 基于機器學習的應用系統指紋識別技術研究
基于機器學習的應用系統指紋識別技術研究
來源:信息安全與通訊保密雜志社
作者:賀彥鈞 , 朱磊 , 黃煒
摘要:在信息安全測試領域,基于機器學習的應用系統深度指紋識別技術對應用系統進行漏洞檢測時,可快速獲取應用系統指紋信息,并且能夠根據系統深度指紋信息進行精確的自適應漏洞檢測。通過研究面向 http 協議的信息收集爬蟲技術、基于字符串匹配的識別技術和目標安全缺陷利用技術,基于目標指紋特征提出并搭建了樸素貝葉斯模型,實現了基于機器學習的應用系統指紋識別技術,識別目標應用系統信息,發現缺陷和自適應漏洞檢測。最后對相關技術的實現進行實驗驗證,實驗結果符合預期。
隨著互聯網的迅速發展和智能化應用的普及,對數據的隱私保護和安全性的要求越來越高。在網絡安全領域,指紋識別技術被廣泛用來識別和驗證用戶的身份,以保護敏感信息和資源的安全。傳統的指紋識別技術主要集中在人體指紋的識別上,但隨著技術的進步和應用場景的改變,深度指紋識別技術逐漸引起了研究者和工程師的關注。深度指紋識別技術是一種基于機器學習的指紋識別方法,通過訓練模型和學習特征來實現更準確和可靠的指紋識別。與傳統的指紋識別技術相比,深度指紋識別技術具有更高的靈活性和擴展性。它能夠識別各種類型的指紋,包括人體指紋、網絡活動指紋、行為指紋等,以滿足不同領域的應用需求。深度指紋識別技術是通過深度學習模型來提取和學習指紋數據的特征,從而實現指紋的分類和識別,并通過分析指紋的局部特征和上下文信息,達到更高的識別準確率和魯棒性。
因此,本文面向信息安全測試領域,在應用系統進行漏洞檢測時,針對如何快速獲取應用系統指紋信息,如何根據應用系統指紋信息進行自適應漏洞檢測等問題,提出了“基于機器學習的深度指紋識別技術及應用”思路,幫助測試人員快速準確找到應用系統漏洞,及時通知系統開發人員進行整改修復,做好網絡安全防護工作,進一步保障系統安全穩定運行。
1研究思路
1.1概述
目前針對 Web 服務器指紋識別的主流研究主要通過分析大量 HTML 數據,包括 HTML 源碼關鍵字和特殊文件及路徑,來識別 Web 組件,探測以下幾個請求和返回信息進行 Web 應用指紋判斷:網站響應頭部信息(Response header)、HTML頁面內 META 標簽信息、HTML 內腳本語言信息(JavaScript,JS)、 層 疊 樣 式 表(Cascading StyleSheets,CSS)等引用鏈接信息、特殊統一資源定位(Uniform Resource Locator,URL)地址及參數、特定文件名、文件內容及文件的數字摘要(Hash 值)。
主流的 Web 指紋識別技術是基于特征匹配實現的,包括特殊靜態文件 Hash 值和關鍵字段兩類特征。特殊靜態文件可以是 js、css 文件,也可以是圖片、默認圖標 favicon.ico 等。關鍵字段特征包括 HTTP 響應頭里的關鍵字段特征信息、正常或錯誤頁面里的關鍵字段特征、文件資源路徑里的關鍵字段特征。
1.2研究思路
本文通過基于機器學習的應用系統深度指紋識別技術及應用的研究,實現了一種使用基于機器學習的自動化安全測試工具。該系統首先通過基于機器學習的數據對安裝在 Web 服務器上的軟件(操作系統、中間件、框架、CMS 等)進行標識和深度識別;其次利用識別后的精確數據,使用安全檢查工具(The Metasploit Framework,MSF)對標識的軟件執行有效的數據分析和安全測試;最后生成掃描結果報告。該系統自動執行上述處理,如圖 1 所示。
