 如何充分發揮SQL能力?
如何充分發揮SQL能力?
阿里妹導讀
如何充分發揮 SQL 能力,是本篇文章的主題。本文嘗試獨辟蹊徑,強調通過靈活的、發散性的數據處理思維,就可以用最基礎的語法,解決復雜的數據場景。
一、前言
1.1 初衷
如何高效地使用 MaxCompute(ODPS)SQL ,將基礎 SQL 語法運用到極致。
在大數據如此流行的今天,不只是專業的數據人員,需要經常地跟 SQL 打交道,即使是產品、運營等非技術同學,也會或多或少地使用到 SQL ,如何高效地發揮 SQL 的能力,繼而發揮數據的能力,變得尤為重要。 MaxCompute(ODPS)SQL發展到今天已經頗為成熟,作為一種 SQL 方言,其 SQL 語法支持完備,具有非常豐富的內置函數,支持開窗函數、用戶自定義函數、用戶自定義類型等諸多高級特性,可以高效地應用在各種數據處理場景。?
如何充分發揮 SQL 能力,是本篇文章的主題。本文嘗試獨辟蹊徑,強調通過靈活的、發散性的數據處理思維,就可以用最基礎的語法,解決復雜的數據場景。
1.2 適合人群
不論是初學者還是資深人員,本篇文章或許都能有所幫助,不過更適合中級、高級讀者閱讀。
本篇文章重點介紹數據處理思維,并沒有涉及到過多高階的語法,同時為了避免主題發散,文中涉及的函數、語法特性等,不會花費篇幅進行專門的介紹,讀者可以按自身情況自行了解。
1.3 內容結構
本篇文章將圍繞數列生成、區間變換、排列組合、連續判別等主題進行介紹,并附以案例進行實際運用講解。每個主題之間有輕微的前后依賴關系,依次閱讀更佳。
1.4 提示信息
本篇文章涉及的 SQL 語句只使用到了 MaxCompute(ODPS)SQL 基礎語法特性,理論上所有 SQL 均可以在當前最新版本中運行,同時特意注明,運行環境、兼容性等問題不在本篇文章關注范圍內。
二、數列
數列是最常見的數據形式之一,實際數據開發場景中遇到的基本都是有限數列。本節將從最簡單的遞增數列開始,找出一般方法并推廣到更泛化的場景。
2.1 常見數列
2.1.1 一個簡單的遞增數列
首先引出一個簡單的遞增整數數列場景:
從數值0開始;
之后的每個數值遞增1;
至數值3結束;
如何生成滿足以上三個條件的數列?即[0,1,2,3]。
實際上,生成該數列的方式有多種,此處介紹其中一種簡單且通用的方案。
-- SQL - 1
select
t.pos as a_n
from (
select posexplode(split(space(3), space(1), false))
) t;
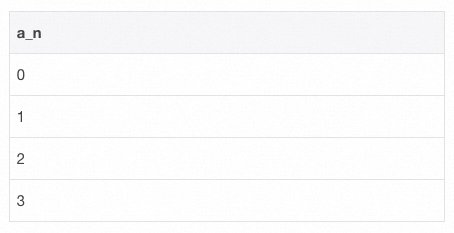
?通過上述 SQL 片段可得知,生成一個遞增序列只需要三個步驟:
1)生成一個長度合適的數組,數組中的元素不需要具有實際含義; 2)通過 UDTF 函數 posexplode 對數組中的每個元素生成索引下標;
3)取出每個元素的索引下標。以上三個步驟可以推廣至更一般的數列場景:等差數列、等比數列。下文將以此為基礎,直接給出最終實現模板。
2.1.2 等差數列
若設首項 ,公差為?
,公差為?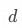 ,則等差數列的通項公式為?
,則等差數列的通項公式為?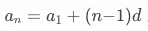 。
。
SQL 實現:
-- SQL - 2
select
a + t.pos * d as a_n
from (
select posexplode(split(space(n - 1), space(1), false))
) t;
2.1.3 等比數列
若設首項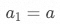 ,公比為?
