 邊緣域AI的“寒武大爆發”
邊緣域AI的“寒武大爆發”
本文來自邊緣域 AI 的“寒武大爆發”,自 ChatGPT 問世以來,從 GPT-1 到 GPT-3.5,GPT 模型的智能化程度不斷提升,GPT-4 多模態模型的發布進一步加速產業革命。ChatGPT 對智能終端的賦能開啟新一輪“寒武大爆發”時代。
根據在網絡中的位置,AI 芯片可以分為云端 AI芯片 、邊緣和終端 AI 芯片;根據其在實踐中的目標,可分為訓練(training )芯片和推理(inference )芯片。
云端主要部署高算力的 AI 訓練芯片和推理芯片,承擔訓練和推理任務,具體有智能數據分析、模型訓練任務和部分對傳輸帶寬要求比高的推理任務;
邊緣和終端主要部署推理芯片,承擔推理任務,需要獨立完成數據收集、環境感知、人機交互及部分推理決策控制任務。
全球新一輪 AI 風暴漸起,各家大廠相繼發布多款 AI 產品和大模型突破進展,可以預見未來訓練和推理端需要的算力將呈指數級增長。單 AI 芯片或計算架構或面臨傳輸時延、功耗、成本等多方面因素制約,因此,未來 AI 運算將呈現邊云協同的多層次算力網絡趨勢,AI 訓練迭代優化等復雜性任務主要在云端,實時、局部數據處理和推理任務主要在邊緣側。
1、邊緣 AI 芯片:打通推理加速的“最后一公里”
目前邊緣計算市場上參與者眾多,不同陣營廠商正以不同的路線共同推動邊緣計算快速發展。以英特爾、AMD 等為代表的芯片廠商積極推出 CPU、GPU、FPGA、DPU、IPU 等邊緣算力芯片;亞馬遜、微軟等云服務廠商將云計算能力向設備和用戶側延伸,擴充云數據中心的外延,將云原生的統一編程模式通過邊緣網關的能力應用到設備構成的邊緣云,主打云邊協同一體化

嚴格意義上的邊緣 AI 市場,包括邊緣終端市場和邊緣服務器市場兩類。邊緣終端市場是指直接在終端設備上做計算的 AI 芯片,對于功耗和能效要求比較高,包括針對特定應用的 SOC 芯片和通用加速器獨立芯片兩種形態。另一種針對邊緣服務器市場,通常以處理器加上通用型深度學習加速芯片為主流方案,傳統巨頭英偉達、華為等在此市場有較深布局。而本文則將重點討論邊緣終端市場的芯片架構,邊緣服務器市場暫不涉及。
2、計算芯片:NPU 算力是“兵家必爭之地”
在經歷文本、圖像、語音等生成式 AI 系統陸續落地之后,我們認為視頻將是后續 AIGC 落地的重要應用場景,人機交互的輸入端也將從文字、語音識別擴展至機器視覺等形態。智能終端的主控芯片也將從傳統的音視頻編解碼功能,擴展至更高性能、更大算力的要求。
目前,實現智能終端算力的最常用方式是在 SoC 芯片中內置 NPU 模塊,即神經網絡處理單元。這是專為物聯網人工智能設計的處理器模塊,用于加速神經網絡的運算,解決傳統芯片在神經網絡運算時效率低下的問題,特別擅長處理視頻、圖像類的海量多媒體數據。
國內芯片廠商均在加大自研 NPU 能力,以把握 AI 浪潮。以阿里平頭哥的含光 800 為例,其是一款面向數據中心 AI 應用的人工處理推理芯片,采用臺積電12nm 制程,集成高達 170 億顆晶體管。
含光 800 自研 NPU 架構為 AI 推理專門定制和創新,包括專有計算引擎和執行單元、192M 本地存儲(SRAM)以及便于快速存取數據的核間通信,從而實現了高算力、低延遲的性能體驗。含光 800 還支持主流的深度學習框架,包括 TensorFlow、MXNet、ONNX 等,能夠以行業領先的性能和效率來處理推理任務。