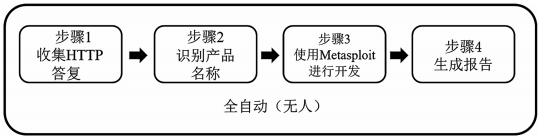
圖 1系統處理步驟
用 戶 的 操 作 只 輸 入 目 標 Web 服 務 器 的 頂 部URL(TOP UR),系統就自動爬取收集目標服務器的數據信息,獲取域名信息,探測 Web 應用程序的目錄結構,識別 Web 應用程序的技術棧,發現敏感信息等。通過系統智能化分析,用戶可以在不花費時間和精力的情況下自動識別 Web 服務器的構建特征信息、組件信息和脆弱性信息等。
2研究內容及方法
2.1HTTP 信息收集爬蟲技術
HTTP 信息收集爬蟲技術是一種利用 HTTP 協議進行信息收集和抓取的技術方法。它通過模擬HTTP 請求,訪問目標網站的不同頁面,獲取網頁內容并提取有用的信息。
本文利用爬蟲技術收集目標網站的 HTTP 響應報文包,在用戶輸入 TOP URL 后,自動擴展目標網站資源、路徑鏈接,進行原始響應數據的爬取。信息收集爬蟲技術基本原理為:網絡爬蟲通過HTTP 鏈接輸入并向目標站點發起請求,即發送一個 Request 請求,請求數據可以包含 Headers(附加信息)、Cookies 等信息,等待后臺的響應。后臺正常接收并響應返回一個 Response 響應數據,響應報文中的響應體包含網頁信息,可能有 HTML、文檔、圖片、視頻等資源文件或者 JSON 數據等 [3]。HTML解析可以使用網頁解析庫和正則表達式進行處理。如果是 JSON 的話,可以直接轉成 JOSN 對象進行解析。如果是其他資源文件,就先保存等待爬取完成后處理。爬蟲可以用不同種形式來存儲網頁信息、生成文本文檔,或者直接保存到數據庫。
本文通過 Scrapy 框架來實現信息收集爬蟲技術。Scrapy 是一個為了爬取網站內容、提取結構性數據而編寫的開源爬蟲應用框架。可以運用在數據挖掘、信息處理或者存儲歷史數據等一系列程序中。使用 Scrapy 框架可以方便地自定義爬蟲的爬取規則,此外,還有很多穩定的開源庫幫助本文進行前置后續處理。
HTTP 信息收集爬蟲技術的實現步驟如下:
(1)確定目標網站:首先需要確定要爬取的目標網站,包括網站的 URL 和要抓取的頁面。
(2)構建爬蟲程序:根據所選的編程語言和爬蟲框架,編寫爬蟲程序。爬蟲程序需要實現 URL管理、HTTP 請求、頁面分析以及數據存儲等功能。
(3)發送 HTTP 請求:爬蟲根據 URL 隊列中的待訪問 URL,構造 HTTP 請求,并發送給目標服務器。HTTP 請求中包含請求方法(GET、POST 等)、請求頭(headers)、請求體(body)等信息。
(4)處理服務器響應:爬蟲接收到目標服務器返回的 HTTP 響應,并根據響應的狀態碼和內容進行處理。常見的響應狀態碼有 200 表示成功,404 表示頁面不存在等。
(5)頁面分析和信息提取:爬蟲對服務器返回的 HTML 頁面進行解析和分析,根據頁面分析技術提取出所需的信息,如文字、鏈接、圖片等。
(6)數據存儲:將提取的信息進行存儲,可以選擇合適的存儲方式,如文本文件、數據庫等。