,公比為?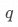 ,則等比數列的通項公式為
,則等比數列的通項公式為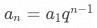 。?
。?
SQL 實現:
-- SQL - 3
select
a * pow(q, t.pos) as a_n
from (
select posexplode(split(space(n - 1), space(1), false))
) t;
提示:亦可直接使用 MaxCompute(ODPS)系統函數 sequence 快速生成數列。
-- SQL - 4 select sequence(1, 3, 1); -- result [1, 2, 3]
2.2 應用場景舉例
2.2.1 還原任意維度組合下的維度列簇名稱
在多維分析場景下,可能會用到高階聚合函數,如cube、rollup、grouping sets等,可以針對不同維度組合下的數據進行聚合統計。
場景描述
現有用戶訪問日志表 visit_log ,每一行數據表示一條用戶訪問日志。
-- SQL - 5
with visit_log as (
select stack (
6,
'2024-01-01', '101', '湖北', '武漢', 'Android',
'2024-01-01', '102', '湖南', '長沙', 'IOS',
'2024-01-01', '103', '四川', '成都', 'Windows',
'2024-01-02', '101', '湖北', '孝感', 'Mac',
'2024-01-02', '102', '湖南', '邵陽', 'Android',
'2024-01-03', '101', '湖北', '武漢', 'IOS'
)
-- 字段:日期,用戶,省份,城市,設備類型
as (dt, user_id, province, city, device_type)
)
select * from visit_log;
現針對省份 province , 城市 city, 設備類型 device_type 三個維度列,通過 grouping sets 聚合統計得到了不同維度組合下的用戶訪問量。問: 1)如何知道一條統計結果是根據哪些維度列聚合出來的?
2)想要輸出聚合的維度列的名稱,用于下游的報表展示等場景,又該如何處理?
解決思路
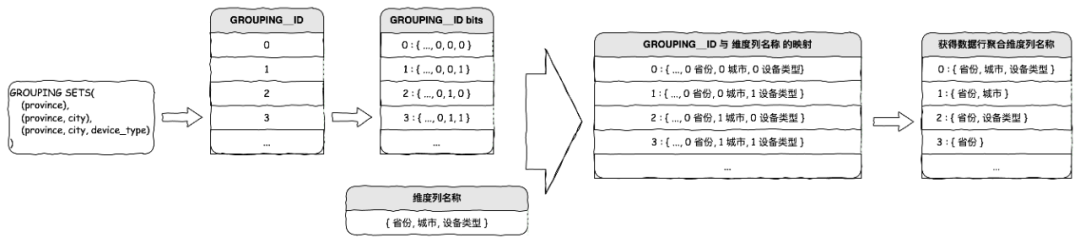
可以借助 MaxCompute(ODPS)提供的 GROUPING__ID 來解決,核心方法是對 GROUPING__ID 進行逆向實現。?
 ?
?