除專門推出 NPU 推理芯片,國產 SoC 廠商也在加大 NPU IP 自研力度,以豐富和提升 SoC 人工智能處理能力。如瑞芯微目前已迭代了 4 代 NPU 的 IP,不斷提升對神經網絡模型的支持和效率,公司最新旗艦芯片 RK3588 支持 6 Tops 的NPU 算力,可以賦能各類 AI 場景,給復雜場景的本地離線 AI 計算、復雜視頻流分析等應用提供了各種可能。
晶晨股份也基于在多媒體音視頻領域的長期積累和技術優勢,致力于疊加神經網絡處理器、專用 DSP 等技術,通過深度機器學習和高速的邏輯推理/系統處理,并結合行業先進的 12nm 制造工藝,形成了多樣化應用場景的人工智能系列芯片,公司的 A311D 系列人工智能芯片最高可支持 5Tops的 NPU 算力。
-
AI芯片
+關注
關注
17文章
1860瀏覽量
34919 -
邊緣計算
+關注
關注
22文章
3070瀏覽量
48660 -
大模型
+關注
關注
2文章
2339瀏覽量
2500
原文標題:邊緣域 AI 的“寒武大爆發”
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
研華科技邊緣AI平臺榮獲2024年IoT邊緣計算卓越獎
RISC-V,即將進入應用的爆發期
AMD分析嵌入式邊緣AI的發展
NVIDIA IGX平臺加速實時邊緣AI應用

算力概念股寒武紀20cm漲停市值重回千億
邊緣AI需求爆發,邊緣計算網關亟待革新
邊緣AI網關,將具備更強大的計算和學習能力
ai邊緣盒子有哪些用途?ai視頻分析邊緣計算盒子詳解

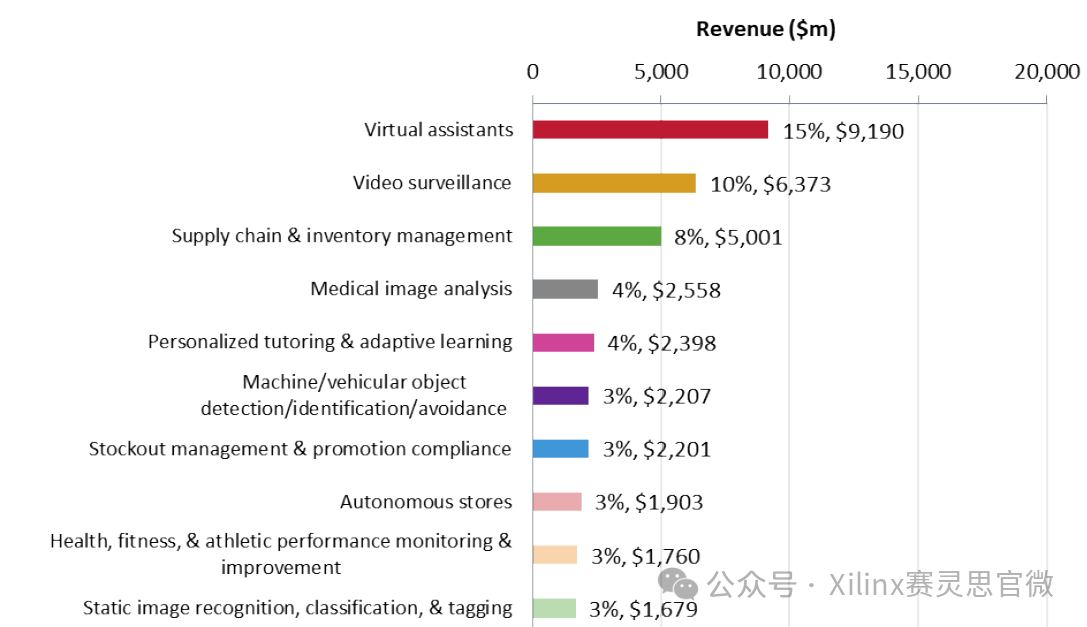
主流邊緣AI算法,在安防、零售、交通等領域的應用
邊緣AI需求大爆發,恩智浦在安全連接和模擬電源方面有怎樣的思考?

AI邊緣盒子助力安全生產相關等場景

“AI芯片第一股”寒武紀發布2023年度業績快報 虧8.36億元!





 工商網監
工商網監
評論