(7)循環迭代:根據需要,爬蟲可以設置循環迭代的邏輯,不斷發送 HTTP 請求,抓取多個頁面的信息,還可以通過設置抓取深度、時間間隔等方式進行控制。
2.2目標指紋識別技術
面向特定目標的指紋識別技術主要利用基于字符串匹配的識別技術和基于機器學習的識別技術,對前面的爬蟲收集的 HTTP 響應數據集進行處理分析,從而識別目標的深度指紋信息。
2.2.1基于字符串匹配識別
(1)原理
基于字符串匹配目標指紋識別技術是一種通過字符串匹配來識別目標的技術。它在文本、代碼、日志等數據中查找指定的字符串,從而實現目標的定位和識別。
基于字符串匹配的目標指紋識別技術的原理主要包括以下幾個方面。
①字符串匹配算法:字符串匹配算法是基于目標字符串和待搜索字符串之間的比較,從而確定是否存在匹配的子串。常見的字符串匹配算法包括暴力 匹 配 法、KMP(Knuth-Morris-Pratt) 算 法、BM(Boyer-Moore)算法等。本文通過 KMP 算法實現字符串匹配和目標識別。
②目標定義和關鍵詞提取:在使用字符串匹配目標識別技術之前,需要明確目標的定義和關鍵詞的提取。目標可以是一個特定的字符串,也可以是一組字符串的組合。關鍵詞提取是通過文本分析和數據挖掘技術,從大量的文本數據中提取出與目標相關的關鍵詞,用于目標識別和匹配。
③輸入數據預處理:在進行字符串匹配目標識別之前,通常需要對輸入數據進行預處理。這包括去除無關字符、轉換大小寫、分割文本等操作。預處理可以提高匹配效率和準確性,減少干擾和誤判。
④匹配模式設計:匹配模式設計是指設計和實現匹配規則和模式,對目標字符串進行匹配。匹配模式可以是簡單的字符串匹配,也可以是模式匹配、正則表達式匹配等更復雜的匹配方法。根據目標的特征和匹配的需求,選擇合適的匹配模式進行目標識別。
⑤目標識別和處理:基于字符串匹配的目標識別技術可以通過掃描輸入數據,并根據預先定義好的匹配模式和關鍵詞,檢測出目標的位置和存在。一旦識別出目標,就可以進行后續的處理,如記錄日志、生成報告、觸發事件等。
(2)實驗驗證
爬蟲所爬取的數據如圖 2 所示。通過字符串匹配可識別出為 Drupal 的 CMS 系統,如圖 3 所示。
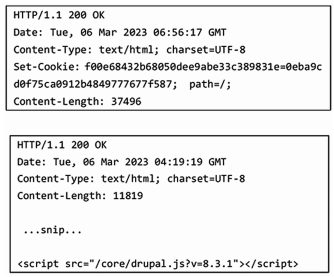
圖 2爬蟲數據

圖 3字符串匹配識別
2.2.2基于機器學習的指紋識別
(1)樸素貝葉斯算法原理
貝葉斯算法主要用于對目標進行分類,其算法思想主要基于貝葉斯原理,關鍵在于計算各類值之間的數據聯合分布 。
由于樸素貝葉斯是假定貝葉斯模型中的所有屬性都是相對獨立的,因此在屬性具有特定值的條件下,可以通過將所有屬性乘以具有特定類標簽的概率來獲得類的概率值,是一種有監督學習算法。計算流程如下文所述。
步驟 1:計算特征值 y 被分類為 xi 類別的后驗概率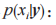
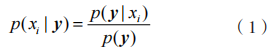
式中: 為
為 特征值的先驗概率。最大化 p(y|xi) 可以實現分類的目的。
特征值的先驗概率。最大化 p(y|xi) 可以實現分類的目的。
步驟 2:已知 HTTP 指紋特征 y 包含 n 維特征向量,則 y 可表示為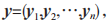 結合公式(1)可知:
結合公式(1)可知:
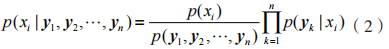
步驟 3:將公式(2)中的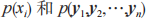 看作常量,則可簡化為:
看作常量,則可簡化為:
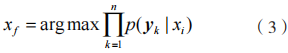
式中: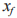 為指紋樣本 y 的分類結果。
為指紋樣本 y 的分類結果。
(2)特征選取
指紋特征輸入到貝葉斯模型前,需要將響應內容從不同的特征維度進行表示,以便貝葉斯模型能夠學習到響應內容的特征 [6-7]。本文主要從響應內容的 4 個特征維度進行考量,具體特征維度如表 1 所示。
表 1? 選取的特征維度

(3)歸一化
HTTP 請求特征和 URL 特征在數據分布區間上存在差異,容易導致模型訓練不收斂,因此采用公式(4)對特征向量進行歸一化:

式中:y 為歸一化后的特征元素;x 為待歸一化的特征元素; 分別為特征元素的最大值和最小值。
分別為特征元素的最大值和最小值。
(4)算法流程
步驟 1:通過 URL 地址發送請求,并獲取返回的響應信息。
步驟 2:對響應信息的 3 個特征維度進行特征編碼,并且對數據進行歸一化處理。
步驟 3:將歸一化后的數據向量作為貝葉斯模型的輸入,輸出結果即為預測結果。
預測流程如圖 4 所示。
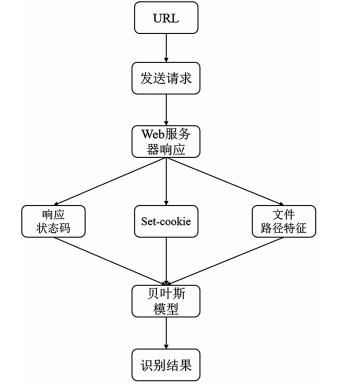
圖 4預測流程
(5)實驗驗證
由 于 Apache、Joomla !、Typeo、Drupal 等 每個軟件的特性都略有不同,將它們組合起來進行識別。樸素貝葉斯利用訓練數據學習。與簽名庫不同的是,當無法在一個特性中識別軟件時,樸素貝葉斯是基于 HTTP 響應中包含的各種特性隨機識別的,如圖 5 可以識別為 CMS Joomla 系統。這是因為機器學習識別模塊學會了 Joomla 的特征,例如“Cookie名稱 (f00e6….9831e)”和“Cookie 值 (0eba9….7f587)”。在本文的數據分析中,Joomla 在許多情況下使用 32個小寫字母作為 Cookie 名稱和 Cookie 值。訓練數據如圖 6 所示。

圖 5響應 set-cookie 值

圖 6訓練數據
基于機器學習指紋識別實驗獲取的目標數據如圖 7 所示,包括產品名稱、產品版本、組件名、操作系統版本。
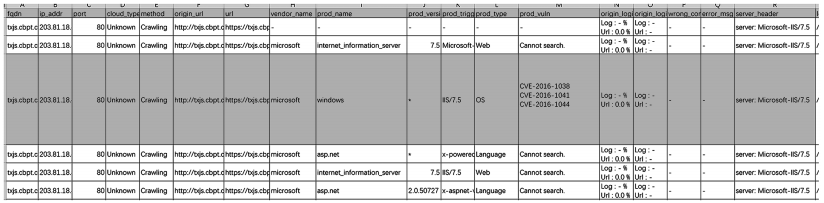
圖 7基于機器學習的指紋識別數據結果
2.3目標安全缺陷利用技術
Metasploit 是一個被廣泛使用的安全測試工具,它可以幫助安全專業人員發現和利用計算機系統中的安全漏洞。它擁有強大的功能和廣泛的支持,可以幫助用戶從安全測試者的角度來檢測和修復系統漏洞。基于機器學習的指紋識別軟件在安全測試中的作用是識別目標系統的運行環境。通過分析系統的響應和標識信息,目標指紋識別軟件可以確定目標系統使用的操作系統、服務和軟件版本等重要信息。這些信息對于成功利用系統漏洞至關重要,因為不同的操作系統和服務可能存在不同的漏洞。