詳細步驟如下:
一、準備好所有的 GROUPING__ID 。
生成一個包含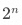 個數值的遞增數列,將每個數值轉為 2 進制字符串,并展開該 2 進制字符串的每個比特位。
個數值的遞增數列,將每個數值轉為 2 進制字符串,并展開該 2 進制字符串的每個比特位。
| GROUPING__ID | bits |
| 0 | { ..., 0, 0, 0 } |
| 1 | { ..., 0, 0, 1 } |
| 2 | { ..., 0, 1, 0 } |
| 3 | { ..., 0, 1, 1 } |
| ... | ... |
| 2n2n | ... |
其中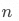 ?為所有維度列的數量,
?為所有維度列的數量,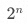 ?即為所有維度組合的數量,每個數值表示一種 GROUPING__ID。
?即為所有維度組合的數量,每個數值表示一種 GROUPING__ID。
二、準備好所有維度名稱。
生成一個字符串序列,依次保存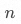 個維度列的名稱,即
個維度列的名稱,即
{ dim_name_1, dim_name_2, ..., dim_name_n }
三、將 GROUPING__ID 映射到維度列名稱。
對于 GROUPING__ID 遞增數列中的每個數值,將該數值的 2 進制每個比特位與維度名稱序列的下標進行映射,輸出所有對應比特位 0 的維度名稱。例如:
GROUPING__ID:3 => { 0, 1, 1 }
維度名稱序列:{ 省份, 城市, 設備類型 }
映射:{ 0:省份, 1:城市, 1:設備類型 }
GROUPING__ID 為 3 的數據行聚合維度即為:省份
SQL 實現
-- SQL - 6
with group_dimension as (
select -- 每種分組對應的維度字段
gb.group_id, concat_ws(",", collect_list(case when gb.placeholder_bit = 0 then dim_col.val else null end)) as dimension_name
from (
select groups.pos as group_id, pe.*
from (
select posexplode(split(space(cast(pow(2, 3) as int) - 1), space(1), false))
) groups -- 所有分組
lateral view posexplode(regexp_extract_all(lpad(conv(groups.pos,10,2), 3, "0"), '(0|1)')) pe as placeholder_idx, placeholder_bit -- 每個分組的bit信息
) gb
left join ( -- 所有維度字段
select posexplode(split("省份,城市,設備類型", ','))
) dim_col on gb.placeholder_idx = dim_col.pos
group by gb.group_id
)
select
group_dimension.dimension_name,
province, city, device_type,
visit_count
from (
select
grouping_id(province, city, device_type) as group_id,
province, city, device_type,
count(1) as visit_count
from visit_log b
group by province, city, device_type
GROUPING SETS(
(province),
(province, city),
(province, city, device_type)
)
) t
join group_dimension on t.group_id = group_dimension.group_id
order by group_dimension.dimension_name;
| dimension_name | province | city | device_type | visit_count |
| 省份 | 湖北 | NULL | NULL | 3 |
| 省份 | 湖南 | NULL | NULL | 2 |
| 省份 | 四川 | NULL | NULL | 1 |
| 省份,城市 | 湖北 | 武漢 | NULL | 2 |
| 省份,城市 | 湖南 | 長沙 | NULL | 1 |
| 省份,城市 | 湖南 | 邵陽 | NULL | 1 |
| 省份,城市 | 湖北 | 孝感 | NULL | 1 |
| 省份,城市 | 四川 | 成都 | NULL | 1 |
| 省份,城市,設備類型 | 湖北 | 孝感 | Mac | 1 |
| 省份,城市,設備類型 | 湖南 | 長沙 | IOS | 1 |
| 省份,城市,設備類型 | 湖南 | 邵陽 | Android | 1 |
| 省份,城市,設備類型 | 四川 | 成都 | Windows | 1 |
| 省份,城市,設備類型 | 湖北 | 武漢 | Android | 1 |
| 省份,城市,設備類型 | 湖北 | 武漢 | IOS | 1 |
三、區間
區間相較數列具有不同的數據特征,不過在實際應用中,數列與區間的處理具有較多相通性。本節將介紹一些常見的區間場景,并抽象出通用的解決方案。
3.1 常見區間操作
3.1.1 區間分割
已知一個數值區間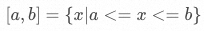 ,如何將該區間均分成?
,如何將該區間均分成?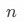 ?段子區間?
?段子區間?
