等各個領域的重要工具,在這些領域,我們需要了解數據隨時間的變化趨勢,以便做出明智的決策和預測。
每個庫都專注于時間序列分析的不同方面,選擇哪個庫取決于具體問題。通過結合使用這些庫,可以處理各種與時間相關的挑戰,從預測財務趨勢到對醫療保健中的活動進行分類。當要開始自己的時間序列分析項目時,請記住這些庫,結合著使用它們可以幫助你解決很多的實際問題。
-
函數
+關注
關注
3文章
4306瀏覽量
62431 -
應用程序
+關注
關注
37文章
3243瀏覽量
57603 -
python
+關注
關注
56文章
4782瀏覽量
84453 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
發布評論請先 登錄
相關推薦
【「時間序列與機器學習」閱讀體驗】全書概覽與時間序列概述
【《時間序列與機器學習》閱讀體驗】+ 了解時間序列
【「時間序列與機器學習」閱讀體驗】時間序列的信息提取
python數據分析的類庫
怎么有效學習Python數據分析?
時間序列小波分析的操作步驟及實例分析

Git的使用說明四個點詳細說明

如何用Python進行時間序列分解和預測?






 工商網監
工商網監
評論