本文通過基于機器學習指紋識別軟件與Metasploit 工具配合執行,檢查被測目標是否受到漏洞的影響,來自動化實現目標安全缺陷利用,如圖 8 所示。
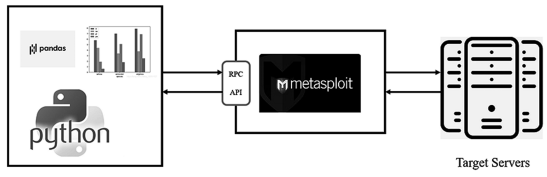
圖 8應用思路
整體應用思路過程如下文所述。
(1)數據收集:機器學習指紋識別軟件通過掃描目標系統收集關鍵特征數據,如操作系統版本、軟件配置等。
(2)特征提取和訓練:收集到的特征數據被提供給機器學習算法進行訓練。這個訓練過程會建立一個指紋庫,其中包含已知的漏洞特征和與之相應的利用。
(3)特征匹配:在執行利用之前,使用指紋識別軟件對目標系統進行掃描,并提取目標系統的特征;然后,與指紋庫中已知的漏洞特征進行匹配,如果匹配成功,就意味著目標系統可能存在與已知漏洞對應的安全缺陷。
(4)目標缺陷利用:機器學習指紋識別軟件 通 過 Metasploit 框 架 的 遠 程 過 程 調 用(Remote Procedure Call,RPC)服務與 Metasploit 工具進行通信連接,實現安全測試流程自動化。一旦匹配到目標系統的漏洞,Metasploit 框架可以根據匹配結果自動選擇相應的漏洞利用模塊進行測試。這樣,目標缺陷利用的過程可以自動化和精確地執行。
將 Metasploit 和基于機器學習的指紋識別軟件結合使用,可以提高安全測試的效率和成功率。首先,Metasploit 通過使用模塊來實現對目標系統的漏洞利用。Metasploit 擁有大量的模塊,包括掃描器、漏洞利用器、Payload 生成器等。用戶可以根據目標系統的特點選擇相應的模塊進行測試和利用。其次,Metasploit 可以根據目標指紋識別軟件提供的信息選擇適當的模塊進行漏洞測試和利用。例如,如果目標系統被識別為運行著一個特定版本的 Web服務器軟件,Metasploit 可以選擇相應的漏洞利用模塊來檢測和利用該軟件版本的安全漏洞。同樣重要的是,Metasploit 還可以使用 Payload 生成器來生成定制的載荷。用戶可以根據目標系統的特點選擇合適的 Payload 生成器來生成特定的載荷,以實現對目標系統的完全控制。
目標安全缺陷利用驗證效果見圖 9。
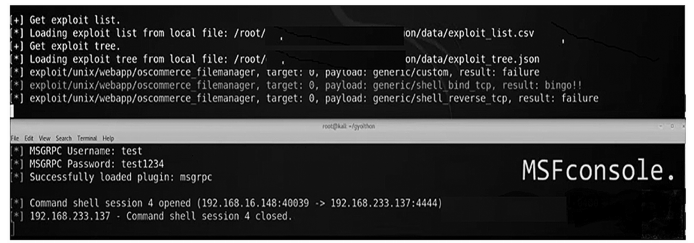
圖 9 目標安全缺陷驗證效果
綜上所述,這種結合使用的目標安全缺陷利用方法可以幫助安全測試人員更準確、高效地對目標系統進行評估和測試。
3結語
基于機器學習的應用系統深度指紋識別技術是面向信息安全測試領域的智能安全測試技術。本文在深入研究信息收集爬蟲技術和基于機器識別的指紋識別技術的基礎上,實現了相關功能模塊,結合基于 Metasploit 的目標安全缺陷利用實現,進行實網目標測試實驗,提高了互聯網目標安全測試的效率和成功率,且實驗驗證結果符合預期。
審核編輯:湯梓紅
-
Web
+關注
關注
2文章
1257瀏覽量
69368 -
指紋識別
+關注
關注
43文章
1741瀏覽量
102169 -
字符串
+關注
關注
1文章
577瀏覽量
20488 -
機器學習
+關注
關注
66文章
8382瀏覽量
132443
原文標題:基于機器學習的應用系統深度指紋識別技術及應用
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論