該問題可以簡化為數列問題,數列公式為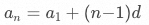 ?,其中
?,其中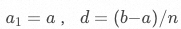 ,具體步驟如下:
,具體步驟如下:
1)生成一個長度為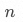 的數組; 2)通過 UDTF 函數 posexplode 對數組中的每個元素生成索引下標;
的數組; 2)通過 UDTF 函數 posexplode 對數組中的每個元素生成索引下標;
3)取出每個元素的索引下標,并進行數列公式計算,得出每個子區間的起始值與結束值。
SQL 實現:
-- SQL - 7
select
a + t.pos * d as sub_interval_start, -- 子區間起始值
a + (t.pos + 1) * d as sub_interval_end -- 子區間結束值
from (
select posexplode(split(space(n - 1), space(1), false))
) t;
3.1.2 區間交叉
已知兩個日期區間存在交叉 ['2024-01-01', '2024-01-03'] 、 ['2024-01-02', '2024-01-04']。問:
1)如何合并兩個日期區間,并返回合并后的新區間?
2)如何知道哪些日期是交叉日期,并返回該日期交叉次數??
解決上述問題的方法有多種,此處介紹其中一種簡單且通用的方案。核心思路是結合數列生成、區間分割方法,先將日期區間分解為最小處理單元,即多個日期組成的數列,然后再基于日期粒度做統計。具體步驟如下:
1)獲取每個日期區間包含的天數; 2)按日期區間包含的天數,將日期區間拆分為相應數量的遞增日期序列;
3)通過日期序列統計合并后的區間,交叉次數。?
SQL 實現:
-- SQL - 8
with dummy_table as (
select stack(
2,
'2024-01-01', '2024-01-03',
'2024-01-02', '2024-01-04'
) as (date_start, date_end)
)
select
min(date_item) as date_start_merged,
max(date_item) as date_end_merged,
collect_set( -- 交叉日期計數
case when date_item_cnt > 1 then concat(date_item, ':', date_item_cnt) else null end
) as overlap_date
from (
select
-- 拆解后的單個日期
date_add(date_start, pos) as date_item,
-- 拆解后的單個日期出現的次數
count(1) over (partition by date_add(date_start, pos)) as date_item_cnt
from dummy_table
lateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val
) t;
| date_start_merged | date_end_merged | overlap_date |
| 2024-01-01 | 2024-01-04 | ["2024-01-02:2","2024-01-03:2"] |
增加點兒難度!
如果有多個日期區間,且區間之間交叉狀態未知,上述問題又該如何求解。即:
1)如何合并多個日期區間,并返回合并后的多個新區間?
2)如何知道哪些日期是交叉日期,并返回該日期交叉次數?
SQL 實現:
-- SQL - 9
with dummy_table as (
select stack(
5,
'2024-01-01', '2024-01-03',
'2024-01-02', '2024-01-04',
'2024-01-06', '2024-01-08',
'2024-01-08', '2024-01-08',
'2024-01-07', '2024-01-10'
) as (date_start, date_end)
)
select
min(date_item) as date_start_merged,
max(date_item) as date_end_merged,
collect_set( -- 交叉日期計數
case when date_item_cnt > 1 then concat(date_item, ':', date_item_cnt) else null end
) as overlap_date
from (
select
-- 拆解后的單個日期
date_add(date_start, pos) as date_item,
-- 拆解后的單個日期出現的次數
count(1) over (partition by date_add(date_start, pos)) as date_item_cnt,
-- 對于拆解后的單個日期,重組為新區間的標記
date_add(date_add(date_start, pos), 1 - dense_rank() over (order by date_add(date_start, pos))) as cont
from dummy_table
lateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val
) t
group by cont;
| date_start_merged | date_end_merged | overlap_date |
| 2024-01-01 | 2024-01-04 | ["2024-01-02:2","2024-01-03:2"] |
| 2024-01-06 | 2024-01-10 | ["2024-01-07:2","2024-01-08:3"] |
3.2 應用場景舉例
3.2.1 按任意時段統計數據
場景描述
現有用戶還款計劃表 user_repayment ,該表內的一條數據,表示用戶在指定日期區間內 [date_start, date_end] ,每天還款 repayment 元。
-- SQL - 10
with user_repayment as (
select stack(
3,
'101', '2024-01-01', '2024-01-15', 10,
'102', '2024-01-05', '2024-01-20', 20,
'103', '2024-01-10', '2024-01-25', 30
)
-- 字段:用戶,開始日期,結束日期,每日還款金額
as (user_id, date_start, date_end, repayment)
)
select * from user_repayment;
如何統計任意時段內(如:2024-01-15至2024-01-16)每天所有用戶的應還款總額?
解決思路
核心思路是將日期區間轉換為日期序列,再按日期序列進行匯總統計。?
SQL 實現
-- SQL - 11
select
date_item as day,
sum(repayment) as total_repayment
from (
select
date_add(date_start, pos) as date_item,
repayment
from user_repayment
lateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val
) t
where date_item >= '2024-01-15' and date_item <= '2024-01-16'
group by date_item
order by date_item;
| day | total_repayment |
| 2024-01-15 | 60 |
| 2024-01-16 | 50 |
四、排列組合
排列組合是針對離散數據常用的數據組織方法,本節將分別介紹排列、組合的實現方法,并結合實例著重介紹通過組合對數據的處理。
4.1 常見排列組合操作
4.1.1 排列
已知字符序列 [ 'A', 'B', 'C' ] ,每次從該序列中可重復地選取出 2 個字符,如何獲取到所有的排列?
借助多重 lateral view 即可解決,整體實現比較簡單。
-- SQL - 12
select
concat(val1, val2) as perm
from (select split('A,B,C', ',') as characters) dummy
lateral view explode(characters) t1 as val1
lateral view explode(characters) t2 as val2;
| perm |
| AA |
| AB |
| AC |
| BA |
| BB |
| BC |
| CA |
| CB |
| CC |
4.1.2 組合
已知字符序列 [ 'A', 'B', 'C' ] ,每次從該序列中可重復地選取出 2 個字符,如何獲取到所有的組合?
借助多重 lateral view 即可解決,整體實現比較簡單。
-- SQL - 13
select
concat(least(val1, val2), greatest(val1, val2)) as comb
from (select split('A,B,C', ',') as characters) dummy
lateral view explode(characters) t1 as val1
lateral view explode(characters) t2 as val2
group by least(val1, val2), greatest(val1, val2);
| comb |
| AA |
| AB |
| AC |
| BB |
| BC |
| CC |
提示:亦可直接使用 MaxCompute(ODPS)系統函數 combinations 快速生成組合。
-- SQL - 14
select combinations(array('foo', 'bar', 'boo'),2);
-- result
[['foo', 'bar'], ['foo', 'boo']['bar', 'boo']]?
4.2 應用場景舉例
4.2.1 分組對比統計
場景描述
現有投放策略轉化表,該表內的一條數據,表示一天內某投放策略帶來的訂單量。
-- SQL - 15
with strategy_order as (
select stack(
3,
'2024-01-01', 'Strategy A', 10,
'2024-01-01', 'Strategy B', 20,
'2024-01-01', 'Strategy C', 30
)
-- 字段:日期,投放策略,單量
as (dt, strategy, order_cnt)
)
select * from strategy_order;
如何按投放策略建立兩兩對比組,按組對比展示不同策略轉化單量情況?
| 對比組 | 投放策略 | 轉化單量 |
| Strategy A-Strategy B | Strategy A | xxx |
| Strategy A-Strategy B | Strategy B | xxx? |
解決思路
核心思路是從所有投放策略列表中不重復地取出 2 個策略,生成所有的組合結果,然后關聯 strategy_order 表分組統計結果。?
SQL 實現
-- SQL - 16
select /*+ mapjoin(combs) */
combs.strategy_comb,
so.strategy,
so.order_cnt
from strategy_order so
join ( -- 生成所有對比組
select
concat(least(val1, val2), '-', greatest(val1, val2)) as strategy_comb,
least(val1, val2) as strategy_1, greatest(val1, val2) as strategy_2
from (
select collect_set(strategy) as strategies
from strategy_order
) dummy
lateral view explode(strategies) t1 as val1
lateral view explode(strategies) t2 as val2
where val1 <> val2
group by least(val1, val2), greatest(val1, val2)
) combs on 1 = 1
where so.strategy in (combs.strategy_1, combs.strategy_2)
order by combs.strategy_comb, so.strategy;
| 對比組 | 投放策略 | 轉化單量 |
| Strategy A-Strategy B | Strategy A | 10 |
| Strategy A-Strategy B | Strategy B | 20 |
| Strategy A-Strategy C | Strategy A | 10 |
| Strategy A-Strategy C | Strategy C | 30 |
| Strategy B-Strategy C | Strategy B | 20 |
| Strategy B-Strategy C | Strategy C | 30 |
五、連續
本節主要介紹連續性問題,重點描述了常見連續活躍場景。對于靜態類型的連續活躍、動態類型的連續活躍,分別闡述了不同的實現方案。
5.1 普通連續活躍統計
場景描述
現有用戶訪問日志表 visit_log ,每一行數據表示一條用戶訪問日志。
-- SQL - 17
with visit_log as (
select stack (
6,
'2024-01-01', '101', '湖北', '武漢', 'Android',
'2024-01-01', '102', '湖南', '長沙', 'IOS',
'2024-01-01', '103', '四川', '成都', 'Windows',
'2024-01-02', '101', '湖北', '孝感', 'Mac',
'2024-01-02', '102', '湖南', '邵陽', 'Android',
'2024-01-03', '101', '湖北', '武漢', 'IOS'
)
-- 字段:日期,用戶,省份,城市,設備類型
as (dt, user_id, province, city, device_type)
)
select * from visit_log;
如何獲取連續訪問大于或等于 2 天的用戶?
上述問題在分析連續性時,獲取連續性的結果以超過固定閾值為準,此處歸類為連續活躍大于 N 天閾值的普通連續活躍場景統計。
SQL 實現
基于相鄰日期差實現( lag / lead 版)
整體實現比較簡單。
-- SQL - 18
select user_id
from (
select
*,
lag(dt, 2 - 1) over (partition by user_id order by dt) as lag_dt
from (select dt, user_id from visit_log group by dt, user_id) t0
) t1
where datediff(dt, lag_dt) + 1 = 2
group by user_id;
| user_id |
| 101 |
| 102 |
基于相鄰日期差實現(排序版)
整體實現比較簡單。
-- SQL - 19
select user_id
from (
select *,
dense_rank() over (partition by user_id order by dt) as dr
from visit_log
) t1
where datediff(dt, date_add(dt, 1 - dr)) + 1 = 2
group by user_id;
| user_id |
| 101 |
| 102 |
基于連續活躍天數實現
可以視作基于相鄰日期差實現(排序版)的衍生版本,該實現能獲取到更多信息,如連續活躍天數。
-- SQL - 20
select user_id
from (
select
*,
-- 連續活躍天數
count(distinct dt)
over (partition by user_id, cont) as cont_days
from (
select
*,
date_add(dt, 1 - dense_rank()
over (partition by user_id order by dt)) as cont
from visit_log
) t1
) t2
where cont_days >= 2
group by user_id;
| user_id |
| 101 |
| 102 |
基于連續活躍區間實現
可以視作基于相鄰日期差實現(排序版)的衍生版本,該實現能獲取到更多信息,如連續活躍區間。
-- SQL - 21
select user_id
from (
select
user_id, cont,
-- 連續活躍區間
min(dt) as cont_date_start, max(dt) as cont_date_end
from (
select
*,
date_add(dt, 1 - dense_rank()
over (partition by user_id order by dt)) as cont
from visit_log
) t1
group by user_id, cont
) t2
where datediff(cont_date_end, cont_date_start) + 1 >= 2
group by user_id;
| user_id |
| 101 |
| 102 |
5.2 動態連續活躍統計
場景描述
現有用戶訪問日志表 visit_log ,每一行數據表示一條用戶訪問日志。
-- SQL - 22
with visit_log as (
select stack (
6,
'2024-01-01', '101', '湖北', '武漢', 'Android',
'2024-01-01', '102', '湖南', '長沙', 'IOS',
'2024-01-01', '103', '四川', '成都', 'Windows',
'2024-01-02', '101', '湖北', '孝感', 'Mac',
'2024-01-02', '102', '湖南', '邵陽', 'Android',
'2024-01-03', '101', '湖北', '武漢', 'IOS'
)
-- 字段:日期,用戶,省份,城市,設備類型
as (dt, user_id, province, city, device_type)
)
select * from visit_log;
如何獲取最長的 2 個連續活躍用戶,輸出用戶、最長連續活躍天數、最長連續活躍日期區間?
上述問題在分析連續性時,獲取連續性的結果不是且無法與固定的閾值作比較,而是各自以最長連續活躍作為動態閾值,此處歸類為動態連續活躍場景統計。
SQL 實現
基于普通連續活躍場景統計的思路進行擴展即可,此處直接給出最終 SQL :
-- SQL - 23
select
user_id,
-- 最長連續活躍天數
datediff(max(dt), min(dt)) + 1 as cont_days,
-- 最長連續活躍日期區間
min(dt) as cont_date_start, max(dt) as cont_date_end
from (
select
*,
date_add(dt, 1 - dense_rank()
over (partition by user_id order by dt)) as cont
from visit_log
) t1
group by user_id, cont
order by cont_days desc
limit 2;
| user_id | cont_days | cont_date_start | cont_date_end |
| 101 | 3 | 2024-01-01 | 2024-01-03 |
| 102 | 2 | 2024-01-01 | 2024-01-02 |
六、擴展
引申出更復雜的場景,是本篇文章前面章節內容的結合與變種。
6.1區間連續(最長子區間切分)
場景描述
現有用戶掃描或連接 WiFi 記錄表 user_wifi_log ,每一行數據表示某時刻用戶掃描或連接 WiFi 的日志。
-- SQL - 24
with user_wifi_log as (
select stack (
9,
'2024-01-01 1000', '101', 'cmcc-Starbucks', 'scan', -- 掃描
'2024-01-01 1000', '101', 'cmcc-Starbucks', 'scan',
'2024-01-01 1000', '101', 'cmcc-Starbucks', 'scan',
'2024-01-01 1000', '101', 'cmcc-Starbucks', 'conn', -- 連接
'2024-01-01 1000', '101', 'cmcc-Starbucks', 'conn',
'2024-01-01 1000', '101', 'cmcc-Starbucks', 'conn',
'2024-01-01 1100', '101', 'cmcc-Starbucks', 'conn',
'2024-01-01 1100', '101', 'cmcc-Starbucks', 'conn',
'2024-01-01 1100', '101', 'cmcc-Starbucks', 'conn'
)
-- 字段:時間,用戶,WiFi,狀態(掃描、連接)
as (time, user_id, wifi, status)
)
select * from user_wifi_log;
現需要進行用戶行為分析,如何劃分用戶不同 WiFi 行為區間?滿足: 1)行為類型分為兩種:連接(scan)、掃描(conn); 2)行為區間的定義為:相同行為類型,且相鄰兩次行為的時間差不超過 30 分鐘;
3)不同行為區間在滿足定義的情況下應取到最長;
| user_id | wifi | status | time_start | time_end | 備注 |
| 101 | cmcc-Starbucks | scan | 2024-01-01 1000 | 2024-01-01 1000 | 用戶掃描了 WiFi |
| 101 | cmcc-Starbucks | conn | 2024-01-01 1000 | 2024-01-01 1000 | 用戶連接了 WiFi |
| 101 | cmcc-Starbucks | conn | 2024-01-01 1100 | 2024-01-01 1100 | 距離上次連接已經超過 30 分鐘,認為是一次新的連接行為 |
上述問題稍顯復雜,可視作 動態連續活躍統計 中介紹的 最長連續活躍 的變種。可以描述為 結合連續性閾值與行為序列中的上下文信息,進行最長子區間的劃分 的問題。?
SQL 實現
核心邏輯:以用戶、WIFI 分組,結合連續性閾值與行為序列上下文信息,劃分行為區間。
詳細步驟:
1)以用戶、WIFI 分組,在分組窗口內對數據按時間正序排序; 2)依次遍歷分組窗口內相鄰兩條記錄,若兩條記錄之間的時間差超過 30 分鐘,或者兩條記錄的行為狀態(掃描態、連接態)發生變更,則以該臨界點劃分行為區間。直到遍歷所有記錄;
3)最終輸出結果:用戶、WIFI、行為狀態(掃描態、連接態)、行為開始時間、行為結束時間;
-- SQL - 25
select
user_id,
wifi,
max(status) as status,
min(time) as start_time,
max(time) as end_time
from (
select *,
max(if(lag_status is null or lag_time is null or status <> lag_status or datediff(time, lag_time, 'ss') > 60 * 30, rn, null))
over (partition by user_id, wifi order by time) as group_idx
from (
select *,
row_number() over (partition by user_id, wifi order by time) as rn,
lag(time, 1) over (partition by user_id, wifi order by time) as lag_time,
lag(status, 1) over (partition by user_id, wifi order by time) as lag_status
from user_wifi_log
) t1
) t2
group by user_id, wifi, group_idx
;
| user_id | wifi | status | start_time | end_time |
| 101 | cmcc-Starbucks | scan | 2024-01-01 1000 | 2024-01-01 1000 |
| 101 | cmcc-Starbucks | conn | 2024-01-01 1000 | 2024-01-01 1000 |
| 101 | cmcc-Starbucks | conn | 2024-01-01 1100 | 2024-01-01 1100 |
該案例中的連續性判別條件可以推廣到更多場景,例如基于日期差值、時間差值、枚舉類型、距離差值等作為連續性判別條件的數據場景。?
結語
通過靈活的、散發性的數據處理思維,就可以用基礎的語法,解決復雜的數據場景是本篇文章貫穿全文的思想。文中針對數列生成、區間變換、排列組合、連續判別等常見的場景,給出了相對通用的解決方案,并結合實例進行了實際運用的講解。
本篇文章嘗試獨辟蹊徑,強調靈活的數據處理思維,希望能讓讀者覺得眼前一亮,更希望真的能給讀者產生幫助。同時畢竟個人能力有限,思路不一定是最優的,甚至可能出現錯誤,歡迎提出意見或建議。
審核編輯:湯梓紅
-
SQL
+關注
關注
1文章
760瀏覽量
44078 -
函數
+關注
關注
3文章
4307瀏覽量
62432 -
數組
+關注
關注
1文章
416瀏覽量
25910
原文標題:如何充分發揮SQL能力?
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
充分發揮FPGA優勢 Altera首推新穎OpenCL工具
IIoT要充分發揮潛力 須先克服兩大挑戰
如何充分發揮傳輸SDN的全部潛力
大數據企業充分發揮優勢 保障了各項防控工作高效有序的進行
AI沖向醫療前線 充分發揮了企業自身優勢全力抗疫
科大訊飛充分發揮AI優勢 多方面助力抗疫
中國聯通將充分發揮eSIM優勢,強勢賦能Apple Watch Series 6火力全開
如何充分發揮出NVMe盤的持久性?
實驗出真知!可充分發揮ESD保護元件性能的電路設計
使用 BQ25180 線性充電器充分發揮NTC的全部潛力






 工商網監
工商網監
評論